对于 Redis 来说,一旦确定了缓存最大容量,比如 4GB,你就可以使用下面这个命令来设定缓存大小:
CONFIG SET maxmemory 4gb
或者在 redis.conf 配置文件中指定 maxmemory 配置项。当设置了缓存最大容量后,我们需要面对缓存被写满时的替换操作。缓存替换需要解决两个问题:决定淘汰哪些数据,如何处理那些被淘汰的数据。
内存淘汰策略
Redis 4.0 版本之前一共实现了 6 种内存淘汰策略,在 4.0 之后,又增加了 2 种策略。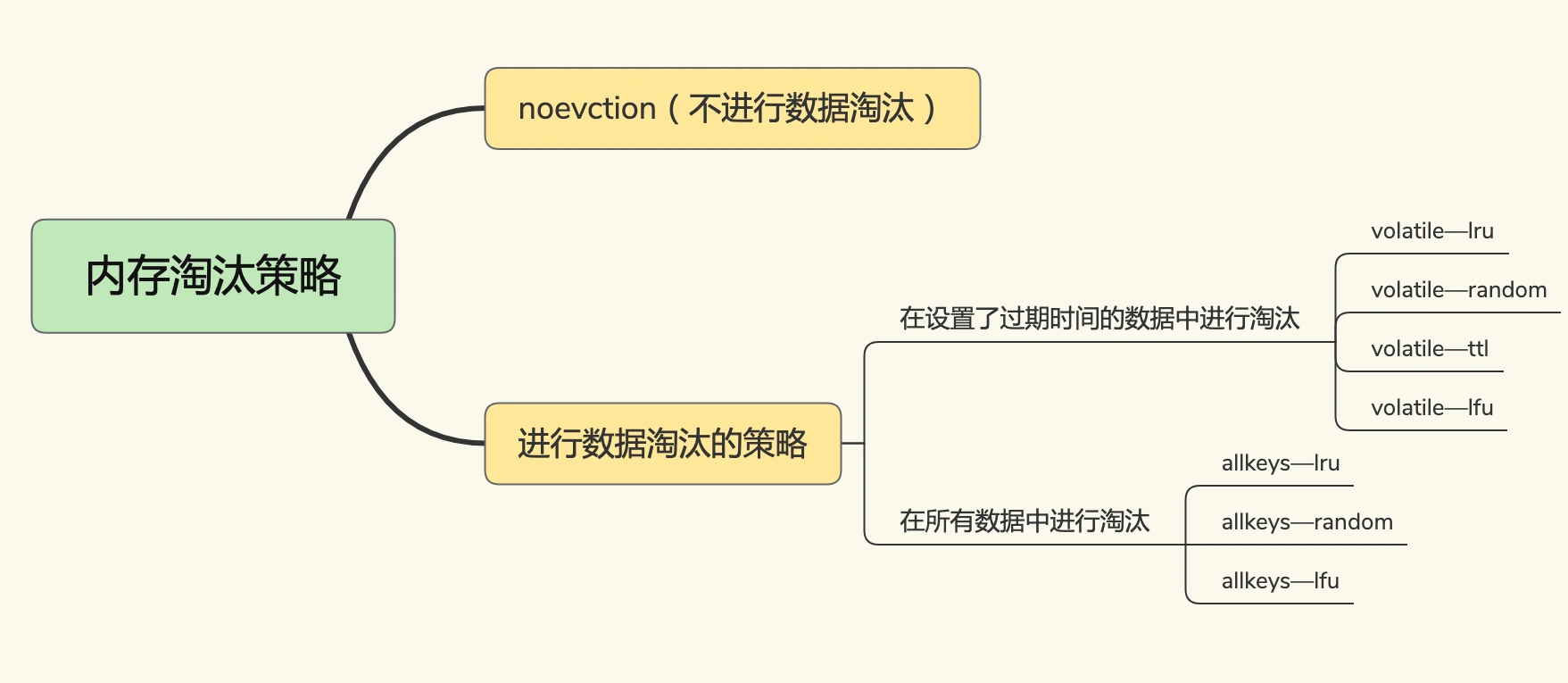
内存淘汰策略通过 maxmemory-policy 配置项进行配置,默认为不进行数据淘汰。对应到 Redis 就是指,一旦缓存被写满了,再有写请求来时,Redis 将不再提供服务,而是直接返回错误。对于把 Redis 用作缓存的场景,显然不应该使用这种策略。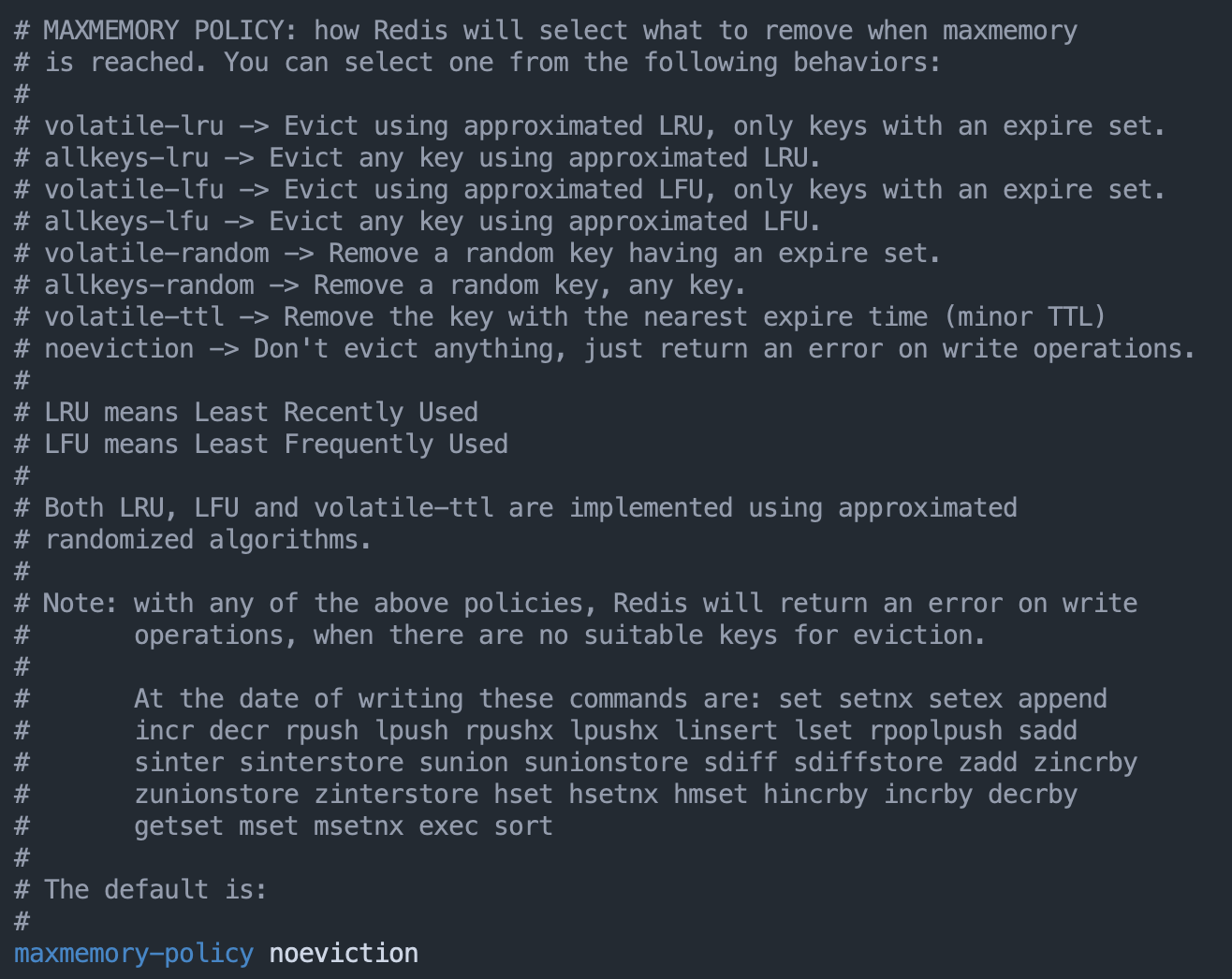
我们再分析下 volatile-random、volatile-ttl、volatile-lru 和 volatile-lfu 这四种淘汰策略。它们筛选的候选数据范围,被限制在已经设置了过期时间的键值对上。也正因为此,即使缓存没有写满,这些数据如果过期了也会被删除。如果没有可删除的键值对,则回退到 noeviction 策略。
volatile-ttl 在筛选时,会针对设置了过期时间的键值对,根据过期时间的先后进行删除,越早过期的越先被删除。
volatile-random 在设置了过期时间的键值对中,进行随机删除。
volatile-lru 会使用 LRU 算法筛选设置了过期时间的键值对。
volatile-lfu 会使用 LFU 算法选择设置了过期时间的键值对。LFU 算法是在 LRU 算法的基础上,同时考虑数据的访问时效性和数据的访问次数,可以看作是对淘汰策略的优化。
相比之下,allkeys-lru、allkeys-random、allkeys-lfu 这三种淘汰策略的备选淘汰数据范围,就扩大到了所有的键值对,无论这些键值对是否设置了过期时间。它们筛选数据进行淘汰的规则是:
