内存管理
堆内和堆外内存规划
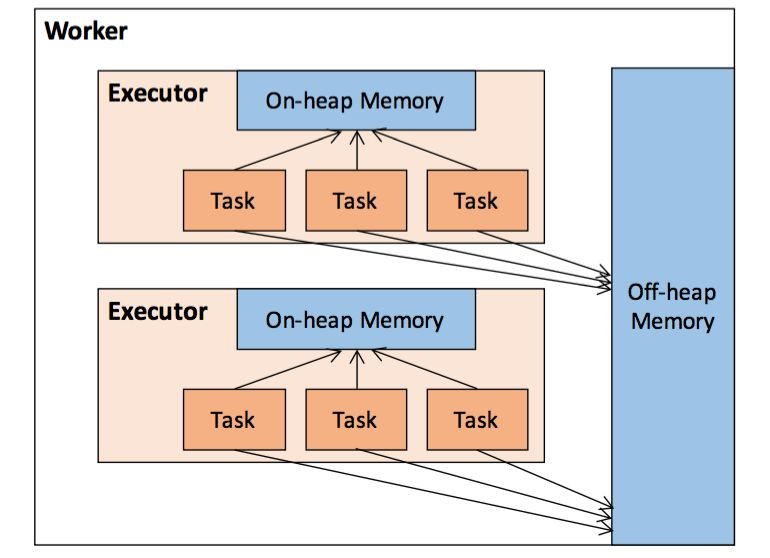
堆内内存
堆内内存的大小,由 Spark 应用程序启动时的 –executor-memory 或 spark.executor.memory 参数配置。Executor 内运行的并发任务共享 JVM 堆内内存,这些任务在缓存 RDD 数据和广播(Broadcast)数据时占用的内存被规划为存储(Storage)内存,而这些任务在执行 Shuffle 时占用的内存被规划为执行(Execution)内存,剩余的部分不做特殊规划,那些 Spark 内部的对象实例,或者用户定义的 Spark 应用程序中的对象实例,均占用剩余的空间。不同的管理模式下,这三部分占用的空间大小各不相同
Spark 对堆内内存的管理是一种逻辑上的”规划式”的管理,因为对象实例占用内存的申请和释放都由 JVM 完成,Spark 只能在申请后和释放前记录这些内存,我们来看其具体流程:
申请内存:
- Spark 在代码中 new 一个对象实例
- JVM 从堆内内存分配空间,创建对象并返回对象引用
- Spark 保存该对象的引用,记录该对象占用的内存
释放内存:
- Spark 记录该对象释放的内存,删除该对象的引用
等待 JVM 的垃圾回收机制释放该对象占用的堆内内存
对于 Spark 中序列化的对象,由于是字节流的形式,其占用的内存大小可直接计算,而对于非序列化的对象,其占用的内存是通过周期性地采样近似估算而得,即并不是每次新增的数据项都会计算一次占用的内存大小,这种方法降低了时间开销但是有可能误差较大,导致某一时刻的实际内存有可能远远超出预期[2]。此外,在被 Spark 标记为释放的对象实例,很有可能在实际上并没有被 JVM 回收,导致实际可用的内存小于 Spark 记录的可用内存。所以 Spark 并不能准确记录实际可用的堆内内存,从而也就无法完全避免内存溢出(OOM, Out of Memory)的异常。
