1. 开篇
1.1. 概念
**Document**(文档)最小数据单元。**Index**(索引)包含一堆有相似结构的document数据,代表了一类相似或者相同的document。**Type**(分类)表示Index中的一个逻辑数据分类。每个Index可以有多个type,而每个type又可以存储多个document。5.X版本一个index可创建多个type。6.X版本一个index只能存在一个type。7.0版本开始,移除Type概念。主要原因是在同一个索引中,存储仅有小部分字段相同或者全部字段都不相同的document,会导致数据稀疏,影响Lucene有效压缩数据的能力,目前在7.x中兼容Type。**Field**(字段)document里面有多个field,每个field就是一个数据字段。**Shard**(分片)单台机器无法存储大量数据,Elasticsearch可以将一个Index(索引)中的数据切分为多个Shard,分布在不同服务器节点上,这样就可以实现水平扩展,提升吞吐量和性能。这其实是一种数据分散集群的架构模式。每个Shard都是一个Lucene index,可以看成是一个Lucene实例。
**Replica**(副本)Shard中的数据就可能丢失,为每个Shard创建多个备份(Replica副本)。Replica可以在Shard故障时提供备用服务,保证数据不丢失,多Replica提升搜索的吞吐量和性能,主从架构模式。每个索引的Primary Shard数量,需要在索引建立时就设置,一旦设置完不能修改,而Replica Shard可以随时修改数量。
| Elasticsearch | 关系型数据库 |
|---|---|
| Index | 数据库实例 |
| Type | 表 |
| Document | 行 |
| Field | 列 |
1.2. 集群状况
**green**每个索引的primary shard和replica shard为active状态。**yellow**每个索引的primary shard为active状态,但部分replica shard非active状态(即不可用状态)。**red**部分索引的primary shard非active状态,部分索引有数据丢失。GET /_cat/health?v
1.3. 索引操作
查询
GET /_cat/indices?v
创建
PUT /test_index?pretty
删除
DELETE /test_index?pretty
1.4. CURD操作
index 索引名 / type 类型名 / id document唯一标识。
- 新增
Elasticsearch会自动建立Index和Type,同时,ES默认会对document的每个field都建立倒排索引,让其可以被搜索。
PUT /{index}/{type}/{id} { #document数据 }
查询
GET /{index}/{type}/{id}
替换:使用替换方式去修改商品信息时,document的所有field都需要带上。
PUT /{index}/{type}/{id} { #document数据 }
更新
POST /{index}/{type}/{id}/_update {
"doc":{#document的指定field}
}
删除
