一、前言
Flink 做为一款流式计算框架,它可用来做批处理,即处理静态的数据集、历史的数据集;也可以用来做流处理,即实时的处理些实时数据流,实时的产生数据流结果,只要数据源源不断的过来,Flink 就能够一直计算下去,这个 Data Sources 就是数据的来源地。
Flink 已经提供了若干实现好了的 source functions,当然你也可以通过实现 SourceFunction 来自定义非并行的 source 或者实现 ParallelSourceFunction 接口或者扩展 RichParallelSourceFunction 来自定义并行的 source
StreamExecutionEnvironment 中可以使用以下几个已实现的 stream sources,总的来说可以分为以下几个大类:
二、基于集合
- fromCollection(Collection):从 Java 的 Java.util.Collection 创建数据流。集合中的所有元素类型必须相同。
- fromCollection(Iterator, Class):从一个迭代器中创建数据流。Class 指定了该迭代器返回元素的类型。
- fromElements(T …):从给定的对象序列中创建数据流。所有对象类型必须相同。 ```java package com.wells.flink.demo.sources;
import com.wells.flink.demo.entity.Person; import org.apache.flink.streaming.api.datastream.DataStreamSource; import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
/**
- Description
- Created by wells on 2020-05-06 20:02:11 */
public class FromElementsSourceTest { public static void main(String[] args) throws Exception { StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
DataStreamSource<Person> personDataStreamSource = env.fromElements(new Person("tom", 23, "man"),new Person("jerry", 2, "woman"));personDataStreamSource.print();env.execute();}
}
