服务器规划
Hadoop集群的高可用,结合Zookeeper搭建;
| NN-1 | NN-2 | DN | ZK | ZKFC | JNN | |
|---|---|---|---|---|---|---|
| node01 | ✅ | ✅ | ✅ | |||
| node02 | ✅ | ✅ | ✅ | ✅ | ✅ | |
| node03 | ✅ | ✅ | ✅ | |||
| node04 | ✅ | ✅ |
NameNode(Master):
- 命名空间管理:命名空间支持对HDFS中的目录、文件和块做类似文件系统的创建、修改、删除、列表文件和目录等基本操作。
- 块存储管理
DataNode(Slaver):
- namenode和client的指令进行存储或者检索block,并且周期性的向namenode节点报告它存了哪些文件的block
ZKFC:与NN放在一起,避免健康检查不及时,对NN进行监控;
JNN:存储、编辑日志信息,方便NameNode的迁移;
1)基础架构
(1)NameNode(Master)
命名空间管理:命名空间支持对HDFS中的目录、文件和块做类似文件系统的创建、修改、删除、列表文件和目录等基本操作。
块存储管理
(2)DataNode(Slaver)
namenode和client的指令进行存储或者检索block,并且周期性的向namenode节点报告它存了哪些文件的block
2)HA架构
使用Active NameNode,Standby NameNode 两个结点解决单点问题,两个结点通过JounalNode共享状态,通过ZKFC 选举Active ,监控状态,自动备援。
(1)Active NameNode:
接受client的RPC请求并处理,同时写自己的Editlog和共享存储上的Editlog,接收DataNode的Block report, block location updates和heartbeat;
(2)Standby NameNode:
同样会接到来自DataNode的Block report, block location updates和heartbeat,同时会从共享存储的Editlog上读取并执行这些log操作,使得自己的NameNode中的元数据(Namespcae information + Block locations map)都是和Active NameNode中的元数据是同步的。所以说Standby模式的NameNode是一个热备(Hot Standby NameNode),一旦切换成Active模式,马上就可以提供NameNode服务
(3)JounalNode:
用于Active NameNode , Standby NameNode 同步数据,本身由一组JounnalNode结点组成,该组结点基数个,支持Paxos协议,保证高可用,是CDH5唯一支持的共享方式(相对于CDH4 促在NFS共享方式)
(4)ZKFC:
监控NameNode进程,自动备援。
(二)YARN
1)基础架构
(1)ResourceManager(RM)
接收客户端任务请求,接收和监控NodeManager(NM)的资源情况汇报,负责资源的分配与调度,启动和监控ApplicationMaster(AM)。
(2)NodeManager
节点上的资源管理,启动Container运行task计算,上报资源、container情况给RM和任务处理情况给AM。
(3)ApplicationMaster
单个Application(Job)的task管理和调度,向RM进行资源的申请,向NM发出launch Container指令,接收NM的task处理状态信息。NodeManager
