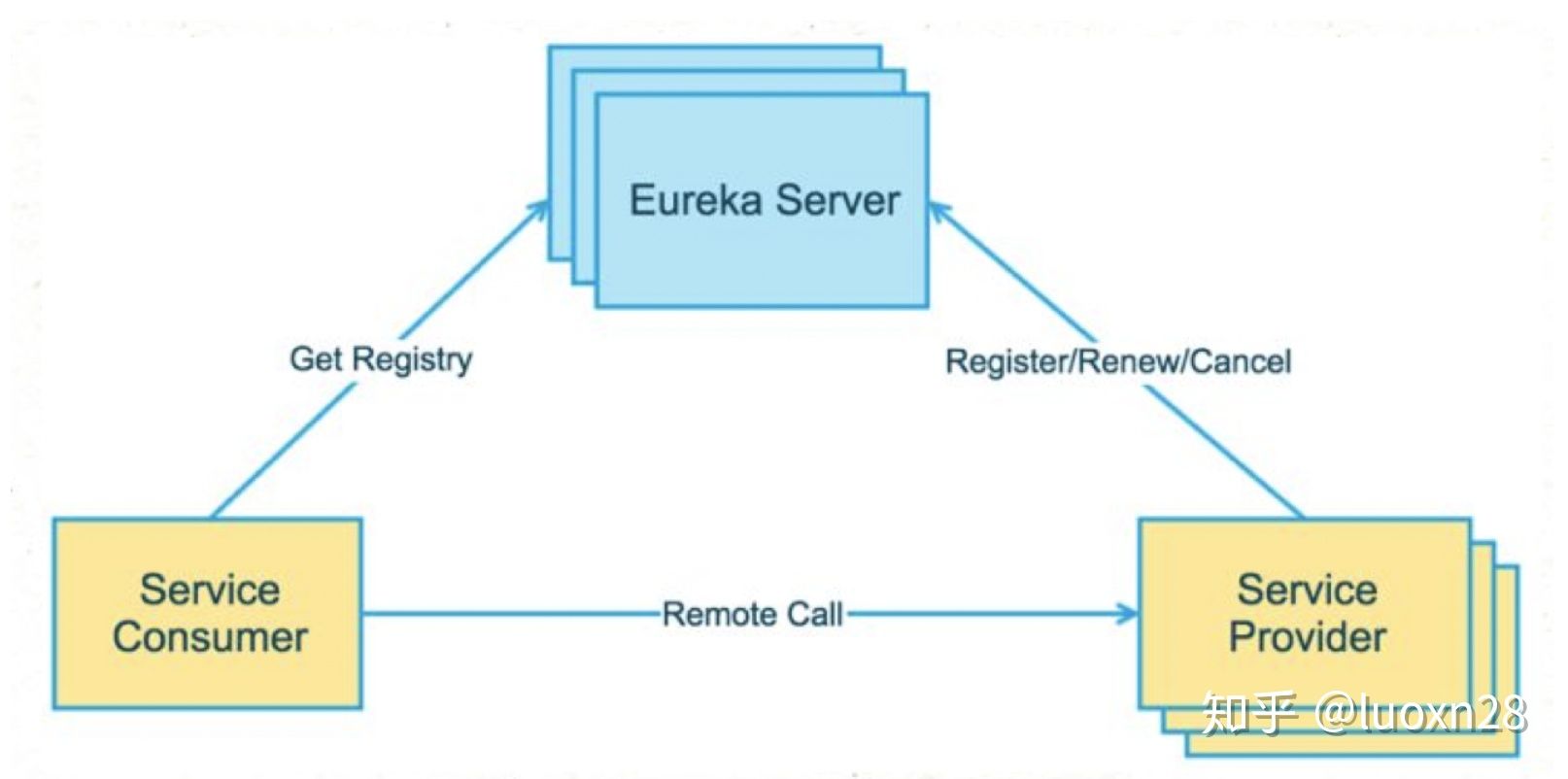
1. Eureka

该CocurrentHashMap为注册表的核心结构,Eureka Server的注册表直接基于纯内存,服务的注册、服务下线、服务故障,全部会在内存里维护和更新这个注册表,服务每隔30秒拉取注册表的时候,Eureka Server提供内存存储的有变化的注册表数据,每隔30秒发起心跳时,也是CocurrentHashMap数据结构里更新心跳时间。维护注册表、拉取注册表、更新心跳时间,全部发生在内存。
1.1. 多级缓存机制
Eureka Server 为了避免同时读写内存数据结构造成的并发冲突问题,还采用了多级缓存机制来进一步提升服务请求的响应速度。**拉取注册表**
首先从 ReadOnlyCacheMap 里查缓存的注册表,若没有,就找 ReadWriteCacheMap 里缓存的注册表,如果还没有,就从内存中获取实际的注册表数据。**注册表发生变更**
会在内存中更新变更的注册表数据,同时过期掉 ReadWriteCacheMap ,此过程不会影响 ReadOnlyCacheMap 提供人家查询注册表,一段时间内 默认30秒 ,各服务拉取注册表会直接读 ReadOnlyCacheMap 30秒过后, Eureka Server 的后台线程发现 ReadWriteCacheMap 已经清空了,也会清空 ReadOnlyCacheMap 中的缓存,下次有服务拉取注册表,又会从内存中获取最新的数据了,同时填充各个缓存。**优点**
- 尽可能保证了内存注册表数据不会出现频繁的读写冲突问题。
- 并且进一步保证对
Eureka Server大量请求,都是快速从纯内存走,性能极高。
1.2. 保护机制
自我保护机制主要在Eureka Client和Eureka Server之间存在网络分区的情况下发挥保护作用,在服务器端和客户端都有对应实现。假设在某种特定的情况下(如网络故障), Eureka Client和Eureka Server无法进行通信,此时Eureka Client无法向Eureka Server发起注册和续约请求,Eureka Server中就可能因注册表中的服务实例租约出现大量过期而面临被剔除的危险,然而此时的Eureka Client可能是处于健康状态的(可接受服务访问),如果直接将注册表中大量过期的服务实例租约剔除显然是不合理的,自我保护机制提高了eureka的服务可用性。
当自我保护机制触发时,Eureka不再从注册列表中移除因为长时间没收到心跳而应该过期的服务,仍能查询服务信息并且接受新服务注册请求,也就是其他功能是正常的。这里思考下,如果eureka节点A触发自我保护机制过程中,有新服务注册了然后网络回复后,其他peer节点能收到A节点的新服务信息,数据同步到peer过程中是有网络异常重试的,也就是说,是能保证 最终一致性 的。
1.3. 服务发现
Eureka server可以集群部署,多个节点之间会进行 异步方式 数据同步,保证数据最终一致性,Eureka Server 作为一个开箱即用的服务注册中心,提供的功能包括:服务注册、接收服务心跳、服务剔除、服务下线等。需要注意的是,Eureka Server 同时也是一个 Eureka Client ,在不禁止 Eureka Server 的客户端行为时,它会向它配置文件中的其他 Eureka Server 进行拉取注册表、服务注册和发送心跳等操作。
