1. 介绍
分布式流处理平台。**特性**
- 发布和订阅流式的记录。这一方面与消息队列或者企业消息系统类似。
- 储存流式的记录,并且有较好的容错性。
- 在流式记录产生时就进行处理。
**应用场景**
- 构造实时流数据管道,它可以在系统或应用之间可靠地获取数据。(相当于message queue)
- 构建实时流式应用程序,对这些流数据进行转换或者影响。(流处理,通过kafka stream topic和topic之间内部进行变化)
**概念**
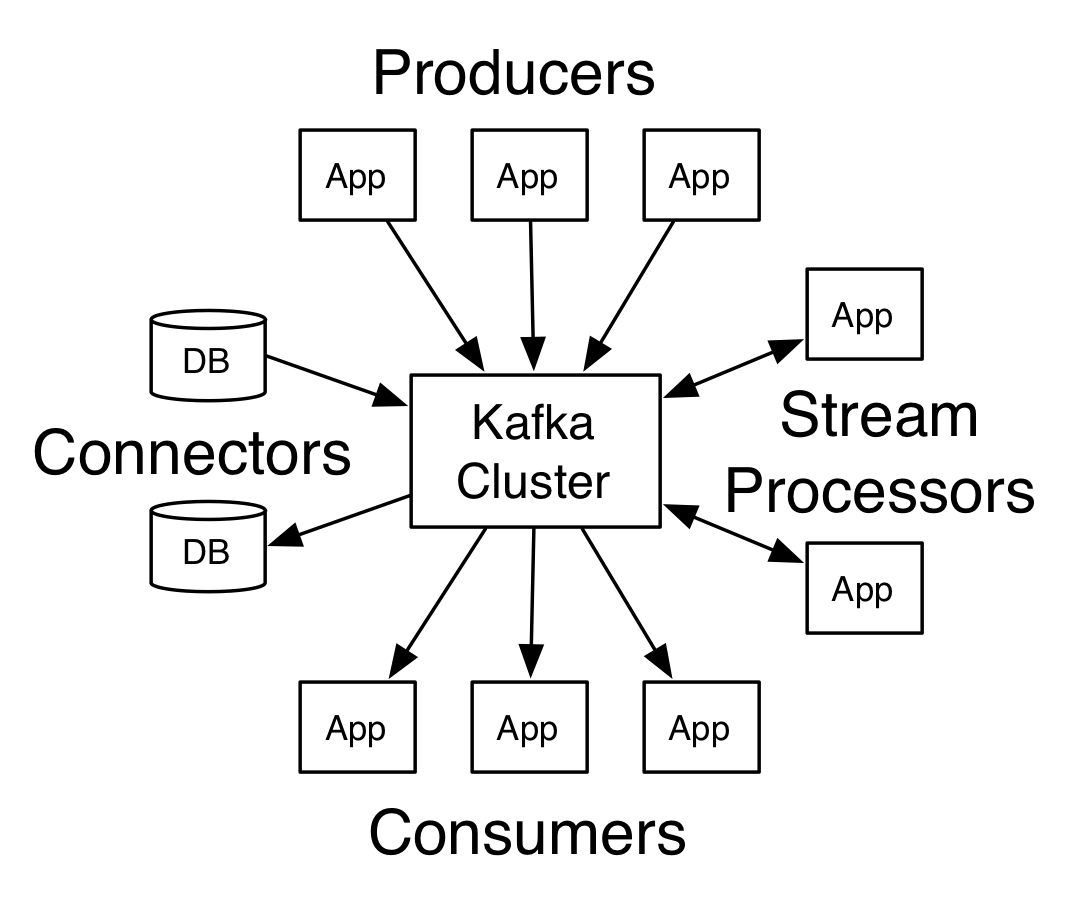
- Kafka作为一个集群,运行在一台或者多台服务器上。
- Kafka通过 topic对存储的流数据进行分类。
- 每条记录中包含key、value、timestamp(时间戳)。
**核心API**
- Producer API 发布一串流式的数据到一个或者多个Kafka topic。
- Consumer API 订阅一个或多个topic ,并对接收的流式数据进行处理。
- Streams API 流处理器,消费一个或多个topic产生的输入流,然后生产一个输出流至一个或多个topic中,在输入/输出流中进行有效的转换。
- Connector API 构建并运行可重用的生产者或消费者,将Kafka topics连接到已存在的应用程序或者数据系统。比如,连接到一个关系型数据库,捕捉表(table)的所有变更内容。
1.1. Topics & 日志
Topic 数据主题,一串流式的记录用来区分业务系统。Kafka中的Topics总是多订阅者模式,一个topic可以拥有一个或者多个消费者来订阅它的数据。对于每一个topic, Kafka集群都会维持一个分区日志。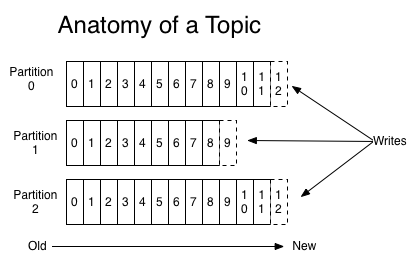
每个分区都是有序且顺序不可变的记录集,并不断地追加到结构化的commit log文件。分区中的每一个记录都会分配一个id号来表示顺序,我们称之为offset用来唯一的标识分区中每一条记录。
Kafka 集群保留所有发布的记录,无论他们是否已被消费,并通过一个可配置的参数,保留期限来控制。例如:如果保留策略设置为2天,一条记录发布后两天内,可以随时被消费,两天过后这条记录会被抛弃并释放磁盘空间。Kafka的性能和数据大小无关,所以长时间存储数据没有什么问题。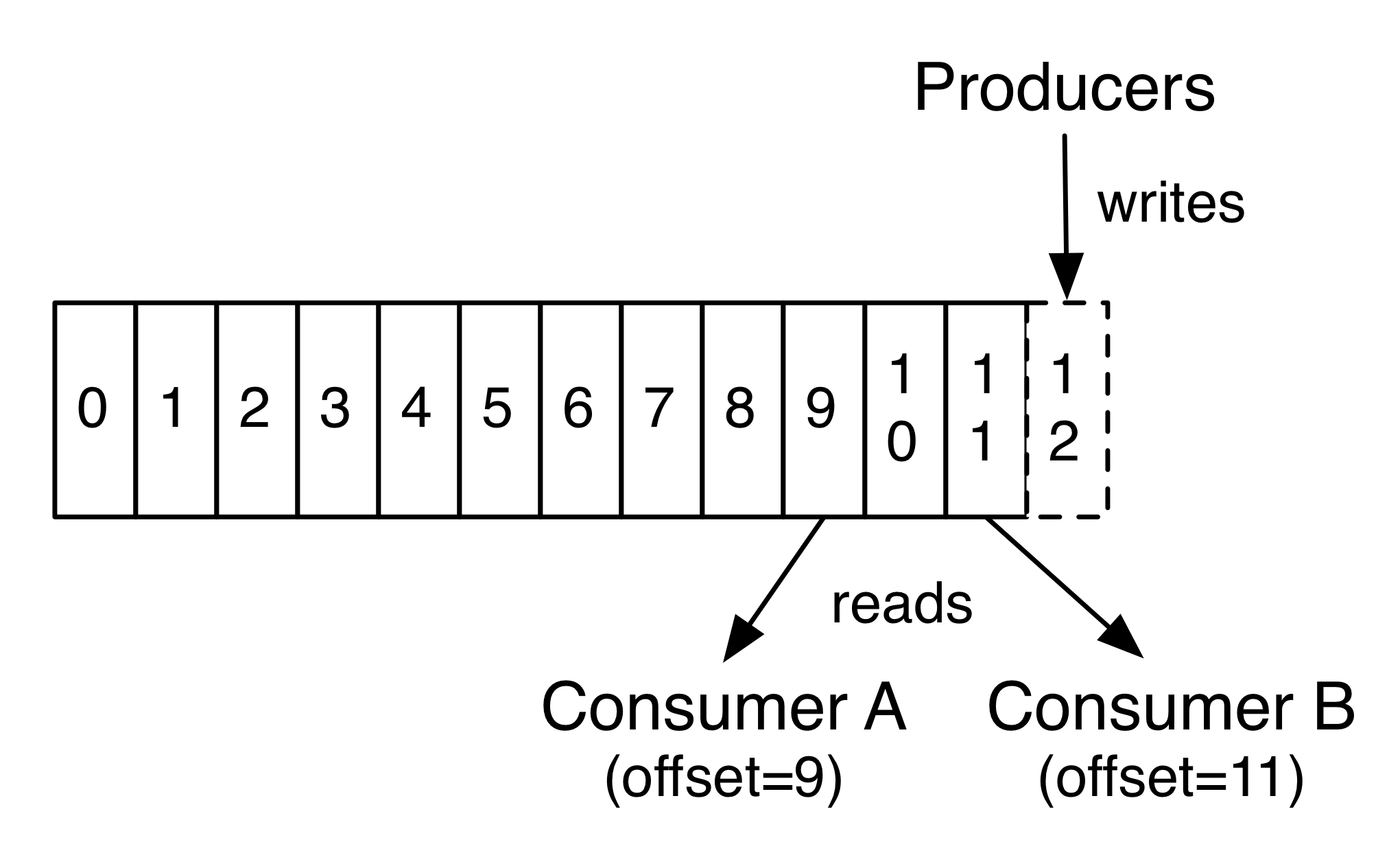
在每一个消费者中唯一保存的元数据是offset(偏移量)即消费在log中的位置。偏移量由消费者所控制:通常在读取记录后,消费者会以线性的方式增加偏移量,但是实际上,由于这个位置由消费者控制,所以消费者可以采用任何顺序来消费记录。例如:一个消费者可以重置到一个旧的偏移量,从而重新处理过去的数据;也可以跳过最近的记录,从”现在”开始消费。