(4)Web Application Proxy
用于防止Yarn遭受Web攻击,本身是ResourceManager的一部分,可通过配置独立进程。ResourceManager Web的访问基于守信用户,当Application Master运行于一个非受信用户,其提供给ResourceManager的可能是非受信连接,Web Application Proxy可以阻止这种连接提供给RM。
(5)Job History Server
NodeManager在启动的时候会初始化LogAggregationService服务, 该服务会在把本机执行的container log (在container结束的时候)收集并存放到hdfs指定的目录下. ApplicationMaster会把jobhistory信息写到hdfs的jobhistory临时目录下, 并在结束的时候把jobhisoty移动到最终目录, 这样就同时支持了job的recovery.History会启动web和RPC服务, 用户可以通过网页或RPC方式获取作业的信息
2)HA架构
ResourceManager HA 由一对Active,Standby结点构成,通过RMStateStore存储内部数据和主要应用的数据及标记。目前支持的可替代的RMStateStore实现有:基于内存的MemoryRMStateStore,基于文件系统的FileSystemRMStateStore,及基于zookeeper的ZKRMStateStore。
ResourceManager HA的架构模式同NameNode HA的架构模式基本一致,数据共享由RMStateStore,而ZKFC成为 ResourceManager进程的一个服务,非独立存在
各个进程解释:
NameNode: hdfs的cluster
ResourceManager: yarn的cluster
DFSZKFC:DFS Zookeeper Failover Controller 激活Standby NameNode
DataNode: hdfs的master
NodeManager
JournalNode:NameNode共享editlog结点服务(如果使用NFS共享,则该进程和所有启动相关配置接可省略)。
QuorumPeerMain:Zookeeper主进程
说明
1.在hadoop2.0中通常由两个NameNode组成,一个处于active状态,另一个处于standby状态。Active NameNode对外提供服务,而Standby NameNode则不对外提供服务,仅同步active namenode的状态,以便能够在它失败时快速进行切换。
hadoop2.0官方提供了两种HDFS HA的解决方案,一种是NFS,另一种是QJM。这里我们使用简单的QJM。在该方案中,主备NameNode之间通过一组JournalNode同步元数据信息,一条数据只要成功写入多数JournalNode即认为写入成功。通常配置奇数个JournalNode
这里还配置了一个zookeeper集群,用于ZKFC(DFSZKFailoverController)故障转移,当Active NameNode挂掉了,会自动切换Standby NameNode为standby状态
2.hadoop-2.2.0中依然存在一个问题,就是ResourceManager只有一个,存在单点故障,hadoop-2.4.1解决了这个问题,有两个ResourceManager,一个是Active,一个是Standby,状态由zookeeper进行协调
