集群节点规划
1. 节点数规划
当我们计划搭建一个 Elasticsearch 集群的时候,面临的第一个问题是这个集群需要多少个节点?一个集群中有多少个节点受多种因素的影响,就数据量而言,如果数据量不大,那么几台机器就能满足需求;如果数据量非常庞大,需要几百台机器也是有可能的。一个集群中使用的硬件资源要根据业务的数据量大小来确定,如果条件允许的话,服务器性能和服务器数量当然是多多益善。
通常需要考虑的一些因素主要有:
- 机器的软硬件配置,如果存在大量写入的场景最好使用 SSD
- 单个文档的大小、文档的总量、索引的总数据量、副本分片数
- 文档的复杂度
- 查询的吞吐量、查询时是否有复杂的查询、聚合操作,有复杂查询场景建议配置单独的协调节点
另一方面,需要控制最大集群规模和数据总量,参考下列两个限制条件:
- 节点总数不应该太多,一般来说,最大集群规模最好控制在 100 个节点左右。
- 单个分片不要超过 50GB,最大集群分片总数控制在几十万的级别。太多分片同样增加了主节点的管理负担,而且集群重启恢复时间会很长。
建议为集群配置较好的硬件,而不是普通的 PC,搜索对 CPU、内存、磁盘的性能要求都很高,要达到比较低的延迟就需要较好的硬件资源。另外,如果使用不同配置的服务器混合部署,则搜索速度可能会取决于最慢的那个节点,产生长尾效应。
2. Master 节点数规划
节点数确定以后会面临第二个问题:集群应该设置多少个 master 节点?在回答这个问题前,我们先来了解一下什么是脑裂。所谓脑裂问题,就是同一个集群中的不同节点对于集群的状态有了不一样的理解,脑裂问题是分布式集群环境中必然会遇到的问题。
首先看一个有两个节点的 Elasticsearch 集群的简单情况。集群维护一个单个索引并有一个分片和一个副本。如下图所示,节点 1 在启动时被选举为主节点并保存主分片(0P),而节点 2 保存副本分片(0R)。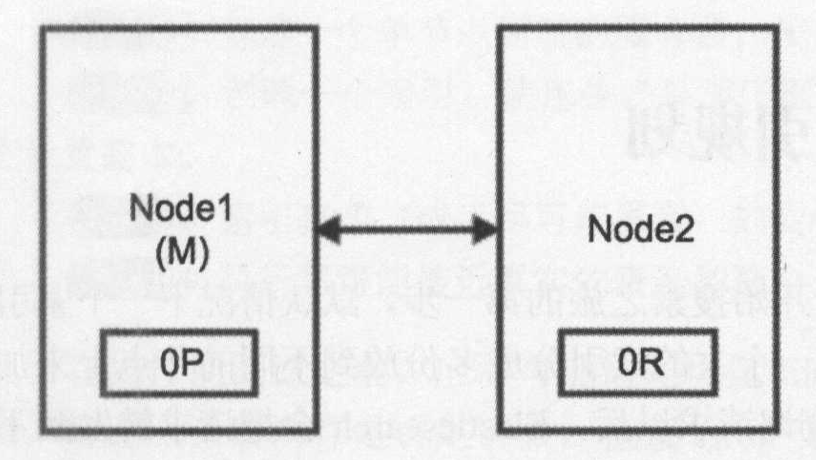
假设现在由于网络问题或其他原因,两个节点之间的通信发生中断,如下图所示: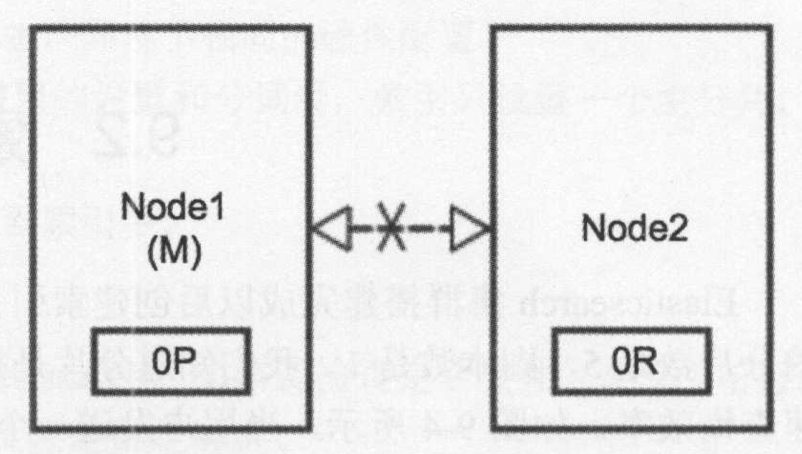
