8.3 OpenCL内存性能的考量
8.3.1 全局内存
与内存相关的话题我们在第2章有详细的讨论过。OpenCL应用的性能与是否高效的使用的内存有着很大的关系。不过,高效的内存则依赖与具体的硬件(执行OpenCL内核的设备)。因此,同样的访存模式,在GPU上是高效的,不过在CPU上就不一定了。因为GPU的供应商繁多,且与CPU在制造方面有很大的区别。
所有例子中,内核吞吐量的级别是内存性能分析的开端。下面简单的计算公式,就是用来计算内核的带宽大小:
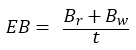 (8.2)
(8.2)
EB代表有效带宽,Br代表从全局内存上读取的数据量(单位:byte),Bw表示写入全局内存的数据量(单位:byte),t代表内核运行的时间。
时间t的获取,可以通过一些性能测评工具,比如:ADM的CodeXL。Br和Bw可以通过每个工作项所读取或写入的数据量,然后乘以工作项的数量计算得出。所以,在某些情况下,这些读写的数据量都是估算出来的。
当我们测得当前执行内核的带宽,我们可以将测出带宽与执行设备的峰值带宽进行比较,看一下二者在数值上差多少。如果二者很接近,那说明我们充分的利用了当前内存系统;如果二者相差甚远,那我们就需要考虑重构我们内存访问的方式,以提高内存的利用率,增大内核带宽。
OpenCL程序在对内存访问时,需要考虑对内存所处的位置。大多数架构在运行OpenCL内核时,会基于不同等级的矢量进行(可能像SSE,或使用管道导向型输入语言进行在佛那个向量化,例如AMD的IL或NVIDIA的PTX),内存系统会将向量中的数据打包一起处理以加速应用。另外,局部访问通常会使用缓存进行。
大多数现代CPU都支持不同版本的SSE和AVX向量指令集。将内存部分设计成全对齐的模式,向量读取这样的内存会有使用到相关的指令集,并且向量指令会使内存访问更加高效。可以给定一个较小的向量尺寸(比如float4),这样编译器会生成更加高效的向量读取指令。其很好的利用了缓存行,缓存和寄存器间做数据移动是最高效的。不过,CPU在处理未对齐的内存或更多的随机访问时,缓存会帮助掩盖一些性能损失。图8.9和图8.10提供了两个例子,一个用于读取一段连续的4个数据,另一个则是通过随机访问4个数据。如果缓存行较窄,则会出现很多次缓存未命中,这样的情况会大大影响应用的性能。
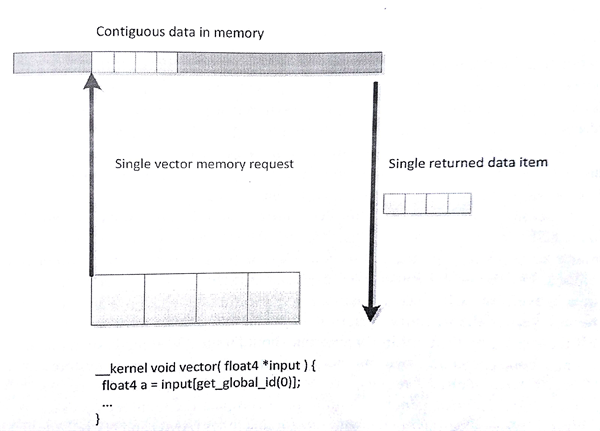
图8.9 内存系统中使用向量的读取数据的方式会更加高效。当工作项访问连续的数据时,GPU硬件会使用合并访问的方式获取数据。
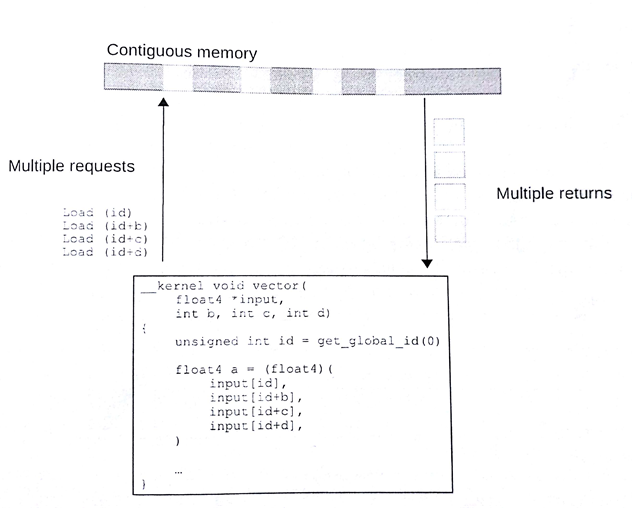
图8.10 访问非连续元素时,性能会有一定的损失。
之前的章节中我们曾讨论过,GPU内存架构与CPU的内存架构有着很大的不同。GPU使用多线程的方式来掩盖不同级别的内存延迟,CPU则会更多的是用ALU的能力,而非缓存和复杂的乱序逻辑。传统GPU具有更多的计算资源可用,如果我们不想GPU饿死,就需要具有更加高带宽的内存系统。很多现代GPU架构,特别是高性能桌面版本,比如AMD的Radeon系列和NVIDIA的GeForce系列,都在使用宽SIMD架构。试想8.10图中的例子,将向量扩展成(AMD Radeon R9支持的)64位硬件向量。
