spark 和 pyspark【1】
Spark是用 Scala编程语言 编写的。为了用Spark支持Python,Apache Spark社区发布了一个工具PySpark。使用PySpark,也可以使用Python编程语言中的 RDD 。正是由于一个名为 Py4j的库,他们才能实现这一目标。
简单来说,在python driver端,SparkContext利用Py4J启动一个JVM并产生一个JavaSparkContext。Py4J只使用在driver端,用于本地python与Java SparkContext objects的通信。大量数据的传输使用的是另一个机制。
RDD在python下的转换会被映射成java环境下PythonRDD。在远端worker机器上,PythonRDD对象启动一些子进程并通过pipes与这些子进程通信,以此send用户代码和数据。
PySpark 是 Spark 为 Python 开发者提供的 API,其依赖于 Py4J
hive on Spark【2】
Hive on Spark为Hive提供了Apache Spark作为执行引擎, 从Hive1.1开始支持使用Spark作为执行引擎。是Hive的产物,和Spark本身发展没有太多关联。
Hive on spark? Spark on hive? 傻傻分不清楚【8】
Spark读取和使用Hive Permanent Function 原理
在Spark 1. 版本中不支持Hive Perment Function的加载,使用起来不是很方便;
在Spark 2. 版本中通过HiveExternalCatalog 中的HiveClient 来直接和hive metaStore交互,轻松实现Hive Perment Function的加载;
Beeline
Hive客户端工具后续将使用Beeline 替代HiveCLI ,并且后续版本也会废弃掉HiveCLI 客户端工具,Beeline是 Hive 0.11版本引入的新命令行客户端工具,它是基于SQLLine CLI的JDBC客户端。
Beeline支持嵌入模式(embedded mode)和远程模式(remote mode)。在嵌入式模式下,运行嵌入式的Hive(类似Hive CLI),而远程模式可以通过Thrift连接到独立的HiveServer2进程上。从Hive 0.14版本开始,Beeline使用HiveServer2工作时,它也会从HiveServer2输出日志信息到STDERR
Application、SparkSession、SparkContext、RDD关系【3】
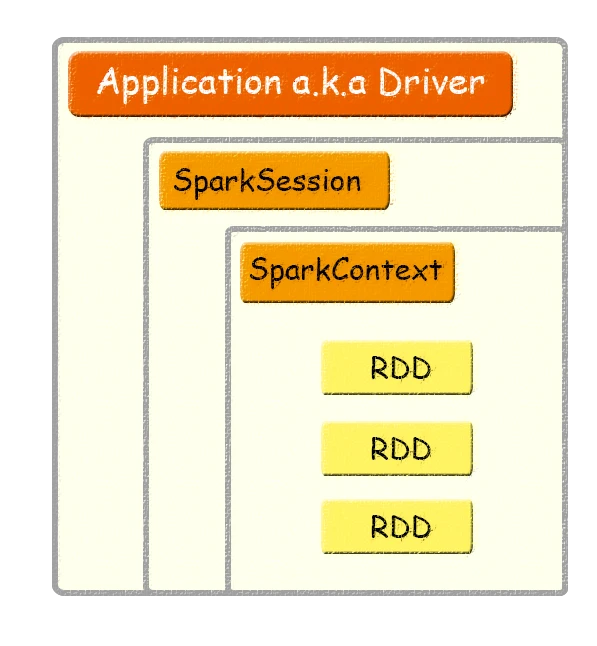
Application:用户编写的Spark应用程序,Driver 即运行上述 Application 的 main() 函数并且创建 SparkContext。
SparkContext:整个应用的上下文,控制应用的生命周期。
RDD:不可变的数据集合,可由 SparkContext 创建,是 Spark 的基本计算单元
Spark Session和Spark Context关系【4】
SparkSession是Spark 2.0引如的新概念。SparkSession为用户提供了统一的切入点,来让用户学习spark的各项功能。
在Spark的早期版本中,SparkContext是spark的主要切入点,由于RDD是主要的API,我们通过sparkcontext来创建和操作RDD。对于每个其他的API,我们需要使用不同的context。例如,对于Streming,我们需要使用StreamingContext;对于sql,使用sqlContext;对于Hive,使用hiveContext。但是随着DataSet和DataFrame的API逐渐成为标准的API,就需要为他们建立接入点。所以在spark2.0中,引入SparkSession作为DataSet和DataFrame API的切入点,SparkSession封装了SparkConf、SparkContext和SQLContext。为了向后兼容,SQLContext和HiveContext也被保存下来
SparkSession实质上是SQLContext和HiveContext的组合(未来可能还会加上StreamingContext),所以在SQLContext和HiveContext上可用的API在SparkSession上同样是可以使用的。SparkSession内部封装了SparkContext,所以计算实际上是由sparkContext完成的。
创建一个SparkContext对象
//Spark app 配置:应用的名字和Master运行的位置val sparkConf=new SparkConf().setAppName("SparkAppTemplate").setMaster("local[2]")//创建sparkContext对象:主要用于读取需要处理的数据,封装在RDD集合中;调度jobs执行val sc = new SparkContext(sparkConf)
创建一个SparkSession对象
//在spark 2.x中不推荐使用sparkContext对象读取数据,而是推荐SparkSessionval spark = SparkSession.builder.appName("Simple Application").master("local[2]").getOrCreate()
SparkSession、SparkContext、SQLContext和HiveContext之间的区别
SparkContext 是什么?