- fromParallelCollection(SplittableIterator, Class):从一个迭代器中创建并行数据流。Class 指定了该迭代器返回元素的类型。- generateSequence(from, to):创建一个生成指定区间范围内的数字序列的并行数据流。<a name="4F95C"></a># 三、基于文件- readTextFile(path) - 读取文本文件,即符合 TextInputFormat 规范的文件,并将其作为字符串返回。- readFile(fileInputFormat, path) - 根据指定的文件输入格式读取文件(一次)。- readFile(fileInputFormat, path, watchType, interval, pathFilter, typeInfo) - 这是上面两个方法内部调用的方法。它根据给定的 fileInputFormat 和读取路径读取文件。根据提供的 watchType,这个 source 可以定期(每隔 interval 毫秒)监测给定路径的新数据(FileProcessingMode.PROCESS_CONTINUOUSLY),或者处理一次路径对应文件的数据并退出(FileProcessingMode.PROCESS_ONCE)。你可以通过 pathFilter 进一步排除掉需要处理的文件。```javapackage com.wells.flink.demo.sources;import org.apache.flink.api.java.io.TextInputFormat;import org.apache.flink.core.fs.Path;import org.apache.flink.streaming.api.datastream.DataStreamSource;import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;import org.apache.flink.streaming.api.functions.source.FileProcessingMode;/*** Description 可以检测文件内容变化和文件新增* Created by wells on 2020-05-06 20:14:42*/public class FileSourceTest {public static void main(String[] args) throws Exception {StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();String filePath = "/Users/wells/Temp/data/wordcount";DataStreamSource<String> stringDataStreamSource = env.readFile(new TextInputFormat(new Path(filePath)), filePath, FileProcessingMode.PROCESS_CONTINUOUSLY, 1000);stringDataStreamSource.print();env.execute();}}
实现:
在具体实现上,Flink 把文件读取过程分为两个子任务,即目录监控和数据读取。每个子任务都由单独的实体实现。目录监控由单个非并行(并行度为1)的任务执行,而数据读取由并行运行的多个任务执行。后者的并行性等于作业的并行性。单个目录监控任务的作用是扫描目录(根据 watchType 定期扫描或仅扫描一次),查找要处理的文件并把文件分割成切分片(splits),然后将这些切分片分配给下游 reader。reader 负责读取数据。每个分片只能由一个 reader 读取,但一个 reader 可以逐个读取多个切分片。