这些细节说明Kafka 消费者是非常廉价的,消费者的增加和减少对集群或者其他消费者没有多大的影响。例如:使用命令行工具,对一些topic内容执行tail操作,并不会影响已存在的消费者消费数据。
日志中的分区(partition)用途:
当日志大小超过了单台服务器的限制,允许日志进行扩展。
每个单独的分区都必须受限于主机的文件限制,不过一个主题可能有多个分区,因此理论上可以处理无限量的数据。
-
1.2. 分布式
日志分区在Kafka集群的服务器上。每个服务器在处理数据和请求时,共享这些分区,每一个分区都会在已配置的服务器上进行备份,确保容错性。
每个分区都有一台server作为leader,零台或多台server作为followers。leader处理一切对分区的读写请求,follwers被动同步leader的数据。当leader宕机了,followers选举一个新的leader。每台server都会成为某些分区的leader和某些分区的follower,因此集群的负载是平衡的。1.3. 生产者
生产者将数据发布到指定topic中,并负责将记录分配到topic的哪一个分区中。可以使用循环的方式来简单地实现负载均衡,也可以根据某些语义分区函数,例如:记录中的key来完成。
1.4. 消费者
消费者使用
消费组名称来进行标识,发布到topic中的每条记录被分配给订阅消费组中的一个消费者实例。消费者实例可以分布在多个进程中或者多个机器上。
- 如果所有的消费者实例在同一消费组中,消息记录会负载均衡到每一个消费者实例。
- 如果所有的消费者实例在不同的消费组中,每条消息记录会广播到所有的消费者进程。

如图所示,Kafka 集群有两台 server 的,四个分区(p0-p3)和两个消费者组。消费组A有两个消费者,消费组B有四个消费者。
通常情况下,每个 topic 都会有一些消费组,一个消费组对应一个”逻辑订阅者”。一个消费组由许多消费者实例组成,便于扩展和容错。这就是发布和订阅的概念,只不过订阅者是一组消费者而不是单个的进程。
Kafka中实现消费的方式是将日志中的分区划分到每一个消费者实例上,以便在任何时间,每个实例都是分区唯一的消费者。维护消费组中的消费关系由Kafka协议动态处理。如果新的实例加入组,他们将从组中其他成员处接管一些分区。如果一个实例消失,拥有的分区将被分发到剩余的实例。
Kafka只保证分区内的记录是有序的,而不保证主题中不同分区的顺序。每个分区按照key值排序足以满足大多数应用程序的需求。但如果你需要总记录在所有记录的上面,可使用仅有一个分区的主题来实现,这意味着每个消费者组只有一个消费者进程。