allkeys-random 策略,从所有键值对中随机选择并删除数据;
allkeys-lru 策略,使用 LRU 算法在所有数据中进行筛选。
allkeys-lfu 策略,使用 LFU 算法在所有数据中进行筛选。
当设置 maxmemory 并启用 LRU、LFU 相关淘汰策略时,Redis 会禁用共享对象池。因为 LRU、LFU 算法需要获取对象最后被访问时间,而对象共享意味着多个引用共享同一个 redisObject,这时 lru 字段也会被共享,导致无法获取每个对象的最后访问时间。
1. LRU 算法工作机制
LRU 算法的全称是 Least Recently Used,从名字上就可以看出,这是按照最近最少使用的原则来筛选数据,最不常用的数据会被筛选出来,而最近频繁使用的数据会留在缓存中。
那具体是怎么筛选的呢?LRU 会把所有的数据组织成一个链表,链表的头和尾分别表示 MRU 端和 LRU 端,分别代表最近最常使用的数据和最近最不常用的数据。我们看一个例子。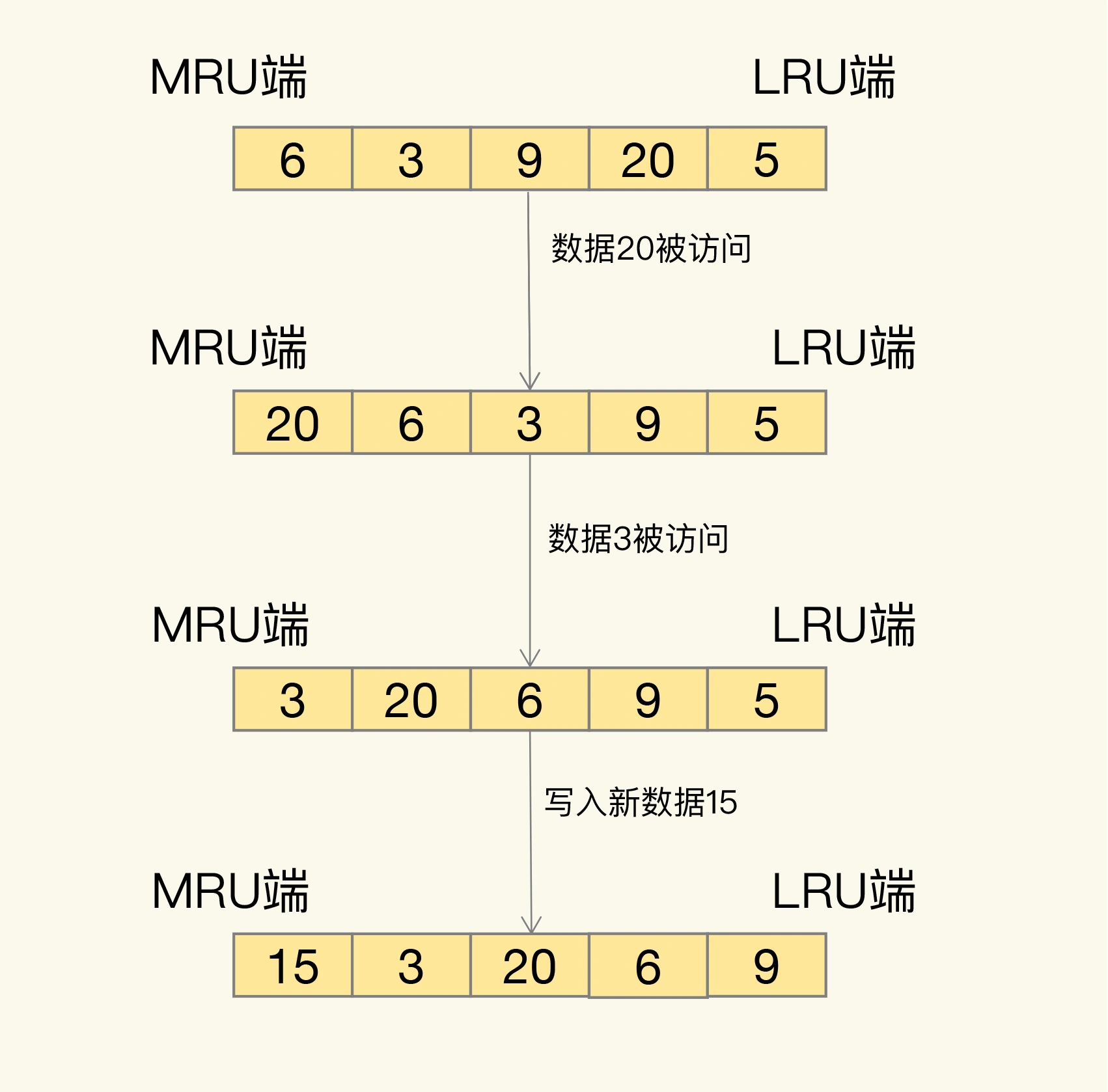
我们现在有数据 6、3、9、20、5。如果数据 20 和 3 被先后访问,它们都会从现有的链表位置移到 MRU 端,而链表中在它们之前的数据则相应地往后移一位。因为,LRU 算法选择删除数据时,都是从 LRU 端开始,所以把刚刚被访问的数据移到 MRU 端,就可以让它们尽可能地留在缓存中。如果有一个新数据 15 要被写入缓存,但此时已经没有缓存空间了,也就是链表没有空余位置了。那么,LRU 算法会先把数据 15 放到 MRU 端,然后把 LRU 端的数据 5 从缓存中删除。
其实,LRU 算法背后的想法非常朴素:它认为刚刚被访问的数据,肯定还会被再次访问,所以就把它放在 MRU 端;长久不访问的数据,肯定就不会再被访问了,所以就让它逐渐后移到 LRU 端,在缓存满时优先删除它。不过,LRU 算法在实际实现时,需要用链表管理所有的缓存数据,这会带来额外的空间开销。而且,当有数据被访问时,需要在链表上把该数据移动到 MRU 端,如果有大量数据被访问,就会带来很多链表移动操作,会很耗时,进而会降低 Redis 性能。
