5.5 设备端排队
OpenCL 2.x版本之前的标准,只允许命令从主机端入队。OpenCL 2.0去除了这个限制,并定义了设备端的命令队列,其允许父内核直接将子内核入队。
设备端任务队列的好处是启用了嵌套并行机制(nested parallelism)——一个并行程序中的某个线程,再去开启多个线程[1]。嵌套并行机制常用于不确定内部某个算法要使用多少个线程的应用中。与单独使用分叉-连接(fork-join)机制相比,嵌套并行机制中产生的线程会在其任务完成后销毁。这两种机制的区别如图5.7所示:
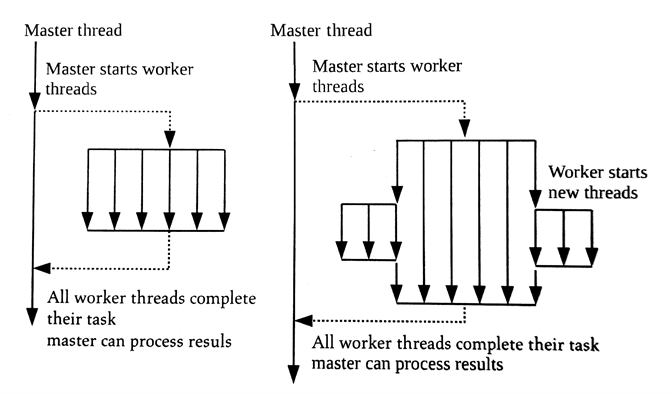
图5.7 单独的”分叉-链接”的结果与嵌套并行机制的线程分布对比
单独调用的方式,执行完任务后,线程的生命周期就结束了。嵌套并行将会在任务执行中间产生更多的线程,并在某个子任务完成后结束线程。
嵌套循环适用于不规则或数据驱动的循环结构。数据驱动型算法有很多,这里用一个比较常见的算法作为例子:广度优先搜索算法(BFS)。广度优先搜索算法从图中的根节点开始访问其相邻的节点。之后,访问到的节点,继续访问其附近的节点,直到所有节点都访问到。当BFS算法并行时,被访问的新顶点不知道应用何时开启。设备端入队允许开发者使用OpenCL内核实现嵌套并行,这样的方式要比在主机端入队合适的多。
总结一下设备端入队的好处:
- 内核可以在设备端直接入队。这样就不需要同步,或与主机的交互,并且会隐式的减少数据传输
- 更加自然的表达算法。当算法包括递归,不规则循环结构,或其他单层并行是固定不均匀的,现在都可以在OpenCL中完美的实现
- 更细粒度的并行调度,以及动态负载平衡。设备能更好的相应数据驱动决策,以及适应动态负载
为了让子内核入队,内核对象需要调用一个OpenCL C内置函数enqueue_kernel()。这里需要注意的是,每个调用该内置函数的工作项都会入队一个子内核。该内置函数的声明如下:
intenqueue_kernel(queue_t queue,kernel_enqueue_flags_t flags,const ndrange_t ndrange,void (^block)(void))
和主机端的API一样,其也需要传递一个命令队列。flags参数用来执行子内核何时开始执行。该参数有三个语义可以选择:
- CLK_ENQUEUE_FLAGS_NO_WAIT:子内核立刻执行
- CLK_ENQUEUE_FLAGS_WAIT_KERNEL:子内核需要等到父内核到到ENDED点时执行。这就意味着子内核在设备上运行时,父内核已经执行完成
- CLK_ENQUEUE_FLAGS_WAIT_WORK_GROUP:子内核必须要等到入队的工作组执行完成后,才能执行。
需要注意的是,父内核可能不会等到子内核执行结束。一个父内核的执行状态为”完成”时,意味着其本身和其子内核都完成。如果父子内核正确无误的执行完成,那么父内核会置为CL_COMPLETE。如果有子内核的程序计数器错误,或非正常终止,父内核的状态会置为一个错误值(一个给定的负值)。
与clEnqueueNDRangeKernel()类似,enqueue_kernel()也需要使用NDRange来指定维度信息(传递给ndrange参数)。与主机端调用一样,全局偏移和工作组数量是可选的。这时需要在内核上创建ndrange_t类型的对象来执行执行单元的配置,这里使用到了一组内置函数:
ndrange_t ndrange_<N>D(const size_t global_work_size[<N>])ndrange_t ndrange_<N>D(const size_t global_work_size[<N>], const size_t global_work_size[<N>])ndrange_t ndrange_<N>D(const size_t global_work_size[<N>], const size_t global_work_size[<N>], const size_t local_work_size_[<N>])
其中<N>可为1,2和3。例如,创建一个二维的800x600的NDRange可以使用如下方式:
size_t globalSize[2] = {800, 600};ndrange_t myNdrange = ndrange_2D(globalSize);
最终,enqueue_kernel()的最后一个参数block,其为指定入队的内核。这里指定内核的方式称为“Clang块”。下面两节中将会更加详细的对“如何利用设备入队”进行讨论,以及如何使用块语法指定一个嵌套内核。
如主机端API一样,enqueue_kernel()会返回一个整数,代表其执行是否成功。返回CLK_SUCCESS为成功,返回CLK_ENQUEUE_FAILURE则为失败。编程者想要了解失败入队的更多原因的话,需要在clBuildProgram()传入”-g”参数,或是clCompileProgram()调用会启用细粒度错误报告,会有更加具体的错误码返回,例如:CLK_INVALID_NDRANGE或CLK_DEVICE_QUEUE_FULL。