重要注意:
如果 watchType 设置为 FileProcessingMode.PROCESS_CONTINUOUSLY,则当文件被修改时,其内容将被重新处理。这会打破“exactly-once”语义,因为在文件末尾附加数据将导致其所有内容被重新处理。
如果 watchType 设置为 FileProcessingMode.PROCESS_ONCE,则 source 仅扫描路径一次然后退出,而不等待 reader 完成文件内容的读取。当然 reader 会继续阅读,直到读取所有的文件内容。关闭 source 后就不会再有检查点。这可能导致节点故障后的恢复速度较慢,因为该作业将从最后一个检查点恢复读取。
四、基于Socket
socketTextStream(String hostname, int port) - 从 socket 读取。元素可以用分隔符切分。
package com.wells.flink.demo.sources;import org.apache.flink.api.common.functions.FlatMapFunction;import org.apache.flink.api.java.tuple.Tuple2;import org.apache.flink.streaming.api.datastream.DataStreamSource;import org.apache.flink.streaming.api.datastream.SingleOutputStreamOperator;import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;import org.apache.flink.util.Collector;/*** Description* Created by wells on 2020-05-06 20:25:10*/public class SocketSourceTest {public static void main(String[] args) throws Exception {String host = "127.0.0.1";int port = 8090;StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();DataStreamSource<String> source = env.socketTextStream(host, port);SingleOutputStreamOperator<Tuple2<String, Integer>> counts = source.flatMap(new FlatMapFunction<String, Tuple2<String, Integer>>() {@Overridepublic void flatMap(String line, Collector<Tuple2<String, Integer>> collector) throws Exception {String[] words = line.split(" ");for (String word : words) {collector.collect(new Tuple2<String, Integer>(word, 1));}}}).keyBy(0).sum(1);counts.print();env.execute();}}
