数据模型
ZooKeeper 的视图结构和标准的 Unix 文件系统非常类似,但没有引入传统文件系统中目录和文件等概念,而是使用了其特有的数据节点概念,我们称之为 ZNode。ZNode 是 ZooKeeper 中数据的最小单元,每个 ZNode 上都可以保存数据,同时还可以挂载子节点,因此构成了一个层次化的命名空间,我们称之为树。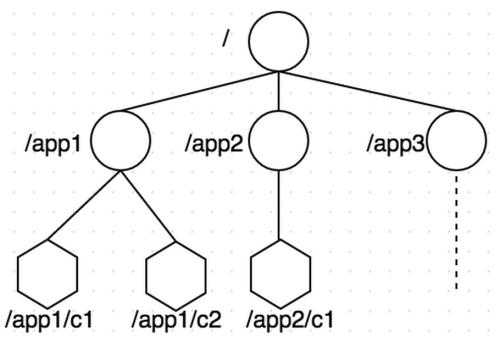
在 ZooKeeper 中,每一个数据节点都被称为一个 ZNode,所有 ZNode 按层次化结构组织成一棵树。ZNode 的节点路径标识方式和 Unix 文件系统路径非常相似,都是由一系列使用斜杠(/)进行分割的路径表示,我们可以向这个节点中写入数据,也可以在节点下创建子节点。
对于每一个事务请求,ZooKeeper 都会为其分配一个全局唯一的事务 ID,用 ZXID 来表示,通常是一个 64 位的数字。每一个 ZXID 对应一次更新操作,从 ZXID 中可以间接识别出 ZooKeeper 处理这些更新操作请求的全局顺序。
节点特性
1. 节点类型
在 ZooKeeper 中,每个数据节点都是有生命周期的,其生命周期的长短取决于数据节点的节点类型。在 ZooKeeper 中,节点类型可以分为持久节点(PERSISTENT)、临时节点(EPHEMERAL)和顺序节点 (SEQUENTIAL)三大类,具体在节点创建过程中,通过组合使用,可生成以下四种节点类型:
PERSISTENTPERSISTENT_SEQUENTIALEPHEMERALEPHEMERAL_SEQUENTIAL
持久节点是 ZooKeeper 中最常见的一种节点类型。所谓持久节点,是指该数据节点被创建后,就会一直存在于 ZooKeeper 服务器上,直到有删除操作来主动清除这个节点。
临时节点的生命周期和客户端的会话绑定在一起,当客户端会话失效时该节点会自动被清理。注意,这里是指客户端会话失效,而非 TCP 连接断开。另外,ZooKeeper 规定了不能基于临时节点来创建子节点,即临时节点只能作为叶子节点。
顺序节点的特性表现在顺序性上,在 ZooKeeper 中,每个父节点都会为它的第一级子节点维护一份顺序,用于记录下每个子节点创建的先后顺序。基于这个顺序特性,在创建子节点的时候可以设置这个标记,那么在创建节点的过程中,ZooKeeper 会自动为给定节点名加上一个数字后缀,作为一个新的、完整的节点名。
2. 节点状态信息
实际上,每个数据节点除了存储了数据内容之外,还存储了数据节点本身的一些状态信息。Stat 类中包含了一个数据节点的所有状态信息。
public class Stat implements Record {
// 即 Created ZXID,表示该数据节点被创建时的事务 ID
private long czxid;
// 即 Modified ZXID,表示该节点最后一次被更新时的事务 ID
private long mzxid;
// 即 Created Time,表示节点被创建的时间
private long ctime;
// 即 Modified Time,表示该节点最后一次被更新的时间
private long mtime;
// 数据节点的版本号
private int version;
// 子节点的版本号
private int cversion;
// 节点的 ACL 版本号
private int aversion;
// 创建该临时节点的会话的 sessionID,如果该节点是持久节点,则该属性为 0
private long ephemeralOwner;
// 数据内容长度
private int dataLength;
// 当前节点的子节点个数
private int numChildren;
// 表示该节点的子节点列表最后一次被修改时的事务 ID,子节点内容修改不影响
private long pzxid;
}
版本
在 ZooKeeper 中为数据节点引入了版本的概念,每个数据节点都具有三种类型的版本信息,即上面提到的 version、cversion、aversion,对数据节点的任何更新操作都会引起版本号的变化,以此来保证在分布式环境下对数据的原子性操作。注意,ZooKeeper 中的版本强调的是变更次数,即使前后两次变更并没有使得数据内容的值发生变化,版本号依然会变。
实际上,在 ZooKeeper 中,version 属性正是用来实现乐观锁机制中的 “写入校验” 的。下面我们看下
ZooKeeper 的 setData 方法的内部实现。在 ZooKeeper 服务器的 PrepRequestProcessor 处理器类中,在处理每一个数据更新请求(SetDataRequest)前都会进行版本检查。
