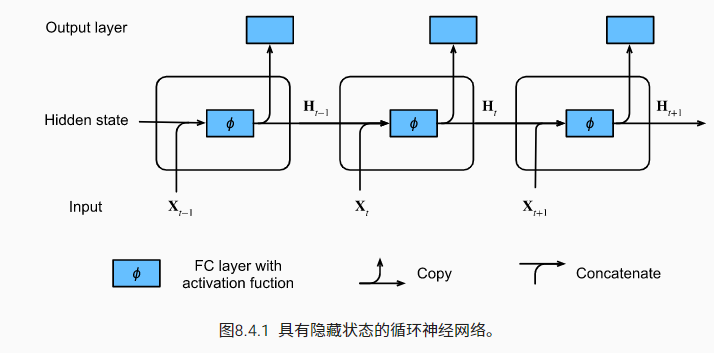

实现
读取一个小说
%matplotlib inlineimport mathimport torchfrom torch import nnfrom torch.nn import functional as Ffrom d2l import torch as d2lbatch_size, num_steps = 32, 35train_iter, vocab = d2l.load_data_time_machine(batch_size, num_steps)
独热编码 词典长度为28
返回0,和2 的独热编码
F.one_hot(torch.tensor([0, 2]), len(vocab))
tensor([[1, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,0, 0, 0, 0],[0, 0, 1, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,0, 0, 0, 0]])
for X, Y in train_iter:print('X: ', X, '\nY:', Y)
X: tensor([[13, 2, 1, ..., 1, 3, 10],[ 1, 3, 9, ..., 8, 2, 11],[ 1, 12, 2, ..., 4, 25, 5],...,[ 6, 26, 14, ..., 3, 21, 2],[ 3, 4, 12, ..., 1, 21, 2],[ 9, 4, 6, ..., 11, 1, 8]])Y: tensor([[ 2, 1, 13, ..., 3, 10, 4],[ 3, 9, 2, ..., 2, 11, 1],[12, 2, 4, ..., 25, 5, 12],...,[26, 14, 10, ..., 21, 2, 16],[ 4, 12, 12, ..., 21, 2, 1],[ 4, 6, 5, ..., 1, 8, 4]])X: tensor([[ 4, 22, 2, ..., 5, 2, 6],[ 1, 5, 6, ..., 1, 9, 5],[12, 19, 4, ..., 9, 5, 8],...,[16, 7, 10, ..., 1, 3, 9],[ 1, 2, 24, ..., 6, 12, 2],[ 4, 3, 1, ..., 1, 3, 9]])Y: tensor([[22, 2, 12, ..., 2, 6, 3],[ 5, 6, 1, ..., 9, 5, 8],[19, 4, 11, ..., 5, 8, 1],...,[ 7, 10, 2, ..., 3, 9, 2],[ 2, 24, 20, ..., 12, 2, 8],[ 3, 1, 11, ..., 3, 9, 2]])X: tensor([[ 3, 1, 3, ..., 4, 1, 10],[ 8, 1, 20, ..., 8, 1, 10],[ 1, 6, 2, ..., 1, 9, 5],...,[ 2, 1, 3, ..., 12, 21, 19],[ 8, 8, 1, ..., 20, 3, 2],[ 2, 3, 4, ..., 9, 2, 1]])Y: tensor([[ 1, 3, 7, ..., 1, 10, 2],[ 1, 20, 4, ..., 1, 10, 4],[ 6, 2, 17, ..., 9, 5, 8],...,[ 1, 3, 5, ..., 21, 19, 1],[ 8, 1, 9, ..., 3, 2, 11],[ 3, 4, 21, ..., 2, 1, 21]])X: tensor([[ 2, 15, 7, ..., 19, 2, 8],[ 4, 3, 9, ..., 20, 7, 6],[ 8, 1, 16, ..., 10, 2, 16],...,[ 1, 8, 1, ..., 9, 2, 1],[11, 1, 5, ..., 3, 9, 5],[21, 10, 5, ..., 9, 2, 1]])Y: tensor([[15, 7, 6, ..., 2, 8, 1],[ 3, 9, 2, ..., 7, 6, 1],[ 1, 16, 2, ..., 2, 16, 14],...,[ 8, 1, 4, ..., 2, 1, 3],[ 1, 5, 8, ..., 9, 5, 6],[10, 5, 18, ..., 2, 1, 13]])X: tensor([[ 1, 8, 9, ..., 12, 19, 1],[ 1, 4, 6, ..., 2, 10, 1],[14, 12, 12, ..., 7, 6, 2],...,[ 3, 5, 13, ..., 17, 4, 8],[ 6, 18, 1, ..., 18, 7, 6],[13, 7, 11, ..., 11, 7, 25]])Y: tensor([[ 8, 9, 7, ..., 19, 1, 20],[ 4, 6, 11, ..., 10, 1, 11],[12, 12, 19, ..., 6, 2, 1],...,[ 5, 13, 2, ..., 4, 8, 1],[18, 1, 9, ..., 7, 6, 4],[ 7, 11, 2, ..., 7, 25, 2]])X: tensor([[20, 4, 12, ..., 2, 11, 1],[11, 5, 6, ..., 7, 4, 13],[ 1, 7, 10, ..., 22, 2, 10],...,[ 1, 4, 1, ..., 8, 15, 4],[ 4, 12, 1, ..., 14, 3, 1],[ 2, 6, 1, ..., 11, 12, 2]])Y: tensor([[ 4, 12, 2, ..., 11, 1, 3],[ 5, 6, 6, ..., 4, 13, 8],[ 7, 10, 1, ..., 2, 10, 8],...,[ 4, 1, 18, ..., 15, 4, 10],[12, 1, 3, ..., 3, 1, 3],[ 6, 1, 15, ..., 12, 2, 8]])X: tensor([[ 3, 9, 2, ..., 8, 7, 16],[ 8, 1, 18, ..., 1, 7, 16],[ 8, 4, 12, ..., 6, 8, 3],...,[10, 15, 2, ..., 4, 6, 11],[ 3, 9, 2, ..., 3, 9, 2],[ 8, 3, 5, ..., 4, 12, 1]])Y: tensor([[ 9, 2, 16, ..., 7, 16, 3],[ 1, 18, 10, ..., 7, 16, 1],[ 4, 12, 12, ..., 8, 3, 4],...,[15, 2, 12, ..., 6, 11, 1],[ 9, 2, 1, ..., 9, 2, 1],[ 3, 5, 15, ..., 12, 1, 5]])X: tensor([[ 3, 1, 10, ..., 18, 9, 3],[ 1, 20, 10, ..., 6, 1, 3],[ 4, 6, 15, ..., 8, 1, 16],...,[ 1, 22, 2, ..., 22, 7, 10],[ 1, 16, 5, ..., 10, 14, 18],[ 5, 6, 1, ..., 10, 5, 12]])Y: tensor([[ 1, 10, 4, ..., 9, 3, 8],[20, 10, 2, ..., 1, 3, 9],[ 6, 15, 2, ..., 1, 16, 7],...,[22, 2, 10, ..., 7, 10, 19],[16, 5, 10, ..., 14, 18, 1],[ 6, 1, 8, ..., 5, 12, 12]])
print(list(vocab.token_to_idx.items())[:])
[('<unk>', 0), (' ', 1), ('e', 2), ('t', 3), ('a', 4), ('i', 5), ('n', 6), ('o', 7), ('s', 8), ('h', 9), ('r', 10), ('d', 11), ('l', 12), ('m', 13), ('u', 14), ('c', 15), ('f', 16), ('w', 17), ('g', 18), ('y', 19), ('p', 20), ('b', 21), ('v', 22), ('k', 23), ('x', 24), ('z', 25), ('j', 26), ('q', 27)]
X = torch.arange(10).reshape((2, 5))
F.one_hot(X.T, 28).shape
torch.Size([5, 2, 28])
F.one_hot(X.T, 28)
tensor([[[1, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0],
[0, 0, 0, 0, 0, 1, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0]],
[[0, 1, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0],
[0, 0, 0, 0, 0, 0, 1, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0]],
[[0, 0, 1, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0],
[0, 0, 0, 0, 0, 0, 0, 1, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0]],
[[0, 0, 0, 1, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0],
[0, 0, 0, 0, 0, 0, 0, 0, 1, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0]],
[[0, 0, 0, 0, 1, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0],
[0, 0, 0, 0, 0, 0, 0, 0, 0, 1, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0]]])
torch.randn(*sizes, out=None) → Tensor
返回一个张量,包含了从标准正态分布(均值为0,方差为1,即高斯白噪声)中抽取的一组随机数。张量的形状由参数sizes定义。
def get_params(vocab_size, num_hiddens, device):
num_inputs = num_outputs = vocab_size
def normal(shape):
"""均值为0方差为0.01"""
return torch.randn(size=shape, device=device) * 0.01
# 隐藏层参数
W_xh = normal((num_inputs, num_hiddens))
W_hh = normal((num_hiddens, num_hiddens))
b_h = torch.zeros(num_hiddens, device=device)
# 输出层参数
W_hq = normal((num_hiddens, num_outputs))
b_q = torch.zeros(num_outputs, device=device)
# 附加梯度
params = [W_xh, W_hh, b_h, W_hq, b_q]
for param in params:
param.requires_grad_(True)
return params

