大数据发展历史
今天我们常说的大数据技术,其实起源于 Google 在 2004 年前后发表的三篇论文,也就是我们经常听到的“三驾马车”,分别是分布式文件系统 GFS、大数据分布式计算框架 MapReduce 和 NoSQL 数据库系统 BigTable。其实,搜索引擎主要做两件事,一个是网页抓取,一个是索引构建,而在这个过程中,有大量的数据需要存储和计算,而这“三驾马车”就是用来解决这个问题的。如今的“大数据”技术,十有八九都来自于 Google 发表这三篇论文,然后再演变成一个个开源系统,让整个行业受益。可以说,Google 就是大数据领域的普罗米修斯。
1. 需求起源
Google 能成为散播大数据火种的人,是有着历史的必然性的。作为一个搜索引擎,Google 在数据层面,面临着比任何一个互联网公司都更大的挑战。无论是 Amazon 这样的电商公司,还是 Yahoo 这样的门户网站,都只需要存储自己网站相关的数据。而 Google 则需要抓取所有网站的网页数据并存下来,光存下来还不够,早在 1999 年,两个创始人就发表了 PageRank 的论文,因此 Google 不只是简单地根据网页里面的关键字来排序搜索结果,而是需要对所有文件中的单词进行词频统计,然后根据 PageRank 算法计算网页排名,这个过程需要进行很多轮的迭代计算,才能最终确认排序。而不断增长的搜索请求量,也让 Google 需要有响应迅速的在线服务。
由此一来,面对存储、计算和在线服务这三个需求,Google 就在 2003、2004 以及 2006 年,分别抛出了三篇重磅论文。也就是上面提到的三驾马车:GFS、MapReduce 和 Bigtable。
GFS 的论文发表于 2003 年,它主要解决了数据的存储问题。在 GFS 出现之前,传统的并行数据库技术就已经在尝试处理海量的数据了,但这些并行数据库的单个集群往往也就是几十个服务器。而在 Google 发表了 GFS 的论文后,我们才第一次看到了单个分布式文件集群系统里可以有上千个节点。集群规模有了数量级上的变化,也就把数据处理能力拉上了一个新的台阶。由于集群可以伸缩到上千乃至上万个节点,Google 可以把所有需要的数据都能很容易地存储下来。
当存储了海量的数据后,我们还要基于这些数据进行各种计算。这个时候,就轮到 2004 年发表的 MapReduce 出场了。Google 利用简单的 Map 和 Reduce 两个函数,对于海量数据计算做了一次抽象,这就让“处理”数据的人不再需要深入掌握分布式系统的开发了。而且他们推出的 PageRank 算法,也可以通过多轮的 MapReduce 的迭代来实现。这样,无论是 GFS 存储数据,还是 MapReduce 处理数据,系统的吞吐量都没有问题了,因为所有的数据都是顺序读写。但是这两个,其实都没有办法解决好数据的高性能随机读写问题。
