就 Kafka 而言,越多的副本数越能够保证数据的可靠性,副本数可以在创建主题时配置,也可以在后期修改,不过副本数越多也会引起磁盘、网络带宽的浪费,同时会引起性能的下降。一般而言,设置副本数为 3 即可满足绝大多数场景对可靠性的要求,而对可靠性要求更高的场景下,可以适当增大这个数值。
acks 确认
仅依靠副本数来支撑可靠性是远远不够的,大多数人还会想到生产者客户端参数 acks。acks=-1 可以最大程度地提高消息的可靠性。对于 acks=1 的配置,生产者将消息发送到 leader 副本,leader 副本在成功写入本地日志后会告知生产者已经成功提交,如下图所示。如果此时 ISR 集合的 follower 副本还没来得及拉取到 leader 中新写入的消息,leader 就宕机了,那么此次发送的消息就会丢失。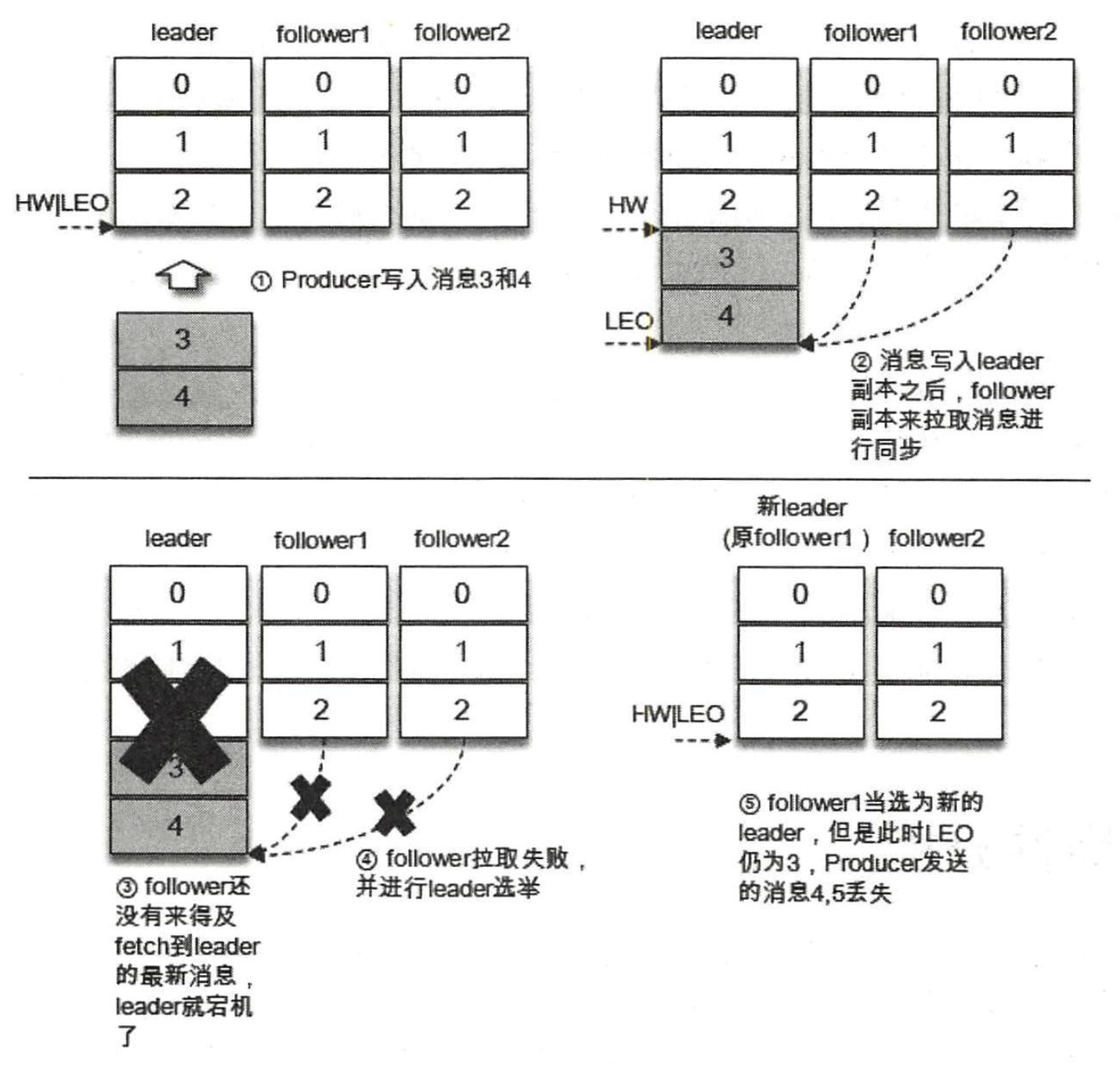
对于 ack=-1 的配置,生产者将消息发送到 leader 副本,leader 副本在成功写入本地日志之后还要等待 ISR 中的 follower 副本全部同步完成才能够告知生产者已经成功提交,即使此时 leader 副本宕机,消息也不会丢失,如下图所示: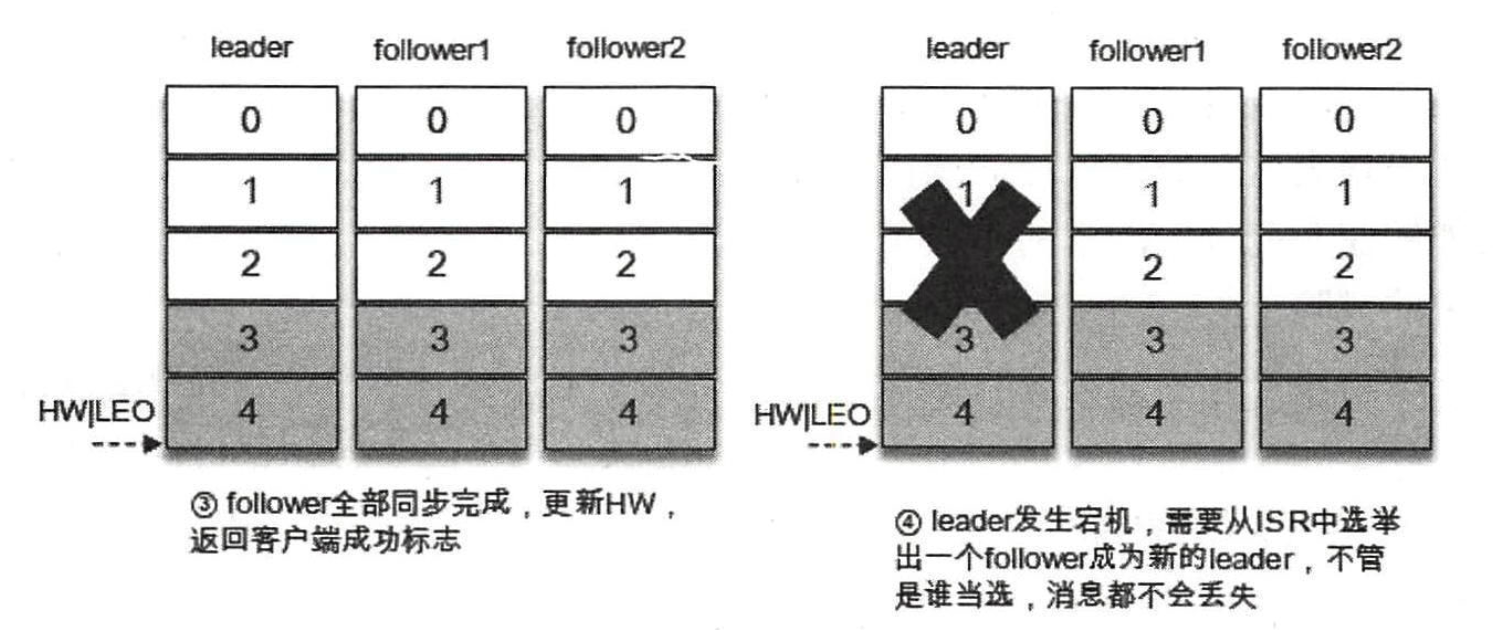
同样对于 acks=-1 的配置,如果在消息成功写入 leader 副本之后,并且在被 ISR 中的所有副本同步之前 leader副本宕机了,那么生产者会收到异常以此告知此次发送失败。
生产者发送模式
前面我们讨论了消息发送的三种模式,即发后即忘、同步和异步。对于发后即忘的模式,不管消息有没有被成功写入,生产者都不会收到通知,那么即使消息写入失败也无从得知,因此发后即忘的模式不适合高可靠性要求的场景。如果要提升可靠性,那么生产者可以采用同步或异步的模式,在出现异常情况时可以及时获得通知,以便可以做相应的补救措施,比如选择重试发送(可能会引起消息重复)。
有些发送异常属于可重试异常,比如 NetworkException,这个可能是由瞬时的网络故障而导致的,一般通过重试就可以解决。对于这类异常,如果直接抛给客户端的使用方也未免过于兴师动众,客户端内部本身提供了重试机制来应对这种类型的异常,通过 retries 参数即可配置。默认情况下,retries 参数设置为 0,即不进行重试,对于高可靠性要求的场景,需要将这个值设置为大于 0 的值,与 retries 参数相关的还有一个 retry.backoff.ms 参数,它用来设定两次重试之间的时间间隔,以避免无效的频繁重试。