1.5. high-level 保证
- 生产者发送到指定
topic partition的消息将按照发送的顺序处理。 - 一个消费者实例按照日志中的顺序查看记录。
- 对于具有N个副本的Topic,最多
N-1服务器故障,从而保证不会丢失任何提交到日志中的记录。1.6. 系统消息
消息系统有两个模块:队列和发布-订阅。
- 传统消费系统:
队列:消费者池从server读取数据,每条记录被池子中的一个消费者消费。
优点:允许将处理数据的过程分给多个消费者实例,从而扩展处理过程。 缺点:队列不是多订阅者模式的,一旦一个进程读取了数据,数据就会被丢弃。
发布订阅:记录被广播到所有的消费者。
优点:允许广播数据到多个进程。 缺点:每条消息都会发送给所有的订阅者,无法进行扩展处理。
- 消费组在Kafka有两层概念:
- 队列:消费组允许将处理过程分发给一系列进程(消费组中的成员)。
- 发布订阅:Kafka允许将消息广播给多个消费组。
Kafka的优势在于每个topic都有以下特性—可以扩展处理并且允许多订阅者模式—不需要只选择其中一个。相比于传统消息队列还具有更严格的顺序保证。
传统队列在服务器上保存有序的记录,如果多个消费者消费队列中的数据,服务器将按照存储顺序输出记录。 虽然服务器按顺序输出记录,但是记录被异步传递给消费者,因此记录可能会无序的到达不同的消费者。这意味着在并行消耗的情况下,记录的顺序是丢失的。因此消息系统通常使用“唯一消费者”的概念,即只让一个进程从队列中消费,但这就意味着不能够并行地处理数据。
Kafka设计的更好。topic中的分区是一个并行的概念,能够为一个消费者池提供顺序保证和负载平衡,通过将topic中的分区分配给消费者组中的消费者来实现,以便每个分区由消费组中的一个消费者消耗。通过这样,我们能够确保消费者是该分区的唯一读者,并按顺序消费数据。 众多分区保证了多个消费者实例间的负载均衡。
注:消费者组中的消费者实例个数不能超过分区的数量。
1.7. 存储系统
许多消息队列可以发布消息,除了消费消息之外还可以充当中间数据的存储系统。数据写入Kafka后被写到磁盘,并且进行备份以便容错。直到完全备份,Kafka才让生产者认为完成写入,即使写入失败Kafka也会确保继续写入。Kafka使用磁盘结构,具有很好的扩展性—50kb和50TB的数据在server上表现一致。 可以存储大量数据,并且可通过客户端控制它读取数据的位置,可认为Kafka是一种高性能、低延迟、具备日志存储、备份和传播功能的分布式文件系统。
1.8. 流处理
