一个 InnoDB 表包含两部分:表结构定义和表数据。在 MySQL 8.0 版本以前,表结构是存在以 .frm 为后缀的文件里。而 MySQL 8.0 版本,则已经允许把表结构定义放在系统数据表中了。因为表结构定义占用的空间很小,所以我们主要讨论表数据。
innodb_file_per_table
表数据既可以存在共享表空间里,也可以是单独的文件。这个行为是由参数 innodb_file_per_table 控制的:
- 参数设置为 OFF 表示的是,表数据放在系统共享表空间,也就是跟数据字典放在一起。
- 参数设置为 ON 表示的是,每个 InnoDB 表数据存储在一个以 .ibd 为后缀的文件中。
从 MySQL 5.6.6 版本开始,它的默认值就是 ON 了。因为一个表单独存储为一个文件更容易管理,而且不需要这个表时,通过 drop table 命令,系统就会直接删除这个文件。而如果是放在共享表空间中,即使表删掉了,空间也是不会回收的。
我们在删除整个表时,可以使用 drop table 命令回收表空间。但我们遇到的更多的删除数据的场景是删除某些行数据,这时你可能会遇到:表中的数据被删除了,但是表空间却没有被回收。我们要彻底搞明白这个问题的话,就要从数据删除流程说起了。