高效的访问在不同的架构中也有不同的方式。对于x86 CPU来说使用的是SSE指令集,我们可能会使用128位的float4类型作为数据处理的单元,这样可能会增加缓存行的利用率,减少缓存未命中的概率。对于AMD Radeon R9 290X GPU架构,同一波面阵中连续的工作项就可以同时对内存进行访问。如果内存系统不能及时的处理这些请求,则会造成访存延迟。对于最高的性能,同一波面阵的工作项同时发起32位的读取请求时,就意味着最多需要读取256字节(32bit x 64个工作项)内存数据,这样内存系统只需要相应开辟一块较大内存上的请求。为了可在不同的架构间进行移植,一个好的解决方式就是让内存访问的效率尽可能的高,可以在宽矢量设备(AMD和NVIDIA GPU)和窄矢量设备(x86 CPU)都有很好的访存效率。为了达到这种效果,我们可以通过工作组计算出所要放访问的内存起始地址,该地址应为work-groupSIze x loadSize对齐,其中loadSize是每个工作项所加载的数据大小,其应该是一个合理的值——对于AMD GCN架构的设备来说,32位是一个不错大小;对于x86 CPU和旧一些的GPU架构来说,128位则是很好的选择;对支持AVX架构的设备来说,256位则是不二之选。为什么32位对于AMD GCN架构来说是一个不错的选择,下面我们就来解释一下。
要处理不同的内存系统,需要面对很多问题,比如:减少片外链接DRAM的访存冲突。先让我们来看一下AMD Radeon架构中如何进行地质分配。图8.11中低8位展示了给定内存块中的数据内存起始地址;这段信息可以存储在缓存行和子缓存行中,供我们进行局部读取。如果尝试读取二维数据中一列的数据,对于行优先的存储方式,这种方式对于片上总线来说是低效的。其也意味着,设备上同时执行的多个工作组,访问的内存通道和内存块都有所不同。

图8.11 将Radeon R9 290X地址空间的内存通道与DRAM块间的映射
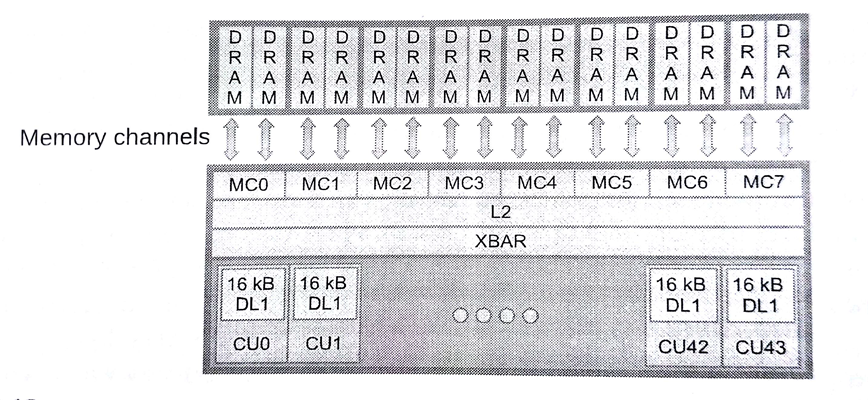
图8.12 Radeon R9 290X内存子系统
每个内存通道的控制器与片外内存进行连接(图8.12)。我们希望执行设备能够通过内存系统,访问到其中的所有内存块与内存通道。不过,一个波面阵中某个矢量将会命中多个内存通道(或内存块)占用和阻塞他们,导致其他波面阵对相应地址访问的延迟,从而导致带宽的下降。最佳的方式是,给定的波面阵能够连续的读取指定内存通道和内存块上的数据,允许更多波面阵可以并行的对内存进行访问,形成高效的数据流。
为了避免使用多个通道,一个波面阵所能访问到的区域在64个字(256字节)之内,这就能保证所有工作项在读取32位数据时,是从连续的地址上获取。这里需要讨论一下访存最坏的结果——“当多个波面阵中的每个工作项对同一地址的数据进行访问”——每个工作项中的变量都将命中同一内存通道和内存块,并且串行的获取数据,访存吞吐量比顶峰时降低数倍。更多的有关AMD架构主题的内容,可以在《AMD的OpenCL编程指南》中找到[4]。同样的信息也在其他GPU供应商的计算架构中出现——例如,NVIDIA的《CUDA编程指南》[5]。
8.3.2 局部内存——软件可控缓存
大多数支持OpenCL的设备都支持不同形式的缓存。由于面向图像的设计,很多GPU只提供只读数据缓存,这样能复用大量的数据。