五、基于Kafka
5.1、部署kafka,略
5.2、flink 引入pom
<properties><project.build.sourceEncoding>UTF-8</project.build.sourceEncoding><project.reporting.outputEncoding>UTF-8</project.reporting.outputEncoding><java.version>1.8</java.version><flink.version>1.10.0</flink.version><scala.version>2.11</scala.version></properties><!-- flink kafka connector --><dependency><groupId>org.apache.flink</groupId><artifactId>flink-connector-kafka-0.11_${scala.version}</artifactId><version>${flink.version}</version></dependency>
5.3、flink main
package com.wells.flink.demo.sources;import org.apache.flink.api.common.serialization.SimpleStringSchema;import org.apache.flink.streaming.api.datastream.DataStream;import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;import org.apache.flink.streaming.connectors.kafka.FlinkKafkaConsumer011;import java.util.Properties;/*** Description Kafka API* Created by wells on 2020-03-25 20:36:53*/public class KafkaSourceTest {public static void main(String[] args) throws Exception {StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();Properties properties = new Properties();properties.setProperty("bootstrap.servers", "localhost:9092");properties.setProperty("zookeeper.connect", "localhost:2181");properties.setProperty("group.id", "flink-demo-topic-group");DataStream<String> stream = env.addSource(new FlinkKafkaConsumer011<String>("flink-demo-topic", new SimpleStringSchema(), properties));stream.print();env.execute();}}
5.4、测试结果
kafka producer send message
flink output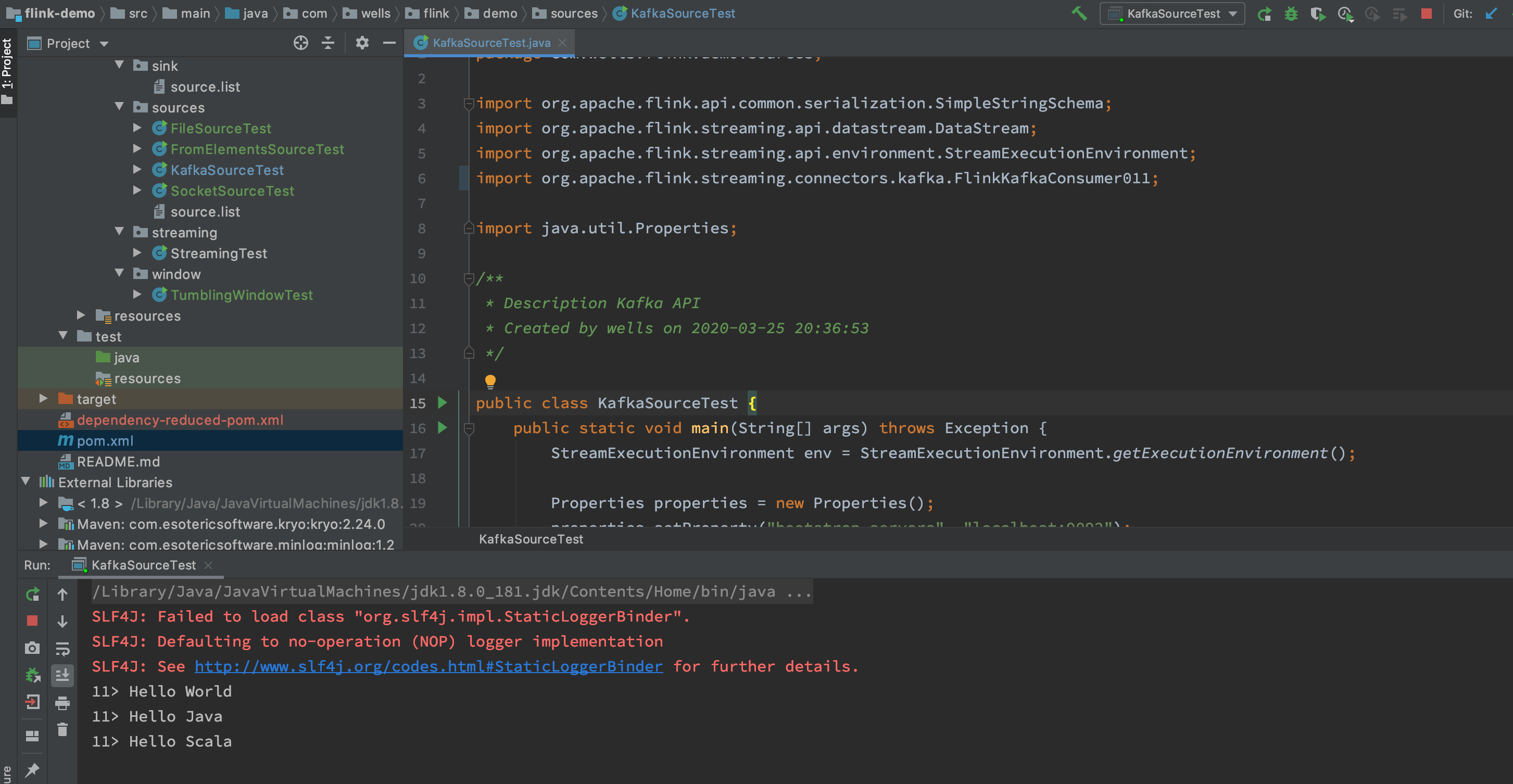
注意:
其中输出结果前面的 11> 数字代表线程编号,由并行分区决定,可以通过 dstream.print().setParallelism(1) 来避免
六、自定义Source
如果你想自己自定义自己的 Source 呢?
那么你就需要去了解一下 SourceFunction 接口了,它是所有 stream source 的根接口,它继承自一个标记接口(空接口)Function。
SourceFunction 定义了两个接口方法: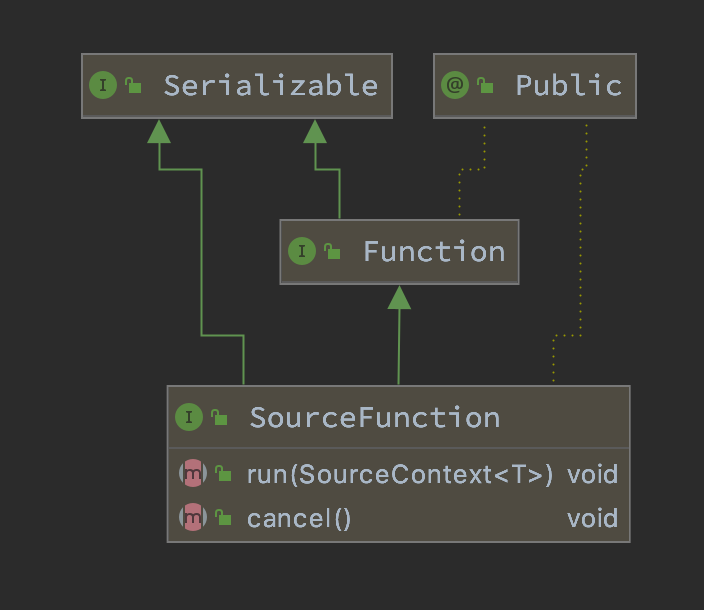
- run : 启动一个 source,即对接一个外部数据源然后 emit 元素形成 stream(大部分情况下会通过在该方法里运行一个 while 循环的形式来产生 stream)。
- cancel : 取消一个 source,也即将 run 中的循环 emit 元素的行为终止。
正常情况下,一个 SourceFunction 实现这两个接口方法就可以了。其实这两个接口方法也固定了一种实现模板。Flink源码中的例子如下: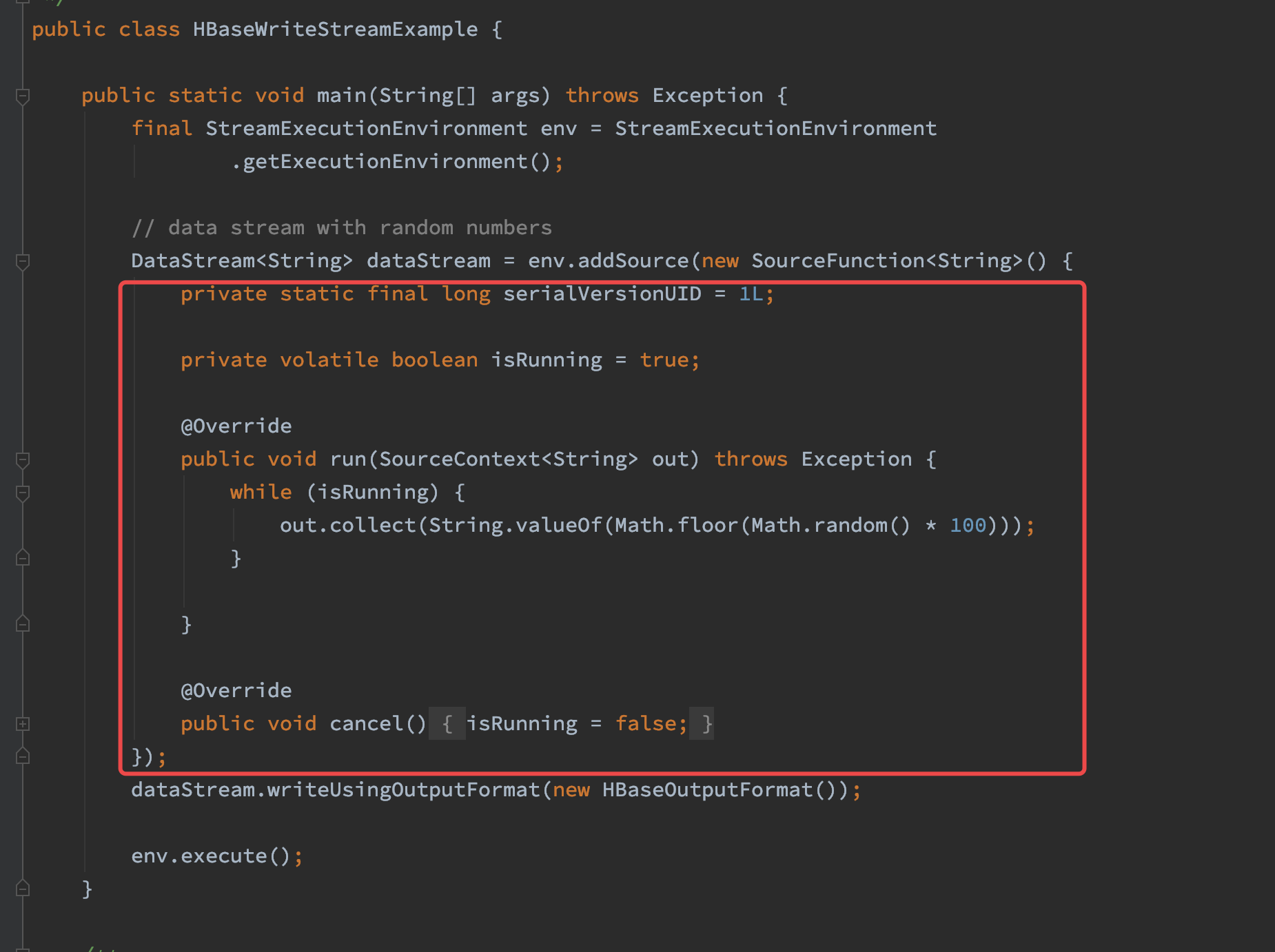
6.2、基于mysql自定义Source
参考:http://www.54tianzhisheng.cn/2018/10/30/flink-create-source/
七、Source对比
说下上面几种的特点吧:
- 基于集合:有界数据集,更偏向于本地测试用
- 基于文件:适合监听文件修改并读取其内容
- 基于 Socket:监听主机的 host port,从 Socket 中获取数据
- 基于Kafka:一般与现网对接较多
- 自定义 addSource:大多数的场景数据都是无界的,会源源不断的过来。比如去消费 Kafka 某个 topic 上的数据,这时候就需要用到这个 addSource,可能因为用的比较多的原因吧,Flink 直接提供了 FlinkKafkaConsumer011 等类可供你直接使用。你可以去看看 FlinkKafkaConsumerBase 这个基础类,它是 Flink Kafka 消费的最根本的类
Flink目前支持的Source如下: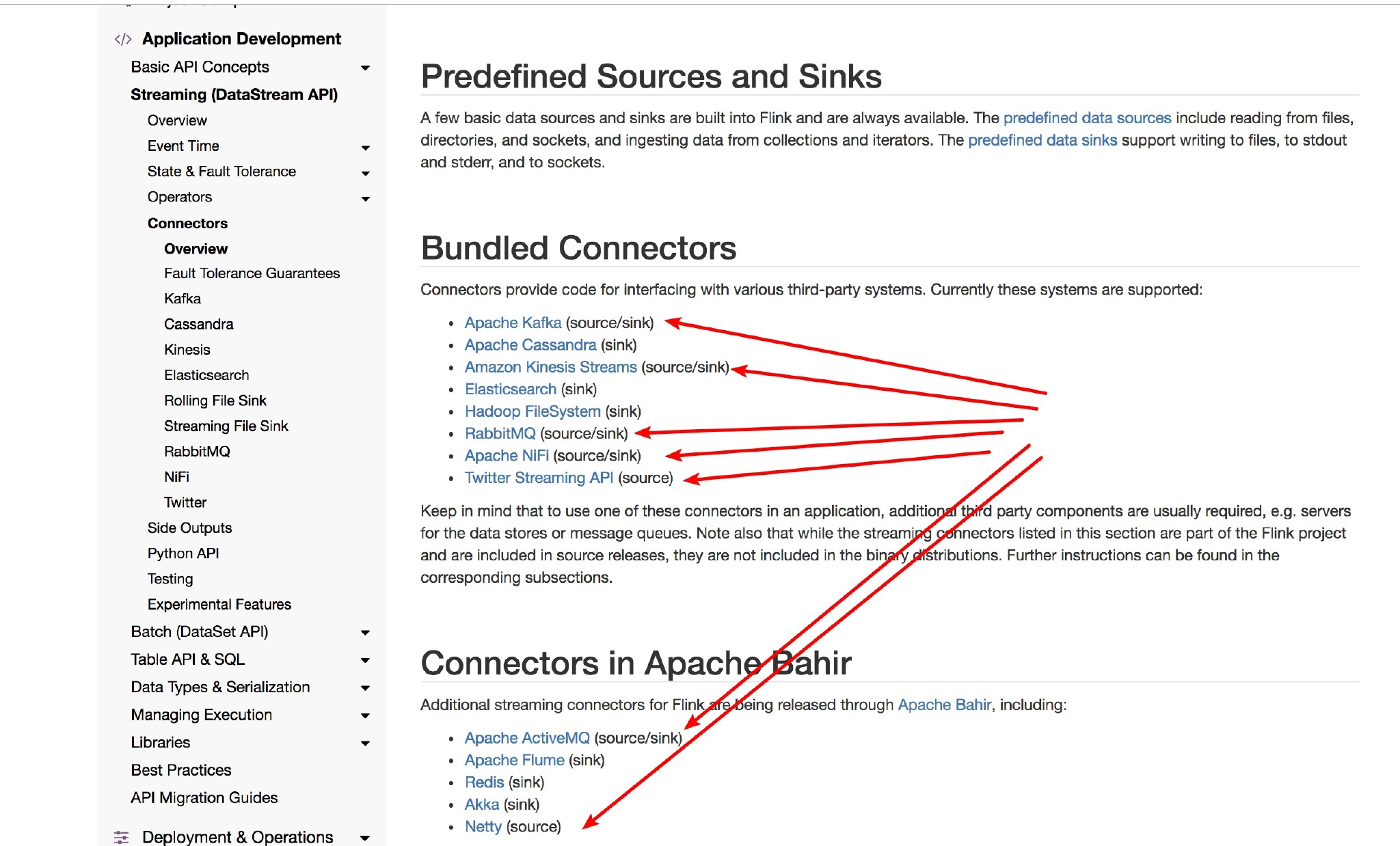

若有收获,就点个赞吧
0 人点赞