DELEET /{index}/{type}/{id}
1.5. 数据检索
1.5.1. query string search
搜索词一般都是跟在search参数后面,以query string的http请求形式发起检索。
GET /{index}/{type}/_search Example GET /ecommerce/product/_search?q=name:yagao&sort=price:desc
# 返回结果
{
"took" : 530,
"timed_out" : false,
"_shards" : {
"total" : 1,
"successful" : 1,
"skipped" : 0,
"failed" : 0
},
"hits" : {
"total" : {
"value" : 3,
"relation" : "eq"
},
"max_score" : null,
"hits" : [
{
...
}
]
}
}
字段含义说明:
took耗费时长(毫秒)。timed_out是否超时。_shards数据拆成的分片数,所以对于搜索请求,会打到所有的primary shard(或者是primary shard对应的某个replica shard)。hits.total查询结果的数量,3个document。hits.max_scorescore的含义,就是document对于一个search的相关度的匹配分数,越相关,就越匹配,分数也高。hits.hits包含了匹配搜索的document的详细数据。query string search适用于一些临时、快速的检索请求,如果查询请求很复杂,那么query string search是不太适用的,所以在生产环境中,几乎很少使用query string search。
1.5.2. query DSL
Domain Specified Language Elasticsearch中很常用的一种检索方式。例如:查询商品名中包含yagao关键子的所有商品,并将结果按照售价排序:
GET /ecommerce/product/_search
{
"query" : {
"match" : {
"name" : "yagao"
}
},
"sort": [
{ "price": "desc" }
]
}
所有查询请求参数全部放到了一个http requstbody里面,所以可以构建复杂的查询,适合生产环境使用。
1.5.3. query filter
query filter主要用于对数据进行过滤。例如:我们要搜索商品名称包含“yagao”,且售价大于25元的商品:
GET /ecommerce/product/_search
{
"query" : {
"bool" : {
"must" : {
"match" : {
"name" : "yagao"
}
},
"filter" : {
"range" : {
"price" : { "gt" : 25 }
}
}
}
}
}
1.5.4. full-text search
**全文检索** 例如:查询producer字段中包含 producer 或 jiajieshi :
GET /ecommerce/product/_search
{
"query" : {
"match" : {