因此,面对这个问题,2006 年发表的 Bigtable 就站上了历史舞台了。它是直接使用 GFS 作为底层存储,来做好集群的分片调度,以及利用 MemTable + SSTable 的底层存储格式,来解决大集群、机械硬盘下的高性能的随机读写问题。下图简单展示了 Google 的三驾马车针对这三类问题的技术优缺点: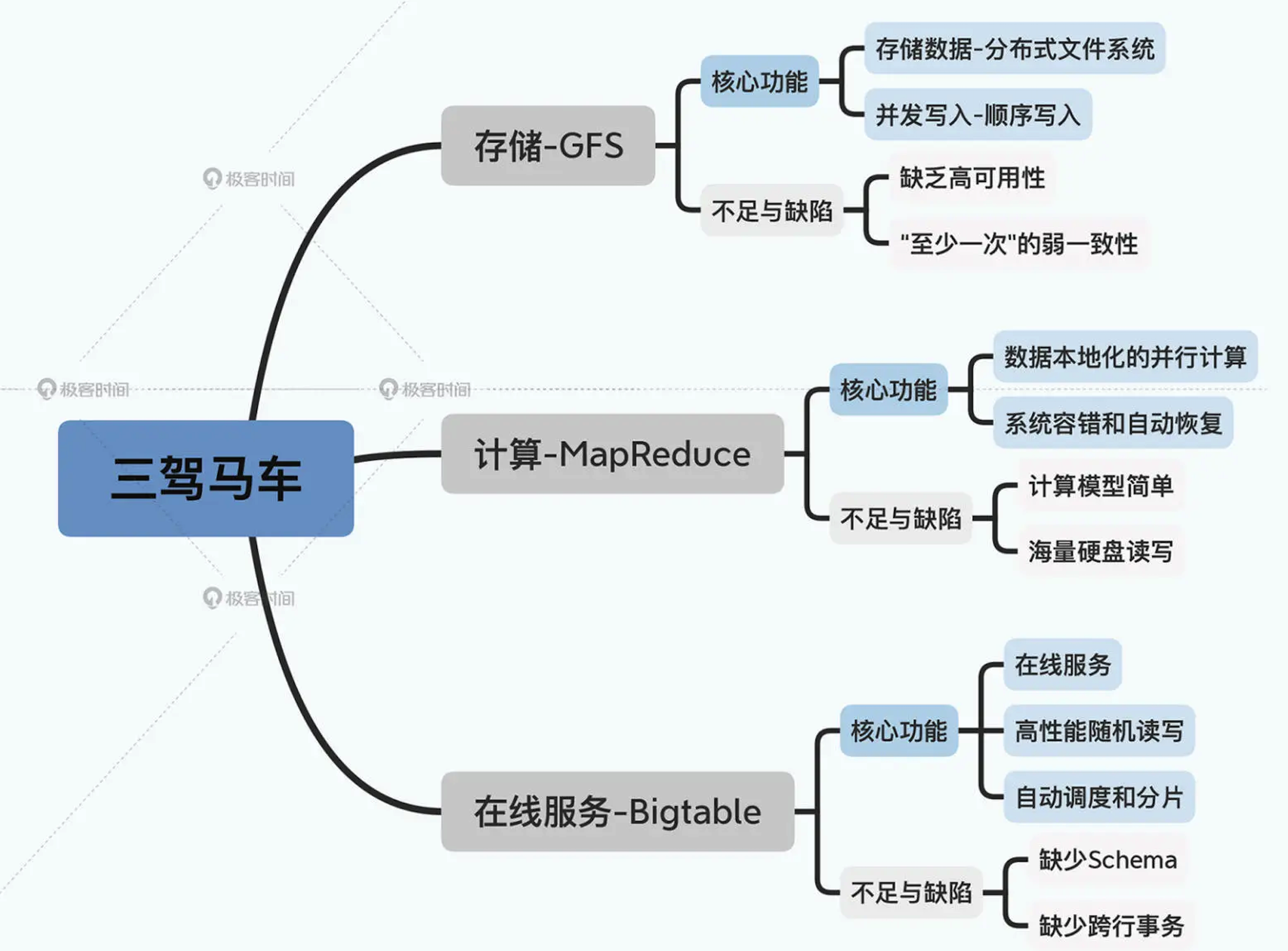
至此,GFS、MapReduce 和 Bigtable 这三驾马车的论文,就完成了“存储”“计算”“实时服务”这三个核心架构的设计。不过这三篇论文其实还依赖了两个基础设施。
第一个是为了保障数据一致性的分布式锁。对于这个问题,Google 在发表 Bigtable 的同一年,就发表了实现了 Paxos 算法的 Chubby 锁服务的论文。第二个是数据怎么序列化以及分布式系统之间怎么通信。Google 在前面的论文里没有提到这一点,而 Facebook 则在 2007 年发表了 Thrift 序列化相关的论文。实际上,Bigtable 的开源实现 HBase 就用了 Thrift 作为和外部多语言进行通信的协议。
2. 大数据生态发展
可以说,GFS、MapReduce 和 Bigtable 这三驾马车为整个业界带来了火种,因为那时大多数公司的关注点其实还是聚焦在单机上,在思考如何提升单机的性能,寻找更贵更好的服务器。而 Google 的思路是部署一个大规模的服务器集群,通过分布式的方式将海量数据存储在这个集群上,然后利用集群上的所有机器进行数据计算。这样 Google 其实不需要买很多很贵的服务器,它只要把这些普通的机器组织到一起,就非常厉害了。
2.1 Hadoop
当时的天才程序员,也是 Lucene 开源项目的创始人 Doug Cutting 正在开发开源搜索引擎 Nutch,在阅读了 Google 的论文后,他非常兴奋,紧接着就根据论文原理初步实现了类似 GFS 和 MapReduce 的功能。两年后的 2006 年,Doug Cutting 将这些大数据相关的功能从 Nutch 中分离了出来,然后启动了一个独立的项目专门开发维护大数据技术,这就是后来赫赫有名的 Hadoop,主要包括 Hadoop 分布式文件系统 HDFS 和大数据计算引擎 MapReduce。之后在 2008 年,Hadoop 正式成为 Apache 的顶级项目。同年,专门运营 Hadoop 的商业公司 Cloudera 成立,Hadoop 也得到了进一步的商业支持。