所以,Redis 对 LRU 算法做了简化,以减轻数据淘汰对缓存性能的影响。具体来说,Redis 默认会记录每个数据的最近一次访问的时间戳(由 RedisObject 中的 lru 字段记录)。然后,Redis 在决定淘汰的数据时,第一次会随机选出 N 个数据,把它们作为一个候选集合。接下来,Redis 会比较这 N 个数据的 lru 字段,把 lru 字段值最小的数据从缓存中淘汰出去。第二次及后续再进入候选集的数据的 lru 值需要小于候选集中的最小 lru 值。
Redis 提供了一个配置参数 maxmemory-samples,这个参数就是 Redis 选出的数据个数 N。默认为 5。
当需要再次淘汰数据时,Redis 需要挑选数据进入第一次淘汰时创建的候选集合。这儿的挑选标准是:能进入候选集合的数据的 lru 字段值必须小于候选集合中最小的 lru 值。当有新数据进入候选数据集后,如果候选数据集中的数据个数达到了 maxmemory-samples,Redis 就把候选数据集中 lru 字段值最小的数据淘汰出去。这样 Redis 就不用为所有数据维护一个大链表,也不用在每次数据访问时都移动链表项,提升了缓存的性能。
实际上,候选集的作用就是先把符合条件(lru值小)的数据准备好。候选集本身按照 lru 值大小排序,等待要淘汰时会根据要淘汰的量,从候选集中淘汰数据。所以,并不是刚进入候选集就立马就淘汰了。准备候选集和淘汰数据实际是两个解耦的逻辑操作。
2. LFU 算法工作机制
LRU 策略虽然能有效留存访问时间最近的数据。但是,也正是因为只看数据的访问时间,使用 LRU 策略在处理扫描式单次查询操作时,无法解决缓存污染。所谓的扫描式单次查询操作,就是指应用对大量的数据进行一次全体读取,每个数据都会被读取,而且只会被读取一次。此时,因为这些被查询的数据刚刚被访问过,所以 lru 字段值都很大,导致这些数据会留存在缓存中很长一段时间,造成缓存污染。
与 LRU 策略相比,LFU 策略中会从两个维度来筛选并淘汰数据:一是,数据访问的时效性(访问时间离当前时间的远近);二是,数据的被访问次数。