version = setDataRequest.getVersion();
currentVersion = nodeRecord.stat.getVersion();
// version为-1,说明客户端并不要求使用乐观锁,可以忽略版本比对
if (version != -1 && version != currentVersion) {
throw new BadVersionException(path);
}
version = currentVersion + 1;
Watcher
ZooKeeper 引入了 Watcher 机制来实现分布式的通知功能。ZooKeeper 允许客户端向服务端注册一个 Watcher 监听,当服务端的一些指定事件触发了这个 Watcher,那么就会向指定客户端发送一个事件通知来实现分布式的通知功能。Watcher 机制主要包括客户端线程、客户端 WatcherManager 和 ZooKeeper 服务器三部分。整个注册与通知过程如下图所示: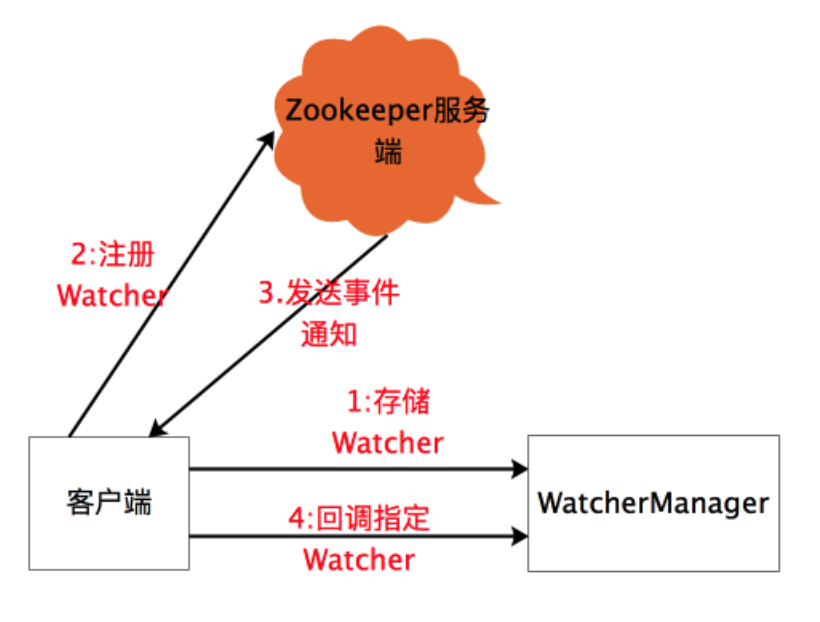
客户端在向 ZooKeeper 注册 Watcher 的同时,会将 Watcher 对象存储在客户端的 WatcherManager 中。当 ZooKeeper 服务器端触发 Watcher 事件向客户端发送通知时,客户端线程从 WatcherManager 中取出对应 Watcher 对象来执行回调。
public interface ClientWatchManager {
// 返回一组应该被通知的watcher
Set<Watcher> materialize(Watcher.Event.KeeperState state, Watcher.Event.EventType type, String path);
}
1. Watcher 接口
Watcher 接口定义了事件通知相关的逻辑,包含 KeeperState 和 EventType 两个枚举类,分别代表了通知状态和事件类型,同时定义了事件的回调方法 process(WatchedEvent event)。
1.1 Watcher 事件
同一个事件类型在不同的通知状态中代表的含义有所不同,下表列举了常见的通知状态和事件类型。
| KeeperState | EventType | 触发条件 | 说明 |
|---|---|---|---|
| SyncConnected | None | 客户端与服务器成功建立会话 | 此时客户端和服务器处于连接状态 |
| NodeCreated | Watcher 监听的对应数据节点被创建 | ||
| NodeDeleted | Watcher 监听的对应数据节点被删除 | ||
| NodeDataChanged | Watcher 监听的对应数据节点的数据内容发生变更 | ||
| NodeChildrenChanged | Watcher 监听的对应数据节点的子节点列表发生变更,子节点数据内容变化不会触发该事件 | ||
| Disconnected | None | 客户端与 ZooKeeper 服务器断开连接 | 此时客户端和服务器处于断开连接状态 |
| Expired | None | 会话超时 | 此时客户端会话失效 |
| AuthFailed | None | - 使用错误的 scheme 进行权限检查 - SASL 权限检查失败 |
通常会收到 AuthFailedException 异常 |
1.2 process 回调
process 方法是 Watcher 接口中的一个回调方法,当 ZooKeeper 向客户端发送一个 Watcher 事件通知时,客户端就会对相应的 process 方法进行回调,从而实现对事件的处理。process 方法定义如下:
void process(WatchedEvent event);
ZooKeeper 使用 WatchedEvent 对象来封装服务端事件并传递给 Watcher,从而方便回调方法 process 对服务端事件进行处理。其数据结构如下:
public class WatchedEvent {
final private KeeperState keeperState;
final private EventType eventType;
private String path;
}
服务端在生成 WatchedEvent 事件之后,会调用 getWrapper 方法将自己包装成一个可序列化的 WatcherEvent事件,以便通过网络传输到客户端。客户端在接收到服务端的这个事件对象后,首先会将 WatcherEvent 事件还原成一个 WatchedEvent 事件,并传递给 process 方法处理。
public WatcherEvent getWrapper() {
