1. 核心
1.1. 原理
请求、事务和标识符 Leader选举 Zab(状态更新的广播协议) 观察者 服务器的构成 本地存储 服务器与会话 服务器与监视点 客户端 序列化 
1.2. 概念
ZooKeeper是一个分布式协调服务,可用于服务发现,分布式锁,分布式领导选举,配置管理等;其提供了一个类似于Linux文件系统的树状结构(可认为是轻量级的内存文件系统,但只适合存少量信息,完全不适合存储大量文件或者大文件),提供了对于每个节点的监控与通知机制。
1.3. 角色
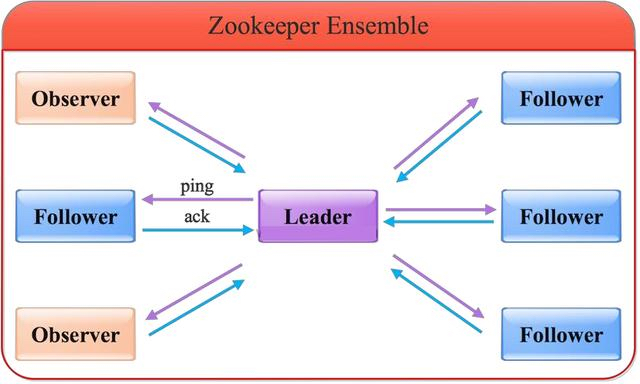
ZooKeeper集群是一个基于主从复制的高可用集群,每个服务承担三种角色中的一种:**Leader**
- 一个ZooKeeper集群同一时间只会有一个实际工作的Leader,他会发起并维护与各Follower及Observer(观察者)间的心跳。
- 所有的写操作必须要通过Leader完成再由Leader将写操作广播给其他服务器。只要有超过半数节点(除Observer节点)。
**Follower**
- 一个ZooKeeper集群可能同时存在多个Follower,他会响应Leader心跳;
- Follower可直接处理并返回客户端的读请求,同时会将请求转发给Leader处理;
- 并且负责在Leader处理写请求时对请求进行投票;
**Observer**
- 角色与Follower类似,但是无投票权。ZooKeeper需要保证高可用和强一致性,为了支持更多的客户端,需要增加更多Server;Server增多,投票阶段延迟增大,影响性能;引入Observer,其不参与投票;Observer接受客户端连接,并将写请求转发给leader节点;加入到更多Observer节点,提高伸缩性,同时不影响吞吐率。
2. ZAB
ZAB(ZooKeeper Atomic Broadcast)ZooKeeper原子消息广播协议。
2.1. 事务请求计数器
协议的事务编号Zxid是一个64位数字,低32位是一个简单的单调递增的计数器,针对客户端每一个事务请求,计数器加1;高32位代表Leader周期epoch的编号,每个当选产生一个新的Leader服务器,就会从这个Leader服务器中取出其本地日志中最大事务的Zxid,并从中读取epoch值,然后加1,以此作为新的epoch,并将低32位从0开始计数。
Zxid(Transaction id)类似RDBMS中事务ID,用于标识一次更新操作的Proposal(提议)ID。为了保证顺序性,改zxid必须单调递增。
2.2. epoch
epoch可以理解为当前集群所处的年代或者周期(每个leader就像皇帝,都有自己的年代号,leader变更会在前一个年代的基础上加1,这样旧的leader崩溃恢复后,没有听从者,Follower只会听从当前年代Leader命令)
两种模式 - 恢复模式(选主) 、广播模式(同步)
Zab协议有两种模式,他们分别为恢复模式(选主)和广播模式(同步)。当服务启动或者在领导者崩溃后,Zab就进入到了恢复模式,当领导者被选举出来,且大多数Server完成了和leader的状态同步以后,恢复模式就结束了。状态同步保证了leader和server具有相同的系统状态。
2.3. 选举过程
- Leader election(选举阶段-选出准Leader):节点在一开始都处于选举阶段,只有一个节点得到超半数节点的票数,他就可以当选准leader。只有到达广播阶段(broadcast)准leader才会成为真的leader。(这一阶段的目的是选出一个准leader,进入下一阶段)
- Discovery(发现阶段):这个阶段Followers跟准leader进行通信,同步Followers最近接收的事务提议。这一阶段的主要目的是发现当前大多数节点接收的最新提议,并且准leader生成新的epoch,让followers接受,更新他们的accepted epoch。一个follower只会连接一个leader,如果有一个节点f认为另一个follower p是leader,follower在尝试连接p时会被拒绝,follower被拒绝之后,就会进入重新选举阶段。
- Synchornization(同步阶段-同步follower副本):同步阶段主要是利用leader前一阶段获得的最新提议历史,同步集群中所有副本。只有当大多数节点都完成同步,准leader才会成为真正的leader。follower只会接收zxid比自己的lastZxid大的提议。
