一、standalone部署
1.1、下载相关tar包
下载链接:https://www.apache.org/dyn/closer.lua/flink/flink-1.10.0/flink-1.10.0-bin-scala_2.11.tgz
注意:如果需要集成hadoop,那么可能需要下载 flink-1.7.0-bin-hadoop27-scala_2.11.tgz 带有hadoop版本的,下载链接我在官网没找到;😂😂😂
1.2、解压 & 配置
- 解压:tar -zxvf flink-1.10.0-bin-scala_2.11.tgz
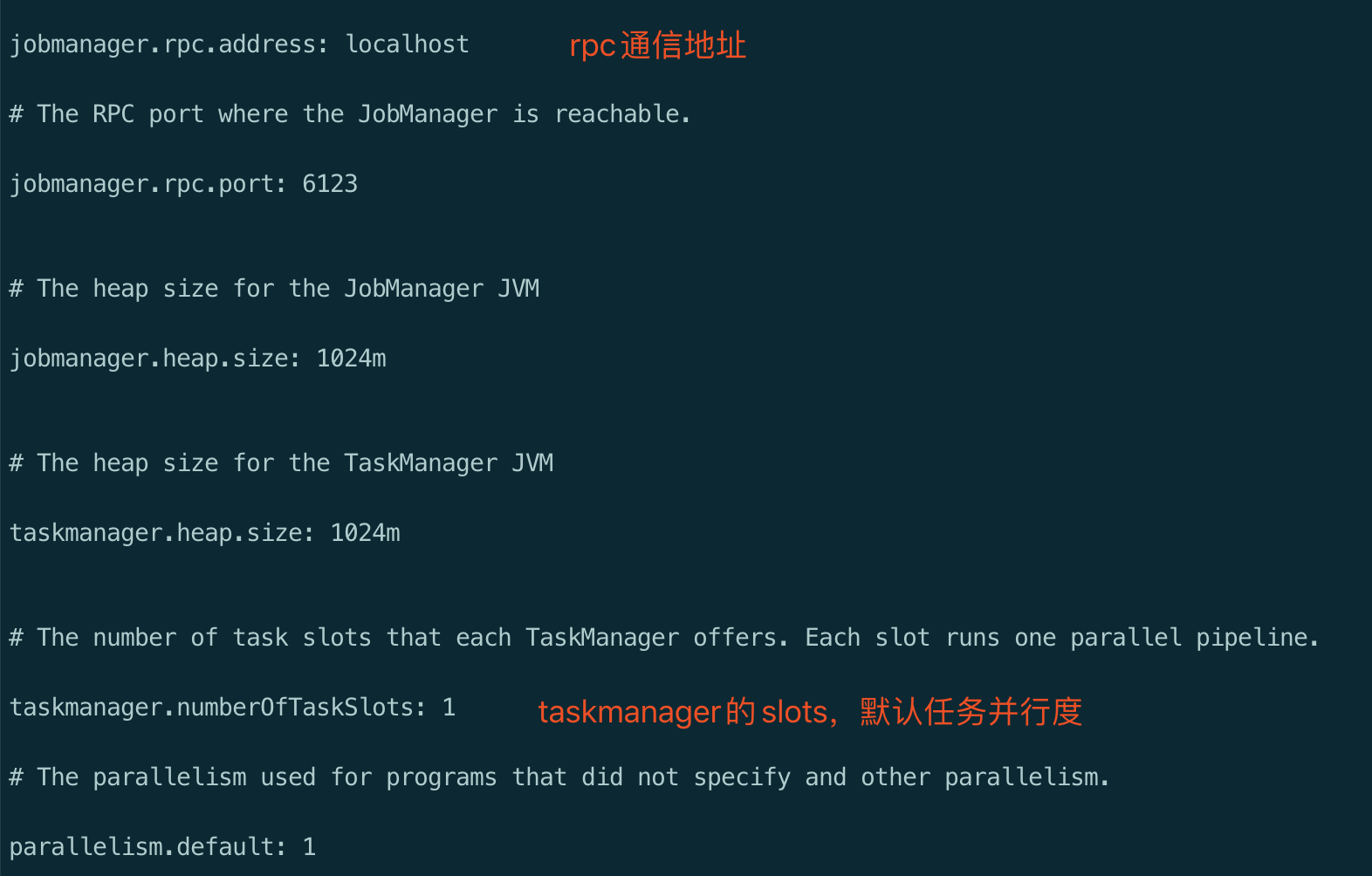
- 修改 flink/conf/flink-conf.yaml 文件,根据需要修改
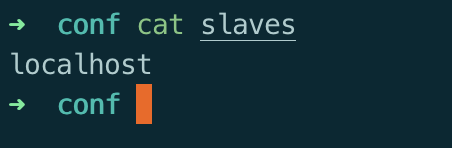
- 修改 /conf/slave文件
