环境(environments)是管理作用域的数据结构 (emm 就是无限套娃)
环境基础
环境组成
- 框架(frame),其中包含名字和对象的绑定(行为很像一个命名列表)
- 父环境。
环境的工作是关联或者绑定一组名称到一组值,每一个名字关联了一个对象,这个对象保存在内存中的某个地方
- 每个名字都指向一个对象,这个对象保存在内存中的某个地方
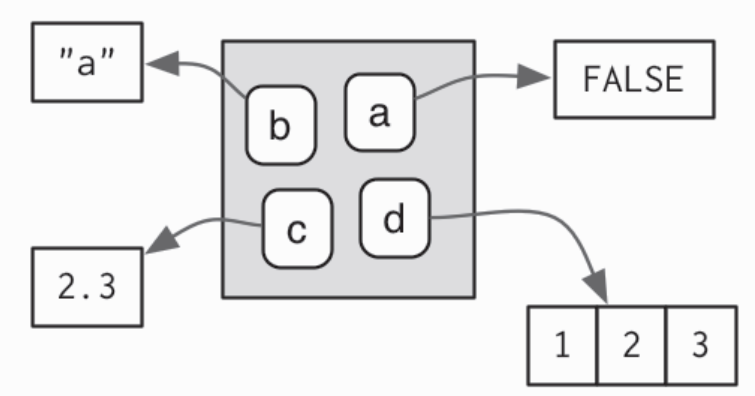
- 对象不存在于环境中,所以多个名字可以关联同一个对象
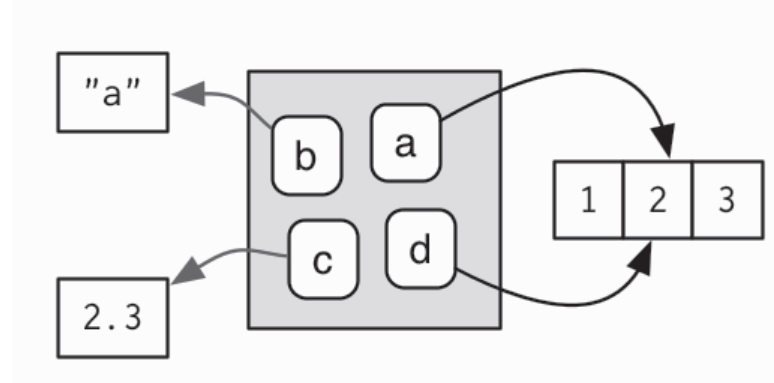
- 可以指向具有相同值的不同对象
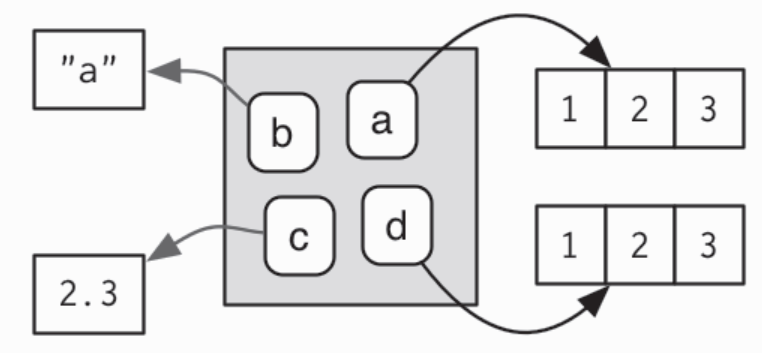
- 如果一个对象没有名字指向它,那么它会被垃圾收集器(garbage collector)自动删除
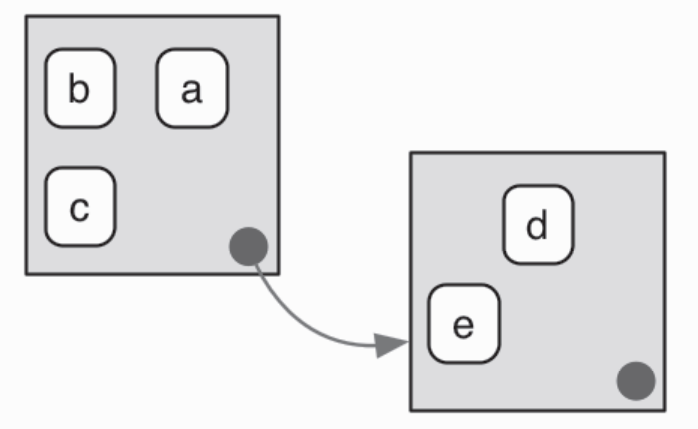
- 每个环境都有父环境,也就是另一个环境。 父环境是用来实现词法作用域的:如果在一个环境中没有找到某个名称,那么 R 将在它的父环境中查找,以此类推。 只有一种环境没有父环境: 空环境
环境和列表的区别
一般来说,环境类似于列表,但是有四个重要区别:
- 在一个环境中的每个对象都有唯一的名称
- 在一个环境中的对象是无序的。 (比如,在一个环境中,查询排在”第一位”的对象是没有意义的)
- 环境有一个父环境
- 环境具有引用语义
引用语义 :一个对象被系统标准的复制函数复制后,与被复制的对象共享底层资源,只要一个改变了另外一个就会改变。.