堆外内存
为了进一步优化内存的使用以及提高Shuffle 时排序的效率,Spark 引入了堆外(Off-heap)内存,使之可以直接在工作节点的系统内存中开辟空间,存储经过序列化的二进制数据。利用 JDK Unsafe API(从 Spark 2.0 开始,在管理堆外的存储内存时不再基于 Tachyon,而是与堆外的执行内存一样,基于 JDK Unsafe API 实现[3]),Spark 可以直接操作系统堆外内存,减少了不必要的内存开销,以及频繁的 GC 扫描和回收,提升了处理性能。堆外内存可以被精确地申请和释放,而且序列化的数据占用的空间可以被精确计算,所以相比堆内内存来说降低了管理的难度,也降低了误差。
在默认情况下堆外内存并不启用,可通过配置spark.memory.offHeap.enabled 参数启用,并由spark.memory.offHeap.size 参数设定堆外空间的大小。除了没有 other 空间,堆外内存与堆内内存的划分方式相同,所有运行中的并发任务共享存储内存和执行内存。
内存空间分配
静态内存管理
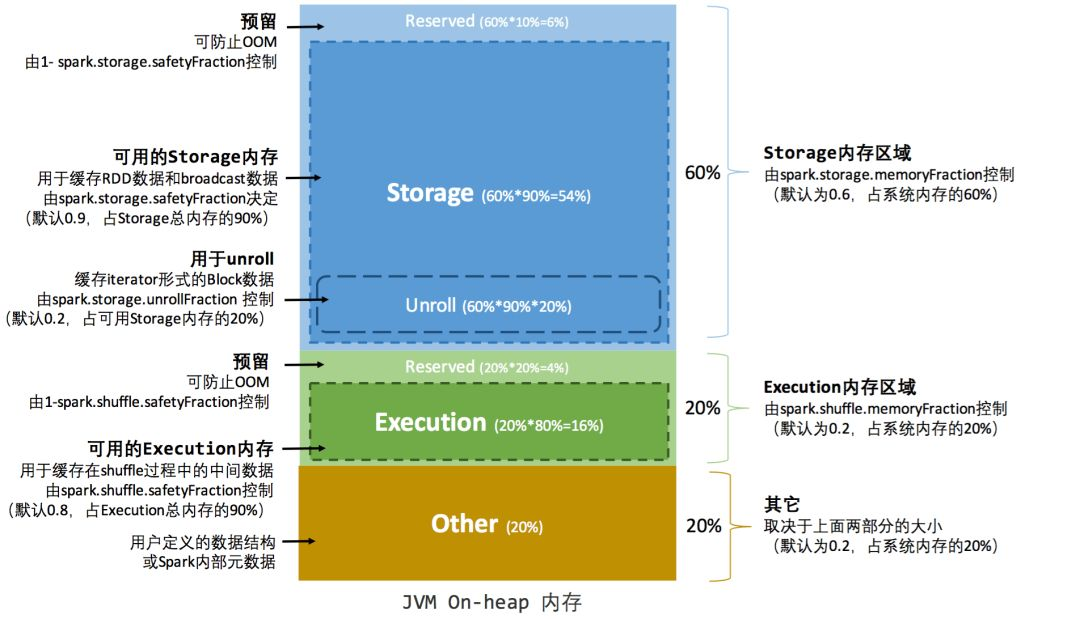
其中 systemMaxMemory 取决于当前 JVM 堆内内存的大小,最后可用的执行内存或者存储内存要在此基础上与各自的memoryFraction 参数和 safetyFraction 参数相乘得出。上述计算公式中的两个 safetyFraction 参数,其意义在于在逻辑上预留出1-safetyFraction 这么一块保险区域,降低因实际内存超出当前预设范围而导致 OOM 的风险(上文提到,对于非序列化对象的内存采样估算会产生误差)。值得注意的是,这个预留的保险区域仅仅是一种逻辑上的规划,在具体使用时 Spark 并没有区别对待,和”其它内存”一样交给了 JVM 去管理。