- 驱动程序使用SparkContext与集群进行连接和通信,它可以帮助执行Spark任务,并与资源管理器(如YARN 或Mesos)进行协调。
- 使用SparkContext,可以访问其他上下文,比如SQLContext和HiveContext。
- 使用SparkContext,我们可以为Spark作业设置配置参数。
【
如果您在spark-shell中,那么SparkContext已经为您提供了,并被分配给变量sc。
如果还没有SparkContext,可以先创建一个SparkConf。
//set up the spark configurationval sparkConf = new SparkConf().setAppName("hirw").setMaster("yarn")//get SparkContext using the SparkConfval sc = new SparkContext(sparkConf)
SQLContext 是什么?【6】
SQLContext在Spark1.6中使用,在spark2.x中已经标记为过时,不推荐使用
SQLContext是通往SparkSQL的入口。下面是如何使用SparkContext创建SQLContext。
// sc is an existing SparkContext.val sqlContext = new org.apache.spark.sql.SQLContext(sc)
一旦有了SQLContext,就可以开始处理DataFrame、DataSet等。
HiveContext 是什么?【6】
HiveContext也是已经过时的不推荐使用。
HiveContext是通往hive入口。
HiveContext具有SQLContext的所有功能。
实际上,如果查看API文档,就会发现HiveContext扩展了SQLContext,这意味着它支持SQLContext支持的功能以及更多(Hive特定的功能)
public class HiveContext extends SQLContext implements Logging
下面是如何使用SparkContext获得HiveContext
// sc is an existing SparkContext.
val hiveContext = new org.apache.spark.sql.hive.HiveContext(sc)
如果想要用spark访问hive的表需要进行一下的配置
1. 拷贝 ${HIVE_HOME}/conf/hive-site.xml到 ${SPARK_HOME}/conf中
2. 在pom.xml文件中添加一下依赖
<!--添加hive依赖-->
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-hive_2.11</artifactId>
<version>${spark.version}</version>
</dependency>
//1)创建相应的Context
val sparkConf = new SparkConf()
val sc = new SparkContext(sparkConf)
val hiveContext = new HiveContext(sc)
//2)相关处理:hiveTable
hiveContext.table("emp").show()
//3)关闭资源
sc.stop()
SparkSession 是什么?【5】
SparkSession是在Spark 2.0中引入的,
它使开发人员可以轻松地使用它,这样我们就不用担心不同的上下文,
并简化了对不同上下文的访问。通过访问SparkSession,我们可以自动访问SparkContext。
下面是如何创建一个SparkSession
val spark = SparkSession
.builder()
.appName("hirw-test")
.config("spark.some.config.option", "some-value")
.getOrCreate()
SparkSession现在是Spark的新入口点,它替换了旧的SQLContext和HiveContext。注意,保留旧的SQLContext和HiveContext是为了向后兼容。
一旦我们访问了SparkSession,我们就可以开始使用DataFrame和Dataset了。
下面是我们如何使用Hive支持创建SparkSession。
val spark = SparkSession
.builder()
.appName("hirw-hive-test")
.config("spark.sql.warehouse.dir", warehouseLocation)
.enableHiveSupport()
.getOrCreate()
Spark读写Hive【7】
Spark SQL支持读写Hive,不过Hive本身包含了大量的依赖,这些依赖spark默认是没有的。如果Hive的依赖在Classpath中,那么Spark可以自动加载(注意Spark的worker节点也需要提供这些依赖)。默认配置Hive只需要把相关的hive-site.xml core-site.xml hdfs-site.xml 放到conf目录下即可。
当使用hive时,需要在 SparkSession 中开启hive,从而获得hive相关的serdes以及函数。如果没有现成的Hive环境也可以使用,spark会自动在当前目录创建metastore_db,目录的位置可以通过参数 spark.sql.warehouse.dir 指定, 默认是启动Spark应用程序的目录。
Spark SQL, DataFrames and Datasets
Spark SQL 是一个用于结构化数据处理的 Spark 模块。 与基本的 Spark RDD API 不同,Spark SQL 提供的接口为 Spark 提供了有关数据结构和正在执行的计算的更多信息。 在内部,Spark SQL 使用这些额外的信息来执行额外的优化。 有多种与 Spark SQL 交互的方式,包括 SQL 和数据集 API。 计算结果时,使用相同的执行引擎,与您使用哪种 API/语言来表达计算无关。 这种统一意味着开发人员可以轻松地在不同的 API 之间来回切换,这提供了表达给定转换的最自然的方式。