Eureka server 端通过 appName 和 instanceInfoId 来唯一区分一个服务实例,服务信息存储如开篇所讲!
1.4. 服务注册
Service Provider 启动时会将服务信息 InstanceInfo 发送给 Eureka server,在接收到之后会写入 registry 中,服务注册默认过期时间 DEFAULT_DURATION_IN_SECS = 90秒 。InstanceInfo写入到本地registry之后,然后同步给其他peer节点,对应方法
com.netflix.eureka.registry.PeerAwareInstanceRegistryImpl.replicateToPeers()
1.4.1. 写入本地 registry
服务信息 InstanceInfo 保存在Lease中,写入本地registry对应方法:
com.netflix.eureka.registry.PeerAwareInstanceRegistryImpl.register()
Lease 统一保存在内存的 ConcurrentHashMap 中,在服务注册过程中,首先加个读锁,然后从 registry 中判断该 Lease 是否已存在,如果已存在则比较lastDirtyTimestamp 时间戳,取二者最大的服务信息,避免发生数据覆盖。
通过读锁并且 registry 的读取和写入不是原子的,该方法并发时,针对 InstanceInfo Lease 的构造,二者的信息是基本一致的,因为registrationTimestamp 取的就是当前时间。
1.4.2. 同步peer
InstanceInfo写入到本地registry之后,然后同步给其他peer节点,对应方法:
com.netflix.eureka.registry.PeerAwareInstanceRegistryImpl.replicateToPeers()
如果当前节点接收到的InstanceInfo本身就是另一个节点同步来的,则不会继续同步给其他节点,避免形成“广播效应”;InstanceInfo同步时会排除当前节点。
InstanceInfo的状态有依以下几种: Heartbeat Register Cancel StatusUpdate DeleteStatusOverride 。默认情况下同步操作时批量异步执行的,请求首先缓存到Map中,key为 requestType + appName + id ,然后由发送线程将请求发送到 peer 节点。
Peer 之间的状态是采用异步的方式同步的,所以不保证节点间的状态一定是一致的,不过基本能保证最终状态是一致的。结合服务发现的场景,实际上也并不需要节点间的状态强一致。在一段时间内(比如30秒),节点A比节点B多一个服务实例或少一个服务实例,在业务上也是完全可以接受的 Service Consumer侧一般也会实现错误重试和负载均衡机制 。所以按照 CAP 理论,Eureka的选择就是放弃 C ,选择 AP 。如果同步过程中,出现了异常怎么办呢,这时会根据异常信息做对应的处理,如果是读取超时或者网络连接异常,则稍后重试;如果其他异常则打印错误日志不再后续处理。
1.4.3. 服务续约