流处理不仅仅用来读写和存储流式数据,它最终的目的是为了能够进行实时的流处理。例如,零售应用程序可能会接收销售和出货的输入流,经过价格调整计算后,再输出一串流式数据。简单的数据处理可以直接用生产者和消费者的API。对于复杂的数据变换,Kafka提供了Streams API允许应用做一些复杂的处理,比如将流数据聚合或者join。
该功能解决无序数据处理、消费端代码变更后重新处理输入,执行有状态计算等问题。 Streams API建立在Kafka的核心之上:使用Producer/Consumer API作为输入,使用Kafka进行有状态的存储,并在流处理器实例之间使用相同的消费组机制来实现容错。
1.9. 批处理
通过组合存储和低延迟订阅,流式应用程序可以以同样的方式处理过去和未来的数据。 应用程序可以处理历史记录的数据,并且可以持续不断地处理以后到达的数据,而不是在到达最后一条记录时结束进程。 这是一个广泛的流处理概念,其中包含批处理以及消息驱动应用程序。作为流数据管道,能够订阅实时事件使得Kafka具有非常低的延迟,同时Kafka还具有可靠存储数据的特性,可用来存储重要的支付数据,或者与离线系统进行交互,系统可间歇性地加载数据,也可在停机维护后再次加载数据。流处理功能使得数据可以在到达时转换数据。
2. 使用案例
2.1. 消息
Kafka替代了传统Message broker(消息代理),可用于各种场合,例如:将数据生成器与数据处理解耦,缓冲未处理的消息等。与大多数消息系统相比,Kafka拥有更好的吞吐量、内置分区、具有复制和容错的功能,这使它成为一个非常理想的大型消息处理应用。
通常消息传递使用较低的吞吐量,但可能要求较低的端到端延迟,Kafka提供强大的持久性来满足这一要求。
2.2. 跟踪网站活动
Kafka 的初始用例是将用户活动跟踪管道重建为一组实时发布-订阅源。 这意味着网站活动(浏览网页、搜索或其他的用户操作)将被发布到中心topic,其中每个活动类型有一个topic。 这些订阅源提供一系列用例,包括实时处理、实时监视、对加载到Hadoop或离线数据仓库系统的数据进行离线处理和报告等。
每个用户浏览网页时都生成了许多活动信息,因此活动跟踪的数据量通常非常大。
2.3. 度量
Kafka 通常用于监控数据。这涉及到从分布式应用程序中汇总数据,然后生成可操作的集中数据源。
2.4. 日志聚合
许多人使用Kafka来替代日志聚合解决方案。 日志聚合系统通常从服务器收集物理日志文件,并将其置于一个中心系统(可能是文件服务器或HDFS)进行处理。 Kafka 从这些日志文件中提取信息,并将其抽象为一个更加清晰的消息流。 这样可以实现更低的延迟处理且易于支持多个数据源及分布式数据的消耗。 与Scribe或Flume等以日志为中心的系统相比,Kafka具备同样出色的性能、更强的耐用性(因为复制功能)和更低的端到端延迟。
2.5. 流处理