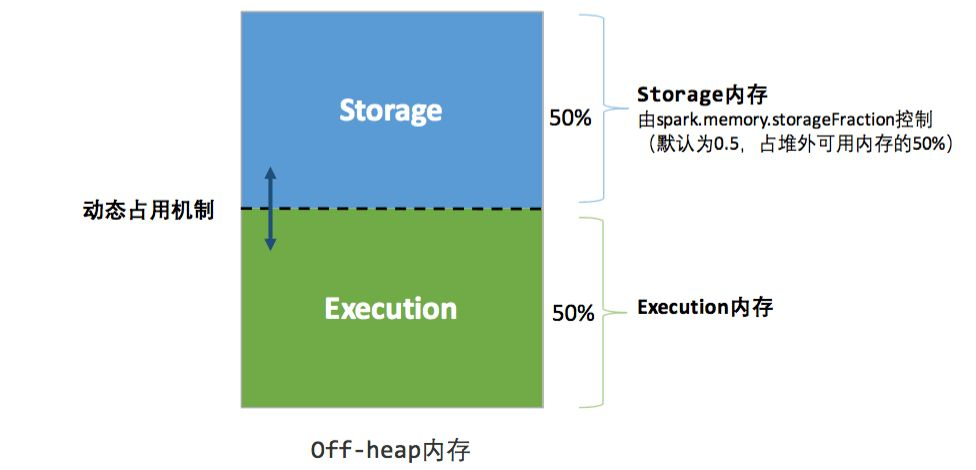
堆外的空间分配较为简单,只有存储内存和执行内存,如图 3 所示。可用的执行内存和存储内存占用的空间大小直接由参数spark.memory.storageFraction 决定,由于堆外内存占用的空间可以被精确计算,所以无需再设定保险区域。
静态内存管理机制实现起来较为简单,但如果用户不熟悉 Spark 的存储机制,或没有根据具体的数据规模和计算任务或做相应的配置,很容易造成”一半海水,一半火焰”的局面,即存储内存和执行内存中的一方剩余大量的空间,而另一方却早早被占满,不得不淘汰或移出旧的内容以存储新的内容。由于新的内存管理机制的出现,这种方式目前已经很少有开发者使用,出于兼容旧版本的应用程序的目的,Spark 仍然保留了它的实现。
统一内存管理
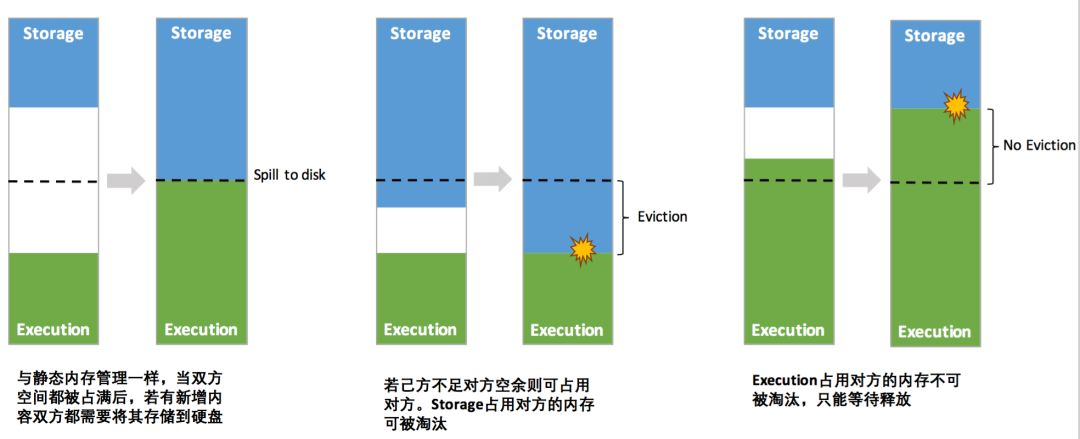
Spark 1.6 之后引入的统一内存管理机制,与静态内存管理的区别在于存储内存和执行内存共享同一块空间,可以动态占用对方的空闲区域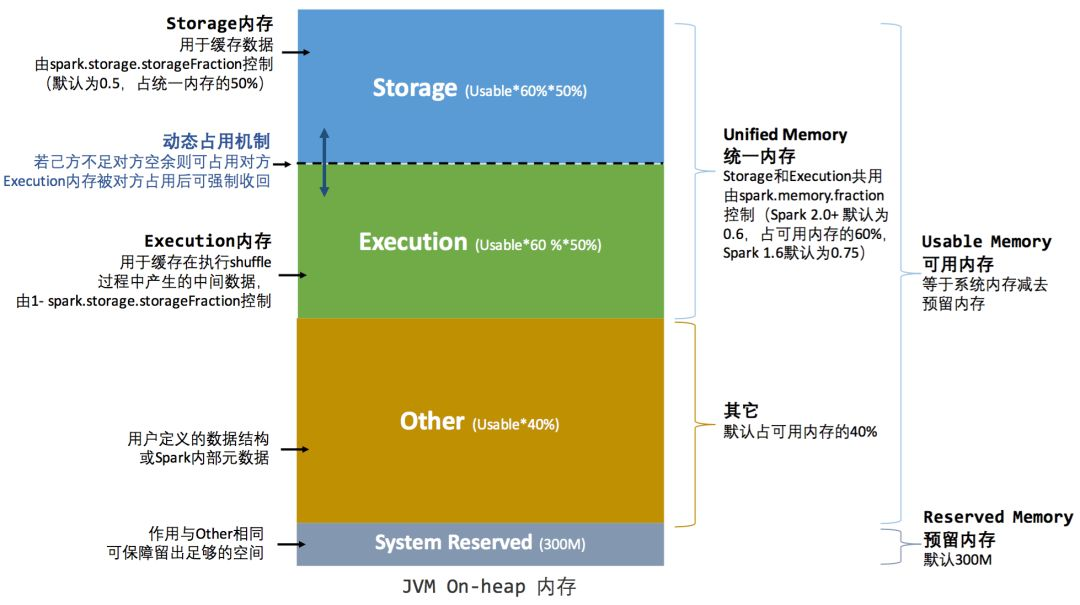
其中最重要的优化在于动态占用机制,其规则如下:
- 设定基本的存储内存和执行内存区域(spark.storage.storageFraction 参数),该设定确定了双方各自拥有的空间的范围
- 双方的空间都不足时,则存储到硬盘;若己方空间不足而对方空余时,可借用对方的空间;(存储空间不足是指不足以放下一个完整的 Block)
- 执行内存的空间被对方占用后,可让对方将占用的部分转存到硬盘,然后”归还”借用的空间
- 存储内存的空间被对方占用后,无法让对方”归还”,因为需要考虑 Shuffle 过程中的很多因素,实现起来较为复杂

若有收获,就点个赞吧
0 人点赞