5.5.1 创建一个设备端队列
设备端队列也需要使用clCreateCommandQueueWithProperties()在主机端进行创建。为了表明是为了设备端创建的命令队列,properties中需要传入CL_QUEUE_ON_DEVICE。另外,当一个设备端队列创建之后,标准要求CL_QUEUE_OUT_OF_ORDER_EXEC_MODE_ENABEL也要传入(使用乱序方式),OpenCL 2.0中设备端队列被定义为乱序队列。这时命令队列可以通过内核的参数传入内核内,其对应的就是内核中的queue_t类型。代码清单5.9中,展示了一个带有队列参数的内核。
{%ace edit=false, lang=’c_cpp’%} // ——————————————- // Relevant host program // ——————————————-
// Specify the queue properties cl_command_queue_properties properties = CL_QUEUE_ON_DEVICE | CL_QUEUE_OUT_OF_ORDER_EXEC_MODE_ENABLE;
// Create the device-side command-queue cl_command_queue device_queue; device_queue = clCreateCommandQueueWithProperties( context, device, &proerties, NULL);
…
clSetKernelArg(kernel, 0, sizeof(cl_command),&device_queue);
…
// ——————————————- // Kernel // ——————————————-
__kernel void foo(queue_t myQueue, …){ … } {%endace%}
程序清单5.9 将设备端队列作为参数设置到内核中
有另外一个可选的配置,CL_QUEUE_ON_DEVICE_DEFAULT可传入clCreateCommandQueueWithProperties中,这样产生的队列默认为设备端可用队列。对于编程者来说,这样简化了许多工作,因为默认队列就可以在相关的内核使用内置函数,所以就不需要再将命令队列作为参数传入内核中了(可以通过内置函数get_default_queue()获取队列对象)。
5.5.2 入队设备端内核
当使用主机端API(clEnqueueNDRangeKernel())入队内核执行命令之前,需要对内核进行参数的设置。设备端使用enqueue_kernel()将内核命令入队前,是没有设置参数的过程。不过,内核的参数还是要设置,那该如何是好呢?为了正确的执行内核,OpenCL选择使用Clang块语法进行参数设置。
Clang块在OpenCL标准中,作为一种方式对内核进行封装,并且Clang块可以进行参数设置,能让子内核顺利入队。Clang块是一种传递代码和作用域的方法。其语法与闭包函数和匿名函数类似。块类型使用到一个结果类型和一系列参数类型(类似lambda表达式)。这种语法让“块”看起来更像是一个函数类型声明。“^”操作用来声明一个块变量(block variable)(该块用来引用内核),或是用来表明作用域的开始(使用内核代码直接进行声明)。
代码清单5.10中的简单例子,用来表明块语法的使用方式。
{%ace edit=false, lang=’c_cpp’%} __kerenl void child0_kernel(){ printf(“Child0: Hello, world!\n”); }
void child1_kernel(){ printf(“Child1: Hello, world!\n”); }
__kernel void parent_kernel(){ kernel_enqueue_flags_t child_flags = CLK_ENQUEUE_FLAGS_NO_WAIT; ndrange_t child_ndrange = ndrange_1D(1);
// Enqueue the child kernel by creating a block variable enqueue_kernel(get_default_queue(), child_flags, child_ndrange, ^{child0_kernel();});
// Create block variable void (^child1_kernel_block)(void) = ^{child1_kernel()};