一、配置服务器
1.1、配置服务器之间免密登录
https://www.yuque.com/wells/big.data/ekxh6e
1.2、配置服务器host
在每台服务器上,进行如下操作:sudo vim /etc/hosts
增加内容如下:
10.0.2.4 node0110.0.2.5 node0210.0.2.6 node0310.0.2.7 node04
二、配置主节点JDK
2.1、步骤:略
JAVA_HOME=/app/ratels/basic-service/java/jdk1.8.0_201
2.2、SCP
scp到其他node上
三、配置主节点node01
下载hadoop3.1.2:wget http://mirror.bit.edu.cn/apache/hadoop/common/hadoop-3.1.2/hadoop-3.1.2.tar.gz
解压:tar -zxvf hadoop-3.1.2.tar.gz
3.1、配置环境变量
编辑 ~/.bash_profile
JAVA_HOME=/app/ratels/basic-service/java/jdk1.8.0_201CLASS_PATH=$JAVA_HOME/libHADOOP_HOME=/app/ratels/basic-service/hadoop/hadoop3/hadoop-3.1.1PATH=$PATH:$HOME/bin:$JAVA_HOME/bin:$HADOOP_HOME/bin:$HADOOP_HOME/sbinexport PATH
修改 ${HADOOP_HOME}/etc/hadoop/下面的文件:
3.2、hadoop-env.sh
设置jdk路径、设置namenode、datanode、secondarynamenode这三个节点对应的角色
export JAVA_HOME=/app/ratels/basic-service/java/jdk1.8.0_201export HDFS_NAMENODE_USER=rootexport HDFS_DATANODE_USER=rootexport HDFS_ZKFC_USER=rootexport HDFS_JOURNALNODE_USER=root
3.3、修改core-site.xml
<configuration><property><name>fs.defaultFS</name><value>hdfs://mycluster</value></property><!-- 存放元数据信息、原始数据 --><property><name>hadoop.tmp.dir</name><value>/app/bi/tools/hadoop/hdp-ha</value></property><property><name>hadoop.http.staticuser.user</name><value>root</value></property><!-- 用于支持故障自动转移 --><property><name>ha.zookeeper.quorum</name><value>node02:2181,node03:2181,node04:2181</value></property></configuration>
3.4、修改hdfs-site.xml