Renew(服务续约)操作由 Service Provider 定期调用,类似于 heartbeat 。主要是用来告诉 Eureka Server Service Provider 还活着,避免服务被剔除掉。renew 接口实现方式和 register 基本一致:首先更新自身状态,再同步到其它 Peer ,服务续约也就是把过期时间设置为当前时间加上 duration 的值。服务注册如果 InstanceInfo 不存在则加入,存在则更新;而服务预约只是进行更新,如果 InstanceInfo 不存在直接返回 false。
1.4.4. 服务下线
Cancel(服务下线)一般在 Service Provider shutdown 的时候调用,用来把自身的服务从 Eureka Server 中删除,以防客户端调用不存在的服务,eureka从本地”删除“(设置为删除状态)之后会同步给其他peer,对应方法
com.netflix.eureka.registry.PeerAwareInstanceRegistryImpl.cancel()。
1.4.5. 服务失效剔除
Eureka Server 中有一个 EvictionTask,用于检查服务是否失效。Eviction(失效服务剔除)用来定期(默认为每60秒)在 Eureka Server 检测失效的服务,检测标准就是超过一定时间没有 Renew 的服务。默认失效时间为90秒,也就是如果有服务超过90秒没有向 Eureka Server 发起 Renew 请求的话,就会被当做失效服务剔除掉。失效时间可以通过 eureka.instance.leaseExpirationDurationInSeconds 进行配置,定期扫描时间可以通过 eureka.server.evictionIntervalTimerInMs 进行配置。
服务剔除 #evict 方法中有很多限制,都是为了保证 Eureka Server 的可用性:比如自我保护时期不能进行服务剔除操作、过期操作是分批进行、服务剔除是随机逐个剔除,剔除均匀分布在所有应用中,防止在同一时间内同一服务集群中的服务全部过期被剔除,以致大量剔除发生时,在未进行自我保护前促使了程序的崩溃。
1.5. Server / Client 流程
1.5.1. 服务信息拉取
Eureka consumer 服务信息的拉取分为全量式拉取和增量式拉取,eureka consumer 启动时进行全量拉取,运行过程中由定时任务进行增量式拉取,如果网络出现异常,可能导致先拉取的数据被旧数据覆盖(比如上一次拉取线程获取结果较慢,数据已更新情况下使用返回结果再次更新,导致数据版本落后),产生脏数据。对此,eureka 通过类型 AtomicLong 的 fetchRegistryGeneration 对数据版本进行跟踪,版本不一致则表示此次拉取到的数据已过期。
fetchRegistryGeneration 过程是在拉取数据之前,执行 fetchRegistryGeneration.get() 获取当前版本号,获取到数据之后,通过fetchRegistryGeneration.compareAndSet() 来判断当前版本号是否已更新。
注:如果增量式更新出现意外,会再次进行一次全量拉取更新。
1.5.2. Server 伸/缩容