LFU 策略在 LRU 策略基础上会为每个数据增加了一个计数器,来统计这个数据的访问次数。当使用 LFU 策略筛选淘汰数据时,首先会根据数据的访问次数进行筛选,把访问次数最低的数据淘汰出缓存。如果两个数据的访问次数相同,LFU 策略再比较这两个数据的访问时效性,把距离上一次访问时间更久的数据淘汰出缓存。
LFU 策略具体实现原理:
在 LRU 策略的基础上,Redis 在实现 LFU 策略的时候,只是把原来 24bit 大小的 lru 字段,又进一步拆分成了 16bit 的 ldt 和 8bit 的 counter,分别用来表示数据的访问时间戳和访问次数。当 LFU 策略筛选数据时,Redis 会在候选集合中,根据数据 lru 字段的后 8bit 选择访问次数最少的数据进行淘汰。当访问次数相同时,再根据 lru 字段的前 16bit 值大小,选择访问时间最久远的数据进行淘汰。
为了避开 8bit 最大只能记录 255 的限制,LFU 策略设计使用非线性增长的计数器来表示数据的访问次数。简单来说就是:每当数据被访问一次时,先用计数器当前的值乘以配置项 lfu_log_factor 再加 1,再取其倒数,得到一个 p 值;然后,把这个 p 值和一个取值范围在(0,1)间的随机数 r 值比大小,只有 p 值大于 r 值时,计数器才加 1。这样,我们可以通过设置不同的 lfu_log_factor 配置项,来控制计数器值增加的速度,避免 counter 值很快就到 255 了。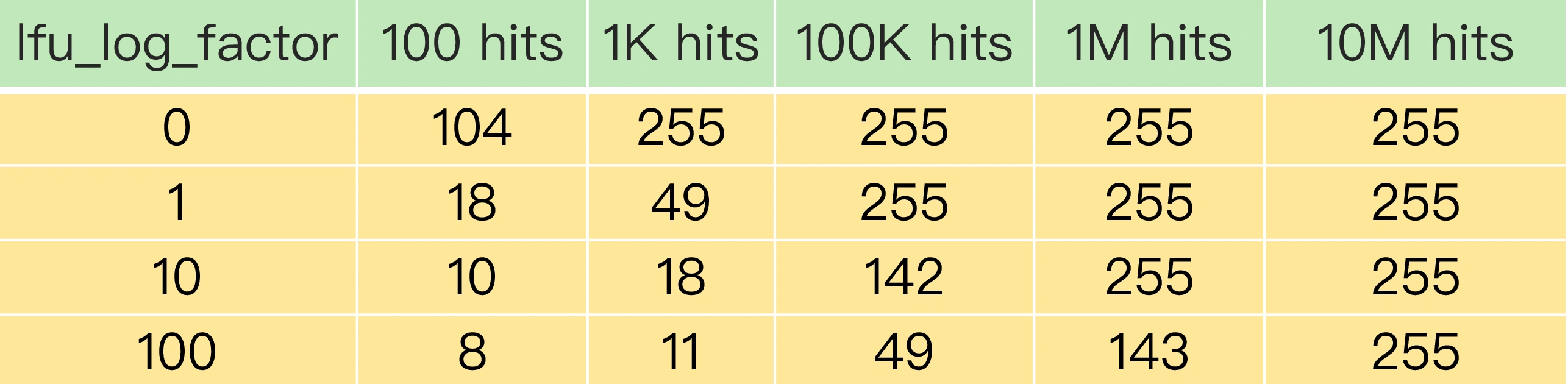
正是因为使用了非线性递增的计数器方法,即使缓存数据的访问次数成千上万,LFU 策略也可以有效地区分不同的访问次数,从而进行合理的数据筛选。从上图中,我们可以看到,当 lfu_log_factor 取值为 10 时,百、千、十万级别的访问次数对应的 counter 值已经有明显的区分了,所以,我们在应用 LFU 策略时,一般可以将 lfu_log_factor 取值为 10。
当然了,由于 counter 值并不精确表示数据被访问的次数,所以当 counter 越来越大或者 lfu-log-factor 参数配置过大时,counter 递增的概率都会越来越低,这种情况下可能会导致一些 key 虽然访问的次数比较高,但是counter 值却递增困难,进而导致这些访问频次较高的 key 却优先被淘汰掉了。在一些极端情况下,LFU 策略使用的计数器可能会在短时间内达到一个很大值,而计数器的衰减配置项设置得较大,导致计数器值衰减很慢,此时数据也可能在缓存中长期驻留。