特殊环境
globalenv()或者叫全局环境,是交互工作空间。 这是普通的工作环境。 全局环境的父环境是上一个你使用library()或require()加载的包。baseenv(),或者叫基础环境,是base包的环境。 它的父环境是空环境。emptyenv(),或者叫空环境,是所有环境的终极祖先,也是唯一没有父环境的环境。environment()是当前环境。
使用search()函数可以列出全局环境中的所有父环境, 这被称为搜索路径,因为在这些环境中的对象,都可以从顶层的交互工作区中找到。 它为每一个加载的包以及其它 attach()的对象都包含一个环境。
> search()[1] ".GlobalEnv" "tools:rstudio" "package:stats" "package:graphics"[5] "package:grDevices" "package:utils" "package:datasets" "package:methods"[9] "Autoloads" "package:base"
Autoloads: 它用于按需加载程序包,以便节省内存
使用as.environment()访问搜索列表中的任何环境
> as.environment("package:stats")<environment: package:stats>attr(,"name")[1] "package:stats"attr(,"path")[1] "D:/soft/R/R-4.0.3/library/stats"
每当你使用library()加载一个新的包,它就会被插入在全局环境以及先前位于搜索路径顶部的包之间 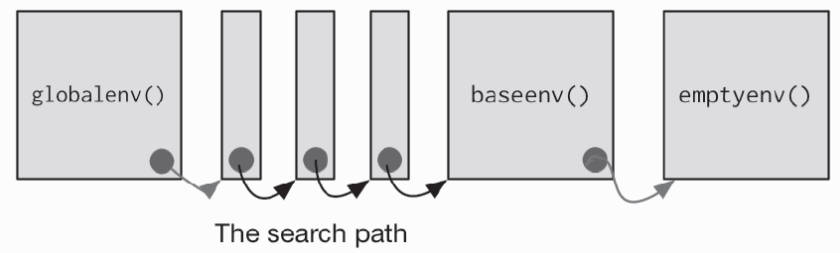
创建环境
使用new.env()创建一个环境,使用$、[[或者get()查看环境中的绑定关系,同时可以修改绑定关系,设置参数all.names = TRUE 可以显示环境中所有的绑定关系
get()使用普通的作用域规则,如果绑定关系找不到,则抛出错误。- 使用
exists()来确定某个绑定关系是否在环境中存在,不会搜索父环境 (inherits = FALSE时,get()也可以) - 使用
rm()来删除绑定关系 要比较环境,必须使用
identical()而不是==e <- new.env("e1")e$a <- 1e$b <- 2ls(e)e$a <- 2
也可以使用
ls.str()查看环境中所有的名字对应的对象,all.names也支持e <- new.env("e1")e$a <- 1e$b <- 2e$d <- "c"> ls.str(e)a : num 1b : num 2d : chr "c"
函数环境