2.2 Hive
与此同时,Yahoo 的一些人觉得用 MapReduce 进行大数据编程太麻烦了,于是便开发了 Pig。Pig 是一种脚本语言,使用类 SQL 的语法,开发者可以用 Pig 脚本描述要对大数据集上进行的操作,Pig 经过编译后会生成 MapReduce 程序,然后在 Hadoop 上运行。编写 Pig 脚本虽然比直接面向 MapReduce 编程容易,但依然需要学习新的脚本语法。于是之后 Facebook 又发布了 Hive。Hive 支持使用 SQL 语法来进行大数据计算,它会把 SQL 语句转化成 MapReduce 的计算程序。这样,熟悉数据库的数据分析师和工程师便可以无门槛地使用大数据进行数据分析和处理了。Hive 出现后极大程度地降低了 Hadoop 的使用难度,迅速得到开发者和企业的追捧。
Hive 虽然披上了一个 SQL 的皮,但是它的底层仍然是一个个 MapReduce 的任务,所以延时很高,没法当成一个交互式系统来给数据分析师使用。于是 Google 又在 2010 年,发表了 Dremel 这个交互式查询引擎的论文,采用数据列存储 + 并行数据库的方式。这样一来,Dremel 不仅有了一个 SQL 的皮,还进一步把 MapReduce 这个执行引擎给替换掉了。
2.3 Yarn
在 Hadoop 早期,MapReduce 既是一个执行引擎,又是一个资源调度框架,服务器集群的资源调度管理由 MapReduce 自己完成。但是这样不利于资源复用,也使得 MapReduce 非常臃肿。于是一个新项目启动了,目标是将 MapReduce 执行引擎和资源调度分离开来,这就是 Yarn。2012 年,Yarn 成为一个独立的项目开始运营,随后被各类大数据产品支持,成为大数据平台上最主流的资源调度系统。
2.4 Spark
同样是在 2012 年,UC 伯克利 AMP 实验室开发的 Spark 开始崭露头角,Spark 通过把数据放在内存而不是硬盘里,大大提升了分布式数据计算性能。当时 AMP 实验室的马铁博士发现使用 MapReduce 进行机器学习计算时性能非常差,因为机器学习算法通常需要进行很多次的迭代计算,而 MapReduce 每执行一次 Map 和 Reduce 计算都要读写一次硬盘,而且 Map 和 Reduce 之间的数据通信,也是先要落到硬盘上的。这样,无论是复杂一点的 Hive SQL,还是需要进行上百轮迭代的机器学习算法,都会浪费非常多的硬盘读写。还有一点就是 MapReduce 主要使用磁盘作为存储介质,而 2012 年的时候,内存已经突破容量和成本限制,成为数据运行过程中主要的存储介质。Spark 一经推出,立即受到业界的追捧,并逐步替代 MapReduce 在企业应用中的地位。