counter 值的衰减机制:
但是在一些场景下,有些数据在短时间内被大量访问后就不会再被访问了。那么再按照访问次数来筛选的话,这些数据会被留存在缓存中,但不会提升缓存命中率。为此,Redis 在实现 LFU 策略时,还设计了一个 counter 值的衰减机制。
简单来说,LFU 策略使用衰减因子配置项 lfu_decay_time 来控制访问次数的衰减。LFU 策略会计算当前时间和数据最近一次访问时间的差值,并把这个差值换算成以分钟为单位。然后,LFU 策略再把这个差值除以 lfu_decay_time 值,所得的结果就是数据 counter 要衰减的值。
简单举个例子,假设 lfu_decay_time 取值为 1,如果数据在 N 分钟内没有被访问,那么它的访问次数就要减 N。如果 lfu_decay_time 取值更大,那么相应的衰减值会变小,衰减效果也会减弱。所以,如果业务应用中有短时高频访问的数据的话,建议把 lfu_decay_time 值设置为 1,这样一来,LFU 策略在它们不再被访问后,会较快地衰减它们的访问次数,尽早把它们从缓存中淘汰出去,避免缓存污染。
内存回收机制
Redis 并不总是可以将空闲内存立即归还给操作系统。如果当前 Redis 内存有 10G,当你删除了 1GB 的 key 后,再去观察内存,你会发现内存变化不会太大。原因是操作系统回收内存是以页为单位,如果这个页上只要有一个 key 还在使用,那么它就不能被回收。Redis 虽然删除了 1GB 的 key,但是这些 key 分散到了很多页面中,每个页面都还有其它 key 存在,所以内存不会立即被回收。这就会导致虽然有空闲空间,Redis 却无法用来保存数据,不仅会减少 Redis 能够实际保存的数据量,还会降低 Redis 运行机器的成本回报率。
1. 内存碎片诱因
虽然操作系统的剩余内存空间总量足够,但是,应用申请的是一块连续地址空间的 N 字节,但在操作系统剩余的内存空间中,没有大小为 N 字节的连续空间了,这些剩余空间就是内存碎片。其实,内存碎片的形成有内因和外因两个层面的原因。简单来说,内因是操作系统的内存分配机制,外因是 Redis 的负载特征。