有四类和函数相关的环境四类与函数相关的环境
封闭环境:封闭环境是函数创建时所处的环境。 每个函数都有且只有一个封闭环境
- 绑定环境:使用
<-把一个函数绑定到一个名称,就定义了一个绑定环境 - 执行环境:调用函数,创建了一个短暂的执行环境,它用于存储执行期间创建的变量
- 调用环境:每一个执行环境都关联了一个调用环境,它告诉你函数是从哪里调用的。
封闭环境
创建一个函数时,它会得到它所处的环境的引用。 这就是封闭环境,用于词法作用域。 你可以调用environment()来确定一个函数的封闭环境,并把函数作为它的第一个参数f <- function(x){x <- x ** 2x}environment(f)#<environment: R_GlobalEnv>
绑定环境
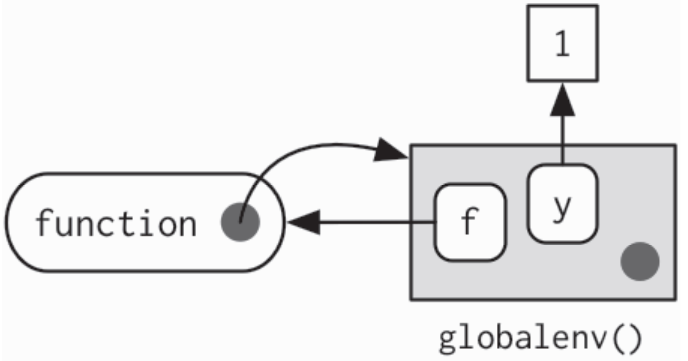
函数的绑定环境是所有与它有绑定关系的环境 ,如下,y是和函数有绑定关系的值,此时的绑定环境和封闭环境是同一个环境<environment: R_GlobalEnv>y <- 1f <- function(x){x <- x ** yx}
如果将函数的封闭环境改一下,那封闭环境和绑定环境就不是同一个了e <- new.env()e$g <- function() 1
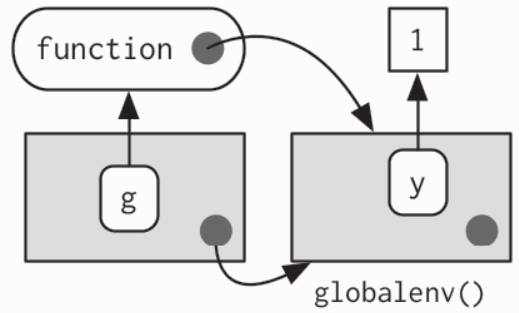
封闭环境属于函数,并且从来都不会改变,即使函数被搬到一个不同的环境中也是。 封闭环境决定函数如何寻找值; 绑定环境决定我们如何找到函数命名空间
namespac是许多编程语言使用的一种代码组织的形式,通过命名空间来分类,区别不同的代码功能,避免不同的代码片段(通常由不同的人协同工作或调用已有的代码片段)同时使用时由于不同代码间变量名相同而造成冲突
对于包的命名空间(namespace)来说, 绑定环境和封闭环境的区别是很重要的。 包的命名空间保持了包的独立性,命名空间是使用环境来实现的,基于这样的事实,那么函数不需要存在于它们的封闭环境中。 以基本函数sd()为例。 它的绑定环境和封闭环境是不同的
environment(sd)#> <environment: namespace:stats>where("sd")# <environment: package:stats>
每一个包都有与它关联的两个环境: 包环境和命名空间环境。 包环境包含所有可公开访问的函数,并且被放置在了搜索路径之上。 命名空间环境包含所有函数(包括内部函数),并且其父环境是一个特殊的导入(import)环境,它包含着这个包需要的所有函数的绑定关系。 包中的每个导出(exported)函数都被绑定到包环境,但是被命名空间环境进行封闭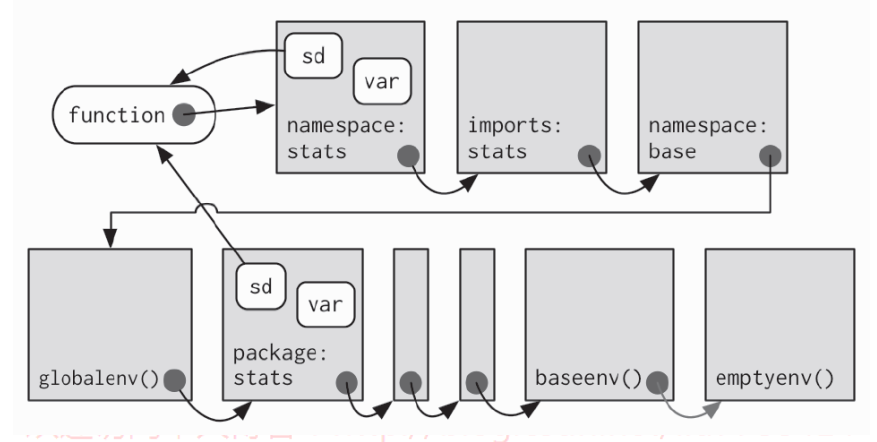