return new WatcherEvent(eventType.getIntValue(), keeperState.getIntValue(), path);
}
可以看到,无论是 WatcherEvent 还是 WatchedEvent,其对 ZooKeeper 服务端事件的封装都是极其简单的。因此,客户端无法直接从该事件中获取到对应数据节点到变化内容,需要客户端再次主动去重新获取数据。
2. 工作机制
2.1 客户端注册 Watcher
在创建一个 ZooKeeper 客户端对象实例时,可以向构造方法中传入一个 Watcher,这个 Watcher 将作为整个 ZooKeeper 会话期间的默认 Watcher,会一直被保存在客户端 ZKWatchManager 的 defaultWatcher 属性。另外,客户端也可以通过 getData、getChildren 和 exist 三个接口来向 ZooKeeper 注册 Watcher,无论使用哪种方式,注册 Watcher 的工作原理都是一致的。
下面,我们以 getData 方法为例,来分析下客户端注册 Watcher 的实现过程:
public byte[] getData(final String path, Watcher watcher, Stat stat)
1)封装 Watcher
客户端首先会对当前客户端请求 request 进行标记,将其设置为 “使用 Watcher 监听”,同时会封装一个 Watcher 的注册信息 WatchRegistration 对象,用于暂时保存数据节点的路径和 Watcher 的对应关系。
WatchRegistration wcb = null;
if (watcher != null) {
wcb = new DataWatchRegistration(watcher, clientPath);
}
......
// 该值用于服务端判断是否需要进行Watcher注册
request.setWatch(watcher != null);
// 放入发送队列中等待客户端发送
ReplyHeader r = cnxn.submitRequest(h, request, response, wcb);
2)发送 Watcher
在 ZooKeeper 中,Packet可以被看作是一个最小的通信协议单元,用于进行客户端与服务端之间的网络传输,任何需要传输的对象都需要包装成一个 Packet 对象。因此,在 ClientCnxn 中的 WatchRegistration 又会被封装到 Packet 中去,然后放入发送队列中等待客户端发送。
public ReplyHeader submitRequest(RequestHeader h, Record request,
Record response, WatchRegistration watchRegistration)
throws InterruptedException {
ReplyHeader r = new ReplyHeader();
Packet packet = queuePacket(h, r, request, response, null, null, null,
null, watchRegistration);
synchronized (packet) {
if (requestTimeout > 0) {
// Wait for request completion with timeout
waitForPacketFinish(r, packet);
} else {
// Wait for request completion infinitely
while (!packet.finished) {
packet.wait();
}
}
}
if (r.getErr() == Code.REQUESTTIMEOUT.intValue()) {
sendThread.cleanAndNotifyState();
}
return r;
}
3)等待响应
随后,ZooKeeper 客户端会向服务端发送这个请求,同时等待请求返回。完成请求发送后,会由客户端 SendThread 线程的 readResponse 方法负责接收来自服务端的响应,finishPacket 方法会从 Packet 中取出对应 Watcher 注册到 ZKWatchManager 中。
protected void finishPacket(Packet p) {
int err = p.replyHeader.getErr();
if (p.watchRegistration != null) {
p.watchRegistration.register(err);
}
......
