10.3.3. 缩放点积注意力
使用点积可以得到计算效率更高的评分函数。
但是点积操作要求查询和键具有相同的长度 d。
假设查询和键的所有元素都是独立的随机变量,
并且都满足均值为 0,和方差为 1。
那么两个向量的点积的均值为 0,方差为 d。
为确保无论向量长度如何,
点积的方差在不考虑向量长度的情况下仍然是 1,
则可以使用 缩放点积注意力(scaled dot-product attention) 评分函数:

将点积除以 。在实践中,
。在实践中,
我们通常从小批量的角度来考虑提高效率,
例如基于 n 个查询和 m个键-值对计算注意力,
其中查询和键的长度为 d,值的长度为 v。
查询  、键
、键  和值
和值  的缩放点积注意力是
的缩放点积注意力是

在下面的缩放点积注意力的实现中,我们使用了 dropout 进行模型正则化。
class DotProductAttention(nn.Module):"""缩放点积注意力"""def __init__(self, dropout, **kwargs):super(DotProductAttention, self).__init__(**kwargs)self.dropout = nn.Dropout(dropout)# `queries` 的形状:(`batch_size`, 查询的个数, `d`)# `keys` 的形状:(`batch_size`, “键-值”对的个数, `d`)# `values` 的形状:(`batch_size`, “键-值”对的个数, 值的维度)# `valid_lens` 的形状: (`batch_size`,) 或者 (`batch_size`, 查询的个数)def forward(self, queries, keys, values, valid_lens=None):d = queries.shape[-1]# 设置 `transpose_b=True` 为了交换 `keys` 的最后两个维度scores = torch.bmm(queries, keys.transpose(1,2)) / math.sqrt(d)self.attention_weights = masked_softmax(scores, valid_lens)return torch.bmm(self.dropout(self.attention_weights), values)
queries = torch.normal(0, 1, (2, 1, 2))attention = DotProductAttention(dropout=0.5)attention.eval()attention(queries, keys, values, valid_lens)
tensor([[[ 2.0000, 3.0000, 4.0000, 5.0000]],[[10.0000, 11.0000, 12.0000, 13.0000]]])
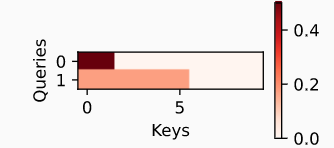
d2l.show_heatmaps(attention.attention_weights.reshape((1, 1, 2, 10)),xlabel='Keys', ylabel='Queries')

若有收获,就点个赞吧
0 人点赞