2.5 数据库
看完了 MapReduce 这头,我们再来看看 Bigtable 那一头。谷歌文件系统 GFS 和 MapReduce 奠定了 Hadoop 的基础,BigTable 则开启了大数据技术的另一分支 NoSQL(非关系型)数据库。
NoSQL 诞生的意义不同于 Hadoop,Hadoop 由于自身的设计哲学,在大规模数据的分析和处理(OLAP)上特别擅长,但是对于追求并发、对时延特别敏感的商业交易型查询(OLTP)上几乎一无建树。在商业交易型查询领域,传统的关系型数据库依然占据着几乎所有的份额。谷歌的 BigTable 意义就在于撼动了关系型数据库在商业交易型查询领域的份额。NoSQL 曾经在 2011 年左右非常火爆,涌现出 HBase、Cassandra 等许多优秀的产品,其中 HBase 是从 Hadoop 中分离出来的、基于 HDFS 的 NoSQL 系统。
但随着开发者使用 NoSQL 的时间长了,他们渐渐的发现 NoSQL 有着很多缺陷。比如,大部分 NoSQL 数据库都不支持 Schema 定义和跨行事务,也不支持各种复杂数据操作,如果想实现复杂的数据操作就必须让应用层去处理这些逻辑,而不是交由数据库完成。这大大加重了程序员的负担。因此,越来越多的程序员不满于 NoSQL 的这些缺陷,并试图找到 SQL 和 NoSQL 之间的一个完美平衡。幸运的是,他们找到了,这就是 NewSQL。
NewSQL 作为新的数据库不仅拥有着 NoSQL 良好的扩展性,而且也拥有着 SQL 这样的语言特性和像关系型数据库一样支持事务。首先是事务问题和 Schema 问题。Google 先是在 2011 年发表了 Megastore 的论文,在 Bigtable 之上,实现了类 SQL 的接口,提供了 Schema,以及简单的跨行事务。如果说 Bigtable 为了伸缩性,放弃了关系型数据库的种种特性。那么 Megastore 就是开始在 Bigtable 上逐步弥补关系型数据库的特性。其次是异地多活和跨数据中心问题。Google 在 2012 年发表的 Spanner,是第一款支持全球性事务的事务性分析数据库,能够做到“全局一致性”。其理念影响了 TiDB,CockroachDB 等开源数据库。自此以后,关系型数据库插上了分布式的翅膀。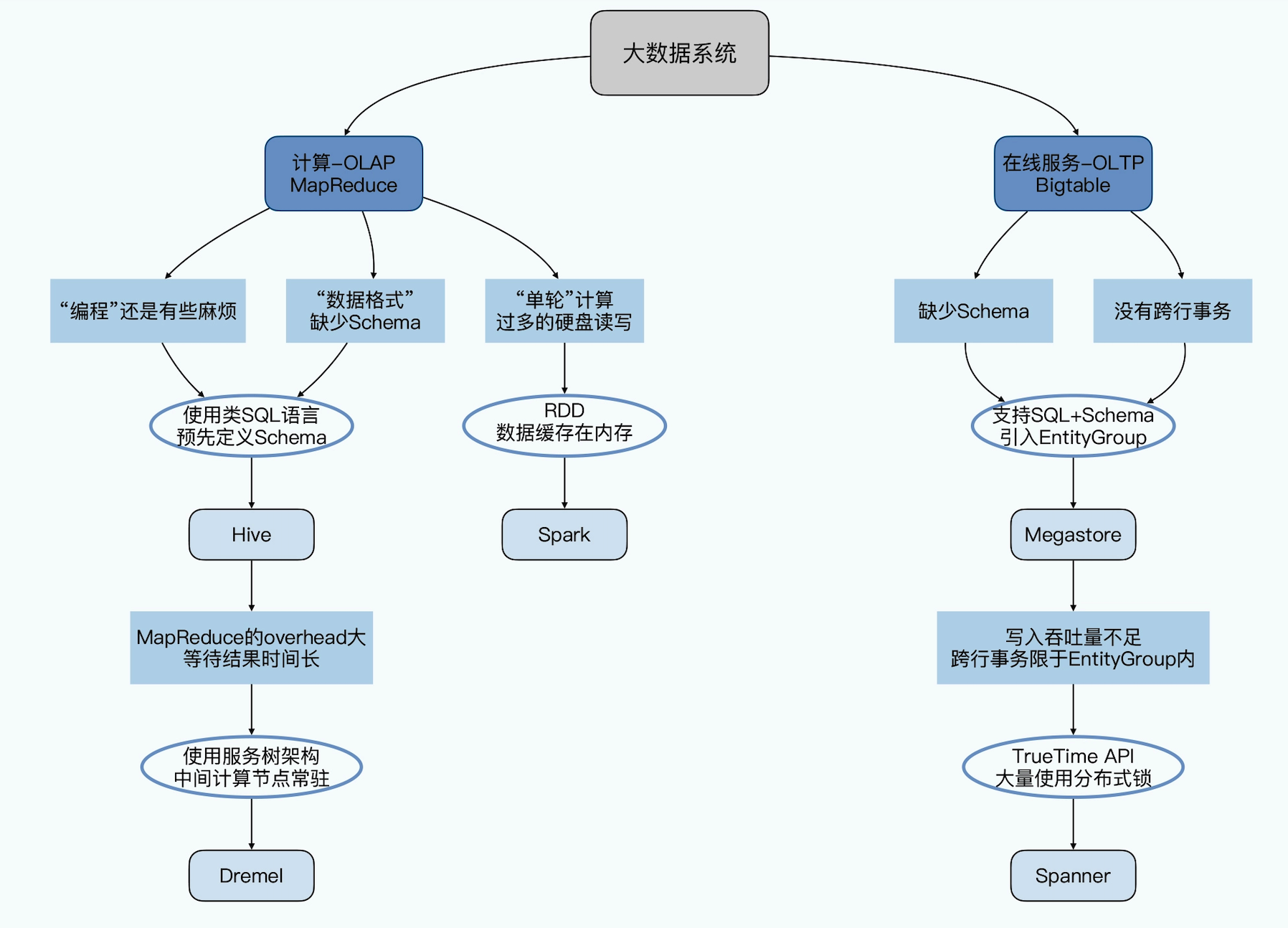
2.6 流式计算
