环境:
- 4台服务器:
| NameNode | SenondaryNameNode | DataNode | |
|---|---|---|---|
| node01 | ✅ | ||
| node02 | ✅ | ✅ | |
| node03 | ✅ | ||
| node04 | ✅ |
- Hadoop版本:Hadoop3.1.1
一、配置主节点JDK
1.1、步骤:略
JAVA_HOME=/app/ratels/basic-service/java/jdk1.8.0_201
1.2、SCP
scp到其他node上
二、配置主节点node01
2.1、配置环境变量
编辑 ~/.bash_profile
JAVA_HOME=/app/ratels/basic-service/java/jdk1.8.0_201CLASS_PATH=$JAVA_HOME/libHADOOP_HOME=/app/ratels/basic-service/hadoop/hadoop3/hadoop-3.1.1PATH=$PATH:$HOME/bin:$JAVA_HOME/bin:$HADOOP_HOME/bin:$HADOOP_HOME/sbinexport PATH
修改 ${HADOOP_HOME}/etc/hadoop/下面的文件:
2.2、hadoop-env.sh
设置jdk路径、设置namenode、datanode、secondarynamenode这三个节点对应的角色
export JAVA_HOME=/app/ratels/basic-service/java/jdk1.8.0_201export HDFS_NAMENODE_USER=rootexport HDFS_DATANODE_USER=rootexport HDFS_SECONDARYNAMENODE_USER=root
2.3、设置core-site.xml
主要对namenode节点进行设置
<configuration><property><name>fs.defaultFS</name><!-- 其中:ip不能写localhost,因为其他节点不能识别,可以写域名或者真实ip;--><!-- 端口根据hadoop版本修改,hadoop3.1.1端口为9820 --><value>hdfs://node01:9820</value></property><property><!-- 该临时目录在保存namenode元数据使用、保存datanode分割的数据存储使用;--><!-- 不能使用默认的,因为默认的会随着集群不可用删除掉 --><name>hadoop.tmp.dir</name><value>/app/ratels/basic-service/hadoop/hadoop3/full</value></property></configuration>
2.4、设置hdfs-site.xml
主要对从节点进行设置
<configuration><property><name>dfs.replication</name><!-- 配置成2或者3 --><value>1</value></property><property><!-- 参考hdfs-default.xml --><name>dfs.namenode.secondary.http-address</name><value>node02:9868</value></property></configuration>
2.5、设置works
对集群中从节点(secondarynamenode、datanode)的ip设置
node02node03node04
二、配置从节点:node02、node03、node04
使用 scp 将node01上的配置copy到各个从节点上,配置不需要改变
scp -r /app/ratels/basic-service/hadoop/hadoop3 root@node02:`pwd`
三、启动全分布式
3.1 配置环境变量
目的:为了在任意目录下使用hadoop相关命令和启动脚本;
如果已经配置,可忽略
3.2 启动全分布式
操作:
在node01上运行
hdfs namenode -format1.生成集群公用的clusterID: cat /xxx/${hadoop.tmp.dir}/dfs/name/current/VERSION2.初始化元数据信息到hadoop.tmp.dirstart-dfs.sh1.该步骤会在各个集群节点上启动对应的子节点ss -nal:查看监听端口访问 node01:9870
上面搭建好之后,主节点是单实例的,没有做到高可用;其中SecondaryNameNode不是NameNode的备份,是做持久化合并操作;
四、问题
问题1:在执行start-dfs.sh命令时,出现下面问题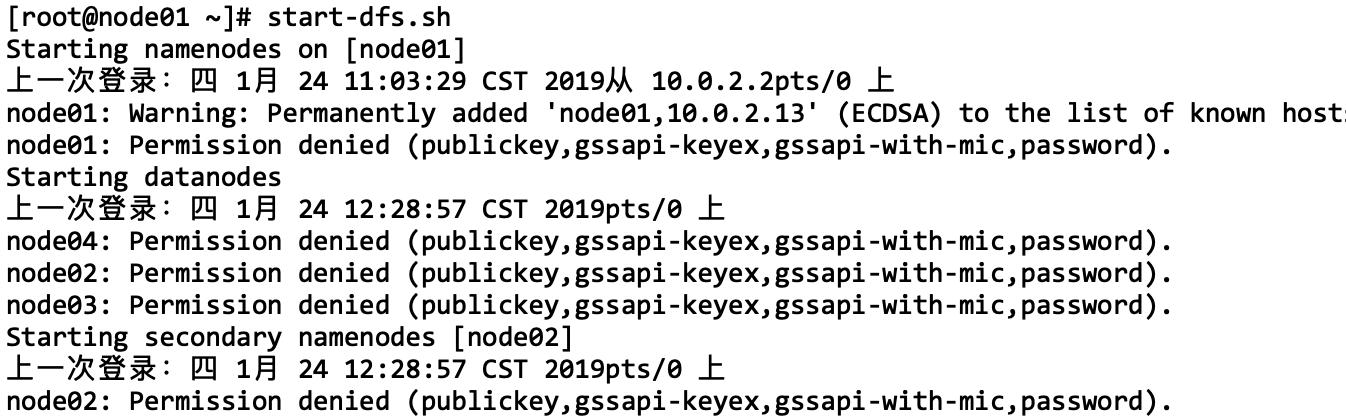
解决方案:
出现上面问题的原因是因为各个主机之间没有配置免密登录,如何配置免密登录,方法:https://www.yuque.com/wells/big.data/ekxh6e

若有收获,就点个赞吧
0 人点赞