"producer" : "producer jiajieshi"
}
}
}
match 中空格分隔 producer jiajieshi ,只要producer字段中包含了上述任意一个字符,就都会被检索到。采用全文检索时,返回的每一项数据中有一个 _score 字段,这个就是 相关度分数 的意思,分数越高,则越接近检索词。
1.5.5. phrase search
**短语搜索** 与全文检索相反。输入的关键字必须在出现指定的文本中,一模一样才匹配。例如:查询producer字段中包含 jiajieshi producer :
GET /ecommerce/product/_search
{
"query" : {
"match_phrase" : {
"producer" : "jiajieshi producer"
}
}
}
1.5.6. highlight search
**高亮搜索** 举个例子,我们希望检索name字段包含 yaogao 的所有商品,然后对检索结果中的 yaogao 文本进行高亮:
GET /ecommerce/product/_search
{
"query" : {
"match" : {
"name" : "yagao"
}
},
"highlight": {
"fields" : {
"name" : {}
}
}
}
匹配项的结果里多了个“highlight”字段,里面用高亮了匹配的文本:
{
"took" : 97,
"timed_out" : false,
"_shards" : {
"total" : 1,
"successful" : 1,
"skipped" : 0,
"failed" : 0
},
"hits" : {
"total" : {
"value" : 1,
"relation" : "eq"
},
"max_score" : 0.13353139,
"hits" : [
{
"_index" : "ecommerce",
"_type" : "product",
"_id" : "1",
"_score" : 0.13353139,
"_source" : {
"name" : "gaolujie yagao",
"desc" : "gaoxiao meibai",
"price" : 30,
"producer" : "gaolujie producer",
"tags" : [
"meibai",
"fangzhu"
]
},
"highlight" : {
"name" : [
"gaolujie <em>yagao</em>"
]
}
}
]
}
}
2. 架构
2.1. 负载均衡
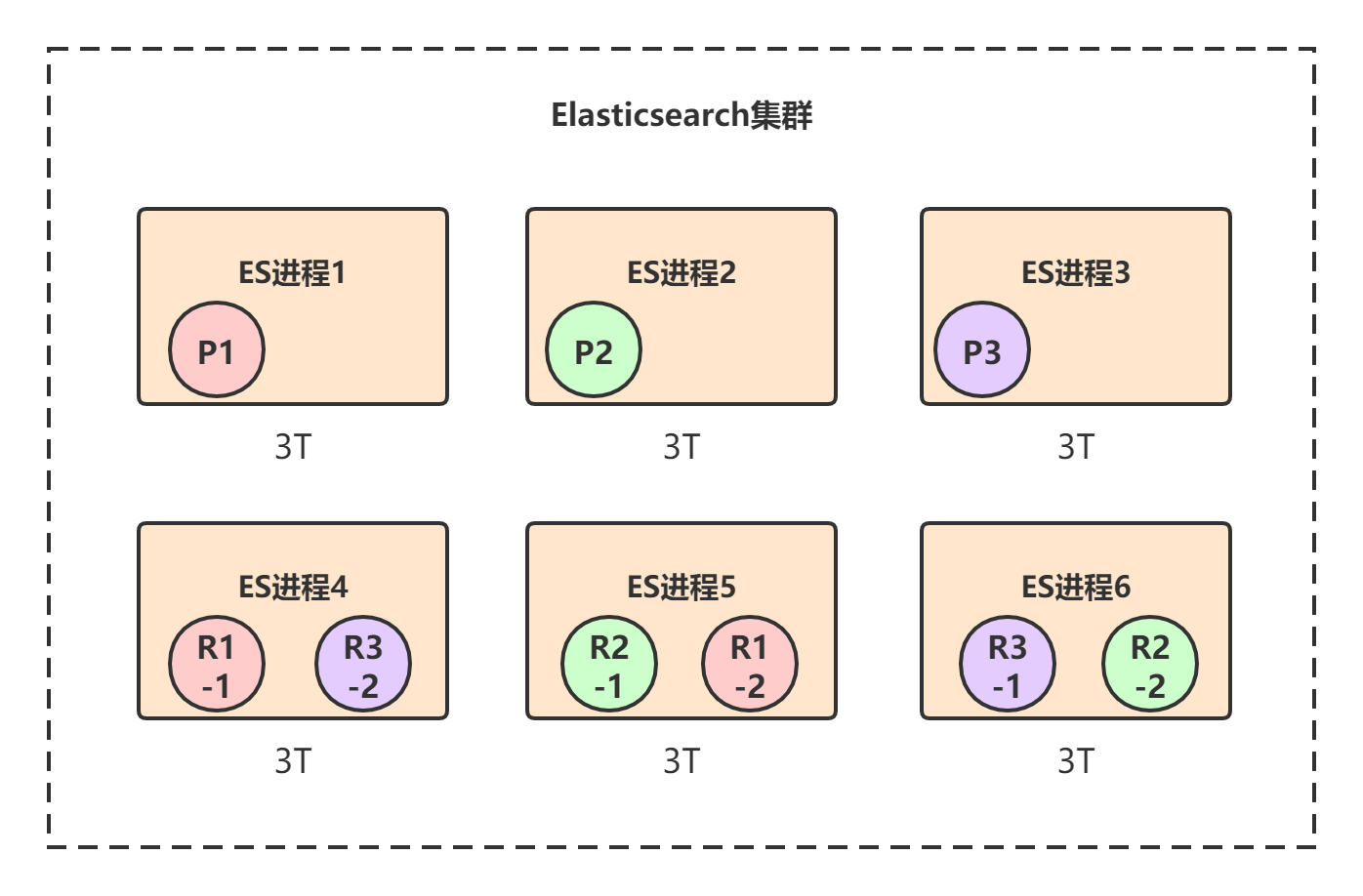
3节点集群创建索引,共有3个primary shard,每个primary shard都有2个replica shard,那总共就是9个shard:
PUT /test_index
{
"settings" : {
"number_of_shards" : 3,
"number_of_replicas" : 2
}
}
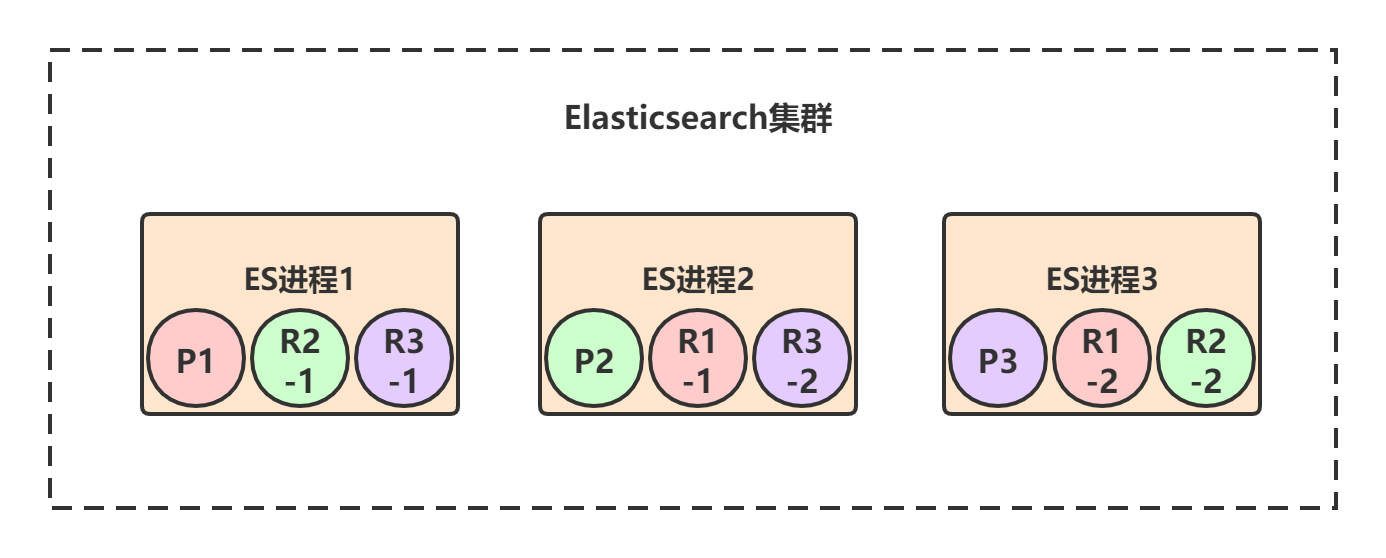
- P1 / P2 / P3:test_index索引的数据会被均匀分布到3个primary shard。