- 启动
./bin/start-cluster.sh
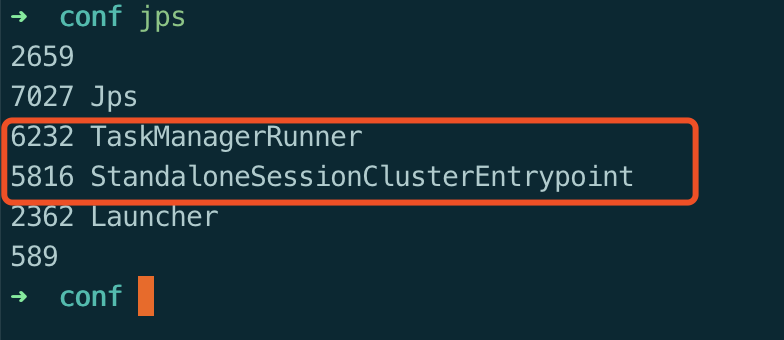
- 查看进程
1.3、提交任务
命令提交
flink run -c com.wells.flink.demo.batch.BatchTest flink-demo-1.0.0.jar /Users/wells/Projects/04-GitHub/java/flink-demo/src/main/resources/wordCountFile.txt

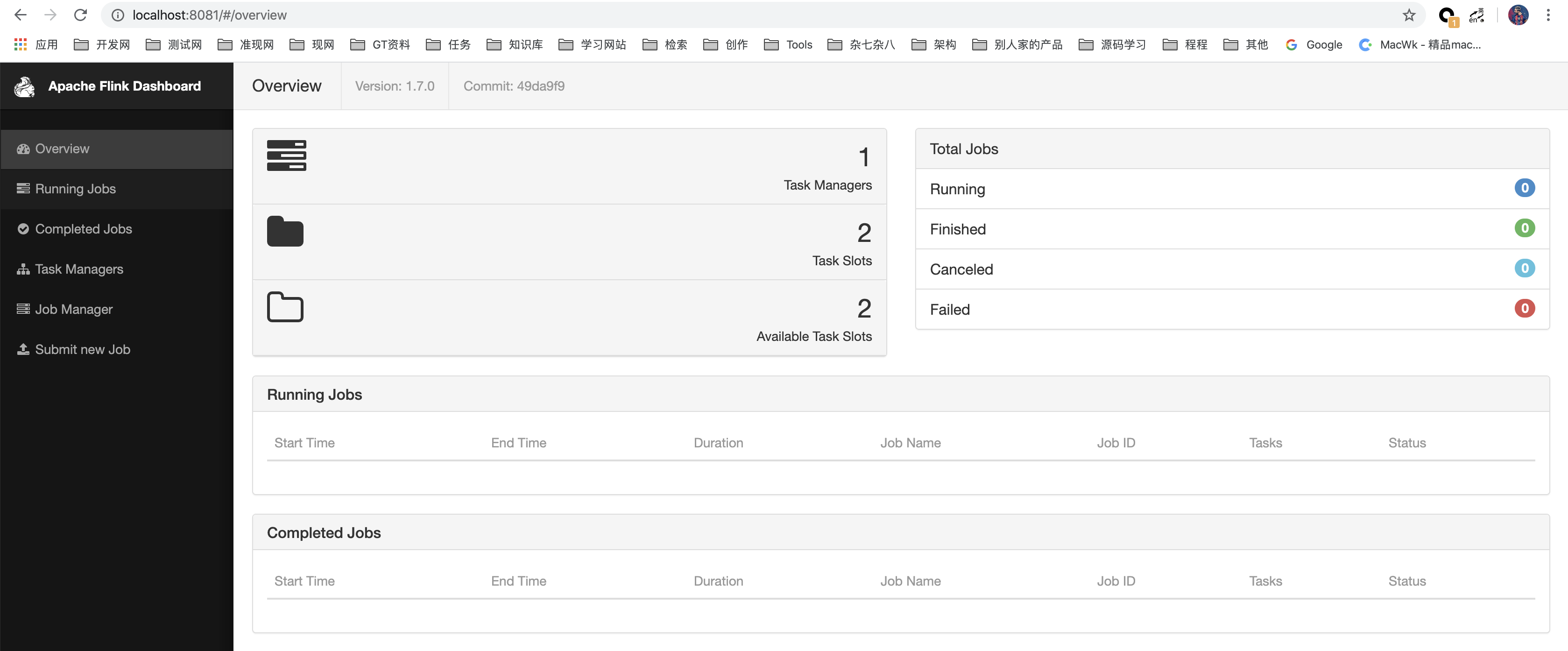
页面提交 & 运行
提交:
运行: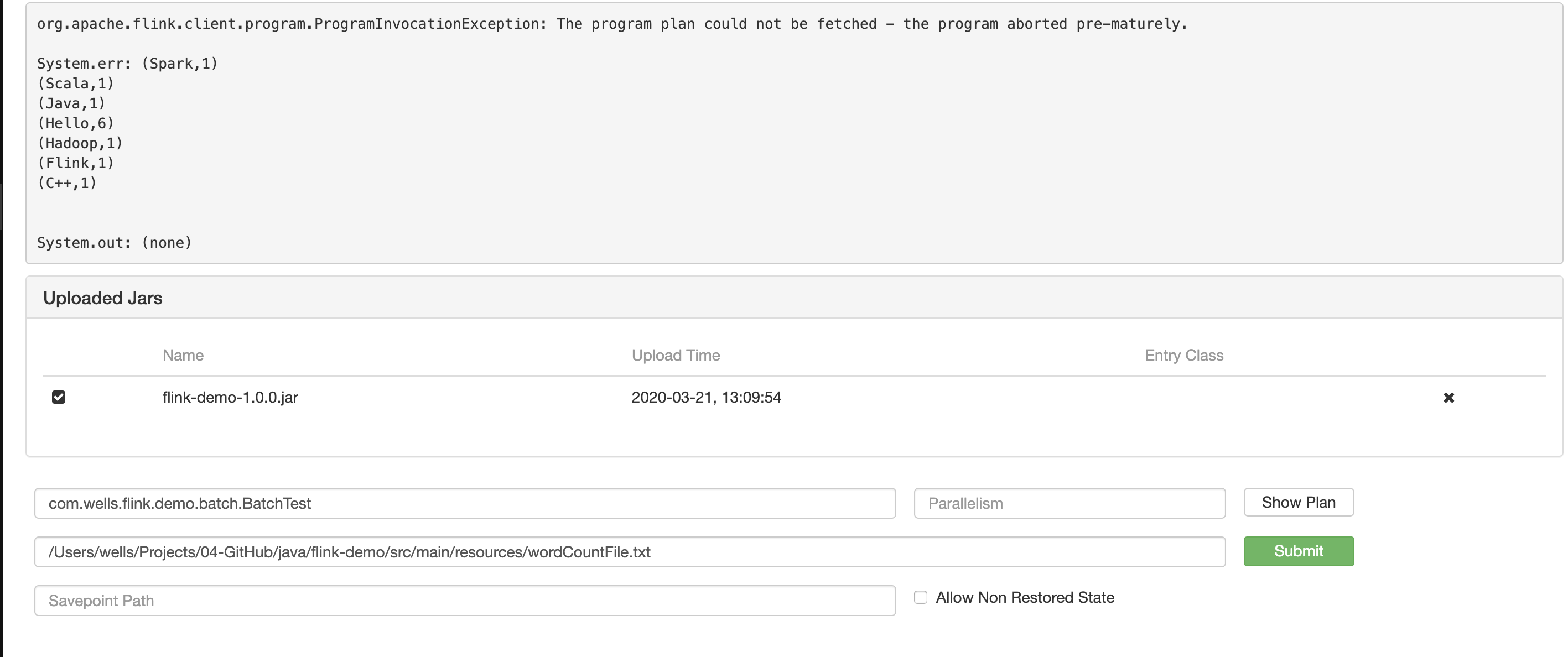
二、yarn模式
2.1、启动Hadoop集群