在配置 retries 和 retry.backoff.ms 之前,最好先估算一下可能的异常恢复时间,这样可以设定总的重试时间大于这个异常恢复时间,以此来避免生产者过早地放弃重试。如果不知道 retries 参数应该配置为多少,则可以参考 KafkaAdminClient,在 KafkaAdminClient 中 retries 参数的默认值为 5。
注意如果配置的 retries 参数值大于 0,则可能引起一些负面的影响。首先,由于默认的 max.in.flight.requests.per.connection 参数值为 5,这样可能会影响消息的顺序性,对此要么放弃客户端内部的重试功能,要么将该参数设置为 1,但这样也就放弃了吞吐。其次,有些应用对于时延的要求很高,很多时候都是需要快速失败的,设置 retries 大于 0 会增加客户端对于异常的反馈时延,可能对应用造成不良影响。
我们回头再来看一下 acks=-1 的情形,它要求 ISR 中所有的副本都收到相关的消息之后才能够告知生产者已经成功提交。试想一下这样的情形,leader 副本的消息流入速度很快,而 follower 副本的同步速度很慢,在某个临界点时所有的 follower 副本都被剔除出了 ISR 集合,那么 ISR 中只有一个 leader 副本,最终 acks=-1 就退化成了 acks=1 的情形,如此也就加大了消息丢失的风险。Kafka 也考虑到了这种情况,为此提供了 min.insync.replicas 参数(默认值为 1)来作为辅助配合 acks=-1 来使用,这个参数指定了 ISR 集合中最小的副本数,如果不满足条件就会抛出异常。在正常的配置下,需要满足副本数大于 min.insync.replicas 参数的值。一个典型的配置方案为:副本数配置为 3,min.insync.replicas 参数值配置为 2。注意 min.insync.replicas 参数在提升可靠性的时候会从侧面影响可用性。试想如果 ISR 中只有一个 leader 副本,那么最起码还可以使用,而此时如果配置 min.insync.replicas 大于 1,则会使消息无法写入。
unclean 选举