输入 var 时,它首先在全局环境中被发现。 而当 sd()寻找 var()时,它首先在其命名空间环境中发现 var(),因此永远都不会搜索 globalenv()
执行环境
函数的调用执行”全新的开始原则”(fresh start principle),每当函数被调用的时候,一个新的环境将被创建出来管理执行过程。 执行环境的父环境是函数的封闭环境。 一旦函数执行完毕,这个环境就会被抛弃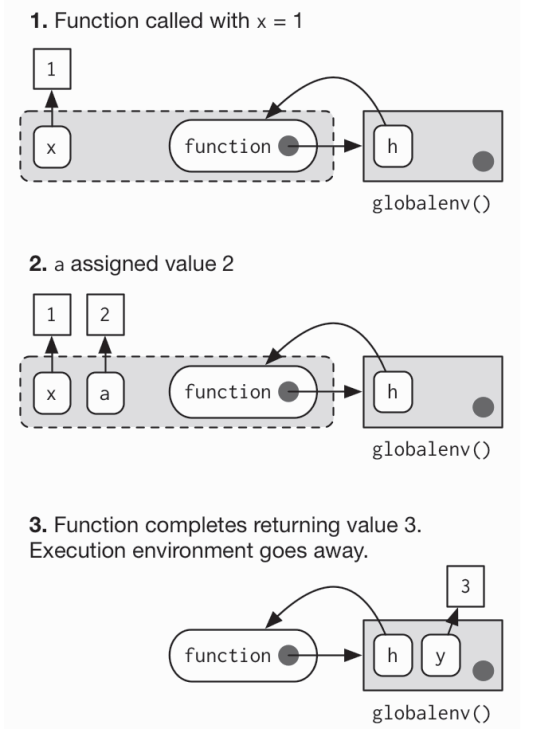
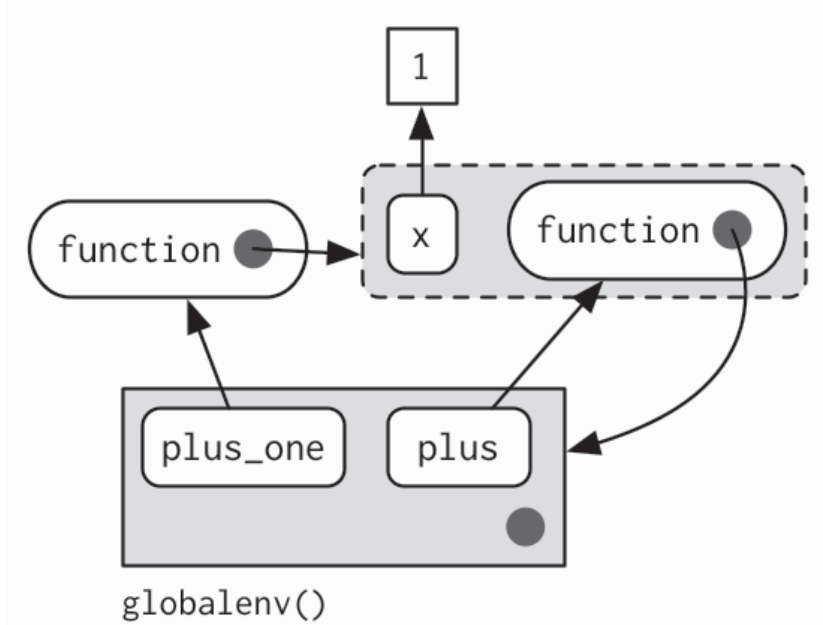
当你在一个函数中创建另一个函数时, 子函数的封闭环境就是父函数的执行环境,并且执行环境不再是临时的
plus <- function(x) {function(y) x + y}plus_one <- plus(1)identical(parent.env(environment(plus_one)), environment(plus))#> [1] TRUE
调用环境
每一个执行环境都关联了一个调用环境,它告诉你函数是从哪里调用的。
顶层的 x(被绑定到 20)其实与结果没有什么关系, h()使用普通的作用域规则,在它被定义的环境中进行搜索,然后发现关联到 x 的值是 10。 然而,在 i()被调用的环境中,询问 x 关联到什么值,仍然是有意义的:在**h()**被定义的环境中,x 是 10,但是在 h()被调用的环境中,它是 20。
h <- function(){x <- 10function(){x}}i <- h()x <- 20i()# 此时i的值为 10
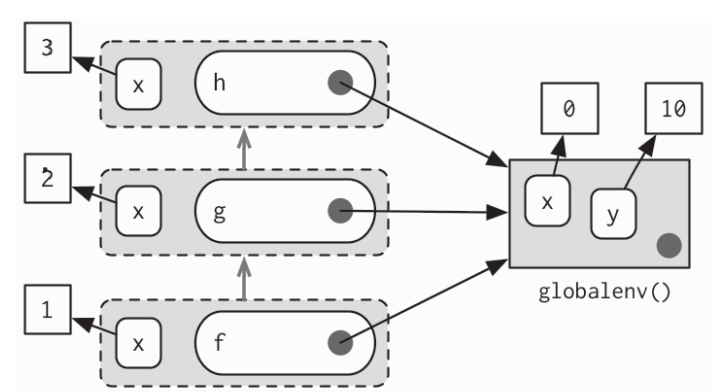
更复杂的场景中,不是只有一个父环境被调用,而是一系列的调用,它会导致从顶层的发起函数开始,一直调用到最底层函数。 下面的代码生成了一个三层深的调用栈。 开放式的箭头表示每一个执行环境的调用环境
x <- 0y <- 10f <- function() {x <- 1g()}g <- function() {x <- 2h()}h <- function() {x <- 3x + y}f()# 此时f()输出为13
赋值
<-
在一个环境中, 赋值就是把一个值绑定(或重新绑定)到一个名字的行为。 它是与作用域相对应的,是决定如何找到与一个名字相关联的值的规则集合,名字通常由字母、数字、 .和组成,而不能以``, 数字开始。并且不能是保留字
<<-
深赋值(deep assignment)箭头符号, <<-,不会在当前环境下创建一个变量,而是不断向上搜索父环境,直到找到变量后,直接修改现有变量。 你也可以使用assign()进行深度绑定:name <<- value 相当于assign("name",value, inherits = TRUE)