数据删除流程
数据删除流程我们先来看一下 InnoDB 中一个索引的示意图。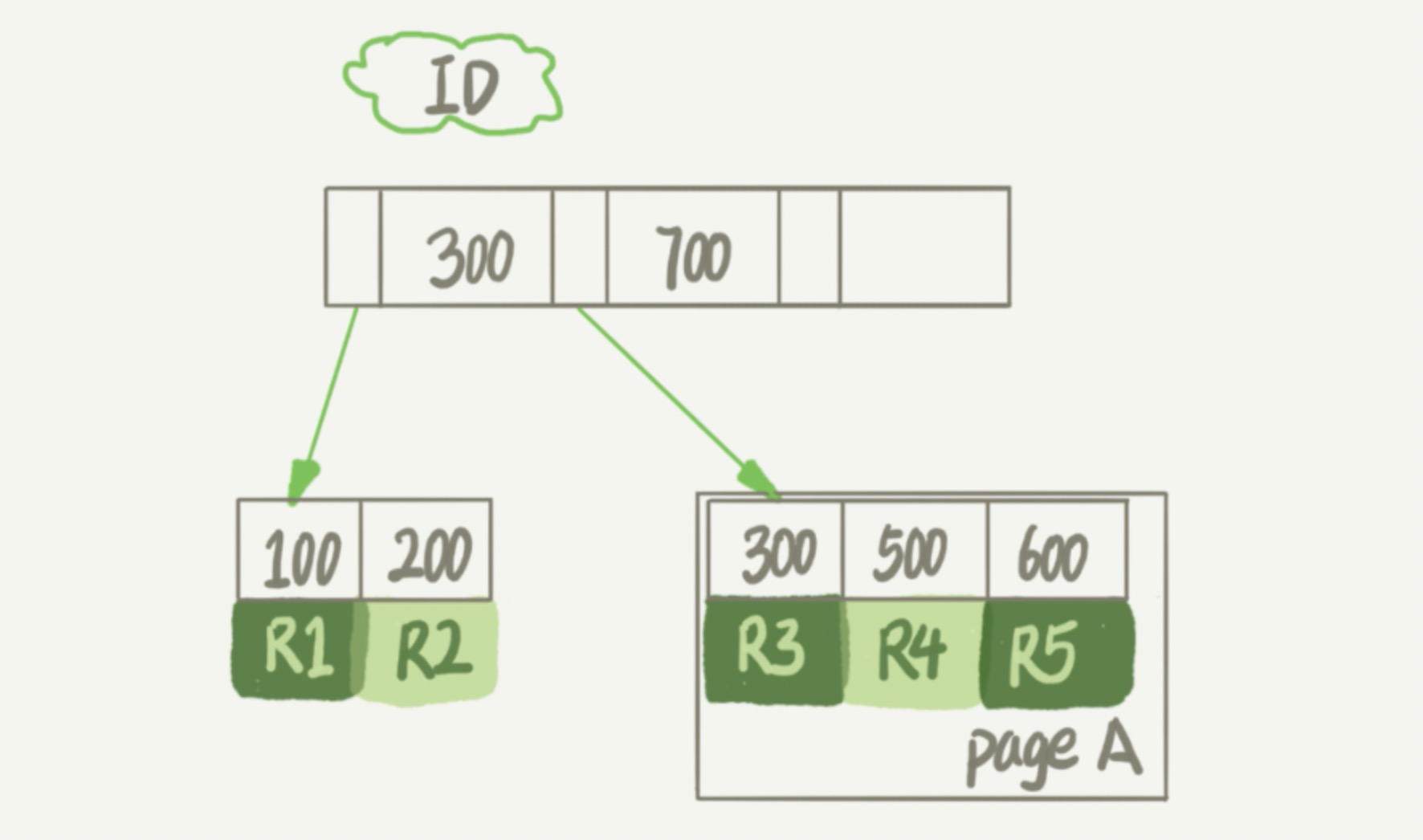
假设,我们要删掉 R4 这个记录,InnoDB 引擎只会把 R4 这个记录标记为删除(delete mark)。如果之后要再插入一个 ID 在 300 和 600 之间的记录时,可能会复用这个位置。但磁盘文件的大小并不会缩小。
由于 InnoDB 的数据是按页存储的,如果删掉一个数据页上的所有记录,那整个数据页就可以被复用了。但数据页的复用跟记录的复用不同。记录的复用只限于符合范围条件的数据。比如 R4 这条记录被删除后,如果插入一个 ID 是 400 的行,可以直接复用这个空间。如果插入一个 ID 是 800 的行,就不能复用了。
而当整个页从 B+ 树里面摘掉以后,可以复用到任何位置。如上图所示,将数据页 page A 上的所有记录删除以后,page A 会被标记为可复用。这时如果要插入一条 ID=50 的记录需要使用新页时,page A 是可以被复用的。如果相邻的两个数据页利用率都很小,系统就会把这两个页上的数据合到其中一个页上,另外一个数据页就被标记为可复用。