具体Hadoop如何搭建以及启动,参考:https://www.yuque.com/wells/big.data/mbckdq
yarn地址: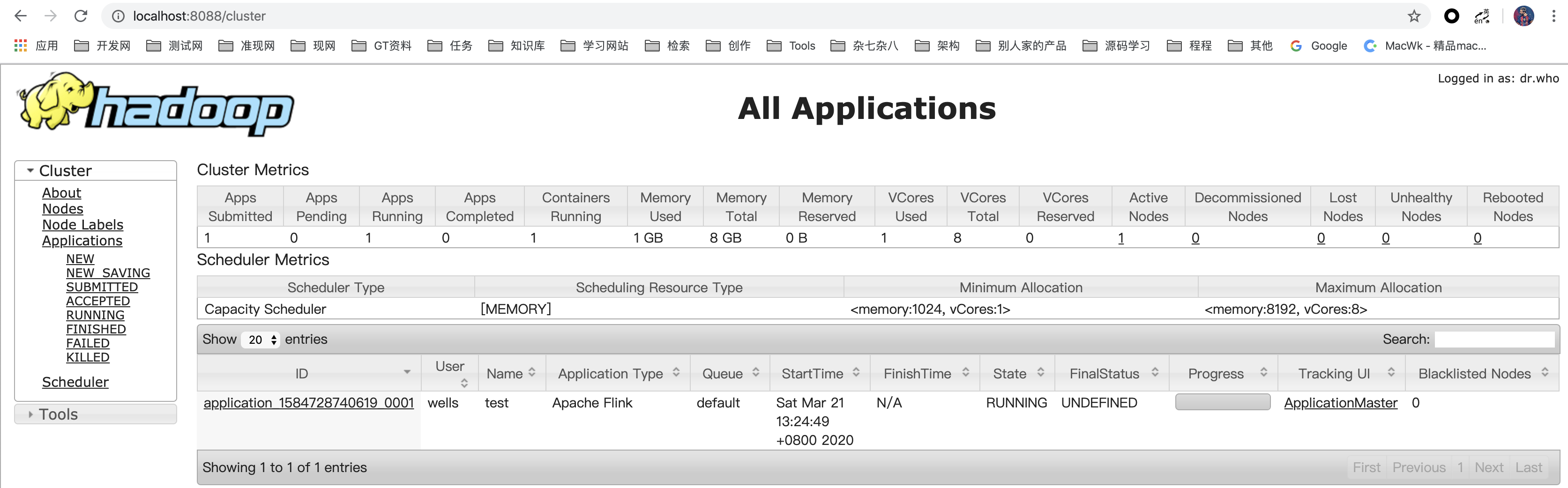
2.2、启动 yarn-session
./yarn-session.sh -n 2 -s 2 -jm 1024 -tm 1024 -nm test -d
参数说明:
- -n(—container):TaskManager的数量