OpenCL使用缓存最简单的方式就是使用图像类型(第6和第7章讨论过)。GPU上,图像可以将数据映射成硬件可读纹理。假设复杂的滤波器不需要进行二维内存访问,那么访问内存效率将会提高。不过,GPU缓存相较波面阵所要读取的内存,则是相形见绌。编程者可通过代码控制暂存式内存在局部空间的大小,在高效获取数据的同时,减少了硬件控制缓存的开销,有效的节约资源。这对于工作组内工作项的数据交换来说,能够减少栅栏冲突和访问延迟。(图5.5就是一个例子)
当然,考虑对数据进行优化时,需要认真的考虑如何利用数据的局部性。很多例子中,其消耗在于使用额外的拷贝指令将数据搬移到局部内存中,之后搬运到ALU中(可能通过寄存器)进行计算,这种方式的效率通常要比简单的复用缓存中数据的效率低得多。大量的读取和写入操作复用同一地址时,将数据搬移到局部内存中将会很有用,读取和写入操作对局部内存的操作延迟要远远小于对于全局内存的操作。并且,对二维数据进行访问时,就不需要通过全局变量进行数据加载,从而减少缓存加载所需要的时间。
下例中的读/写操作,将会大大收益与局部内存,特别是给定宽度的只读缓存。读者可以尝试,写出前缀求和的C代码和下面的代码进行对照:
{%ace edit=false, lang=’c_cpp’%} void localPrefixSum( global unsigned *input, global unsigned output, __local unsigned prefixSums, unsigned numElements){
/ Copy data from global memory to local memory / for (unsigned index = get_local_id(0); index < numElements; index += get_local_size(0)){ prefixSums[index] = input[index]; }
/* Run through levels of tree, each time halving the size
of the element set performing reduction phase */ int offset = 1; for (unsigned level = numElements / 2; level > 0; level /= 2){ barrier(CLK_LOCAL_MEM_FENCE);
for (int sumElement = get_local_id(0); sumElement < level; sumElement += get_local_size(0)){ int ai = offset (2 sumElement + 1) - 1; int bi = offset (2 sumElement + 2) - 1; prefixSums[bi] = prefixSums[ai] + prefixSums[bi]; } offset *= 2; }
barrier(CLK_LOCAL_MEM_FENCE);
/ Need to clear the last element / if (get_local_id(0) == 0){ prefixSums[numElements - 1] = 0; }
/ Push values back down the tree / for (int level = 1; level < numElements; level *= 2){ offset /= 2; barrier(CLK_LOCAL_MEM_FENCE);