如果用 delete 命令把整个表的数据删除呢?
结果就是,所有的数据页都会被标记为可复用。但是磁盘上文件不会变小。delete 命令其实只是把记录的位置或数据页标记为了可复用,但磁盘文件的大小是不会变的。也就是说,通过 delete 命令是不能回收表空间的。这些可以复用而没有被使用的空间,看起来就像是空洞。
实际上,不止是删除数据会造成空洞,插入数据也会。如果数据是按索引递增顺序插入的,那索引是紧凑的。但如果数据是随机插入的,就可能造成索引的数据页分裂。假设图中 page A 已经满了,这时要再插入一行数据会怎样呢?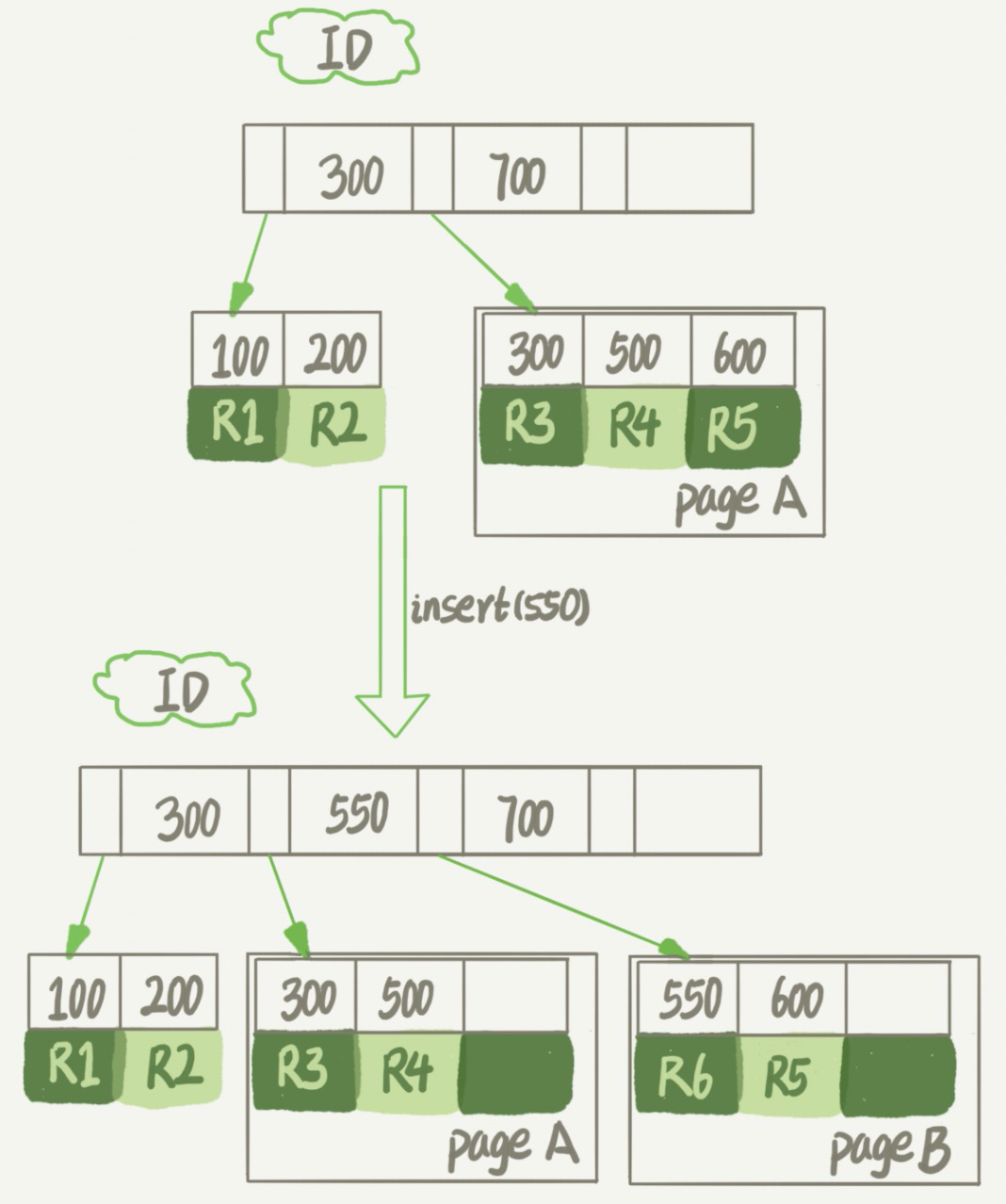
可以看到,由于 page A 满了,再插入一个 ID 是 550 的数据时,就不得不再申请一个新的页面 page B 来保存数据了。页分裂完成后,page A 的末尾就留下了空洞。
另外,更新索引上的值,可以理解为删除一个旧的值,再插入一个新值,这也是会造成空洞的。也就是说,经过大量增删改的表,都是可能是存在空洞的。所以,如果能够把这些空洞去掉,就能达到收缩表空间的目的。而重建表就可以达到这样的目的。
重建表
假设你现在有一个表 A,需要做空间收缩,为了把表中存在的空洞去掉,可以怎么做呢?