- R-:每个primary shard都有一个replica shard,replica shard其实就是个数据备份,类似于msater/slave模式中的slave节点。6个replica shard也会被负载均衡到各个ES进程节点上。
Elasticsearch有一个原则:primary shard和它对应的replica shard不能全部署在同一个节点上,否则节点挂了的话,数据和拷贝都会丢失。
2.2. 高可用
Elasticsearch保证集群高可用的方式采用主从模式+选举的方式。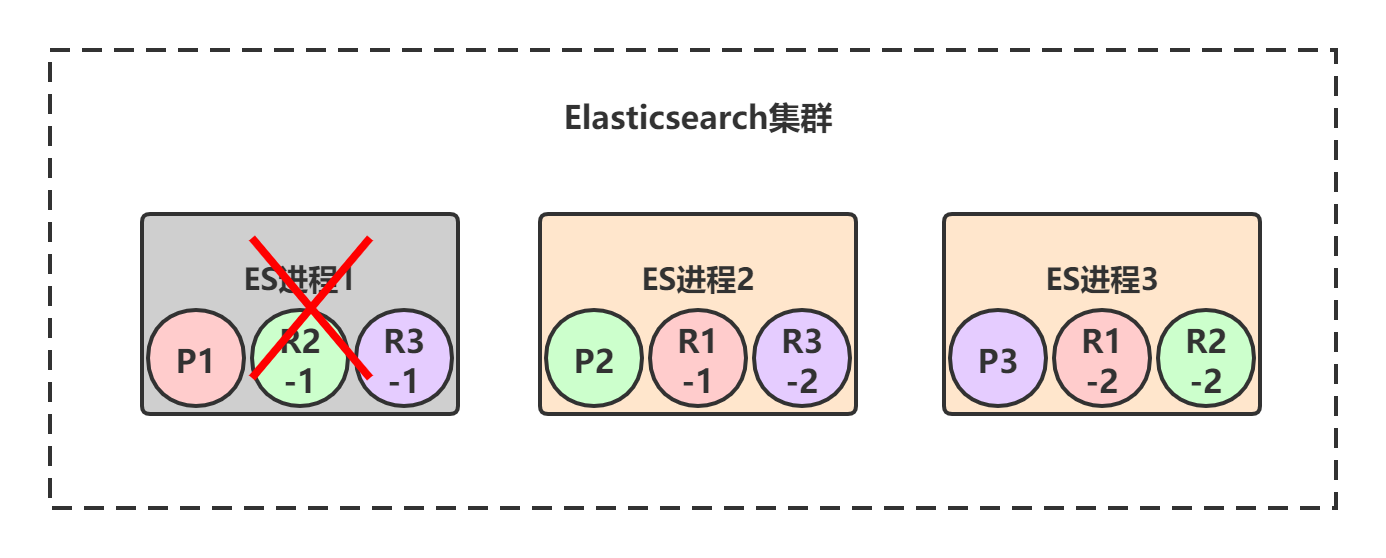
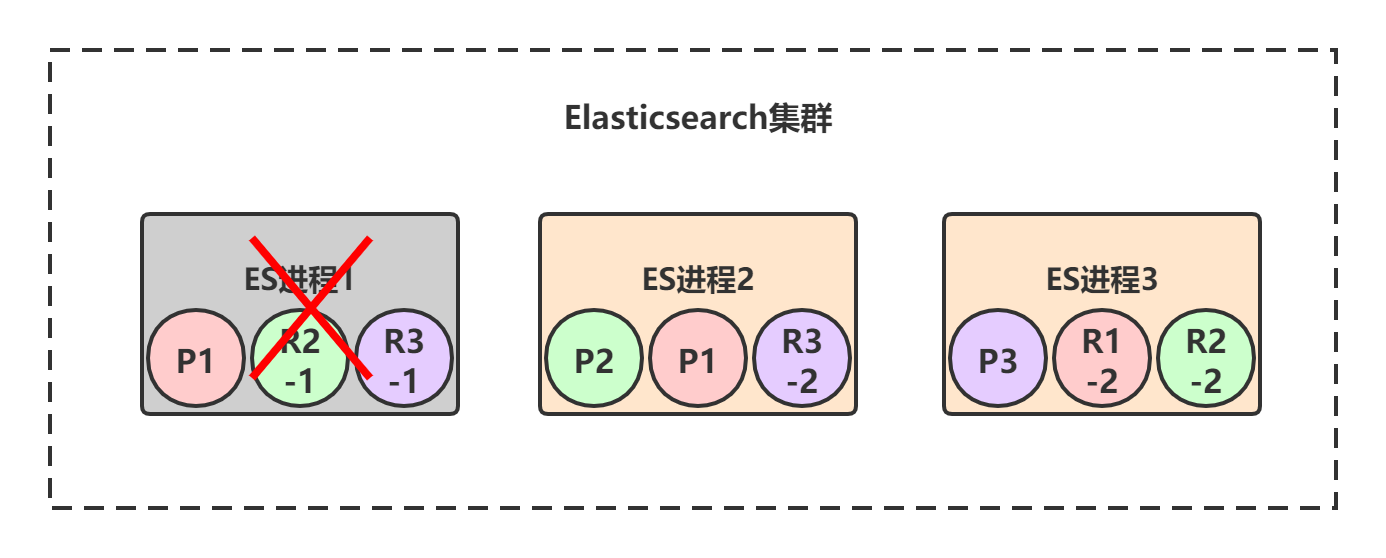
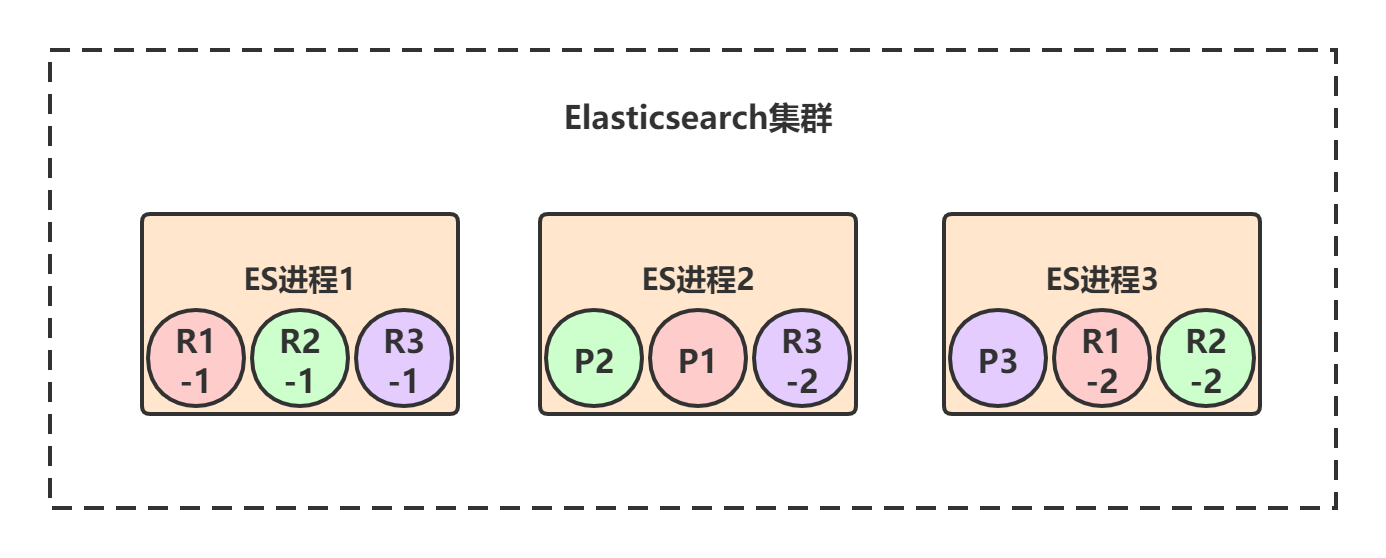
节点1宕机了,对于P1这个primary shard为非active状态,此时集群状态转为red。但是节点2和节点3上仍然保存着完整的数据,P1的两个副本R1-1和R1-2开始一轮选举,胜出者为primary shard,假设R1-1胜出。
当宕机的节点1恢复后,shard又会重新加入到集群中,原来P1发现节点2上有新的primary shard,自身变成repilca shard,并进行数据同步。
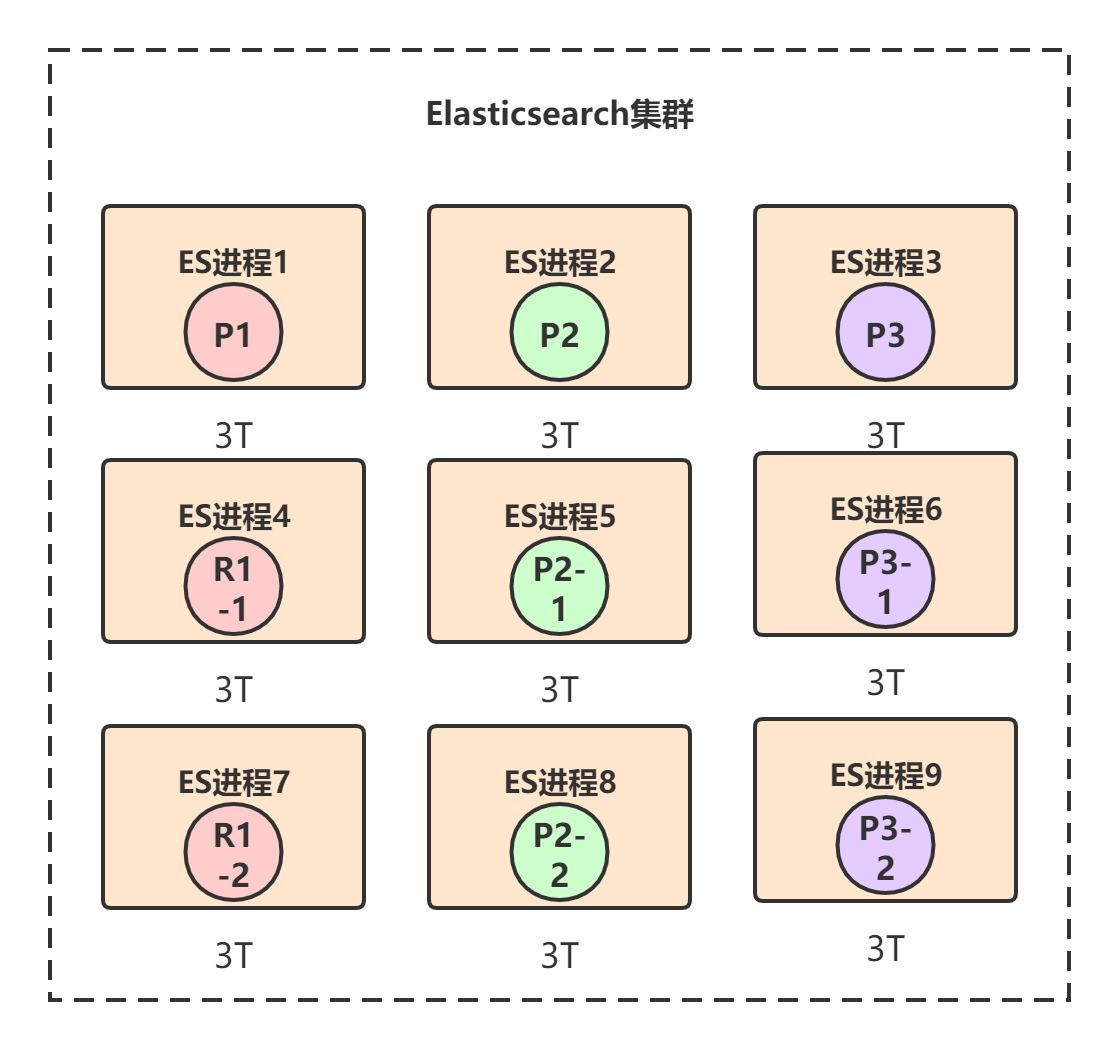
2.3. 水平扩展
2.4. 并发控制
2.4.1. _version
Elasticsearch内部采用了版本号机制对document的并发修改进行控制。所谓版本号,本质是一种乐观锁。Elasticsearch写入document数据时,ES会自动为document生成一个版本号_version。首次创建document时,_version版本号为1,每次对这个document修改或删除时,_version版本号会自动加1。
执行流程:
- 假设我们现在有两个线程A和B,同时读取到了商品信息,此时获取到的document的_version版本号是相同的,假设都是1。
- A线程在本地将库存减1后,发送PUT更新请求,请求里带上了版本号PUT /product/storage/1?version=1。
- ES收到请求后,对数据进行更新,然后将版本号+1。
- B线程在本地将库存减1后,发送PUT更新请求,请求里也带上了版本号1,PUT /product/storage/1?version=1。
- ES收到请求后,发现id为1的document的版本号已经是2了,而B线程的更新请求里带的版本号还是1,两者不一样,于是拒绝更新,返回报错。
2.4.2. external version
基于自身维护的一个版本号来进行并发控制。
内部版本语法
?version=1
自定义版本号语法
?version=1&version_type=external
当version_type=external的时,只有当提供的version比Elasticsearch中的_version大的时候,才能完成修改。
2.5. 路由原理
Elasticsearch就是采用了hash路由算法,对document记录的id标识进行计算,产生了一个shard序号,通过这个shard序号就可以立即确认写到哪个shard里面,路由算法shard = hash(routing_key) % number_of_primary_shards。也可以手动指定document的routing_key值,那么routing_key相同的document就会路由到同一个shard中。