// Enqueue kernel from block variable enqueue_kernel(get_default_queue(), child_flags. child_ndrange, child1_kernel_block);
// Enqueue kernel from a block literal // The block literal is bound by “^{“ and “}” enqueue_kernel(get_default_queue(), child_flags, child_ndrange, ^{printf(“Child2: Hello, world!\n”);}); } {%endace%}
代码清单5.10 一个用来展示Clang块语法是如何使用的例子
代码清单5.10中展示了三种设备端入队的方式。不过,这里的内核都没有参数。块语法是支持传递参数的。这里将第3章的向量相加的内核借用过来:
__kernelvoid vecadd(__global int *A,__global int *B,__global int *C){int idx = get_global_id(0);C[idx] = A[idx] + B[idx];}
可以用这个内核来进行参数传递,我们可以将这个内核作为一个子内核进行入队。程序清单5.11中展示了如何使用块变量进行参数传递,程序清单5.12中使用了块函数进行参数传递。注意程序清单5.11中的参数传递有些类似于标准函数的调用。不过,当我们使用块函数的方式时,不需要显式的传递参数。编译器会为作用域创建一个新的函数域。全局变量可以使用绑定的方式,私有和局部数据就必须进行拷贝了。注意指向私有或局部地址的指针是非法的,因为当程序运行到工作组或工作项之外时,这些指针就会失效。不过,OpenCL也支持为子内核开辟局部内存,我们将会在后面讨论这种机制。因为内核函数总是返回void,声明块时不需要显式的定义。
{%ace edit=false, lang=’c_cpp’%} kernel void child_vecadd( global int A, __global int B, __global int *C){
int idx = get_gloabl_id(0);
C[idx] = A[idx] + B[idx]; }
kernel void parent_vecadd( global int A, __global int B, __global int *C){
kernel_enqueue_flags_t child_flags = CLK_ENQUEUE_FLAGS_NO_WAIT; ndrange_t child_ndrange = ndrange_1D(get_global_size(0));
// Only enqueue one child kernel if (get_global_id(0) == 0){
enqueue_kerenl(get_default_queueu(),child_flags,child_ndrange,^{child_vecadd(A, B, C);}); // Pass arguments to child
} } {%endace%}
代码清单5.11 使用块语法传递参数
{%ace edit=false, lang=’c_cpp’%} kernel void parent_vecadd( global int A, __global int B, __global int *C){
kernel_enqueue_flags_t child_flags = CLK_ENQUEUE_FLAGS_NO_WAIT; ndrange_t child_ndrange = ndrange_1D(get_global_size(0));
// Only enqueue one child kernel if (get_global_id(0) == 0){
// Enqueue kernel from block literalenqueue_kerenl(get_default_queueu(),child_flags,child_ndrange,^{int idx = get_global_id(0);C[idx] = A[idx] + B[idx];});
} } {%endace%}
代码清单5.12 使用作用域的方式
动态局部内存
使用主机端API设置内核参数,需要动态分配局部内存时,只需要使用clSetKernelArg()向内核该参数传递为NULL就好。设备端没有类似的设置参数的机制,enqueue_kernel()有重载的函数:
intenqueue_kerenl(queue_t queue,kernel_enqueue_flags_t flags,const ndrange_t ndrange,void (^block)(local void *, ...),uint size0, ...)