Datasets and DataFrames
数据集(Dataset)是数据的分布式集合。 Dataset 是 Spark 1.6 中添加的一个新接口,它提供了 RDD 的优点(强类型、使用强大 lambda 函数的能力)以及 Spark SQL 优化执行引擎的优点。数据集可以从 JVM 对象构建,然后使用函数转换(map、flatMap、filter 等)进行操作。数据集 API 在 Scala 和 Java 中可用。 Python 不支持 Dataset API。但是由于 Python 的动态特性,Dataset API 的许多好处已经可用(即您可以自然地通过名称访问行的字段 row.columnName)。 R 的情况类似。
DataFrame 是组织成命名列的数据集。它在概念上等同于关系数据库中的表或 R/Python 中的数据框,但在幕后进行了更丰富的优化。 DataFrames 可以从多种来源构建,例如:结构化数据文件、Hive 中的表、外部数据库或现有 RDD。 DataFrame API 在 Scala、Java、Python 和 R 中可用。在 Scala 和 Java 中,DataFrame 由行数据集表示。在 Scala API 中,DataFrame 只是 Dataset[Row] 的类型别名。而在 Java API 中,用户需要使用 Dataset
RDD、DataFrame和DataSet的区别【9】
RDD和DataFrame【11】
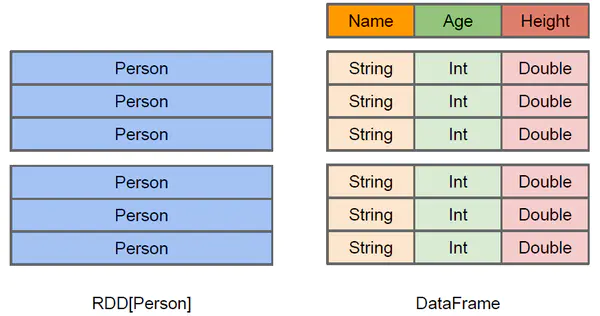
上图直观地体现了DataFrame和RDD的区别。左侧的RDD[Person]虽然以Person为类型参数,但Spark框架本身不了解Person类的内部结构。而右侧的DataFrame却提供了详细的结构信息,使得Spark SQL可以清楚地知道该数据集中包含哪些列,每列的名称和类型各是什么。DataFrame多了数据的结构信息,即schema。RDD是分布式的Java对象的集合。DataFrame是分布式的Row对象的集合。DataFrame除了提供了比RDD更丰富的算子以外,更重要的特点是提升执行效率、减少数据读取以及执行计划的优化,比如filter下推、裁剪等。
RDD的优缺点:
优点:
- 编译时类型安全 :编译时就能检查出类型错误
- 面向对象的编程风格 :直接通过类名点的方式来操作数据
缺点:
- 序列化和反序列化的性能开销 :无论是集群间的通信, 还是IO操作都需要对对象的结构和数据进行序列化和反序列化。
- GC的性能开销 :频繁的创建和销毁对象, 势必会增加GC
DataFrame通过引入schema和off-heap(不在堆里面的内存,指的是除了不在堆的内存,使用操作系统上的内存),解决了RDD的缺点。
- Spark通过schame就能够读懂数据, 因此在通信和IO时就只需要序列化和反序列化数据, 而结构的部分就可以省略了
- 通过off-heap引入,可以快速的操作数据,避免大量的GC。但是却丢了RDD的优点,DataFrame不是类型安全的, API也不是面向对象风格的
DataSet和DataFrame【10】
DataFrame也可以叫Dataset[Row],每一行的类型是Row,不解析每一行究竟有哪些字段,各个字段又是什么类型都无从得知,只能用getAS/getString方法或者共性中的拿出特定字段。
//列信息及数据信息:{"name":"Michael","age":10, "adress": "beijin"}
peopleDF.map(x => x.getAs[String]("adress")).show()
peopleDF.map(x => x.getString(0)).show()
而Dataset中,每一行是什么类型是不一定的,在自定义了case class之后可以很自由的获得每一行的信息。
case class Coltest(col1:String,col2:Int) extends Serializable //定义字段名和类型
/**
rdd
("a", 1)
("b", 1)
("a", 1)
* */
val test: Dataset[Coltest] = rdd.map {
line =>
Coltest(line._1,line._2)
}.toDS
test.map {
line =>
println(line.col1)
println(line.col2)
}
注意:Dataset在需要访问列中的某个字段时是非常方便的,但是:如果要写一些适配性很强的函数时,如果使用Dataset,行的类型又不确定,可能是各种case class,无法实现适配,这时候用DataFrame即Dataset[Row]就能比较好的解决问题
参考
【1】:https://blog.csdn.net/zp17834994071/article/details/108267232
【2】:https://www.jianshu.com/p/f31e802d121b
【3】:https://segmentfault.com/a/1190000009554236
【4】:https://blog.csdn.net/qq_35495339/article/details/98119422
【5】:https://www.cnblogs.com/lillcol/p/11233456.html
【6】:https://blog.csdn.net/xiaoduan_/article/details/79730428
【7】:https://zhuanlan.zhihu.com/p/148137008
【8】:https://zhuanlan.zhihu.com/p/363800243
【9】:https://www.jianshu.com/p/c0181667daa0
【10】:https://blog.csdn.net/qq_43688472/article/details/86491720
【11】:https://blog.csdn.net/hellozhxy/article/details/82660610

若有收获,就点个赞吧
0 人点赞