2.5.1. 写入
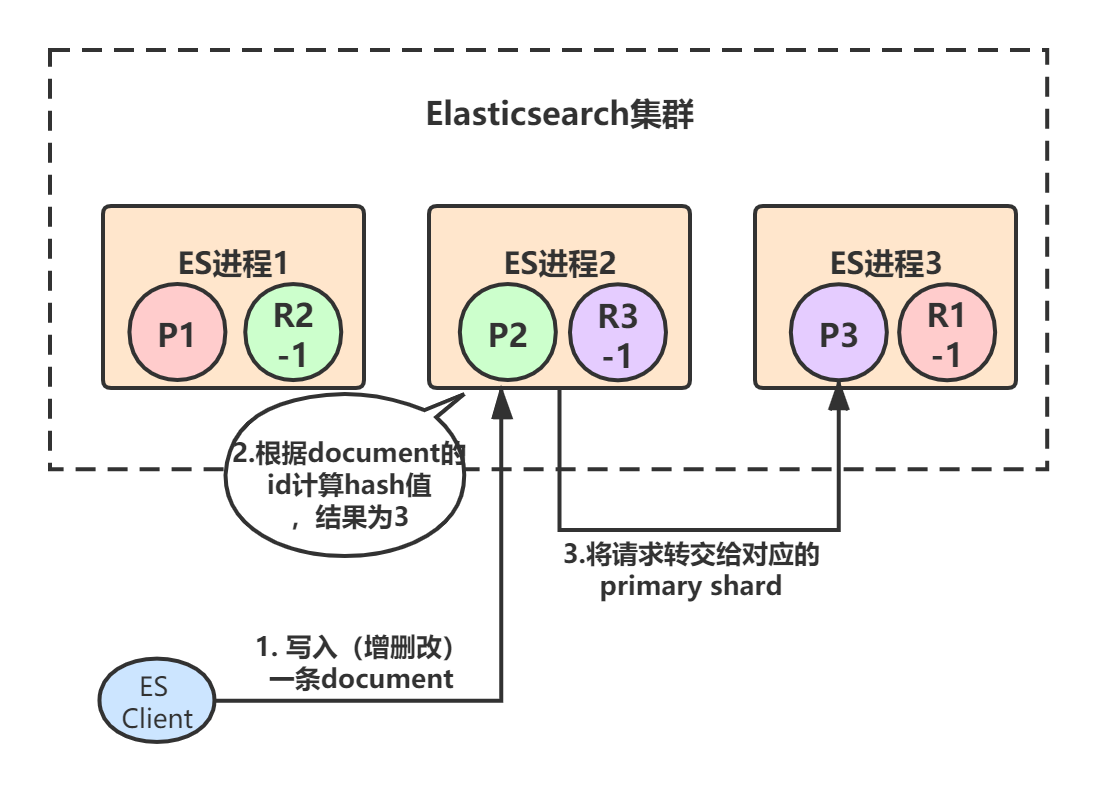
Example:初始3个primary shard,每个primary shard都有一个副本。初始时,客户端(集成了Elasticsearch Client SDK)发起了一条document的写入请求,请求可能hit到任意某个ES节点上,hit到的这个节点也叫做coordinate node(协调节点)
每个ES节点其实都知道集群中的其它节点的信息,包括集群中一共有多少primary/replica shard,每个节点上分配着哪些primary/replica shard。
- 假设ES进程2节点(协调节点)接受到了请求,于是根据document的id进行hash计算,发现结果是3,也就是应该由P3这个primary shard处理这个请求,所以就会把请求转发给ES进程3节点上的P3。
- primary shard 3处理完请求后,会将数据同步到自己的replica shard(R3-1),同步完后响应ES进程2,ES进程2(协调节点)收到响应后,返回给ES client结果。
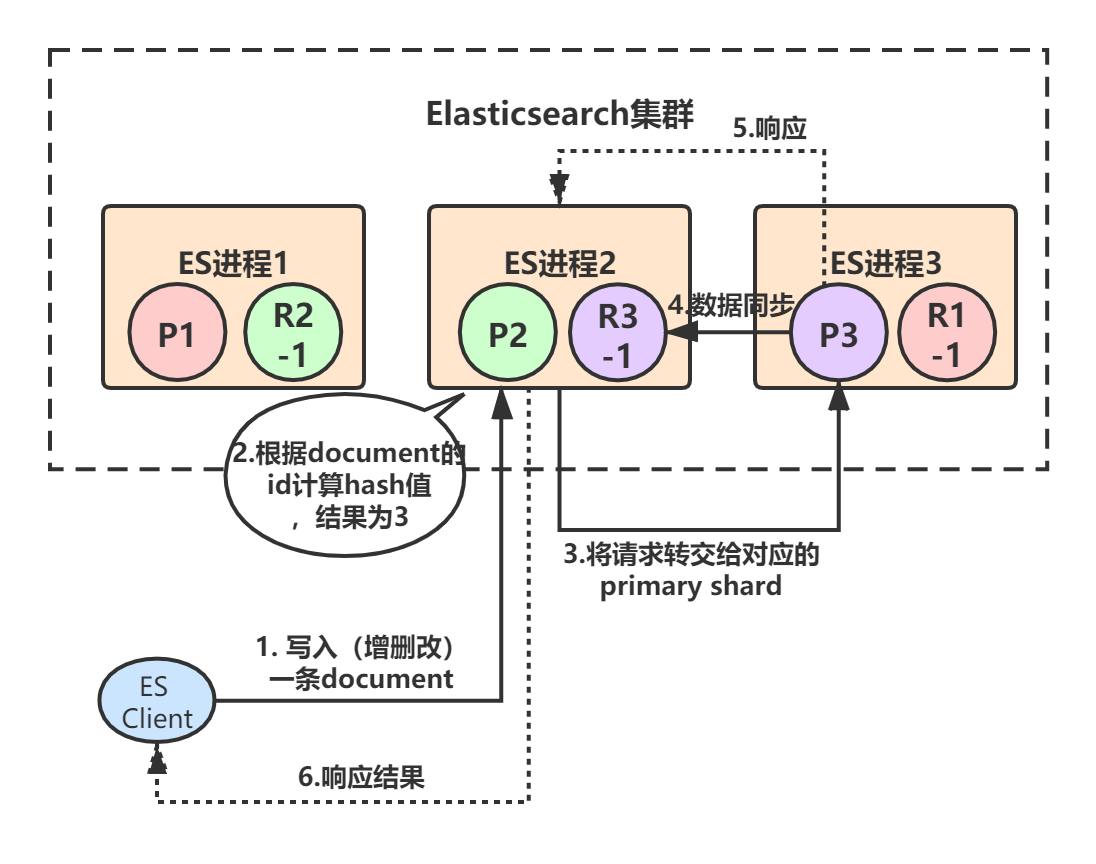
Elasticsearch对于写请求,最终都是转交给primary shard去处理的。
2.5.2. 读取
document数据查询的原理基本和写入类似,查询请求既可以由primary shard处理,也可以由replica shard处理,提升系统的吞吐量和性能。coordinate node(协调节点)在接受到查询请求后,会采用round-robin算法,在对应的primary shard及其所有replica中随机选择一个发送请求,以达到读请求负载均衡的目的。
Example:客户端发起查询某个document的请求,假设命中到ES进程2,ES进程2根据document Id计算出应该由primary shard 3来处理,primary shard 3有一个replica,所以协调节点会采用round-robin算法选取其中一个转发请求,比如选择了R3-1,然后将请求转发给它,R3-1查询得到结果后返回,最终ES进程2将结果返回给客户端。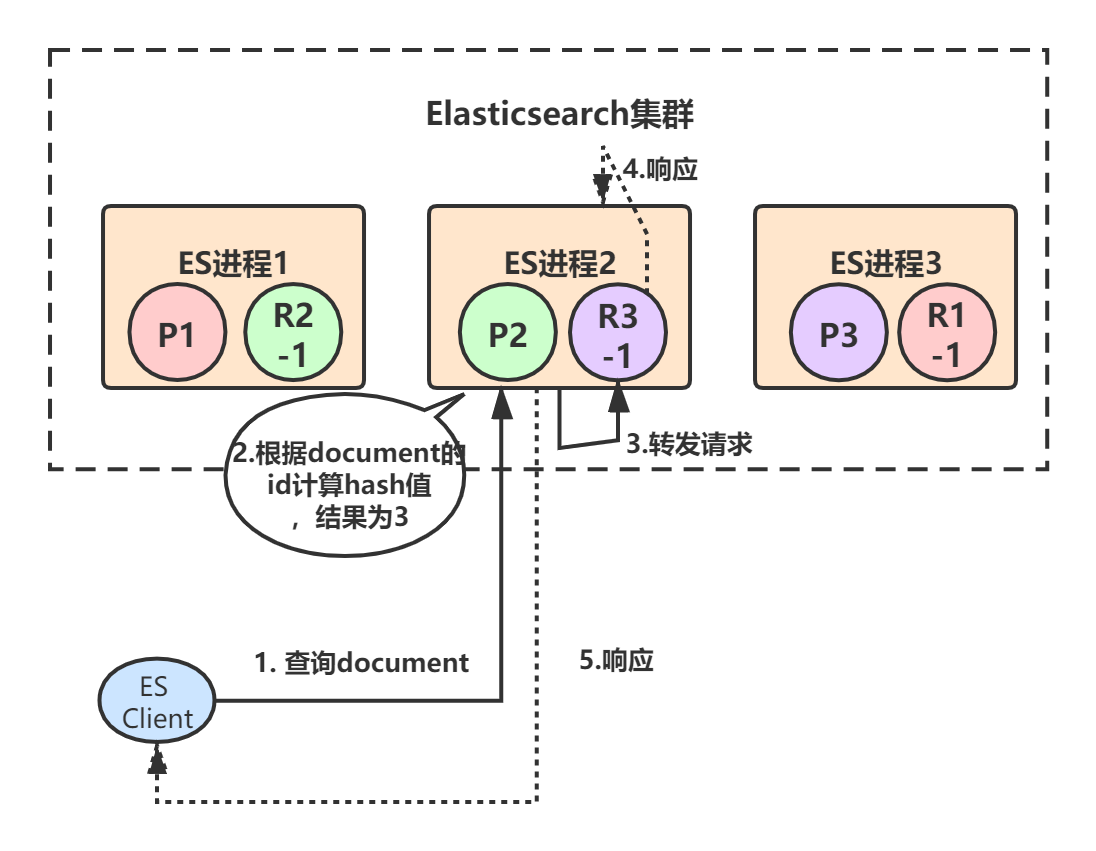
2.6. 数据一致性
Elasticsearch其实提供了三种数据同步机制:one,all,quorum,在请求时带上consistency参数,默认是quorum。
PUT /index/type/id?consistency=quorum
- one:对于document的写操作(增删改),只要有一个primary shard是active活跃可用的,操作就可以执行。
- all:对于document的写操作(增删改),要求必须所有的primary shard和replica shard都是活跃的,才可以执行这个写操作。