这时两个节点都相信对方己经挂了,节点 1 不需要做什么,因为它本身就被选举为主节点,但是节点 2 会自动选举它自己为主节点,因为节点 2 和集群的主机点之间已经无法通信了,如下图所示。在 Elasticsearch 集群中是由主节点来决定将分片分配到从节点的,节点 2 保存的是副本分片,但它相信主节点不可用了,所以它会自动提升从节点为主节点 。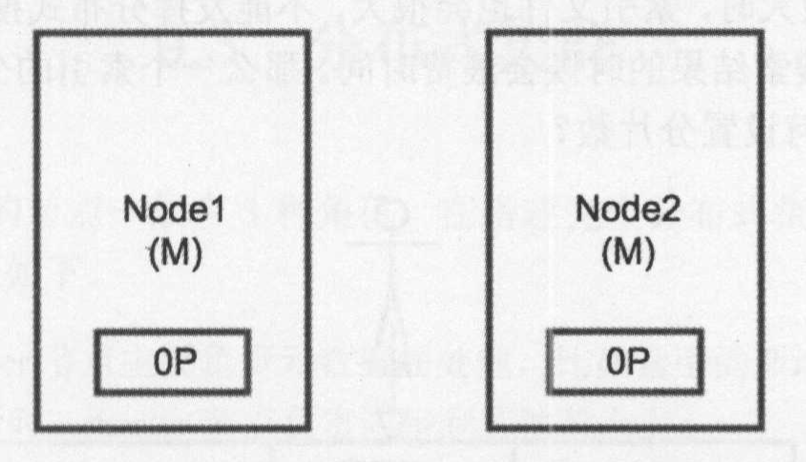
现在集群处于不一致的状态,发送到节点 1 上的索引请求不会将数据分配到节点 2 上,同时发送到节点 2 的请求也不会将数据分配到节点 1 上。在这种情况下,分片的两份数据分开了,并且这个问题非常透明难以发现,因为请求仍会成功完成,问题只有在搜索数据时才会被隐约发现。
要避免脑裂的发生,可以在 elasticsearch.yml 配置文件中配置 discovery.zen.minimum_master_nodes 参数来指定在主节点选择过程中最少需要有多少个 master 节点,默认是 1。一个基本原则是要设置成 ,其中 N 是集群中候选主节点的数量。例如在一个 3 节点的集群中,该配置应该被设为 2。因此在集群配置下建议配置一个 3 节点集群,这样可以减少脑裂的可能性并最大限度地提升集群的高可用性。
避免脑裂的另一个参数是 discovery.zen.ping_timeout,默认值是 3 秒,它用来决定节点之间网络通信的等待时间。如果网络环境较差,可以将这个值调的大一点。这个参数不仅适用于高网络延迟的情况,还能在一个节点超载响应慢时起作用。
从 Elasticsearch 7.0 版本之后,使用了全新的集群协调子系统,移除了 minimum_master_nodes 参数,能够让 Elasticsearch 自己选择最少需要的 master 节点数量。典型的主节点选举现在只需很短时间就能完成,集群的扩充和缩减变得更加安全和简单,并且大幅降低了因系统配置不当而可能造成数据丢失的风险。
新版参考:https://www.elastic.co/cn/blog/a-new-era-for-cluster-coordination-in-elasticsearch
索引分片规划
集群搭建完成后创建索引是开始搜索之旅的第一步,当用户发送一个查询请求后,Elasticsearch 会把请求转发到不同的节点上,分别到各个分片上进行搜索,然后把各个分片的搜索结果合并,最后返回搜索结果。当分片过少数据量很大时,索引文件也会很大,不能发挥分布式搜索的优点;当分片数过多,在分发查询请求及合并搜索结果时又会浪费时间。那创建索引时应该如何规划分片数呢?