许多Kafka用户通过管道来处理数据,有多个阶段: 从Kafka topic中消费原始输入数据,然后聚合,修饰或通过其他方式转化为新的topic, 以供进一步消费或处理。 例如,一个推荐新闻文章的处理管道可以从RSS订阅源抓取文章内容并将其发布到“文章”topic; 然后对这个内容进行标准化或者重复的内容, 并将处理完的文章内容发布到新的topic; 最终它会尝试将这些内容推荐给用户。 这种处理管道基于各个topic创建实时数据流图。从0.10.0.0开始,在Apache Kafka中,Kafka Streams可以用来执行上述的数据处理,它是一个轻量但功能强大的流处理库。除Kafka Streams外,可供替代的开源流处理工具还包括Apache Storm和Apache Samza。
2.6. 采集日志
Event sourcing是一种应用程序设计风格,按时间来记录状态的更改。
2.7. 提交日志
Kafka可以从外部为分布式系统提供日志提交功能。 日志有助于记录节点和行为间的数据,采用重新同步机制可以从失败节点恢复数据。 Kafka的日志压缩功能支持这一用法。
3. 快速开始
3.1. 安装
https://www.apache.org/dyn/closer.cgi?path=/kafka/1.0.0/kafka_2.11-1.0.0.tgz
tar-xzf kafka_2.11-1.0.0.tgzcd kafka_2.11-1.0.0
3.2. 启动
Kafka使用ZooKeeper服务器,通过与kafka打包在一起的便捷脚本来快速简单地创建一个单节点ZooKeeper实例。
Zookeeper
bin/zookeeper-server-start.sh config/zookeeper.properties
[2013-04-22 15:01:37,495] INFO Reading configuration from: config/zookeeper.properties (org.apache.zookeeper.server.quorum.QuorumPeerConfig)
...
Kafka
bin/kafka-server-start.sh config/server.properties
[2013-04-22 15:01:47,028] INFO Verifying properties (kafka.utils.VerifiableProperties)
[2013-04-22 15:01:47,051] INFO Property socket.send.buffer.bytes is overridden to 1048576 (kafka.utils.VerifiableProperties)
...