def init_rnn_state(batch_size, num_hiddens, device):
return (torch.zeros((batch_size, num_hiddens), device=device), )
def rnn(inputs, state, params):
# `inputs`的形状:(`时间步数量`,`批量大小`,`词表大小`)
W_xh, W_hh, b_h, W_hq, b_q = params
H, = state
outputs = []
# `X`的形状:(`批量大小`,`词表大小`)
for X in inputs:
H = torch.tanh(torch.mm(X, W_xh) + torch.mm(H, W_hh) + b_h)
Y = torch.mm(H, W_hq) + b_q
outputs.append(Y)
return torch.cat(outputs, dim=0), (H,)
定义了所有需要的函数之后,接下来我们创建一个类来包装这些函数,并存储从零开始实现的循环神经网络模型的参数。
class RNNModelScratch:
"""从零开始实现的循环神经网络模型"""
def __init__(self, vocab_size, num_hiddens, device,
get_params, init_state, forward_fn):
self.vocab_size, self.num_hiddens = vocab_size, num_hiddens
self.params = get_params(vocab_size, num_hiddens, device)
self.init_state, self.forward_fn = init_state, forward_fn
def __call__(self, X, state):
X = F.one_hot(X.T, self.vocab_size).type(torch.float32)
return self.forward_fn(X, state, self.params)
def begin_state(self, batch_size, device):
return self.init_state(batch_size, self.num_hiddens, device)

若有收获,就点个赞吧
0 人点赞