for (int sumElement = get_local_id(0); sumElement < level; sumElement += get_local_size(0)){ int ai = offset (2 sumElement + 1) - 1; int bi = offset (2 sumElement + 2) - 1; unsigned temporary = prefixSums[ai]; prefixSums[ai] = prefixSums[bi]; prefixSums[bi] = temporary + prefixSums[bi]; } }
barrier(CLK_LOCAL_MEM_FENCE);
/ Write the data out to global memory / for (unsigned index = get_local_id(0); index < numElements; index += get_local_size(0)){ output[index] = prefixSums[index]; } } {%endace%}
程序清单8.2 单工作组的前缀求和
这段代码是进行过一定优化的,其让工作组中的工作项共享一段数组,从而降低访问数据的延迟。数据流中的第一个循环(第19行)如图8.13所示。注意循环中的每次迭代更新一些工作项中的数据,以供下次迭代使用。这里需要工作项之间的合作,才能完成这项工作。内部的循环最好能覆盖大部分工作项,以避免执行分支。为了保证工作项的正确行为,我们在外层循环中添加了栅栏,同步对应的工作项,以确保数据在下次循环时已经准备好。
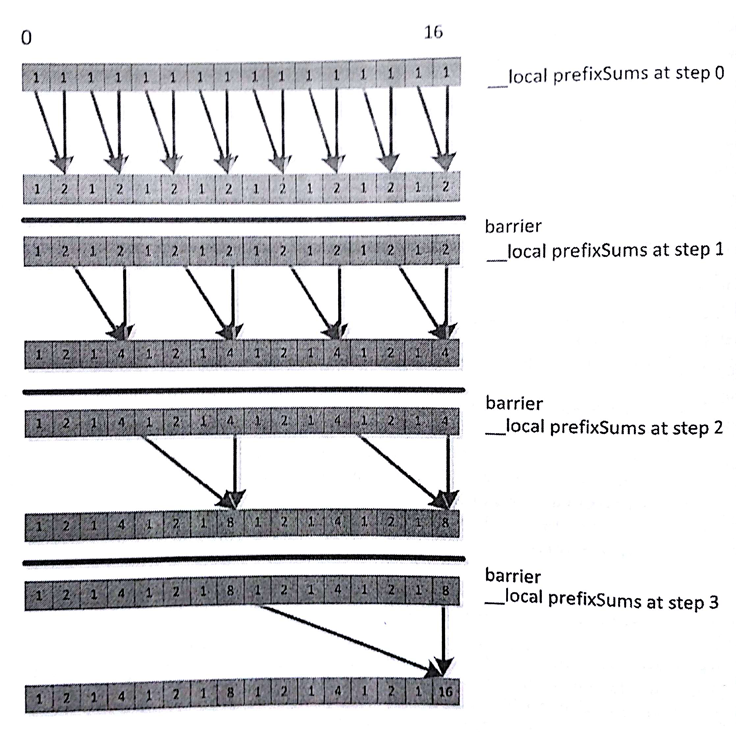
图8.13 展示了代码清单8.2中将16个元素存入局部内存,使用8个工作项进行前缀累加
代码清单8.2中的前缀求和使用的是局部内存的方式,这种方式在大多数宽SIMD架构下的效率并不高(比如:高端GPU)。之前我们讨论过全局变量,内存系统倾向于将内存进行分块,而非让每个内存位置都能让外部访问到。最后,硬件的暂存式内存(比如:缓存)更加倾向于让每个内存块执行多次读操作,或者并发的进行读写操作(或其他一些多次访问操作),多次读取操作可以跨越多个内存块进行。所以在使用宽硬件SIMD访问内存时,这点必须要考虑到。每个周期中,Radeon R9 290X GPU使用4个SIMD单元可以处理两个局部内存操作。每个SIMD单元具有16个通道,每个周期可以完成32个读或写操作,可以LDS上32个内存块。每个内存块支持一个访问入,那么每个内存块只能提供一个值,所以只有在所有访问目标都在不同的内存块上时,才能获取最好的吞吐率。同样的规则也适用于其他计算架构:NVIDIA的费米框架,局部内存分为32个内存块。
局部内存的问题并没有全局内存那么严重。全局内存中,大范围跨越访问会因缓存行上的多个访问丢失,导致访存延迟。局部内存中,至少架构中是由暂存器的,编程者可以根据自身意愿将数据放到该内存上。这里需要的是,我们发起的16次局部内存访问,最好访问的是不同的内存块。
图8.14中展示了图8.13前缀求和在8个LDS块上进行的第一步,这里每个工作项在每个周期中能执行一次局部内存操作。这个例子中,我们的局部内存可以在一个周期内返回8个值。那么我们应该如何在第一步中提升应用的执行效率呢?