内存分配器的分配策略:
内存分配器的分配策略就决定了操作系统无法做到按需分配。因为,内存分配器一般是按固定大小来分配内存,而不是完全按照应用程序申请的内存空间大小给程序分配。Redis 默认使用 jemalloc 内存分配器来分配内存,jemalloc 的分配策略之一,是按照一系列固定的大小划分内存空间,例如 8 字节、16 字节、32 字节 … 2KB、4KB、8KB 等。当程序申请的内存最接近某个固定值时,jemalloc 会给它分配相应大小的空间。
这样的分配方式本身是为了减少分配次数。例如,Redis 申请一个 20 字节的空间保存数据,jemalloc 就会分配 32 字节,此时,如果应用还要写入 10 字节的数据,Redis 就不用再向操作系统申请空间了,因为刚才分配的 32 字节已经够用了,这就避免了一次分配操作。但是,如果 Redis 每次向分配器申请的内存空间大小不一样,这种分配方式就会有形成碎片的风险。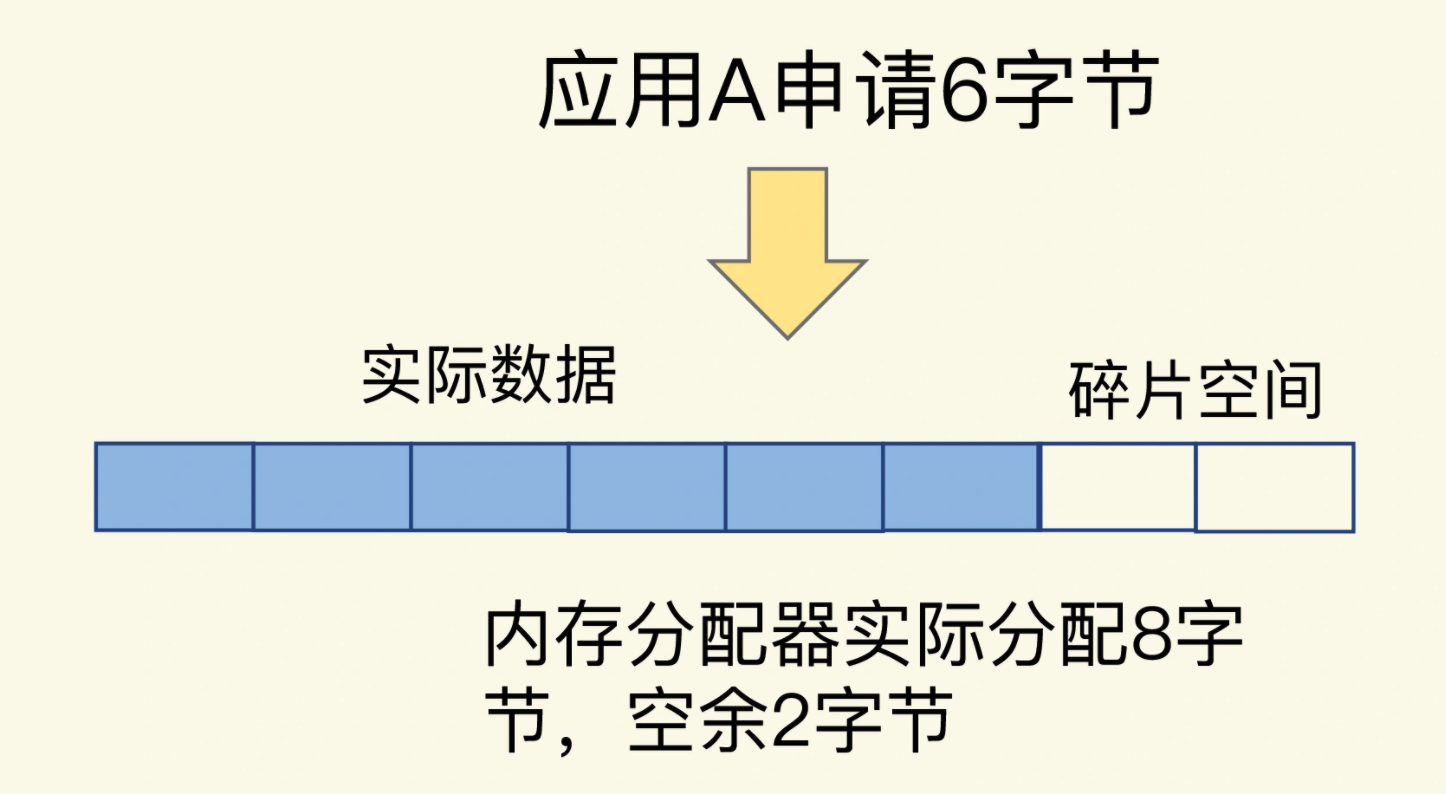
大量内存碎片的存在,会造成 Redis 的内存实际利用率变低,接下来,我们就要来解决这个问题了。不过,在解决问题前,我们要先判断 Redis 运行过程中是否存在内存碎片。
2. 监控内存碎片
Redis 是内存数据库,内存利用率的高低直接关系到 Redis 运行效率的高低。为了让用户能监控到实时的内存使用情况,Redis 自身提供了 INFO 命令,可以用来查询内存使用的详细信息,命令如下:
INFO memory# Memoryused_memory:1073741736used_memory_human:1024.00Mused_memory_rss:1997159792used_memory_rss_human:1.86G…mem_fragmentation_ratio:1.86
这里有一个 mem_fragmentation_ratio 的指标,它表示的就是 Redis 当前的内存碎片率。那么,这个碎片率是怎么计算的呢?其实,就是上面的命令中的两个指标 used_memory_rss 和 used_memory 相除的结果。