- Broadcast(广播阶段):ZooKeeper集群开始对外提供事务服务,并且leader可以进行消息广播。同时如果有新的节点加入,还需要对新节点进行同步。ZAB提交事务并不像2PC一样需要全部的follower都ACK,只需要得到超过半数的节点的ACK就可以了。
ZAB协议Java实现(FLE-发现阶段和同步合并为Recovery Phase(恢复阶段))
协议的Java版本实现和上面的定义有些不同,选举阶段使用的事 Fast Leader Election(FLE),它包含了选举的发现职责。因为FLE会选举拥有最新提议历史的节点作为leader,省去了发现最新提议的步骤。实际的实现将发现阶段和同步阶段合并为 Recovery Phase(恢复阶段)。所以ZAB的实现只有三个阶段: Fast Leader Election Recovery Phase Broadcast Phase 。
2.4. 投票机制
每个 server 首先给自己投票,然后用自己的原票和其他 server 选票对比,权重大的胜出,使用权重较大的更新自身选票箱。选举过程:
- 每个 server 启动以后询问其他的 server 它要投票给谁。对于其他server的许文,servre每次根据自己的状态都回复自己推荐的leader的id和上一次处理事务的zxid(系统每次启动时每个server都会推荐自己)。
- 收到所有server回复以后,计算出zxid最大的Server,并将这个server相关信息设置成下一次投票的server。
- 计算过程中获得票数最多的server为获胜者,票数超过半数改server为leader。否则继续这个过程,知道leader被选举出来。
- leader开始等待server连接。
- follower连接leader,最大的zxid发送给leader。
- leader根据follower的zxid确定同步点,至此选举阶段完成。
- 选举阶段完成leader同步后,通知follower已经成为uptodate状态。
- follower收到uptodate消息后,又可以重新接受client请求服务。
例如:5台服务器,每台服务器都没有数据,编号分别问1,2,3,4,5按编号依次启动,选举过程:
- 服务器1启动,给自己投票,发投票信息,由于其他服务器未启动所以收不到反馈信息,服务器1处于Looking状态。
- 服务器2启动,给自己投票,同时与之前启动的服务器1交换结果,由于服务器2的编号大所以服务器2胜出,但此时投票数没有大于半数,所以两个服务器的状态依然是Looking。
- 服务器3启动,给自己投票,同时与服务器1,2交换信息,服务器3编号最大胜出,投票大于半数,服务器3成为领导者。
- 服务器4启动,给自己投票,同时与之前1,2,3交换信息,由于3胜出,4编号大无意义,4成为小弟。
- 服务器5启动,和4的逻辑相同,变成小弟。
3. 工作原理
ZooKeeper 核心是原子广播,这个机制保证了各个 server 之间的同步,实现这个机制的协议叫做 Zab 协议,Zab 协议两种模式,恢复模式和广播模式,服务器启动或领导者崩溃后,Zab进入恢复模式,领导者被选举出来,且大多数server完成了和leader的状态同步以后,恢复模式结束,状态同步保证了leader和 server 具有相同的系统状态。
一旦 Leader 已经和大多数 follower 进行状态同步后,可以开始广播消息,进入广播状态。当一个 server 进入 ZooKeeper 服务中,他会在恢复模式下启动,发现 leader ,并和 leader 进行状态同步,待到同步结束,他也参与消息广播。ZooKeeper 服务一直维持在 broadcast 状态,直到 leader 崩溃或者失去大部分的 follower 支持。
广播模式需要保证 proposal 被按顺序处理。zk采用递增的事务 id(zxid)来保证,所有提议(proposal)都在被提出的时候加上 zxid,实现zxid是一个64位数字,高32位是epoch来标识leader关系是否改变,每次leader被选出来,都会有一个新的epoch。低32位递增计数。当leader崩溃或者leader失去大多数 follower,zk进入恢复模式,恢复模式重新选举出一个leader,让所有server恢复到正确的状态。3.1. Znode目录节点
PERSISTENT持久节点EPHEMERAL暂时节点PERSISTENT_SEQUENTIAL持久化顺序编号目录节点EPHEMERAL_SEQUENTIAL暂时化顺序编号目录节点

若有收获,就点个赞吧
0 人点赞