3.3. 创建Topic
创建一个分区和一个副本名称为test的Topic:
bin/kafka-topics.sh --create --zookeeper localhost:2181 --replication-factor 1 --partitions 1 --topic test
list指令查看topic:
bin/kafka-topics.sh --list --zookeeper localhost:2181
test
注:可通过代理配置实现,发布topic不存在时自动创建。
3.4. 发送消息
Kafka自带一个命令行客户端,它从文件或标准输入中获取输入,并将其作为message(消息)发送到Kafka集群。默认情况下,每行将作为单独的message发送。运行producer,在控制台输入一些消息以发送到服务器。
bin/kafka-console-producer.sh --broker-list localhost:9092 --topic test
This is a message
This is another message
3.5. 启动消费者
bin/kafka-console-consumer.sh --bootstrap-server localhost:9092 --topic test--from-beginning
This is a message
This is another message
3.6. 设置多代理集群
创建代理配置文件。
cp config/server.properties config/server-1.properties
cp config/server.properties config/server-2.properties
配置文件设置属性。
config/server-1.properties:
broker.id=1
listeners=PLAINTEXT://:9093
log.dir=/tmp/kafka-logs-1
config/server-2.properties:
broker.id=2
listeners=PLAINTEXT://:9094
log.dir=/tmp/kafka-logs-2
broker.id属性是集群中每个节点的名称,这一名称是唯一且永久的。必须重写端口和日志目录,因为我们在同一台机器上运行这些,我们不希望所有的代理尝试在同一个端口注册,或者覆盖彼此的数据。
启动新节点。
bin/kafka-server-start.sh config/server-1.properties &
...
bin/kafka-server-start.sh config/server-2.properties &
...
创建副本为3的topic。
bin/kafka-topics.sh --create --zookeeper localhost:2181 --replication-factor 3 --partitions 1 --topic my-replicated-topic
bin/kafka-topics.sh --describe --zookeeper localhost:2181 --topic my-replicated-topic
Topic:my-replicated-topic PartitionCount:1 ReplicationFactor:3 Configs:
Topic: my-replicated-topic Partition: 0 Leader: 1 Replicas: 1,2,0 Isr: 1,2,0
第一行为所有分区的摘要,下面的每行都给出了一个分区的信息。因为我们只有一个分区,所以只有一行。
- leader:负责给定分区所有读写操作的节点。每个节点都是随机选择的部分分区的领导者。
- replicas:复制分区日志的节点列表,不管这些节点是leader还是仅仅活着。
- isr:一组“同步”replicas,是replicas列表的子集,它活着并被指到leader。
注:示例中节点1是Topic中唯一分区Leader。
在已创建的原始Topic上运行相同的命令来查看它的位置。
bin/kafka-topics.sh --describe --zookeeper localhost:2181 --topic test
Topic:testPartitionCount:1 ReplicationFactor:1 Configs:
Topic: testPartition: 0 Leader: 0 Replicas: 0 Isr: 0
发送信息至新topic。
bin/kafka-console-producer.sh --broker-list localhost:9092 --topic my-replicated-topic
...
my testmessage 1
my testmessage 2
消费消息。
bin/kafka-console-consumer.sh --bootstrap-server localhost:9092 --from-beginning --topic my-replicated-topic
...
my testmessage 1
my testmessage 2
容错性测试。
# Linux
ps aux | grep server-1.properties
7564 ttys002 0:15.91 /System/Library/Frameworks/JavaVM.framework/Versions/1.8/Home/bin/java
...
kill-9 7564
# Windows
wmic process where "caption = 'java.exe' and commandline like '%server-1.properties%'"get processidProcessId
6016
taskkill /pid 6016 /f
Leader已经切换到一个从属节点,而且节点1也不在同步副本集中。
bin/kafka-topics.sh --describe --zookeeper localhost:2181 --topic my-replicated-topic
Topic:my-replicated-topic PartitionCount:1 ReplicationFactor:3 Configs:
Topic: my-replicated-topic Partition: 0 Leader: 2 Replicas: 1,2,0 Isr: 2,0
即使Leader宕机,消息仍可消费。
bin/kafka-console-consumer.sh --bootstrap-server localhost:9092 --from-beginning --topic my-replicated-topic
...