mem_fragmentation_ratio = used_memory_rss / used_memory
- used_memory_rss 是操作系统实际分配给 Redis 的物理内存空间,里面就包含了碎片;
- used_memory 是 Redis 为了保存数据实际申请使用的空间。
当 mem_fragmentation_ratio 的值大于 1 但小于 1.5 时,这种情况是合理的。因为内存碎片的产生是难以避免的,毕竟内存分配器的分配策略都是通用的,不会轻易修改;而 Redis 执行的命令操作也无法限制。但是,当 mem_fragmentation_ratio 大于 1.5 时,这表明内存碎片率已经超过了 50%。一般这个时候,我们就需要采取一些措施来降低内存碎片率了。
3. 清理内存碎片
从 Redis 4.0-RC3 版本以后,Redis 自身提供了一种内存碎片自动清理的方法。其实现机制简单来说就是搬家让位,合并空间。当有数据把一块连续的内存空间分割成好几块不连续的空间时,操作系统就会把数据拷贝到别处。此时,数据拷贝需要能把这些数据原来占用的空间都空出来,把原本不连续的内存空间变成连续的空间。否则,如果数据拷贝后,并没有形成连续的内存空间,这就不能算是清理了。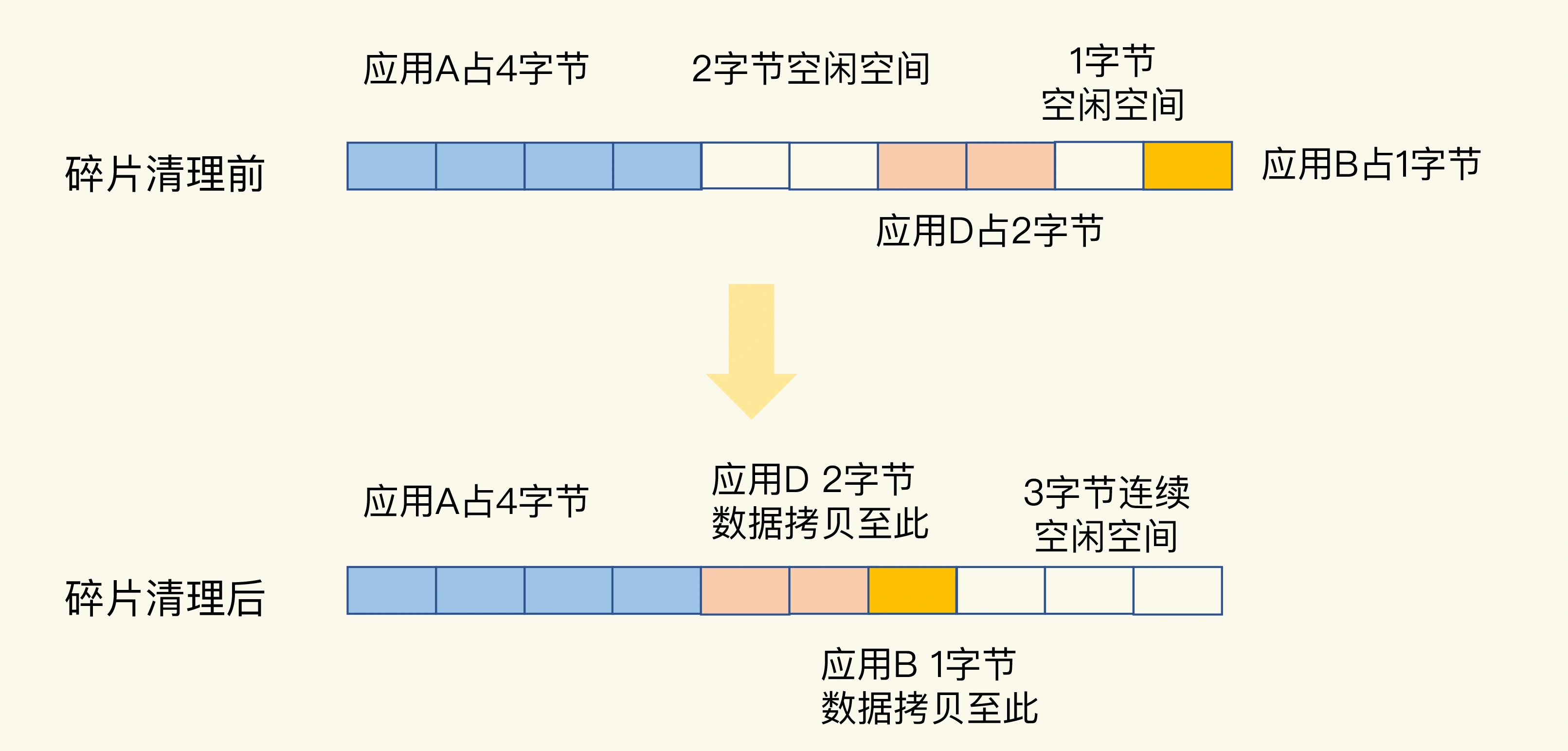
在进行碎片清理前,这段 10 字节的空间中分别有 1 个 2 字节和 1 个 1 字节的空闲空间,只是这两个空间并不连续。操作系统在清理碎片时,会先把应用 D 的数据拷贝到 2 字节的空闲空间中,并释放 D 原先所占的空间。然后,再把 B 的数据拷贝到 D 原来的空间中。这样这段 10 字节空间的最后三个字节就是一块连续空间了。
不过,需要注意的是:碎片清理是有代价的,操作系统需要把多份数据拷贝到新位置,把原有空间释放出来,这会带来时间开销。因为 Redis 是单线程,在数据拷贝时,Redis 只能等待,这就导致 Redis 无法及时处理客户端请求,导致性能降低。而且,有的时候,数据拷贝还需要注意顺序,如上例所示,操作系统需要先拷贝 D,并释放 D 的空间后,才能拷贝 B。这种顺序性的要求会进一步增加 Redis 的等待时间。