Eureka Server在启动后会调用 EurekaClientConfig.getEurekaServerServiceUrls() 来获取所有的 Peer 节点,并且会定期更新。定期更新频率可以通过 eureka.server.peerEurekaNodesUpdateIntervalMs 配置。这个方法的默认实现是从配置文件读取,所以如果 Eureka Server 节点相对固定的话,可以通过在配置文件中配置来实现。如果希望能更灵活的控制 Eureka Server 节点,比如动态扩容/缩容,那么可以 override getEurekaServerServiceUrls() 方法,提供自己的实现,比如我们的项目中会通过数据库读取 Eureka Server 列表。Eureka server 启动时把自己当做是 Service Consumer 从其它 Peer Eureka 获取所有服务的注册信息。然后对每个服务信息,在自己这里执行 Register ,isReplication=true,从而完成初始化。
1.5.3. Provider
Service Provider 启动时首先时注册到 Eureka Service 上,除了在启动时之外,只要实例状态信息有变化,也会注册到 Eureka Service 。需要注意的是,需要确保配置 eureka.client.registerWithEureka=true 。register 逻辑在方法 AbstractJerseyEurekaHttpClient.register() 中,Service Provider 会依次注册到配置的 Eureka Server Url 上,如果注册出现异常,则会继续注册其他的 url。
Renew 操作会在 Service Provider 端定期发起,用来通知 Eureka Server 自己还活着。 这里 instance.leaseRenewalIntervalInSeconds 属性表示 Renew 频率。默认是30秒,也就是每30秒会向Eureka Server发起Renew操作。这部分逻辑在HeartbeatThread类中。在 Service Provider 服务 shutdown 的时候,需要及时通知Eureka Server把自己剔除,从而避免客户端调用已经下线的服务,逻辑本身比较简单,通过对方法标记 @PreDestroy,从而在服务 shutdown 的时候会被触发。
1.5.4. Consumer
Service Consumer这块的实现相对就简单一些,因为它只涉及到从Eureka Server获取服务列表和更新服务列表。Service Consumer在启动时会从 Eureka Server 获取所有服务列表,并在本地缓存。需要注意的是,需要确保配置 eureka.client.shouldFetchRegistry=true 。由于在本地有一份 Service Registries 缓存,所以需要定期更新,定期更新频率可以通过 eureka.client.registryFetchIntervalSeconds 配置。
1.6. Eureka server故障转移
- 以8761和8762两个端口号启动EurekaServer。
- 启动ServiceA,配置注册中心地址为:http://localhost:8761/eureka,http://localhost:8762/eureka。
- 启动成功后,关闭8761端口的EurekaServer。
- 观察EurekaClient端发送心跳请求的方法:AbstractJerseyEurekaHttpClient.sendHeartBeat()。