}
public void register(int rc) {
if (shouldAddWatch(rc)) {
Map<String, Set<Watcher>> watches = getWatches(rc);
synchronized (watches) {
Set<Watcher> watchers = watches.get(clientPath);
if (watchers == null) {
watchers = new HashSet<Watcher>();
watches.put(clientPath, watchers);
}
watchers.add(watcher);
}
}
}
在 register 方法中,客户端会将之前暂时保存的 Watcher 对象转交给 ZKWatchManager 并最终保存到 datawatches 中去。ZKWatchManager.datawatches 是一个 Map
4)存在的问题
考虑到每调用一次 getData 方法就注册一个 Watcher,如果客户端注册的所有 Watcher 都被传递到服务端的话,那么服务端肯定会出现内存紧张或其他性能问题了。因此在 ZooKeeper 底层的网络传输序列化过程中,只会将 Packet 对象中的 requestHeader 和 request 两个属性进行序列化,而并没有将 WatchRegistration 序列化到底层字节数组中去。我们看下 Packet 的序列化过程:
public void createBB() {
try {
ByteArrayOutputStream baos = new ByteArrayOutputStream();
BinaryOutputArchive boa = BinaryOutputArchive.getArchive(baos);
boa.writeInt(-1, "len");
if (requestHeader != null) {
requestHeader.serialize(boa, "header");
}
if (request instanceof ConnectRequest) {
request.serialize(boa, "connect");
boa.writeBool(readOnly, "readOnly");
} else if (request != null) {
request.serialize(boa, "request");
}
......
} catch (IOException e) {
LOG.warn("Ignoring unexpected exception", e);
}
}
2.2 服务端处理 Watcher
1)ServerCnxn 存储
服务端收到来自客户端的请求之后,会在 FinalRequestProcessor 类中的 processRequest() 中判断当前请求是否需要注册 Watcher,当 getWatch() 为 true 时,ZooKeeper 就认为当前客户端请求需要进行 Watcher 注册,于是就会将当前的 ServerCnxn 对象和数据节点路径传入例如 getData 方法中去。
// 假设当前请求是getData请求,则会被路由到该分支
case OpCode.getData: {
GetDataRequest getDataRequest = new GetDataRequest();
// 反序列化request
ByteBufferInputStream.byteBuffer2Record(request.request, getDataRequest);
DataNode n = zks.getZKDatabase().getNode(getDataRequest.getPath());
......
Stat stat = new Stat();
byte b[] = zks.getZKDatabase().getData(getDataRequest.getPath(), stat,
getDataRequest.getWatch() ? cnxn : null);
rsp = new GetDataResponse(b, stat);
break;
}
ServerCnxn 是一个 ZooKeeper 客户端和服务器之间的连接接口,代表了一个客户端和服务器的连接。这个类实现了 Watcher 接口。数据节点路径和 ServerCnxn 会被存储在 DataTree 的 dataWatches 中。
public class DataTree {
private final WatchManager dataWatches = new WatchManager();
......
}
dataWatches 是 WatchManager 类的一个实例,最终数据会保存在 WatchManager 的 watchTable 和 watch2Paths 中。WatchManager 是 ZooKeeper 服务端 Watcher 的管理者,负责事件的触发,并移除那些已经被触发的 Watcher。
public class WatchManager {
// 从数据节点的粒度来托管Watcher
private final HashMap<String, HashSet<Watcher>> watchTable = new HashMap<>();
// 从Watcher的粒度来控制事件触发需要触发的数据节点
private final HashMap<Watcher, HashSet<String>> watch2Paths = new HashMap<>();
}
2)Watcher 触发
比如 NodeDataChanged 事件的触发条件是 “Watcher 监听的节点的数据内容发生变更”,具体实现如下:
public Stat setData(String path, byte data[], int version, long zxid, long time) throws KeeperException.NoNodeException {
Stat s = new Stat();
DataNode n = nodes.get(path);
byte lastdata[] = null;
synchronized (n) {
lastdata = n.data;
n.data = data;
n.stat.setMtime(time);
n.stat.setMzxid(zxid);
n.stat.setVersion(version);
n.copyStat(s);
}
......
