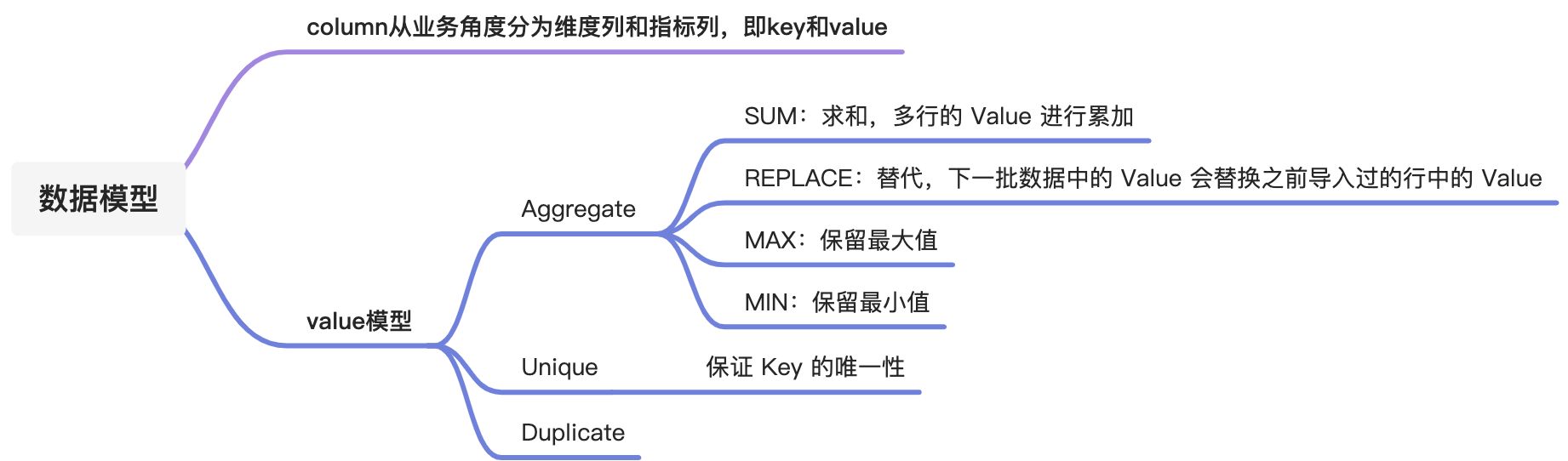
Aggregate 模型示例
| ColumnName | Type | AggregationType | Comment |
|---|---|---|---|
| user_id | LARGEINT | 用户id | |
| date | DATE | 数据灌入日期 | |
| city | VARCHAR(20) | 用户所在城市 | |
| age | SMALLINT | 用户年龄 | |
| sex | TINYINT | 用户性别 | |
| last_visit_date | DATETIME | REPLACE | 用户最后一次访问时间 |
| cost | BIGINT | SUM | 用户总消费 |
| max_dwell_time | INT | MAX | 用户最大停留时间 |
| min_dwell_time | INT | MIN | 用户最小停留时间 |
-- 省略建表语句中的 Partition 和 Distribution 信息CREATE TABLE IF NOT EXISTS example_db.expamle_tbl(`user_id` LARGEINT NOT NULL COMMENT "用户id",`date` DATE NOT NULL COMMENT "数据灌入日期时间",`city` VARCHAR(20) COMMENT "用户所在城市",`age` SMALLINT COMMENT "用户年龄",`sex` TINYINT COMMENT "用户性别",`last_visit_date` DATETIME REPLACE DEFAULT "1970-01-01 00:00:00" COMMENT "用户最后一次访问时间",`cost` BIGINT SUM DEFAULT "0" COMMENT "用户总消费",`max_dwell_time` INT MAX DEFAULT "0" COMMENT "用户最大停留时间",`min_dwell_time` INT MIN DEFAULT "99999" COMMENT "用户最小停留时间")AGGREGATE KEY(`user_id`, `date`, `city`, `age`, `sex`)DISTRIBUTED BY HASH(`user_id`) BUCKETS 1PROPERTIES ("replication_allocation" = "tag.location.default: 1");
Unique 模型
CREATE TABLE IF NOT EXISTS example_db.expamle_tbl(`user_id` LARGEINT NOT NULL COMMENT "用户id",`username` VARCHAR(50) NOT NULL COMMENT "用户昵称",`city` VARCHAR(20) COMMENT "用户所在城市",`age` SMALLINT COMMENT "用户年龄",`sex` TINYINT COMMENT "用户性别",`phone` LARGEINT COMMENT "用户电话",`address` VARCHAR(500) COMMENT "用户地址",`register_time` DATETIME COMMENT "用户注册时间")UNIQUE KEY(`user_id`, `username`)DISTRIBUTED BY HASH(`user_id`) BUCKETS 1PROPERTIES ("replication_allocation" = "tag.location.default: 1");
Duplicate 模型
Duplicate 模型没有聚合模型的这个局限性。因为该模型不涉及聚合语意,在做 count(*) 查询时,任意选择一列查询,即可得到语意正确的结果。
不是重点,不重要
参考
https://doris.apache.org/zh-CN/data-table/data-model.html#%E5%9F%BA%E6%9C%AC%E6%A6%82%E5%BF%B5

若有收获,就点个赞吧
0 人点赞