- quorum:对于document的写操作(增删改),写之前必须确保大多数shard都可用,当不满足“大多数”这个条件时,请求就会默认等待1分钟,超过时间就会报timeout错误。我们可以在写操作的时候,加一个timeout参数。
PUT /index/type/id?timeout=30
Elasticsearch是通过一个公式去计算“大多数”shard。
(primary + number_of_replicas) / 2 + 1
2.7. 数据持久化
**Segment File**
在Elasticsearch中创建一个index索引时,需要指定shard分片,一个shard分片在底层其实是一个Lucene索引,它由若干个segment文件和对应的commit point(提交点文件)构成。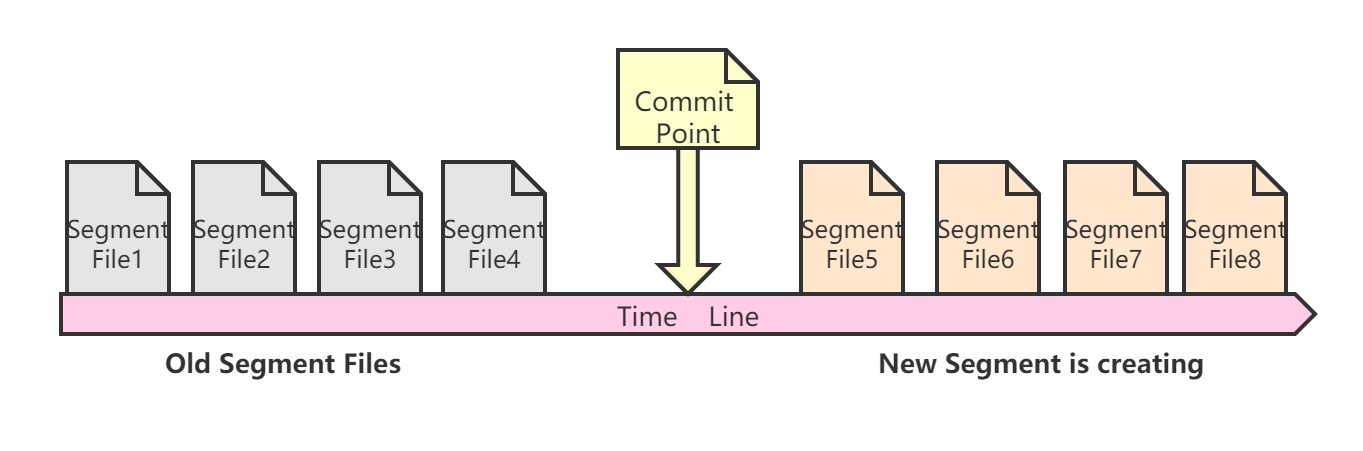
Segment文件可以理解成底层存储document数据的文件,ES进行检索时最终是从它里面检索出数据,而commit point文件可以理解成一个保存了若干segment信息的列表,它标识着这个commit point前所有旧的segment file文件。
Example:当Elasticsearch创建commit point文件时,会已有一些segment文件是已经存在的,那commit point就保存着这些旧的segment文件的信息。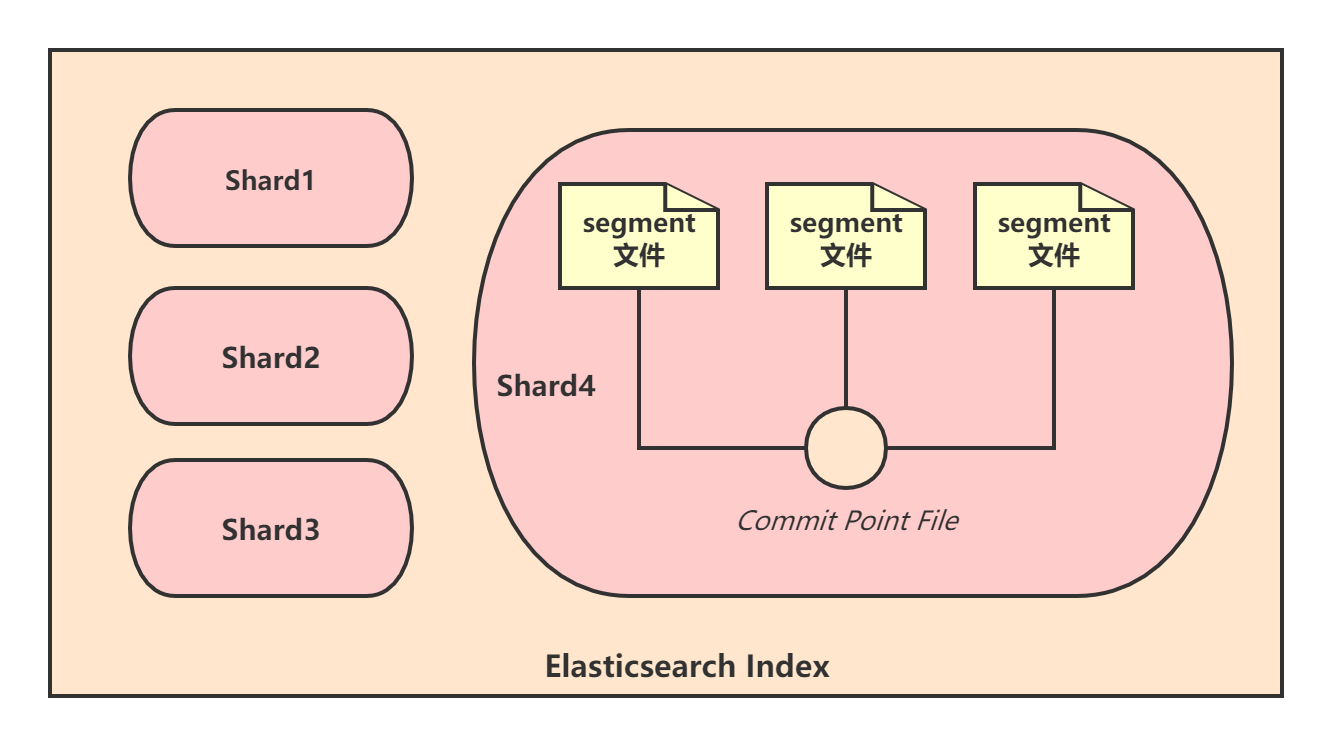
写入流程:一条document数据被写入磁盘会经历以下几个过程。
1.write > 2.refresh > 3.flush > 4.merge
**Write**
document会被写入in-memory buffer中,所谓in-memory buffer其实就是应用内存。同时,document数据会被写入translog日志文件。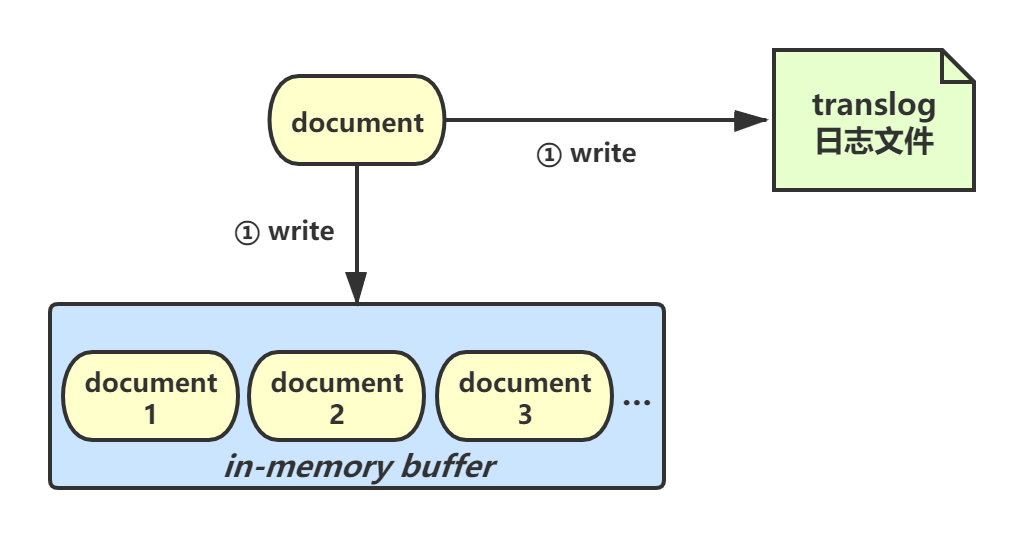
**Refresh**
每隔1秒Elasticsearch会执行一次refresh操作,将buffer中的数据refresh到filesystem cache中的一个新segment file中。filesystem cache等价os cache。注意:此时的segment file仅仅是存在于os cache中的缓存数据,并不存在于磁盘上。
refresh操作完成后,buffer会被清空。如果buffer满了也会执行refresh。当数据进入filesystem cache后可以被检索到。
Elasticsearch是准实时(NRT,near real-time),默认每隔1秒refresh一次,写入的数据1秒之后才能被检索到。通过index的index.refresh_interval参数配置refresh的时间间隔。
**Flush**
segment file一直存在于os cache中,如果发生宕机cache数据会丢失,提供一种机制将缓存数据写入磁盘文件。在refresh的过程中,os cache中的segment file会越来越多(每次refresh都会创建一个新的segment file)。当translog到达阈值时触发flush操作。
- flush的第一步,将buffer中的现有数据refresh到os cache中,清空buffer。