可以新建一个与表 A 结构相同的表 B,然后按主键 ID 递增的顺序,把数据一行一行地从表 A 里读出来再插入到表 B 中。由于表 B 是新建的表,所以表 A 主键索引上的空洞在表 B 中不存在。因此表 B 数据页的利用率也更高。如果把表 B 作为临时表,数据从表 A 导入表 B 后再用表 B 替换 A,从效果上看,就起到了收缩表 A 空间的作用。
这里可以用 alter table A engine=InnoDB 命令来重建表。在 MySQL 5.5 版本前,这个命令的执行流程跟上面描述的差不多,区别只是这个临时表 B 不需要自己创建,MySQL 会自动完成转存数据、交换表名、删除旧表的一系列操作。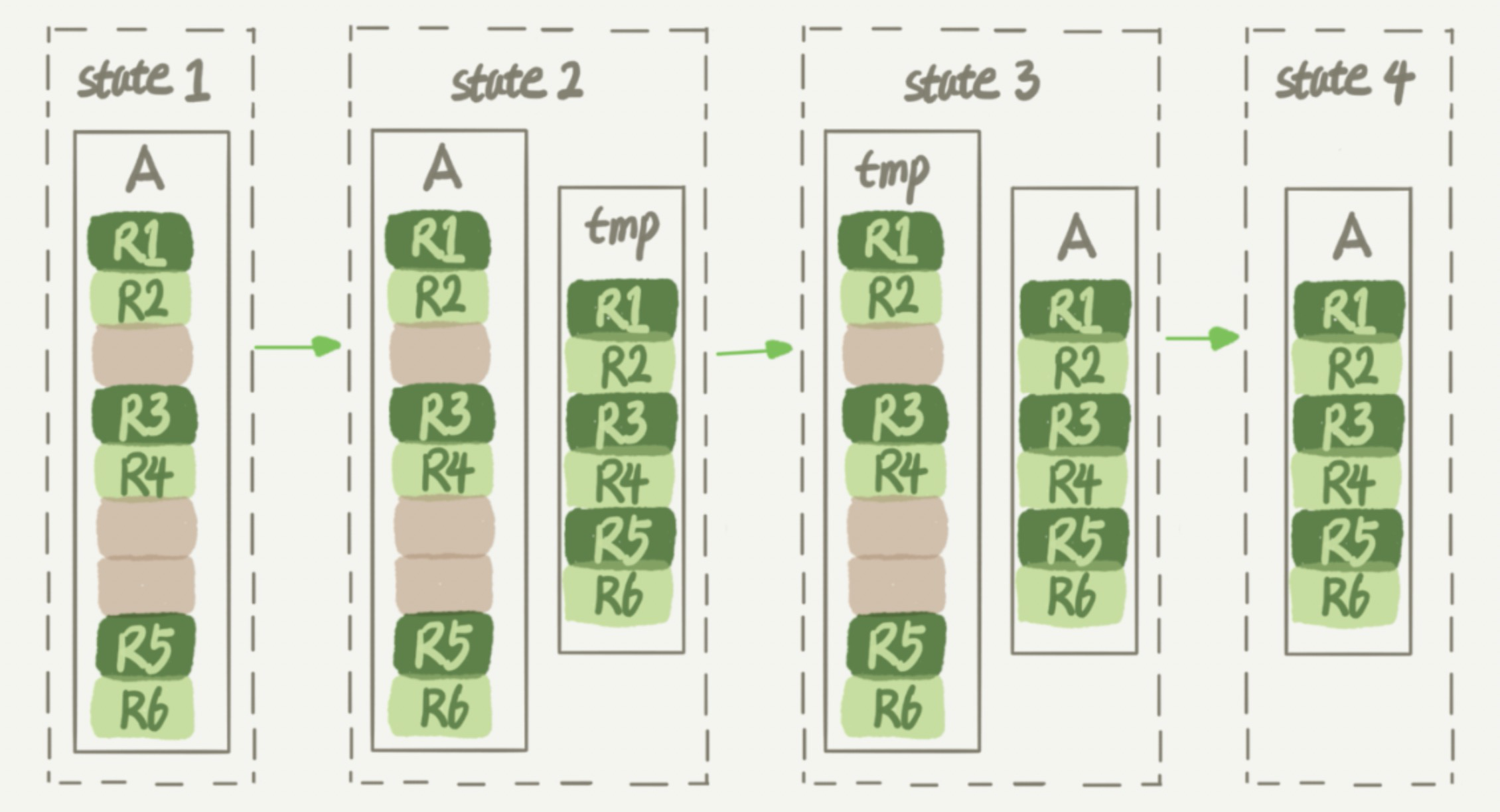
1. Online DDL
整个过程最耗时的步骤是往临时表中插入数据的过程,如果在这个过程中有新的数据要写入到表 A 的话,就会造成数据丢失。因此在整个 DDL 过程中,表 A 中不能有更新。也就是说,这个 DDL 不是 Online 的。而在 MySQL 5.6 版本引入了 Online DDL 对这个操作流程做了优化:
- 建立一个临时文件,扫描表 A 主键的所有数据页。
- 用数据页中表 A 的记录生成 B+ 树,存储到临时文件中。
- 生成临时文件的过程中,将所有对 A 的操作记录在一个日志文件(row log)中。
- 临时文件生成后,将日志文件中的操作应用到临时文件,得到一个逻辑数据上与表 A 相同的数据文件。
- 用临时文件替换表 A 的数据文件。
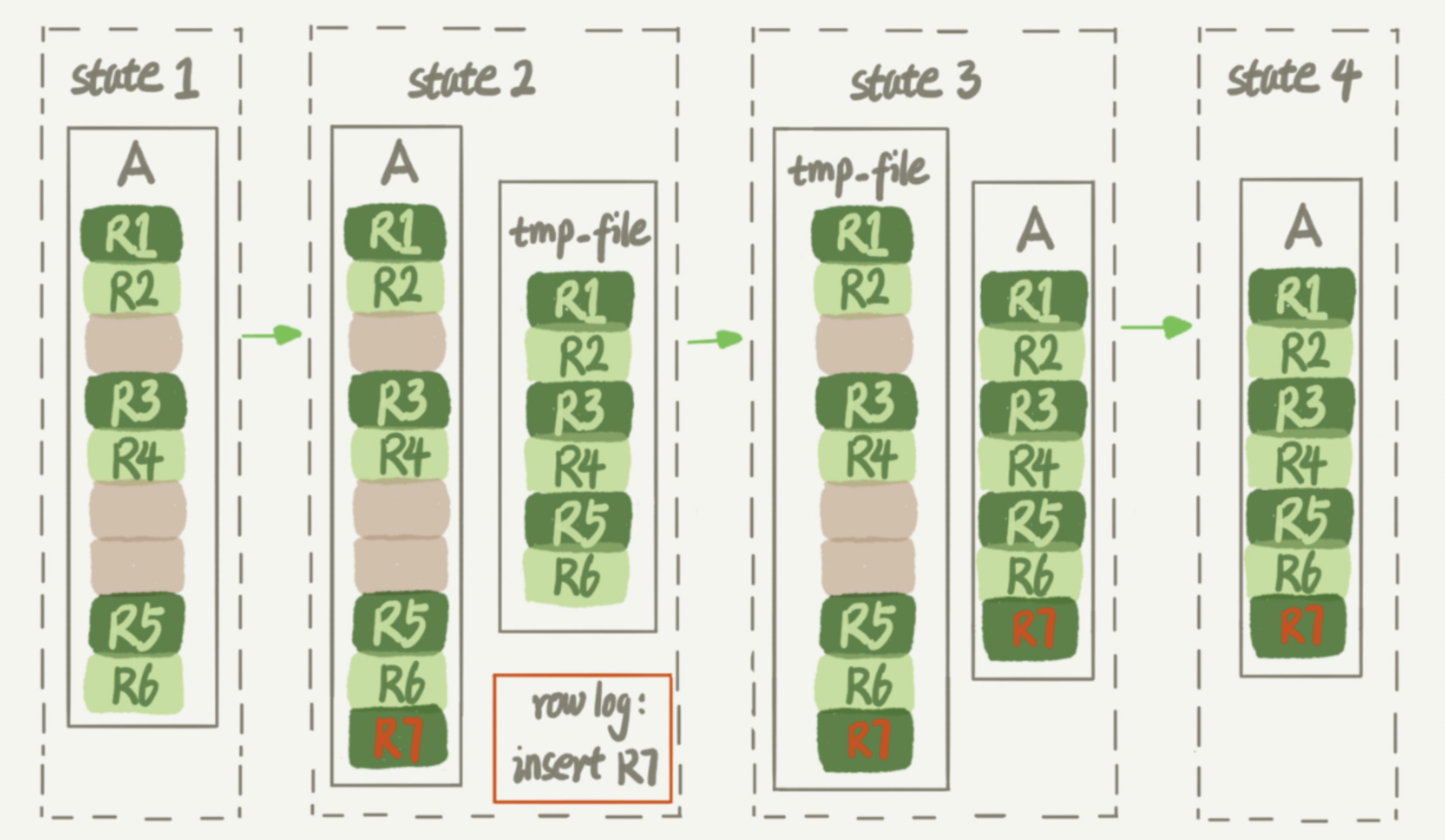