如果<<-没有找到现有变量,那么它将在全局环境中创建一个。 这通常是不可取的,因为全局变量会引入不易察觉的函数之间的依赖关系。
延迟绑定
延迟绑定创建和存储一个表达式的承诺,仅在需要的时候进行计算,而不是立即赋予表达式的结果,使用特殊赋值运算符%<d-%来创建延迟绑定,它由pryr包提供
system.time(b %<d-% {Sys.sleep(1); 1}, 1)
活动绑定
每次访问它们的时候,都会重新进行计算, %<a-%
x1 <- runif(1)x1x1[1] 0.2595692[1] 0.2595692x2 %<a-% runif(1)x2x2[1] 0.6626286[1] 0.7056665
显式环境
显式环境(Explicit environments) ,不像 R 中的其它大多数对象,当你修改一个环境时,它不会进行复制
modify <- function(x) {x$a <- 2invisible()}x1 <- list()modify(x1)x1# [1] list()x_env <- new.env()modify(x_env)x_env$a# [1] 2
避免复制
由于环境具有引用语义,因此你永远都不会意外地创建了一个副本。 这使得它成为可以包含大对象的很有用的容器。 这是 bioconductor包用于管理大基因组对象,经常需要使用的技术。 但是,R 3.1.0中的改变使这种技术变得不那么重要了,因为修改列表不再会进行深拷贝(deep copy)了。 此前,修改列表中的一个元素会导致复制所有元素,如果某些元素很大,那么这是一种开销很大的操作。 而现在,修改列表时会有效地重用已有的向量,节省了大量时间
管理一个包的状态
在包中,显式的环境是有用的,因为它们允许你在函数调用之间维护包的状态。通常,包中的对象是锁定的,所以你不能直接修改它们, emptyenv()可以替换成其他环境,这样就能修改包中的变量的了
my_env <- new.env(parent = emptyenv())my_env$a <- 1get_a <- function(){my_env$a}set_a <- function(value){old <- my_env$amy_env$a <- valueinvisible(old)}get_a()set_a(11)get_a()
高效地通过名字查找值
哈希表(hashmap)是一种数据结构,使用它根据名字来查找对象时,查找的时间复杂度是常数的, O(1)。 在默认情况下,环境提供了这种行为,所以它可以用来模拟一个哈希表

若有收获,就点个赞吧
0 人点赞