- 在磁盘上写入一个commit point文件,里面标识着这个commit point前os cache中的所有旧segment file文件数据。
- 强行将os cache中的所有数据fsync到磁盘文件中去。
- 最后将translog清空,因为此时里面记录的数据此时都已经被fsync到磁盘了。
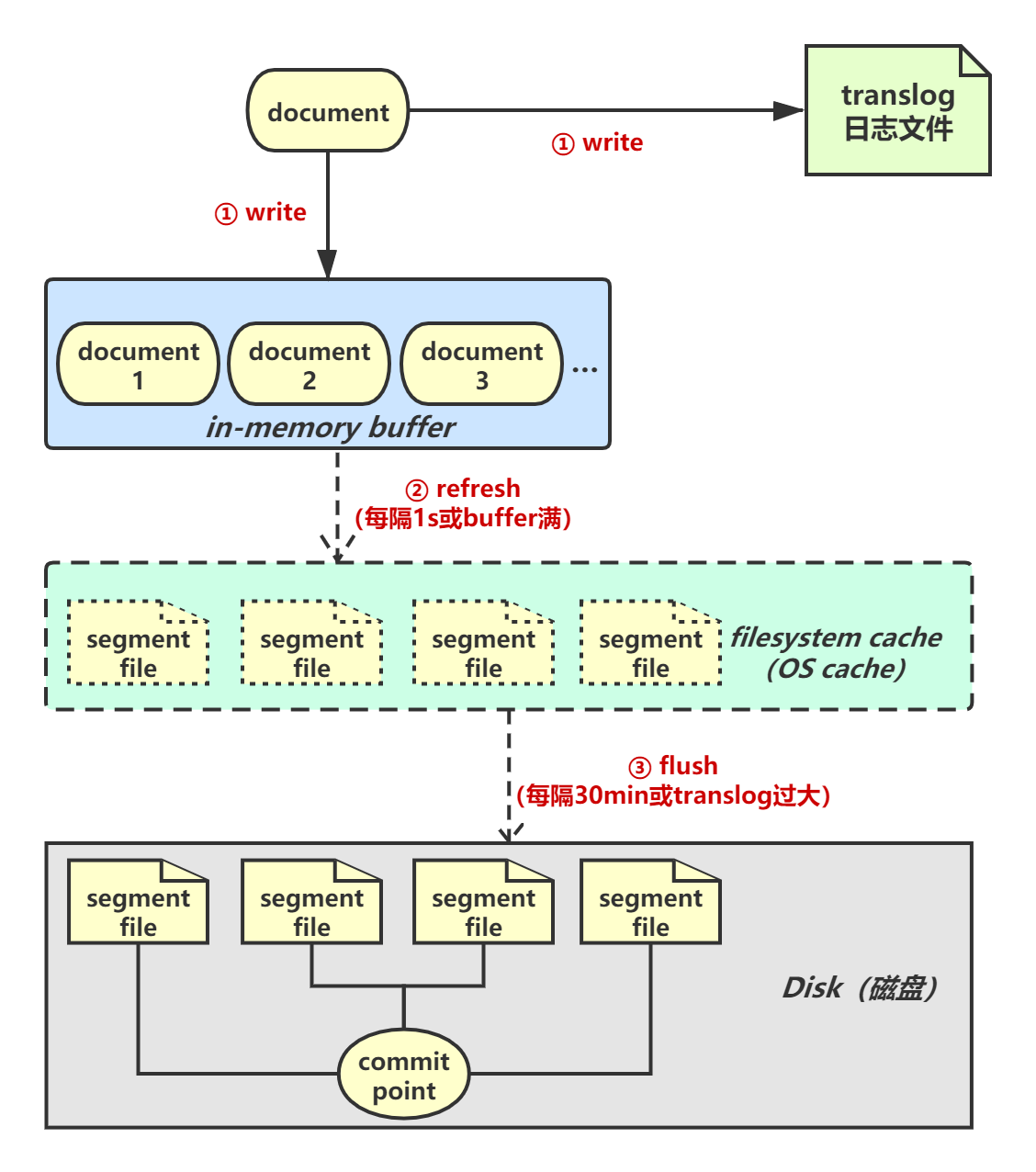
默认每隔30分钟会自动执行一次flush操作,如果translog过大会提前触发。
在执行flush操作之前,数据要么是停留在buffer中,要么是停留在os cache中,此时一旦这台机器宕机,数据就全丢了。所以,需要将数据写入到一个专门的日志文件中,此时即使机器宕机了,再次重启时,Elasticsearch会自动读取translog日志文件中的数据,恢复到内存buffer和os cache中去。translog中的数据,本身也是先写入os cache,然后默认每隔5秒刷一次到磁盘中。所以默认情况下,即使有translog保证可用性,也可能丢失5s的数据。此时数据仅仅停留在buffer或者translog文件的os cache中,如果此时机器挂了,会丢失这5秒钟的数据。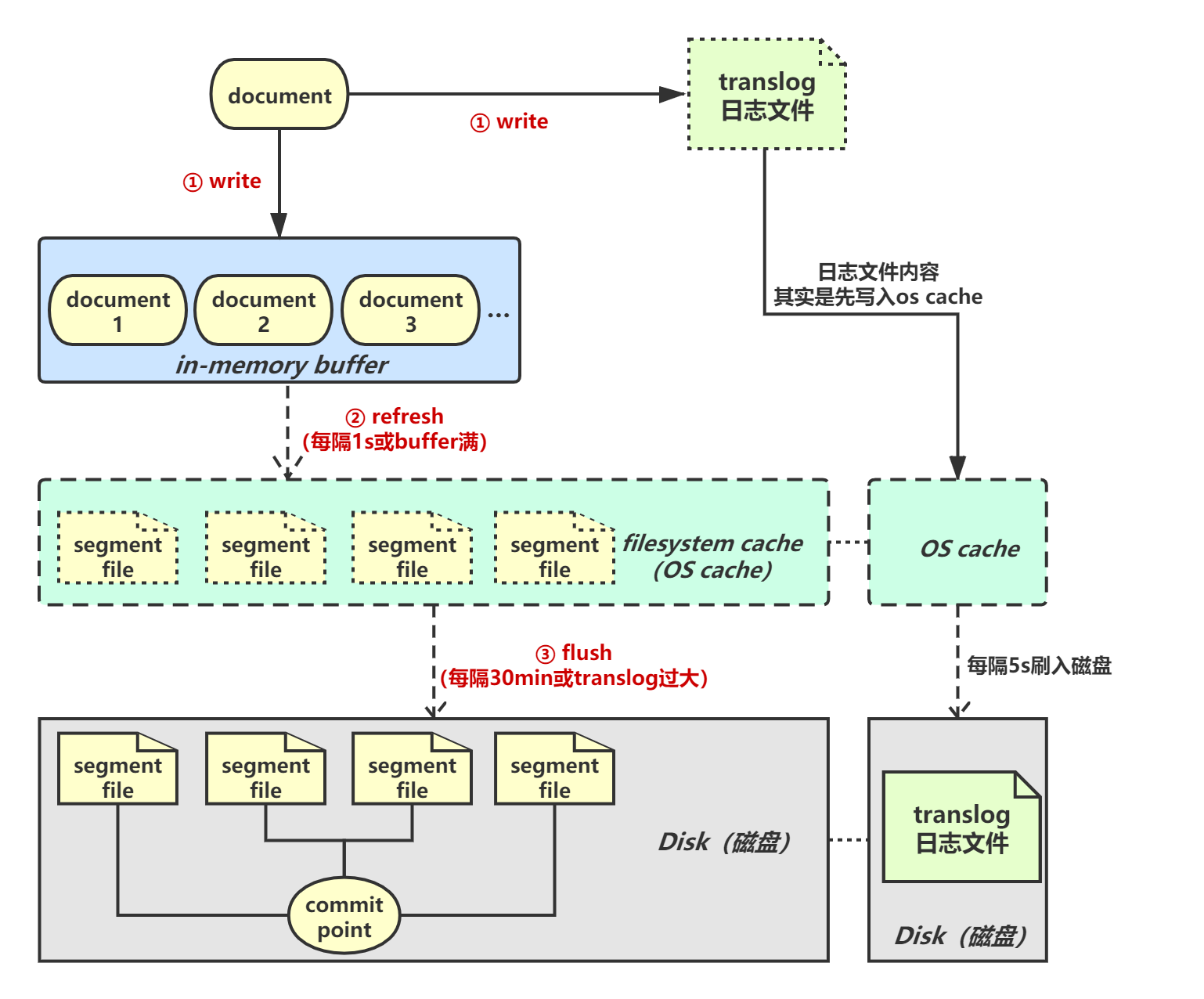
保证数据不丢失设置index的index.translog.durability参数,每次写入一条数据都写入buffer,同时fsync写入磁盘上translog文件,写性能、吞吐量严重下降。
**Merge**
每refresh一次会在os cache中产生一个新的segment file,随着segment file增多,搜索的性能会降低。Elasticsearch会定期执行merge操作,每次merge时,ES会选择一些相似大小的segment进行合并,同时会将那些标识为deleted的document物理删除掉。合并后新的segment file会被写入磁盘,同时会新建commit point文件,里面标识着所有合并后新的segment file。
2.8. 分词器
对文本内容进行一些特定处理,根据处理后的结果再建立倒排索引,主要的处理过程一般如下:
character filter符号过滤,比如hello过滤成hello,I&you过滤成I and you ;tokenizer分词,比如,将hello you and me切分成hello、you、and、me;token filter比如,dogs替换为dog,liked替换为like,Tom 替换为 tom,small 替换为 little等等。
内置了以下几种分词器 standard analyzer simple analyzer whitespace analyzer language analyzer 。
我们可以通过以下命令,看下分词器的分词效果:
GET /{index}/_analyze
{
"analyzer": "standard",
"text": "a dog is in the house"
}
# 采用standard分词器对text进行分词
分词器的各种替换行为,也叫做normalization,本质是为了提升命中率,官方叫做recall召回率。
对于document中的不同字段类型,采用不同的分词器进行处理,比如 date 类型压根就不会分词,检索时完全匹配,而对于 text 类型会进行分词处理。