my testmessage 1
my testmessage 2
^C
3.7. 导入/导出
Kafka Connect可扩展工具可将数据导入和导出至Kafka。通过运行connectors(连接器),使用自定义逻辑来实现与外部系统的交互。 准备数据
# Linux
echo-e "foo\nbar"> test.txt
# Windows
echofoo> test.txt
echobar>> test.txt
启动两个standalone(独立)运行的连接器,各自运行在单独的本地专用进程上。 并提供三个配置文件,首先是Kafka Connect的配置文件,包含常用的配置,如Kafka brokers连接方式和数据的序列化格式。 其余的配置文件均指定一个要创建的连接器。这些文件包括连接器的唯一名称,类的实例,以及其他连接器所需的配置。
Monster:~ chiang$ bin/connect-standalone.sh config/connect-standalone.properties config/connect-file-source.properties config/connect-file-sink.properties
这些包含在Kafka中的示例配置文件使用您之前启动的默认本地群集配置,并创建两个连接器: 第一个是源连接器,用于从输入文件读取行,并将其输入到 Kafka topic。 第二个是接收器连接器,它从Kafka topic中读取消息,并在输出文件中生成一行。
在启动过程中,你会看到一些日志消息,包括一些连接器正在实例化的指示。 一旦Kafka Connect进程启动,源连接器就开始从test.txt读取行并且 将它们生产到主题connect-test中,同时接收器连接器也开始从主题connect-test中读取消息, 并将它们写入文件test.sink.txt中。我们可以通过检查输出文件的内容来验证数据是否已通过整个pipeline进行交付:
more test.sink.txt
foo
bar
注:数据存储在Kafka topicconnect-test中,因此我们也可以运行一个console consumer(控制台消费者)来查看 topic 中的数据(或使用custom consumer(自定义消费者)代码进行处理)。
bin/kafka-console-consumer.sh --bootstrap-server localhost:9092 --topic connect-test--from-beginning
{"schema":{"type":"string","optional":false},"payload":"foo"}
{"schema":{"type":"string","optional":false},"payload":"bar"}
...
连接器一直在处理数据,所以我们可以将数据添加到文件中,并看到它在`pipeline`中移动。
echo Another line>> test.txt
3.8. Streams数据处理
Kafka Streams是用于构建实时关键应用程序和微服务的客户端库,输入与输出数据存储在Kafka集群中。 Kafka Streams把客户端能够轻便地编写部署标准Java和Scala应用程序的优势与Kafka服务器端集群技术相结合,使这些应用程序具有高度伸缩性、弹性、容错性、分布式等特性。
4. 生态圈
5. Kafka 1.0.0
5.1. 计划
更新所有代理上的
server.properties并添加以下属性CURRENT_KAFKA_VERSION代表升级的版本。CURRENT_MESSAGE_FORMAT_VERSION代表当前正在使用的消息格式版本。 如果重写过消息格式版本应保留当前值。如果从0.11.0.x之前的版本升级,应将current_message_format_version设置为与current_kafka_version匹配的值。如果从0.11.0.x升级,且没有重写消息格式,需要覆盖inter-broker协议格式。nter.broker.protocol.version=CURRENT_KAFKA_VERSION log.message.format.version=CURRENT_MESSAGE_FORMAT_VERSION inter.broker.protocol.version=CURRENT_KAFKA_VERSION。
一次升级一个代理:关闭代理,更新代码,重新启动代理。
- 整个群集升级后,通过编辑修改协议版本inter.broker.protocol.version 并将其设置为1.0。
- 重新启动代理,以使新的协议版本生效。
- 如果您按照上面的指示重写了消息格式版本,则需要再执行一次滚动重启才能将其升级到最新版本。一旦所有(或大部分的)consumer升级到0.11.0或更高版本,请将每个代理上的log.message.format.version更改为1.0,然后逐个重启它们。
注:之前的Scala Consumer不支持0.11中新的消息格式,避免转换中的性能成本,必须使用较新的Java Consumer 。
5.2. 变更
- 默认启动删除topic功能。
delete.topic.enable=false修改默认配置。 - 对于可以按时间戳搜索的topic,如果找不到分区的偏移量,则会将该分区显示在搜索结果中,并将偏移量值设置为空。在以前的版本中,这类分区不会显示。这种更改是为了使搜索行为与不支持时间戳搜索的topic相一致。