<configuration><!-- 主节点逻辑名称 --><property><name>dfs.nameservices</name><value>mycluster</value></property><!-- 集群中每个NameNode节点的名称 --><property><name>dfs.ha.namenodes.mycluster</name><value>nn1,nn2</value></property><!-- rpc config --><property><name>dfs.namenode.rpc-address.mycluster.nn1</name><value>node01:8020</value></property><property><name>dfs.namenode.rpc-address.mycluster.nn2</name><value>node02:8020</value></property><!-- http config: 与浏览器通信的端口 --><property><name>dfs.namenode.http-address.mycluster.nn1</name><value>node01:9870</value></property><property><name>dfs.namenode.http-address.mycluster.nn2</name><value>node02:9870</value></property><!-- JNN共享目录 --><property><name>dfs.namenode.shared.edits.dir</name><value>qjournal://node01:8485;node02:8485;node03:8485/mycluster</value></property><!-- 故障转移代理类 --><property><name>dfs.client.failover.proxy.provider.mycluster</name><value>org.apache.hadoop.hdfs.server.namenode.ha.ConfiguredFailoverProxyProvider</value></property><!-- stand by namenode 免密登录 active namenode --><property><name>dfs.ha.fencing.methods</name><value>sshfence</value></property><property><name>dfs.ha.fencing.ssh.private-key-files</name><value>/root/.ssh/id_rsa</value></property><!-- setting journalnode bak dir --><property><name>dfs.journalnode.edits.dir</name><value>/app/bi/tools/hadoop/hdp-ha/journalnode</value></property><!-- 自动故障转移 --><property><name>dfs.ha.automatic-failover.enabled</name><value>true</value></property></configuration>
3.5、修改workers配置
修改集群中所有节点workers配置为hdp从节点的host,例如:
node02node03node04
3.6、 配置zk集群
https://www.yuque.com/wells/big.data/zgsep3
3.7、启动zk集群
zkServer.sh startzkServer.sh status