- 查看该处数据,第一次请求的EurekaServer是8761端口的服务,因为该服务已经关闭,所以返回的response是null。
- 第二次会重新请求8762端口的服务,返回的response为状态为200,故障转移成功。
EurekaClient 端的 IP 作为随机的种子,然后随机打乱 serverLis ,每次请求 serverList 中的第一个服务,从而达到负载的目的。通过 EurekaClient 端的ipv4做为随机的种子,生成一个重新排序的 serverList ,也就是对应代码中的 randomList,所以每个 EurekaClient 获取到的 serverList 顺序可能不同,在使用过程中,取列表的第一个元素作为 server 端 host ,从而达到负载的目的。(负载的情况并不是很均匀)
2. Ribbon
2.1. IRule & IPing
负载均衡默认Server选择逻辑
Server选择:Ribbon 初始化过程中,默认的 IRule 为 ZoneAvoidanceRule(依次轮询)。Ribbon实际执行http请求逻辑
RibbonLoadBalancerClient.execute() 中request.apply()会做一个serverName的替换逻辑。最后到RibbonLoadBalancerClient.reconstructURI(),这个方法是把请求自带的getURI方法给替换了,我们最后查看context.reconstructURIWithServer() 方法,这里面会拼接对应的请求URL。Ribbon中ping机制原理
默认的IPing实现类为:NIWSDiscoveryPing。获取DiscoveryEnabledServer对应的注册信息是否为UP状态,查看isAlive()调用即可以找到调度的地方,在BaseLoadBalancer构造函数中调用setupPingTask()方法进行调度。pingIntervalSeconds在BaseLoadBalancer中定义的是10s,但是在initWithConfig()方法中。。Ribbon中其他IRule负载算法初探 RoundRobinRule 系统内置的默认负载均衡规范,直接round robin轮询,从一堆serverList中,不断的轮询选择出来一个server,每个server平摊到的这个请求,按照顺序轮询。AvailabilityFilteringRule 这个rule就是会考察服务器的可用性。如果3次连接失败,就会等待30秒后再次访问;如果不断失败,那么等待时间会不断变长,如果某个服务器的并发请求太高了,那么会绕过去,不再访问。这里先用Round Robin算法,轮询依次选择一台server,如果判断这个server是存活的可用的,如果这台server是不可以访问的,那么就用round robin算法再次选择下一台server,依次循环往复,10次。WeightedResponseTimeRule 带着权重的,每个服务器可以有权重,权重越高优先访问,如果某个服务器响应时间比较长,那么权重就会降低,减少访问。ZoneAvoidanceRule 根据机房和服务器来进行负载均衡,spring cloud ribbon环境中的默认的Rule。BestAvailableRule 忽略那些请求失败的服务器,然后尽量找并发比较低的服务器来请求 。