2.8.1. 定制分词器
修改分词器的默认行为。比如,我们修改my_index索引的分词器,启用english停用词:
PUT /my_index
{
"settings": {
"analysis": {
"analyzer": {
"es_std": {
"type": "standard",
"stopwords": "_english_"
}
}
}
}
}
查看分词效果:
GET /my_index/_analyze
{
"analyzer": "es_std",
"text": "a dog is in the house"
}
2.8.2. IK分词器
安装:GitHub上下载预编译好的IK包,与ES版本一致。解压缩放置到
YOUR_ES_ROOT/plugins/ik/目录下,重启Elasticsearch。 https://github.com/medcl/elasticsearch-analysis-ik/releases。
IK和Elasticsearch主要的版本对照:
| IK version | ES version |
|---|---|
| master | 7.x -> master |
| 6.x | 6.x |
| 5.x | 5.x |
IK分词器有两种analyzer ik_max_word ik_smart 但是一般是选用 ik_max_word 。ik_max_word 会将文本做最细粒度的拆分,比如会将“中华人民共和国国歌”拆分为“ 中华人民共和国 中华人民 中华 华人 人民共和国 人民 人 民 共和国 共和 和 国国 国歌 ”等等,会穷尽各种可能的组合。ik_smart 只做最粗粒度的拆分,比如会将“中华人民共和国国歌”拆分为“ 中华人民共和国 国歌 ”。
IK分词器的分词效果,先将改变指定字段的mapping:
PUT /my_index
{
"mappings": {
"properties": {
"text": {
"type": "text",
"analyzer": "ik_max_word"
}
}
}
}
分词效果:
GET /my_index/_analyze
{
"text": "美专家称疫情在美国还未达到顶峰",
"analyzer": "ik_max_word"
}
**配置文件**
IK的配置文件存在于 YOUR_ES_ROOT/plugins/ik/config 目录下,目录下各个文件作用:main.dic IK原生内置的中文词库,总共有27万多条,只要是这些单词,都会被分在一起;quantifier.dic 放了一些单位相关的词;suffix.dic 放了一些后缀;surname.dic 中国的姓氏;stopword.dic 英文停用词。
如果自定义词库,可以修改 IKAnalyzer.cfg.xml 的 ext_dict ,配置我们扩展的词库,重启 ES 生效。**热更新词库**
目前有两种方案,业界一般采用第一种:
- 修改IK分词器源码,然后每隔一定时间,自动从MySQL中加载新的词库。
- 基于IK分词器原生支持的热更新方案:部署一个web服务器,提供一个http接口,通过 modified 和 tag 两个 http 响应头,来提供词语的热更新。

若有收获,就点个赞吧
0 人点赞