一般说来,像 MapReduce、Spark 这类计算框架处理的业务场景都被称作批处理计算,因为它们通常针对以“天”为单位产生的数据进行一次计算,然后得到需要的结果,这中间计算需要花费的时间大概是几十分钟甚至更长的时间。因为计算的数据是非在线得到的实时数据,而是历史数据,所以这类计算也被称为大数据离线计算。而在大数据领域,还有另外一类应用场景,它们需要对实时产生的大量数据进行即时计算,比如对于遍布城市的监控摄像头进行人脸识别和嫌犯追踪。这类计算称为大数据流计算。
为了解决好这个问题,流式数据处理就走上了舞台。首先是 Yahoo 在 2010 年发表了 S4 的论文,并在 2011 年开源了 S4。而几乎是在同一时间,Twitter 工程师南森·马茨(Nathan Marz)以一己之力开源了 Storm,并且在很长一段时间成为了工业界的事实标准。另外,基于 Storm 和 MapReduce,南森更是提出了 Lambda 架构,它可以称之为是第一个“流批协同”的大数据处理架构。
接着在 2011 年,Kafka 的论文也发表了。最早的 Kafka 其实只是一个“消息队列”,但由于 Kafka 里发送的消息可以做到“正好一次”(Exactly-Once),所以大家就动起了在上面直接解决 Storm 解决不好的消息重复问题的念头。于是,Kafka 逐步进化出了 Kafka Streams 这样的实时数据处理方案。而后在 2014 年,Kafka 的作者提出了 Kappa 架构,这个可以被称之为第一代“流批一体”的大数据处理架构。
一直到 2015 年,Google 发表了 Dataflow 模型,可以说是对于流式数据处理模型做出了最好的总结和抽象。一直到现在,Dataflow 就成为了真正的“流批一体”的大数据处理架构。而后来开源的 Flink 和 Apache Beam,则是完全按照 Dataflow 的模型实现的了。在典型的大数据的业务场景下,数据业务最通用的做法是,采用批处理的技术处理历史全量数据,采用流式计算处理实时新增数据。而像 Flink 这样的计算引擎,可以同时支持流式计算和批处理计算。
大数据应用场景
上面讲的这些基本上都可以归类为大数据引擎或者大数据框架。而大数据处理的主要应用场景包括数据分析、数据挖掘与机器学习。数据分析主要使用 Hive、Spark SQL 等 SQL 引擎完成;数据挖掘与机器学习则有专门的机器学习框架 TensorFlow、Mahout 以及 MLlib 等,内置了主要的机器学习和数据挖掘算法。此外,大数据要存入分布式文件系统(HDFS),要有序调度 MapReduce 和 Spark 作业执行,并能把执行结果写入到各个应用系统的数据库中,还需要有一个大数据平台整合所有这些大数据组件和企业应用系统。

若有收获,就点个赞吧
0 人点赞