该函数可用来创建局部内存指针,标准中块可以是一个可变长参数的表达式(一个可以接受可变长参数的函数)。其中每个参数的类型必须是local void *。注意,声明中,函数列表可以被void类型替代。enqueue_kernel()函数同样也是可变长的,末尾提供的数值是用来表示每个局部素组的大小。代码清单5.13对向量相加的例子进行修改,用来展示如何使用块语法,进行动态局部内存的分配。
{%ace edit=false, lang=’c_cpp’%} // When a kernel has been defined like this, then it can be // enqueued from the host as well as from the device kernel void child_vecadd( global int A, __global int B, global int *C, local int localA, __local int localB, __local int *localC){
int idex = get_global_id(0); int local_idx = get_local_id(0);
local_A[local_idx] = A[idx]; local_B[local_idx] = B[idx]; local_C[local_idx] = local_A[local_idx] + local_B[local_idx]; C[idx] = local_C[local_idx]; }
kernel void parent_vecadd( global int A, __global int B, __global int *C){
kernel_enqueue_flags_t child_flags = CLK_ENQUEUE_FLAGS_NO_WAIT; ndrange_t child_ndrange = ndrange_1D(get_global_size(0));
int local_A_mem_size = sizeof(int) 1; int local_B_mem_size = sizeof(int) 1; int local_C_mem_size = sizeof(int) * 1;
// Define a block with local memeory for each // local memory argument of the kernel void (^child_vecadd_blk)( local int , local int , local int ) = ^(local int local_A, local int local_B, local int local_C){
child_vecadd(A, B, C, local_A, local_B, local_C);};
// Only enqueue one child kernel if (get_global_id(0) == 0){ // Variadic enqueue_kernel function takes in local // memory size of each argument in block enqueue_kernel( get_default_queue(), child_flags, child_ndrange, child_vecadd_blk, local_A_mem_size, local_B_mem_size, lcoal_C_mem_size); } } {%endace%}
代码清单5.13 如何动态的为子内核动态分配局部内存
使用事件强制依赖
介绍设备端命令队列时就曾说过,设备端命令队列可以乱序的执行命令。这就暗示着设备端需要提供严格的依赖顺序。在主机端将内核直接入队,事件对象可以很好的指定依赖顺序。这里再次提供一个enqueue_kernel()的另一个重载版本。
intenqueue_kenrel(queue_t queue,kernel_enqueue_flags_t flags,const ndrange_t ndrange,uint num_events_in_wait_list,const clk_event_t *event_wait_list,clk_event_t *event_ret,void (^block)(void))
读者需要注意的是增加的三个参数:num_events_in_wait_list,event_wait_list和event_ret。与主机端API中事件相关的参数用法一样。
事件版本当然也有局部内存的重载版本:
intenqueue_kenrel(queue_t queue,kernel_enqueue_flags_t flags,const ndrange_t ndrange,uint num_events_in_wait_list,const clk_event_t *event_wait_list,clk_event_t *event_ret,void (^block)(local void *, ...),uint size0, ...)
{%ace edit=false, lang=’c_cpp’%} __kernel void child0_kernel(){ printf(“Child0: I will run first.\n”); }
__kernel void child1_kernel(){ printf(“Child1: I will run second.\n”); }
__kernel void parent_kernel(){ kernel_enqueue_flags_t child_flags = CLK_ENQUEUE_FLAGS_NO_WAIT; ndrange_t child_ndrange = ndrange_1D(1);
clk_event event;
// Enqueue a kernel and initialize an event enqueue_kernel( get_default_queue(), child_flags, child_ndrange, 0, NULL, &event, ^{child0_kernel();});
// Pass the event as a dependency between the kernels enqueue_kernel( get_default_queue(), child_flags, child_ndrange, 1, &event, NULL, ^{child1_kernel();});
// Release the event. In this case, the event will be released // after the dependency is satisfied // (second kernel is ready to execute) release_event(event); } {%endace%}
代码清单5.14 设备端入队时使用事件指定依赖关系
[1] J.Reinders. Intel Threading Building Blocks: Outfiting C++ for Multi-Core Processor Parallelism. O’Reilly Media, Inc., Sebastopol. 2007.

若有收获,就点个赞吧
0 人点赞