dataWatches.triggerWatch(path, EventType.NodeDataChanged);
return s;
}
在对指定节点进行数据更新后,通过调用 WatchManager 的 triggerWatch 方法来触发相关事件。
public Set<Watcher> triggerWatch(String path, EventType type, Set<Watcher> supress) {
WatchedEvent e = new WatchedEvent(type, KeeperState.SyncConnected, path);
HashSet<Watcher> watchers;
synchronized (this) {
watchers = watchTable.remove(path);
if (watchers == null || watchers.isEmpty()) {
return null;
}
for (Watcher w : watchers) {
HashSet<String> paths = watch2Paths.get(w);
if (paths != null) {
paths.remove(path);
}
}
}
for (Watcher w : watchers) {
if (supress != null && supress.contains(w)) {
continue;
}
w.process(e);
}
return watchers;
}
- 首先将通知状态、事件类型以及节点路径封装成一个 WatchedEvent 对象。
- 根据节点路径从 watchTable 中取出对应的 Watcher。如果没有找到 Watcher,说明没有任何客户端在该节点上注册过 Watcher,直接返回。如果找到了会将其提取出来,并从 watchTable 和 watch2Paths 中将其删除——从这里我们可以看出,Watcher 在服务端是一次性的。
- 调用 process 方法来触发 Watcher,这里调用的 process 实际上就是 ServerCnxn 的对应方法。
- 该 process 内部将 WatchedEvent 包装成 WatcherEvent,同时向客户端发送该通知。
synchronized public void process(WatchedEvent event) {
// 标记XID为-1,代表这是一个通知类型的响应
ReplyHeader h = new ReplyHeader(-1, -1L, 0);
WatcherEvent e = event.getWrapper();
sendResponse(h, e, "notification");
}
2.3 客户端回调 Watcher
1)SendThread 接收事件通知
对于一个来自服务端的响应,客户端都是由 SendThread 的 readResponse() 方法来统一进行处理的。
void readResponse(ByteBuffer incomingBuffer) throws IOException {
ByteBufferInputStream bbis = new ByteBufferInputStream(incomingBuffer);
BinaryInputArchive bbia = BinaryInputArchive.getArchive(bbis);
ReplyHeader replyHdr = new ReplyHeader();
// 反序列化
replyHdr.deserialize(bbia, "header");
if (replyHdr.getXid() == -1) {
WatcherEvent event = new WatcherEvent();
event.deserialize(bbia, "response");
if (chrootPath != null) {
String serverPath = event.getPath();
if(serverPath.compareTo(chrootPath)==0)
event.setPath("/");
else if (serverPath.length() > chrootPath.length())
event.setPath(serverPath.substring(chrootPath.length()));
}
WatchedEvent we = new WatchedEvent(event);
eventThread.queueEvent(we);
return;
}
......
}
如果响应头 replyHdr 中标识了 XID 为 -1,表明这是一个通知类型的响应,对其的处理大体分四个步骤:
- 反序列化为 WatcherEvent 对象。
- 处理 chrootPath,如果客户端设置了 chrootPath 属性,那么需要对服务端传过来的完整的节点路径进行 chrootPath 处理,生成客户端的一个相对节点路径。
- 还原 WatchedEvent。
- 回调 Watcher,将 WatchedEvent 对象交给 EventThread 线程,在下一个轮询周期中进行回调。
2)EventThread 处理事件通知
服务端的 Watcher 事件通知,最终交给了 EventThread 线程来处理。EventThread 线程是 ZooKeeper 客户端中专门用来处理服务端通知事件的线程,SendThread 接收到服务端的事件通知后,会调用 EventThread 的 queueEvent 方法来将事件传给 EventThread 线程,其逻辑如下:
public void queueEvent(WatchedEvent event) {
if (event.getType() == EventType.None && sessionState == event.getState()) {
return;
}
sessionState = event.getState();
WatcherSetEventPair pair = new WatcherSetEventPair(
watcher.materialize(event.getState(), event.getType(),
event.getPath()), event);
waitingEvents.add(pair);
}
- materialize 方法用于从 ZKWatchManager 中取出所有相关类型的 Watcher。
- 获取到所有相关 Watcher 后,会将其放入 waitingEvents 队列中去,EventThread 的 run 方法会不断对该队列进行处理。
3. 特性
一次性:无论是服务端还是客户端,一旦一个 Watcher 被触发,ZooKeeper 都会将其从相应的存储中移除,这样的设计有效地减轻了服务端的压力。
客户端串行执行:客户端 Watcher 回调的过程是一个串行同步的过程,因此要注意不要因为一个 Watcher 的处理逻辑影响了整个客户端的回调。
轻量:Watcher 通知非常简单,只会告诉客户端发生了事件,而不会说明事件的具体内容。

若有收获,就点个赞吧
0 人点赞