- 如果
inter.broker.protocol.version=1.0或更高版本,即使存在脱机日志目录,代理也会一直保持联机,并在实时日志目录上提交副本。由硬件故障导致的IOException,日志目录可能会变为脱机状态。用户需要监控每个代理度量标准offlineLogDirectoryCount来检查是否存在离线日志目录。 - 增加可回溯的异常
KafkaStorageException。客户端FetchRequest或ProducerRequest版本不支持KafkaStorageException,则KafkaStorageException将在响应中转换为NotLeaderForPartitionException。 - 默认的JVM设置中,
+ DisableExplicitGC被-XX:+ ExplicitGCInvokesConcurrent替换。有助于避免通过直接缓冲区分配本机内存时出现的内存异常。 - 重写handleError方法已经从以下过时类中除去kafka.api:包
FetchRequest,GroupCoordinatorRequest,OffsetCommitRequest,OffsetFetchRequest,OffsetRequest,ProducerRequest,TopicMetadataRequest。这只是为了在代理上使用,但是实际上它已经不再被使用了,实现也没有被维护。只是因为二进制兼容性,保留了一个存根。 - Java客户端和工具现在接受任何字符串作为客户端ID。
- kafka-consumer-offset-checker.sh工具已被弃用。使用kafka-consumer-groups.sh来得到consumer group 的详细信息
- SimpleAclAuthorizer默认将拒绝访问日志记录到授权人日志中。
- AuthenticationException中的一个子类向客户端报告身份验证失败日志。如果客户端连接失败,并不会重新进行验证 。
- 自定义 SaslServer 实现可能会向客户端抛出 SaslAuthenticationException 来提供有关身份验证失败的错误信息。同时应注意在异常信息中,不要向未授权的客户泄露任何安全方面的关键信息。
- 向JMX提供版本和提交ID 的app-info将被弃用,由提供这些属性的metrics(度量)来替换。
- Kafka metrics 现在可能包含非数字值。org.apache.kafka.common.Metric#value()已被弃用并返回0.0以最大限度地减少用户读取每个客户端值时系统断开的概率(用户调用 MetricsReporter 或metrics() 来读取)。org.apache.kafka.common.Metric#metricValue()用来检索数字和非数字的度量值
- 每个 Kafka 速率指标都有相应的累计计数度量标准,带后缀 -total方便后续处理。 例如, records-consumed-rate对应的度量标准是 records-consumed-total。
- 当系统属性kafka_mx4jenable 设置为 true时,Mx4j才会启用。以前它是默认启用的,如果 kafka_mx4jenable 设置为 true,则禁用Mx4j。
- 客户端jar 包中的org.apache.kafka.common.security.auth包现在是公有的,已被添加到javadocs中。这个包中的内部类已经移到其他地方了。
- 当使用授权且用户对topic没有必备的权限时,broker 返回TOPIC_AUTHORIZATION_FAILED错误表示broker对于已存在的topic无权限。如果用户具有权限但topic不存在,则返回UNKNOWN_TOPIC_OR_PARTITION错误。
为新的consumer配置config/consumer.properties 文件中的属性。
5.3. 协议
KIP-112:LeaderAndIsrRequest v1 引入一个分区字段 is_new 。
- KIP-112:UpdateMetadataRequest v4 引入一个分区字段 offline_replicas 。
- KIP-112:MetadataResponse v5 引入一个分区字段offline_replicas。
- KIP-112:ProduceResponse v4 引入了错误代码KafkaStorageException。
- KIP-112:FetchResponse v6 引入了错误代码KafkaStorageException。
KIP-152:添加SaslAuthenticate request来报告身份验证失败。当SaslHandshake request版本大于0,将使用此请求。
5.4 程序升级
将Streams应用程序从0.11.0升级到1.0.0不需要使用代理。Kafka Streams 1.0.0应用程序可以连接到0.11.0,0.10.2和0.10.1的代理。
- 如果监控Streams指标,需要更改报告和代码中的指标名称,因为传递指标的层次结构已更改。
- 公共API,如
ProcessorContext#schedule()、Processor#punctuate()、KStreamBuilder和TopologyBuilder正在被新的API取代。

若有收获,就点个赞吧
0 人点赞