与可靠性和 ISR 集合有关的还有一个参数:unclean.leader.election.enable。这个参数的默认值为 false,如果设置为 true 就意味着当 leader 下线时可以从非 ISR 集合中选举出新的 leader,这样有可能造成数据的丢失。如果这个参数设置为 false,那么也会影响可用性,非 ISR 集合中的副本虽然没能及时同步所有的消息,但最起码还是存活的可用副本。随着 Kafka 版本的变更,有的参数被淘汰,也有新的参数加入进来,而传承下来的参数一般都很少会修改既定的默认值,而 unclean.leader.election.enable 就是这样一个反例,从 0.11.0.0 版本开始, unclean.leader.election.enable 的默认值由原来的 true 改为了 false,可以看出 Kafka 的设计者愈发地偏向于可靠性的提升。
日志刷盘策略
在 broker 端还有两个参数:log.flush.interval.messages 和 log.flush.interval.ms 用来调整同步刷盘的策略,默认是不做控制而交由操作系统本身来进行处理。同步刷盘是增强一个组件可靠性的有效方式,Kafka 也不例外,但在绝大多数情景下,一个组件(尤其是大数据量的组件)的可靠性不应该由同步刷盘这种极其损耗性能的操作来保障,而应该采用多副本的机制来保障。
自动位移提交
对于消息的可靠性,很多人都会忽视消费端的重要性,如果一条消息成功地写入 Kafka,并且也被 Kafka 完好地保存,而在消费时由于某些疏忽造成没有消费到这条消息,那么对于应用来说,这条消息也是丢失的。
enable.auto.commit 参数的默认值为 true,即开启自动位移提交的功能,虽然这种方式非常简便,但它会带来重复消费和消息丢失的问题,对于高可靠性要求的应用来说显然不可取,所以需要将 enable.auto.commit 参数设置为 false 来执行手动位移提交。在执行手动位移提交的时候也要遵循一个原则:如果消息没有被成功消费,那么就不能提交所对应的消费位移。对于高可靠要求的应用来说,宁愿重复消费也不应该因为消费异常而导致消息丢失。有时候,由于应用解析消息的异常,可能导致部分消息一直不能够成功被消费,那么这个时候为了不影响整体消费的进度,可以将这类消息暂存到死信队列中,以便后续的故障排除。
对于消费端,Kafka 还提供了一个可以兜底的功能,即回溯消费,通过这个功能可以让我们能够有机会对漏掉的消息相应地进行回补,进而可以进一步提高可靠性。

若有收获,就点个赞吧
0 人点赞