这两种方式的不同之处在于,由于日志文件记录和重放操作这个功能的存在,这个方案在重建表的过程中,允许对表 A 做增删改操作。这也就是 Online DDL 名字的来源。
但 DDL 之前是要拿 MDL 写锁的。上图流程中,alter 语句在启动时需要获取 MDL 写锁,但这个写锁在真正拷贝数据之前就退化成读锁了。为什么要退化呢?为了实现 Online,MDL 读锁不会阻塞数据的增删改操作。
那为什么不干脆直接解锁呢?为了保护自己,禁止其他线程对这个表同时做 DDL。而对于一个大表来说,Online DDL 最耗时的过程就是拷贝数据到临时表的过程,这个步骤的执行期间可以接受增删改操作。因此在整个 DDL 过程中,锁的时间是非常短的。对业务来说就可以认为是 Online 的。
误删数据怎么办?
传统的高可用架构是不能预防误删数据的,因为主库的一个 drop table 命令,会通过 binlog 传给所有从库和级联从库,进而导致整个集群的实例都会执行这个命令。那在误删数据前后,我们可以做些什么来减少误删数据的风险和由误删数据带来的损失呢?我们先对和 MySQL 相关的误删数据做下分类:
- 使用 delete 语句误删数据行。
- 使用 drop table 或者 truncate table 语句误删数据表。
- 使用 drop database 语句误删数据库。
- 使用 rm 命令误删整个 MySQL 实例。
1. 误删行
如果使用 delete 语句误删了数据行,可以用 Flashback 工具通过闪回把数据恢复回来。Flashback 恢复数据的原理是修改 binlog 的内容,拿回原库重放。而能够使用这个方案的前提是要确保 binlog_format = row 和 binlog_row_image = FULL。具体恢复数据时,对单个事务做如下处理:
对于 insert 语句,对应的 binlog event 类型是 Write_rows event,把它改成 Delete_rows event 即可。
同理,对于 delete 语句,也是将 Delete_rows event 改为 Write_rows event。
而如果是 Update_rows 的话,binlog 里面记录了数据行修改前和修改后的值,对调这两行的位置即可。如果误删数据涉及到了多个事务的话,需要将事务的顺序调过来再执行。
当然更重要是要做到事前预防。可以把 sql_safe_updates 参数设置为 on。这样如果我们忘记在 delete 或者 update 语句中写 where 条件,或者 where 条件里面没有包含索引字段的话,这条语句的执行就会报错。
使用 delete 命令删除的数据可以用 Flashback 来恢复。而使用 truncate /drop table 和 drop database 命令删除的数据就没办法通过 Flashback 来恢复了。因为即使我们配置了 binlog_format=row,执行这三个命令时记录的 binlog 还是 statement 格式。binlog 里就只有一个 truncate/drop 语句,这些信息是恢复不出数据的。
2. 误删表
这种情况要想恢复数据,就需要使用全量备份加增量日志的方式了。这个方案要求线上有定期的全量备份,并且实时备份 binlog。在这两个条件都具备的情况下,假如有人中午 12 点误删了一个库,恢复数据的流程如下:
- 取最近一次全量备份,假设这个库是一天一备,上次备份是当天 0 点。
- 用备份恢复出一个临时库。
- 从日志备份里面,取出凌晨 0 点之后的日志。
- 把这些日志,除了误删除数据的语句外,全部应用到临时库。
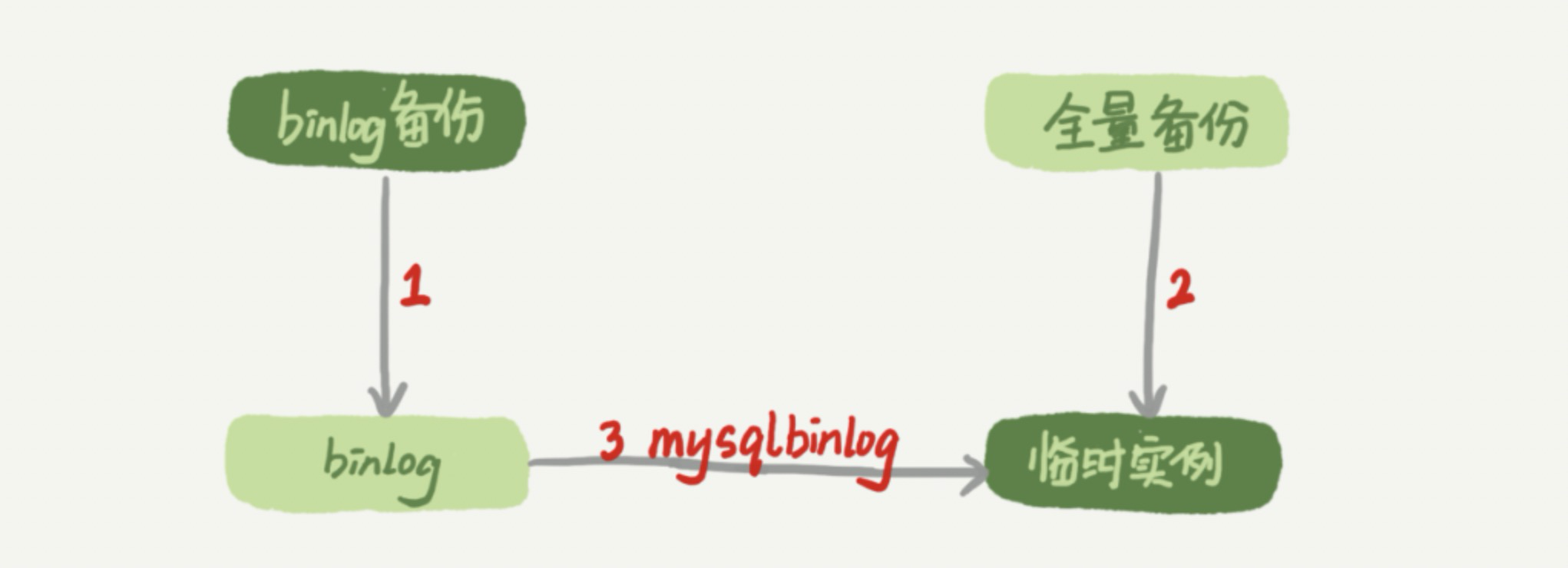
不过使用 mysqlbinlog 方法恢复数据还是不够快,主要原因有两个:如果是误删表,最好就是只恢复出这张表,也就是只重放这张表的操作,但是 mysqlbinlog 工具并不能指定只解析一个表的日志;用 mysqlbinlog 解析出日志应用,应用日志的过程就只能是单线程。
那我们有什么方法可以缩短恢复数据需要的时间呢?
如果有非常核心的业务,不允许太长的恢复时间,我们可以考虑搭建延迟复制的备库。这个功能是 MySQL 5.6 版本引入的。一般的主备复制结构存在的问题是,如果主库上有个表被误删了,这个命令很快也会被发给所有从库,进而导致所有从库的数据表也都一起被误删了。
延迟复制的备库是一种特殊的备库,通过 CHANGE MASTER TO MASTER_DELAY = N 命令,可以指定这个备库持续保持跟主库有 N 秒的延迟。比如把 N 设置为 3600,就代表了如果主库上有数据被误删了,并且在 1 小时内发现了这个误操作命令,这个命令就还没有在这个延迟复制的备库执行。这时候到这个备库上执行 stop slave,再通过上面介绍的方法跳过误操作命令,就可以恢复出需要的数据。这样你就随时可以得到一个,只需要最多再追 1 小时就可以恢复出数据的临时实例,也就缩短了整个数据恢复需要的时间。

若有收获,就点个赞吧
0 人点赞