- -s(—slots): 每个TaskManager的slot数量,默认一个slot一个core,默认每个taskmanager的slot的个数为1,有时可以多一些taskmanager,做冗余
- -jm:JobManager的内存(单位MB)
- -tm:每个taskmanager的内存(单位MB)
- -nm:yarn 的appName(现在yarn的ui上的名字)
- -d:后台执行
启动日志如下: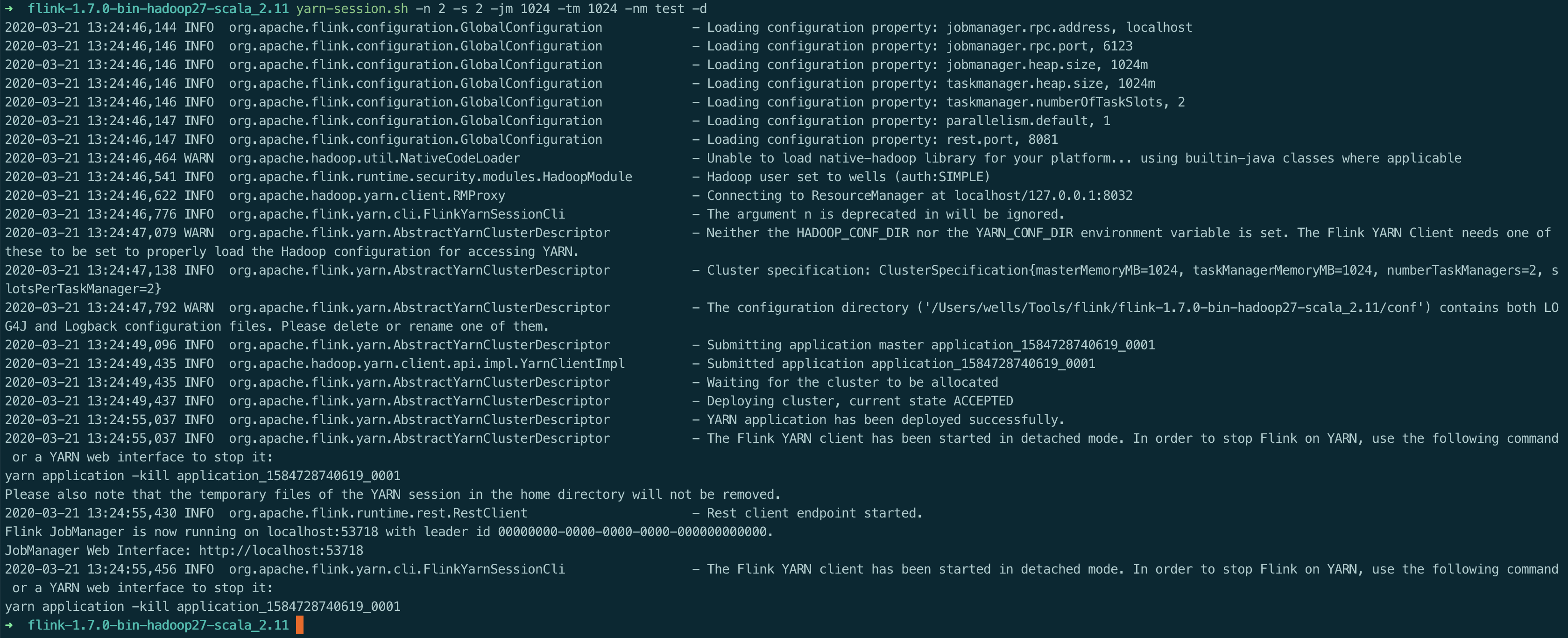
2.3、提交任务
依然可以通过flink默认端口,访问flink web:http://localhost:8088/
命令提交
flink run -m yarn-cluster -c com.wells.flink.demo.streaming.StreamingTest flink-demo-1.0.0.jar localhost 9090