为此,Redis 专门为自动内存碎片清理机制设置了参数。我们可以通过设置参数,来控制碎片清理的开始和结束时机,以及占用的 CPU 比例,从而减少碎片清理对 Redis 本身请求处理的性能影响。首先,如果 Redis 要启用自动内存碎片清理机制,需要把 activedefrag 配置项设置为 yes,命令如下:
config set activedefrag yes
这个命令只是启用了自动清理功能,但具体什么时候清理会受到下面这两个参数的控制。这两个参数分别设置了触发内存清理的一个条件,如果同时满足这两个条件就开始清理。在清理的过程中,只要有一个条件不满足了就会停止自动清理:
- active-defrag-ignore-bytes 100mb:表示内存碎片的字节数达到 100MB 时,开始清理;
- active-defrag-threshold-lower 10:表示内存碎片空间占操作系统分配给 Redis 的总空间比例达到 10% 时,开始清理。
为了尽可能减少碎片清理对 Redis 正常请求处理的影响,自动内存碎片清理功能在执行时,还会监控清理操作占用的 CPU 时间,而且还设置了两个参数,分别用于控制清理操作占用的 CPU 时间比例的上、下限,既保证清理工作能正常进行,又避免了降低 Redis 性能。这两个参数具体如下:
- active-defrag-cycle-min 25: 表示自动清理过程所用 CPU 时间的比例不低于 25%,保证清理能正常开展;
- active-defrag-cycle-max 75:表示自动清理过程所用 CPU 时间的比例不高于 75%,一旦超过,就停止清理,从而避免在清理时,大量的内存拷贝阻塞 Redis,导致响应延迟升高。
最后,需要注意:内存碎片自动清理涉及内存拷贝,这对 Redis 而言是个潜在的风险。如果在实践过程中遇到 Redis 性能变慢,记得通过日志看下是否正在进行碎片清理。如果 Redis 的确正在清理碎片,那么建议你调小 active-defrag-cycle-max 的值,以减轻对正常请求处理的影响。

若有收获,就点个赞吧
0 人点赞