3.8、启动journalnode
journalnode需要在对应服务器上,一个一个启动,不能马虎;
启动:hadoop-daemon.sh start journalnode停止:hadoop-daemon.sh stop journalnode
3.9、格式化namenode
描述:生成集群需要的clusterId和元数据信息;
执行:在其中一台namenode节点上,执行
hdfs namenode -format
验证:在core-site.xml配置的hadoop.tmp.dir目录下查看元数据信息
$ cd /app/bi/tools/hadoop/hdp-ha/dfs/name/current$ pwd/app/bi/tools/hadoop/hdp-ha/dfs/name/current$ cat VERSION#Thu Jun 13 07:36:05 CST 2019namespaceID=1382251291clusterID=CID-920a81c0-e98a-48fe-b9d2-c8d2923a9aedcTime=1560382565375storageType=NAME_NODEblockpoolID=BP-78938617-10.0.2.4-1560382565375layoutVersion=-64
注意:
同一个集群中的NameNode需要使用相同的clusterID等元数据信息
3.10、在其他的NameNode上同步元数据信息
在其他NameNode节点上同步元数据信息前提是,已经进行过格式化的NameNode必须启动起来:
- 格式化
- 启动namenode
在规划的另外的namenode上格式化namenode
hdfs namenode -format
启动规划的 两个 namenode节点,启动命令( 分别在两个namenode节点上执行 ):
$ hadoop-daemon.sh start namenode
在其中一个NameNode上同步元数据信息到另外的NameNode,执行命令:
$ hdfs namenode -bootstrapStandby
验证:
$ cd /app/bi/tools/hadoop/hdp-ha/dfs/name/current$ cat VERSIONnamespaceID=1382251291clusterID=CID-920a81c0-e98a-48fe-b9d2-c8d2923a9aedcTime=1560382565375storageType=NAME_NODEblockpoolID=BP-78938617-10.0.2.4-1560382565375layoutVersion=-64
3.11 zk格式化
前提:zk集群必须启动起来
执行:
$ hdfs zkfc -formatZK
验证:
通过 zkCli.sh 登录zk,查看根目录下,会多一个hadoop-ha目录:ls /hadoop-ha/mycluster
3.12 启动hdp集群
命令:
$ start-dfs.sh
验证:
- 通过jps查看进程是否与规划匹配
- 通过 zkCli.sh 登录zk,查看:get /hadoop-ha/mycluster/ActiveBreadCrumb (激活的主节点的信息)
- 通过http端口访问页面:
激活的主节点页面: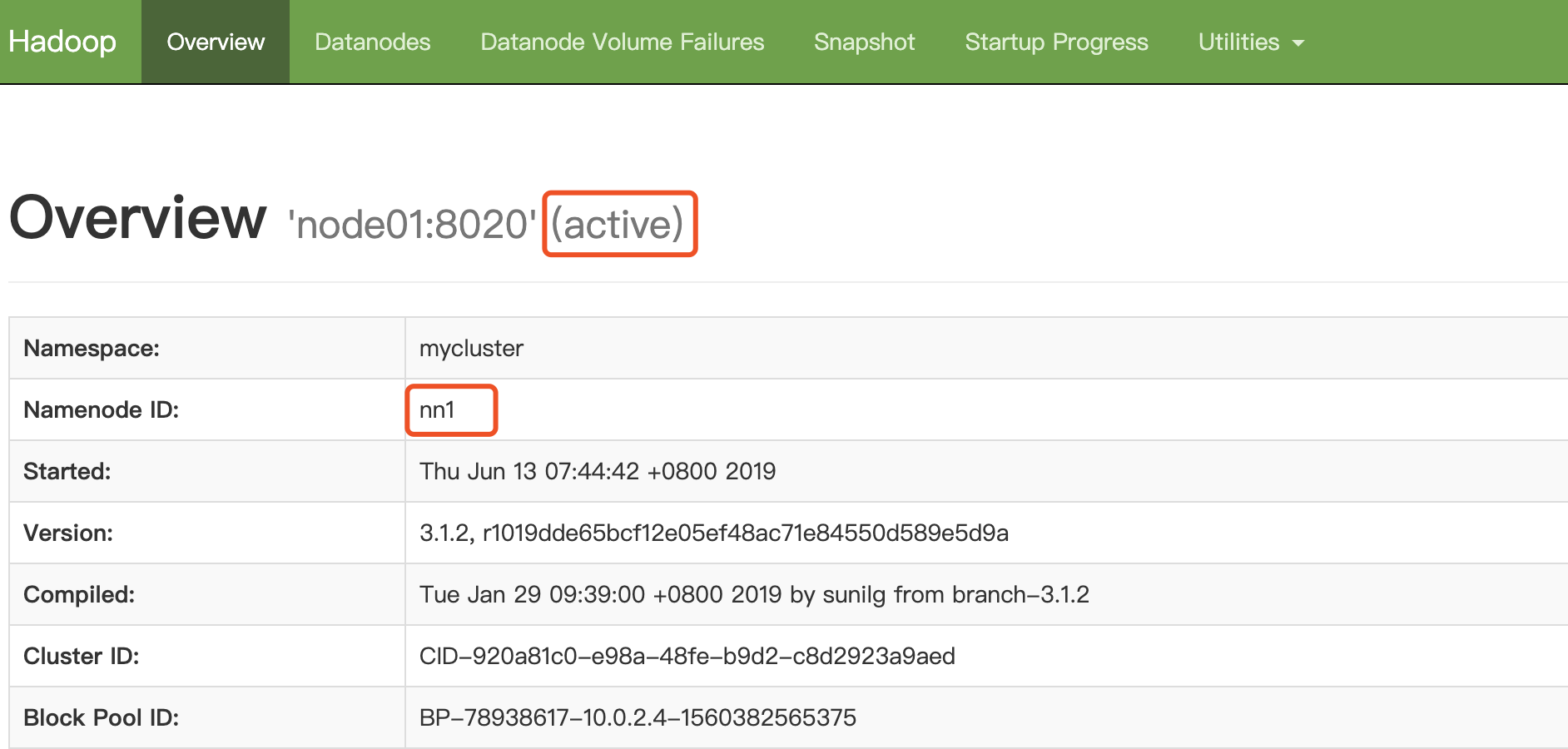
备主节点的页面: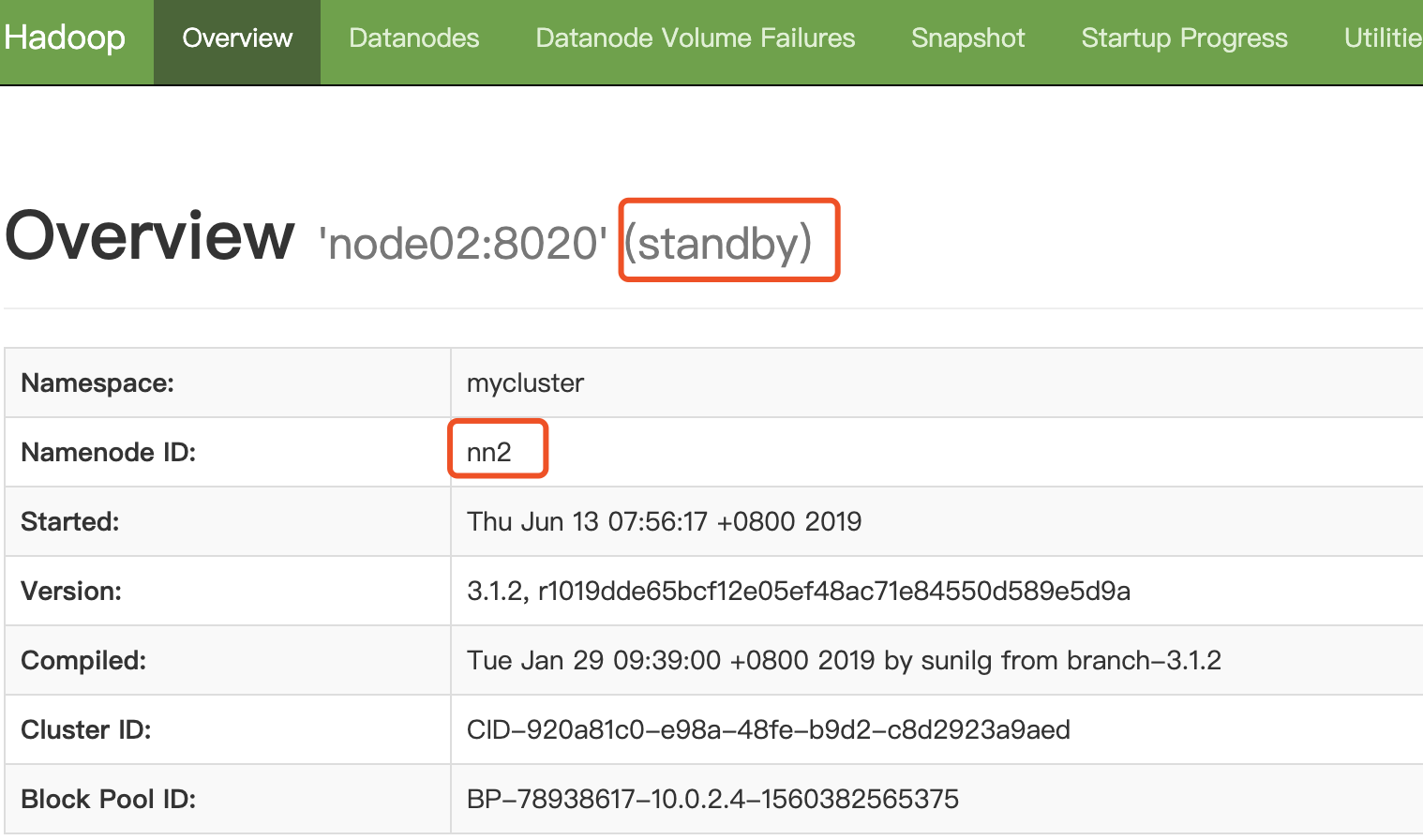

若有收获,就点个赞吧
0 人点赞