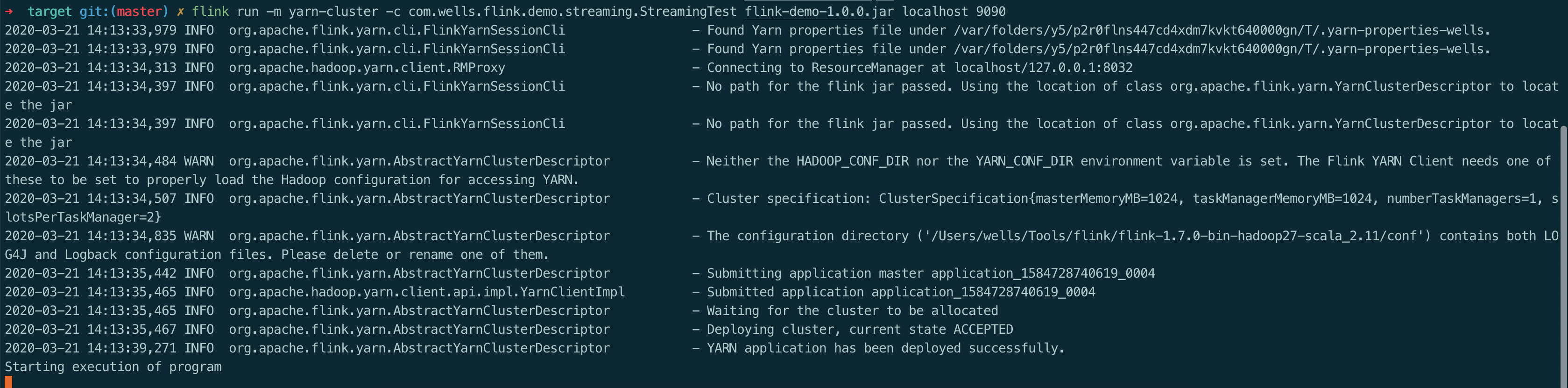
yarn展示
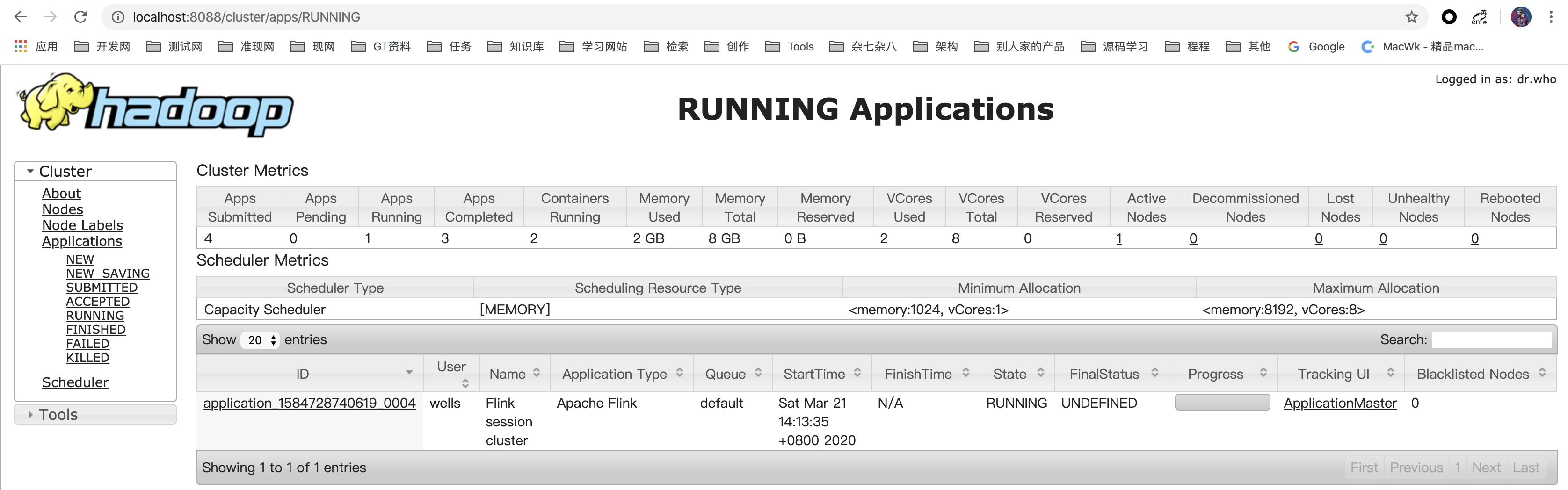
测试
输入: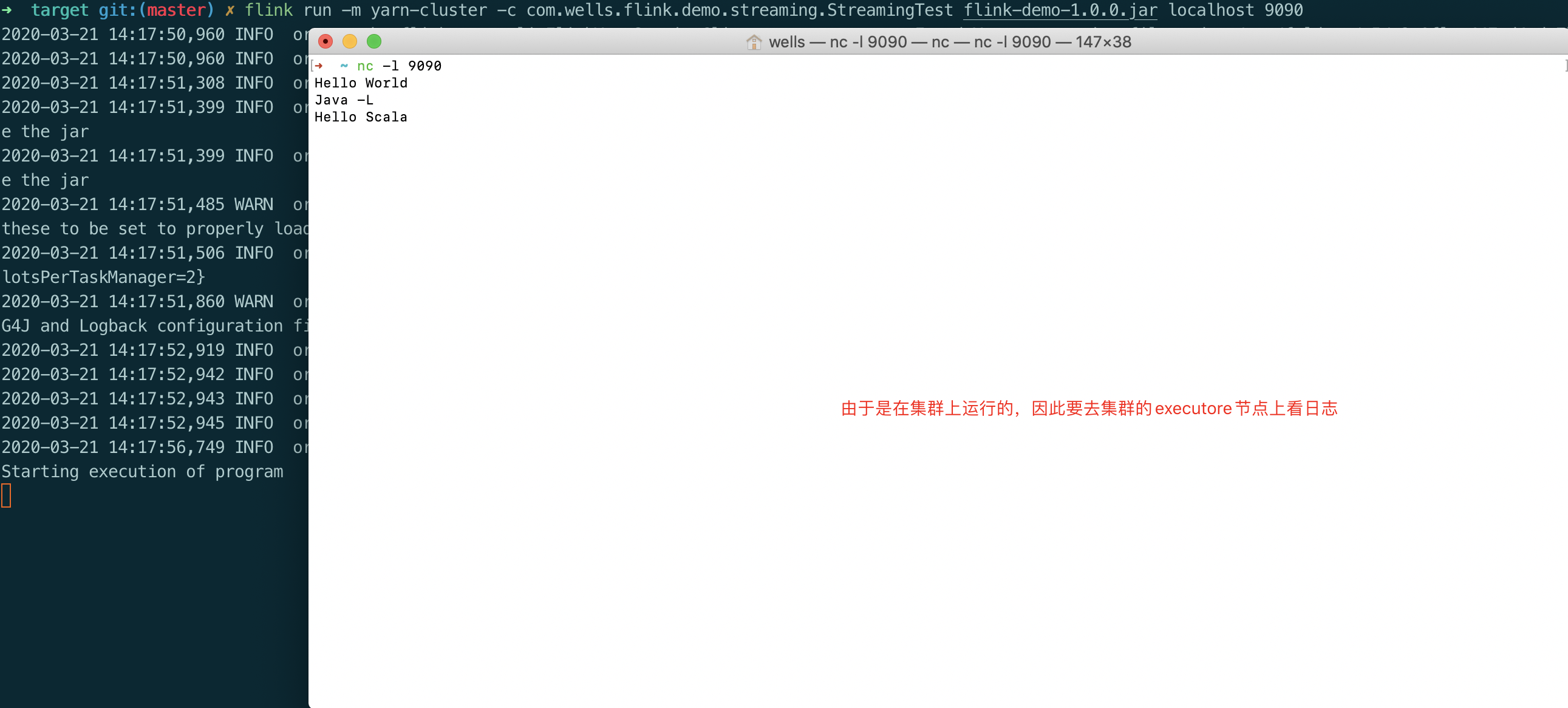
输出: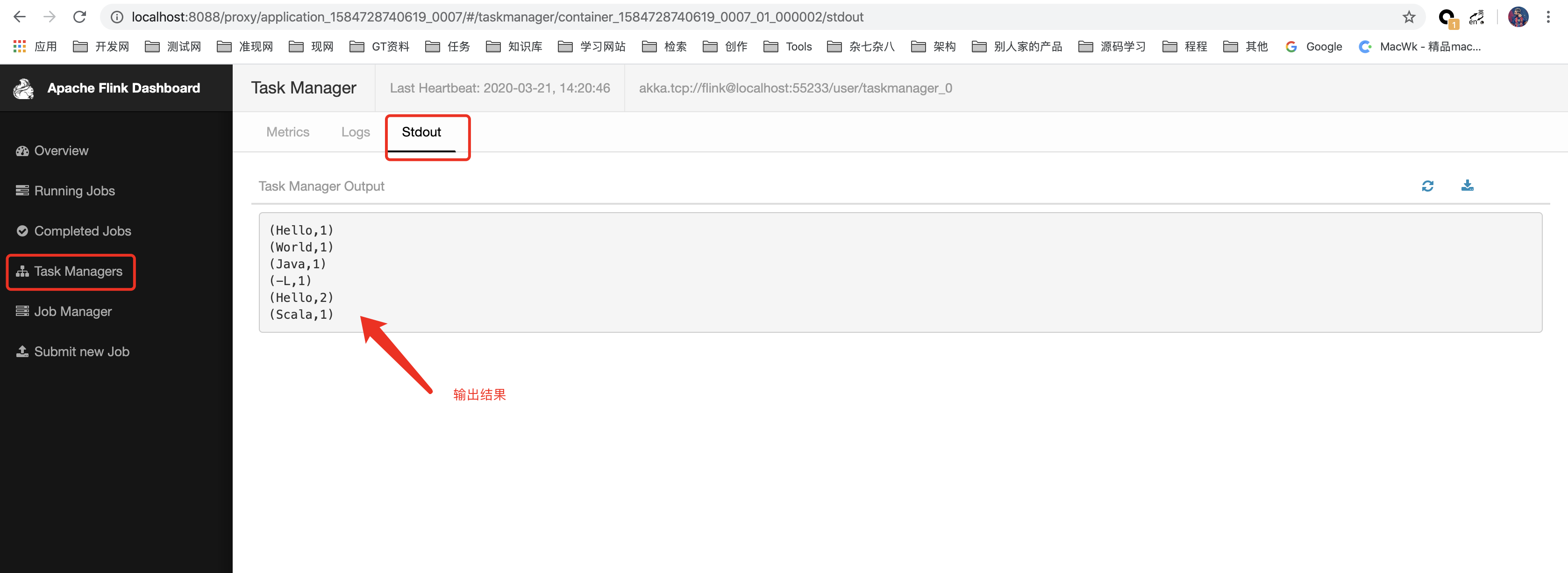

若有收获,就点个赞吧
0 人点赞