注意16个元素的局部内存(对于前缀求和来说是很有必要的)已经超过两行。每列上的数据在一个内存块上,每行上只存放每个内存块的一个地址。假设(通常在很多架构中)每个内存块都是32位宽,并且假设当前波面阵不需要依赖其他波SIMD单元处理后的数据。不过在图8.14中,我们的第一步可谓是失败的。局部内存和全局内存一样,一个SIMD矢量会根据矢量长度连续,并高效的访问数据,并且局部内存不存在访问争夺。图8.13中我们看到的是另一番景象。29行中prefixSums[bi]=perfixSums[ai]+perfixSums[bi]中,对prefixSums[bi]访问了两次。图中就是尝试对位置3、7、11和15进行读取。图8.14中,3和11都存储在内存块3上,7和15存储在内存块7上。根据之前的描述,就不要想同时读取到内存块上的两个值,所以访问同一块内存的操作只能在GPU上串行执行,从而导致读取延迟。为了达到最优性能,我们要尽可能避免冲突。有个十分有用的技巧是进行简单的填充地址,就如图8.15所示。为了偏移地址(以内存块大小对齐),甚至可以改内存访问的跨度。不过,对地址操作的开销要比内存块冲突严重的大多;因此,我们要在具体的架构上进行调试。
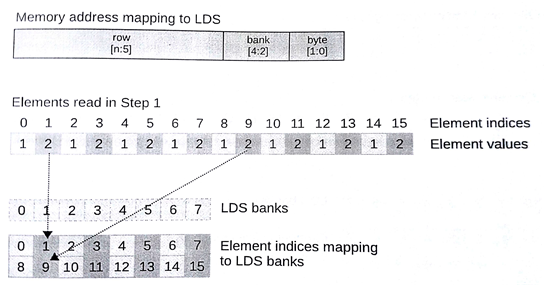
图8.14 图8.13中的第一步,LDS上具有8个内存块
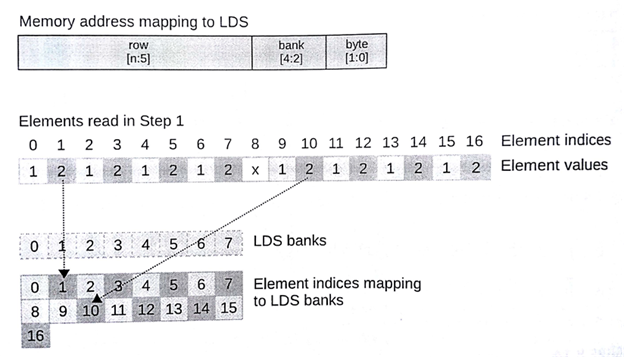
图8.15 图8.14中的第一步,为了避免LDS中的内存块访问冲突,则去访问下个内存块的数据
局部内存的大小是固定的。任何OpenCL设备都具有一段暂存式内存,这块内存大小有限,且不归硬件管理。Radeon R9 290X GPU式例中,其局部空间大小为64KB。要注意的是这64KB是所有工作组一共可以使用的共享内存。因为GPU是用多线程提高吞吐量,从而掩盖访存的延迟。如果每个工作组使用16KB,那么每个核上只能运行4个工作组。如果几个波面阵(一个或两个)中包含有几个工作组,那么这样就刚好能够掩盖访问延迟。虽然局部内存能提升应用性能,不过局部内存大小有限。因此,我们需要在使用局部内存和减少硬件线程方面进行平衡。
OpenCL运行时API也支持查询对应设备上局部内存的大小。在编程者编译或暂存局部内存数据时,其可以作为OpenCL内核参数。下面代码第一个调用,是用来查询局部内存类型,其可以用来判断哪些内存属于局部内存或全局内存(哪些是可以缓存或不能缓存的),第二个调用时用来返回局部内存的大小:
cl_int err;cl_device_local_mem_type type;err = clGetDeviceInfo(deviceId,CL_DEVICE_LOCAL_MEM_TYPE,sizeof(cl_device_local_mem_type),&type,0);cl_ulong size;err = clGetDeviceInfo(deviceId,CL_DEVICE_LOCAL_MEM_SIZE,sizeof(cl_ulong),&size,0);
[4] Advanced Micro Device, The AMD Accelerated Paralel Processing-OpenCL Programming Guide, Advanced Micro Devices, Inc,. Sunnyvale, CA, 2012.
[5] NVIDIA, CUDA C Programming Guide, NVIDIA Corporation, Santa Clara, CA, 2012.

若有收获,就点个赞吧
0 人点赞