分片数量的确定从根本上来讲是看查询的效率,有些情况下响应时间要求是毫秒级,有些情况下要求是秒级,所以分片的数量以能够最大化查询效率为原则。查询的响应时间受多个变量影响,挑出一些重要的总结如下:
- 服务器的性能:服务器的内存大小、CPU 性能等参数对查询效率有很大的影响。同样的数据分成相同多个分片,性能好的服务器响应时间更快。
- 硬盘:使用机械硬盘和 SSD 在性能上有着很大的差别,同样的数据,在普通硬盘上的查询时间不能满足系统对响应时间的要求,也许数据放到 SSD 上就能满足。
- 文档结构的复杂度:复杂结构的文档比结构简单的文档需要消耗更多的资源,查询时间也会延长,文档结构的复杂程度会影响搜索效率。
- 查询语句的复杂程度:复杂查询,尤其是嵌套搜索、聚合分析会比简单查询更加耗时。
我们可以先进行单机性能测试,使用生产环境下相同的硬件配置只设置一个主分片,执行尽可能接近真实的查询和聚合。通过测试一台服务器上的一个分片来估算 N台服务器的性能,一旦获取单个分片的性能再考虑整个文档的大小及预期的增长等因素就可以确定 N 台服务器下的分片数。
从 Elasticsearch 7.0 版本开始,新创建一个索引时,默认只有一个主分片。在单分片情况下,查询算分、聚合不准的问题都可以得到解决,但是单分片即使增加新的节点,无法实现水平扩展。实际上,在分片数大于节点数的情况下,集群增加一个节点后,Elasticsearch 会自动进行分片的移动,也叫 Shard Rebalancing,并且分片在重新分配时,系统不会暂停服务。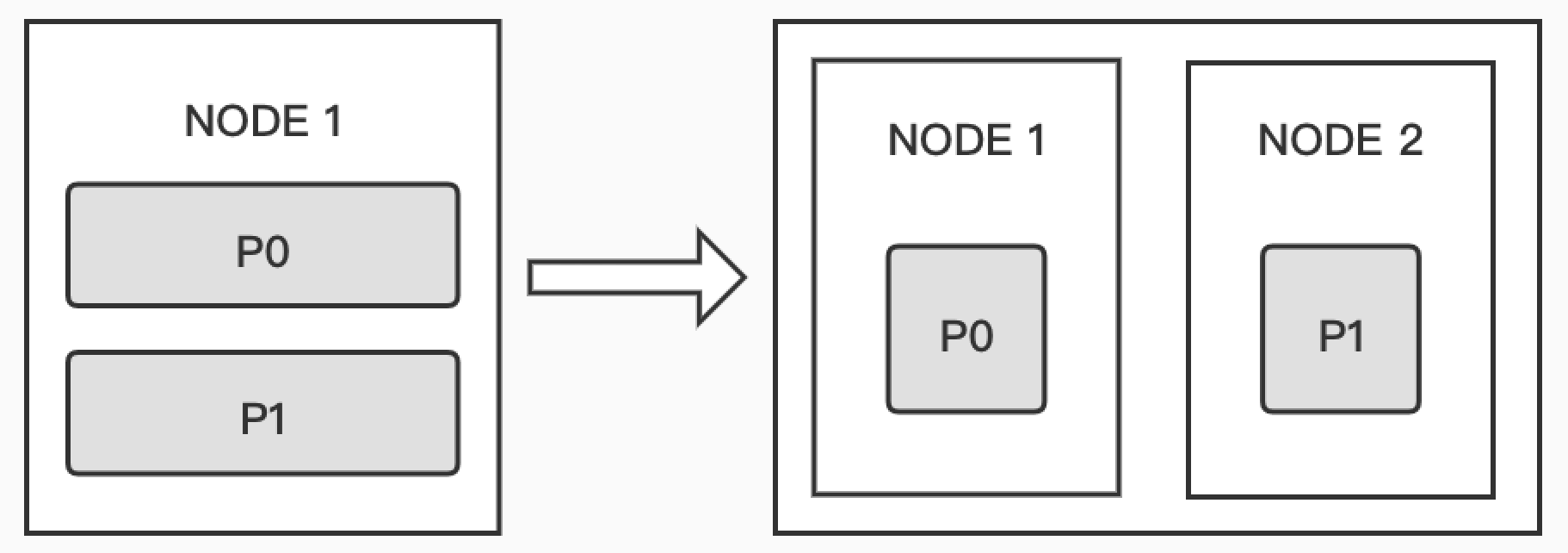
但是分片过多也会带来一些副作用:
- 每个分片是一个 Lucene 的索引,过多的分片会导致额外的性能开销,包括内存、文件描述符等
- 每次搜索的请求,需要从每个分片上获取数据,分片过多会影响性能
- 分片的 meta 信息由 Master 节点维护,分片过多会增加管理的负担
避免热索引分配不均:
默认情况下,ES 的分片均衡策略是尽量保持各个节点分片数量大致相同。但是当集群扩容时,新加入集群的节点没有分片,此时新创建的索引分片会集中在新节点上,这导致新节点拥有太多热点数据,该节点可能会面临巨大的写入压力。因此,对于一个索引的全部分片,我们需要控制单个节点上存储的该索引的分片总数,使索引分片在节点上分布得更均匀一些。
例如,10 个节点的集群,索引主分片数为 5,副本数量为 1,那么平均下来每个节点应该有 (5×2)/10=1 个分片,考虑到节点故障、分片迁移的情况,可以设置节点分片总数为 2:
curl -X PUT "localhost:9200/myindex/_settings?pretty" -H 'Content-Type: application/json' -d'{"index" : {"routing.allocation.total_shards_pre_node" : 2}}'

若有收获,就点个赞吧
0 人点赞