Ribbon注册表拉取及更新逻辑这里也梳理下,这里如果Ribbon保存的注册表信息有宕机的情况,这里最多4分钟才能感知到,所以spring cloud出现服务熔断。
3. Hystrix
隔离 将请求封装在HystrixCommand中,然后这些请求在一个独立的线程中执行,每个依赖服务维护一个小的线程池(信号量),在调用失败或超时的情况下可以断开依赖调用或者返回指定逻辑。熔断 当HystrixCommand请求后端服务失败数量超过一定比例(默认50%), 断路器会切换到开路状态(Open). 这时所有请求会直接失败而不会发送到后端服务,断路器保持在开路状态一段时间后(默认5秒),自动切换到半开路状态(HALF-OPEN),这时会判断下一次请求的返回情况, 如果请求成功, 断路器切回闭路状态(CLOSED),否则重新切换到开路状态(OPEN)。降级 服务降级是指当请求后端服务出现异常的时候, 可以使用fallback方法返回的值 。
3.1. 容错模式
主动超时 Http请求主动设置一个超时时间,超时就直接返回,不会造成服务堆积。限流 限制最大并发数。熔断 当错误数超过阈值时快速失败,不调用后端服务,同时隔一定时间放几个请求去重试后端服务是否能正常调用,如果成功则关闭熔断状态,失败则继续快速失败,直接返回。(此处有个重试,重试就是弹性恢复的能力)。隔离 把每个依赖或调用的服务都隔离开来,防止级联失败引起整体服务不可用。降级 服务失败或异常后,返回指定的默认信息。
3.2. 容错流程
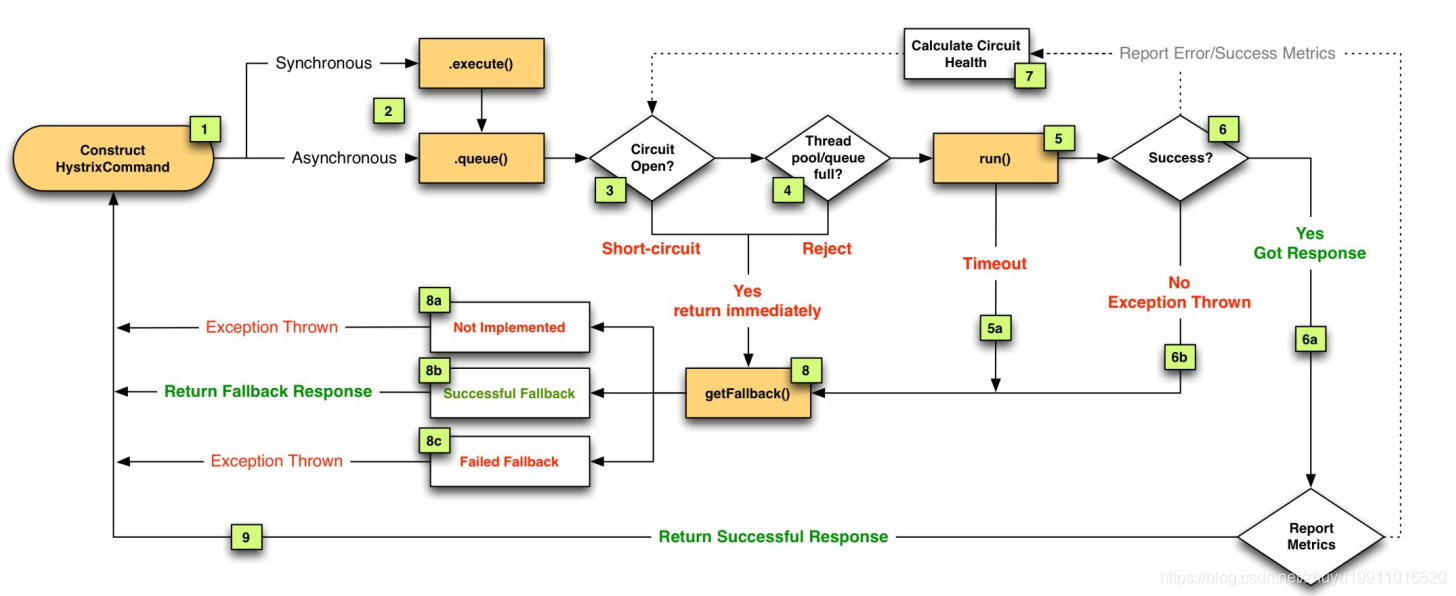
- 每个请求都会封装到 HystrixCommand 中。
- 请求会以同步或异步的方式进行调用。
- 判断熔断器是否打开,如果打开,它会直接跳转到 8 ,进行降级。
- 判断线程池/队列/信号量是否跑满,如果跑满进入降级步骤8。
- 如果前面没有错误,就调用 run 方法,运行依赖逻辑。
- 运行方法可能会超时,超时后从 5a 到 8,进行降级。
- Success
- 运行正常会进入 6a,正常返回回去,同时把错误或正常调用结果告诉 7 (Calculate Circuit Health)。
- 运行过程中如果发生异常,6b. 会从6b到8,进行降级。
- Calculate Circuit Health它是 Hystrix 的大脑,是否进行熔断是它通过错误和成功调用次数计算出来的。
降级方法(8a没有实现降级、8b实现降级且成功运行、8c实现降级方法,但是出现异常)。
依赖都可能会失败。
- 资源都有限制(CPU、内存、线程池)。
- 网络并不靠谱。
- 延迟是应用稳定性最大杀手。
4. Feign
Feign是一个http请求调用的轻量级框架,可以以Java接口注解的方式调用Http请求。Spring Cloud引入 Feign并且集成了Ribbon实现客户端负载均衡调用。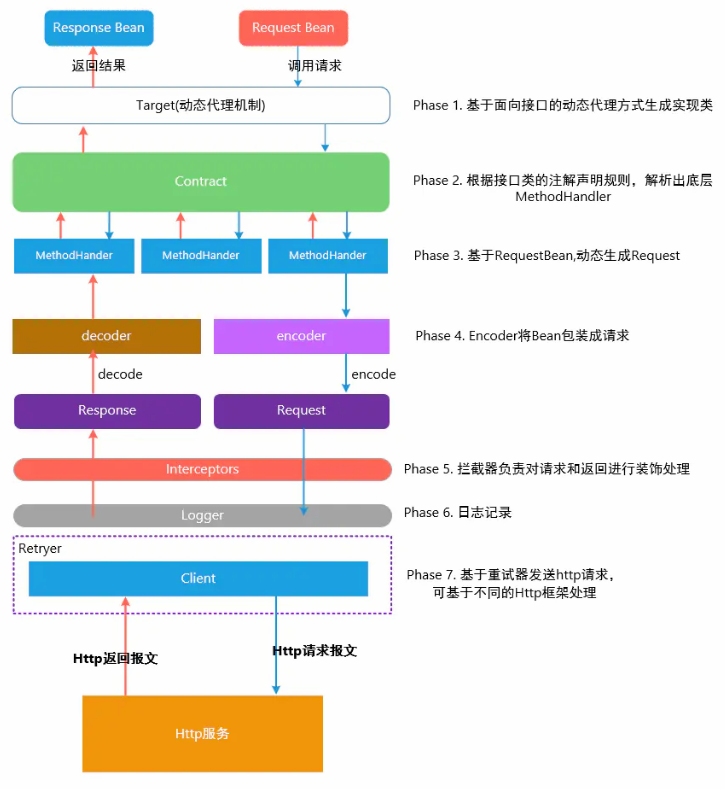
**接口的动态代理**在Feign 底层,通过基于面向接口的动态代理方式生成实现类,将请求调用委托到动态代理实现类。**Contract协议解析**。**动态生成Request**基于 RequestBean,根据传入的Bean对象和注解信息,从中提取出相应的值,来构造Http Request 对象。**Encoder/Decoder**消息解析和转码逻辑。**拦截器**负责对请求和返回进行装饰处理,在请求转换的过程中,Feign 抽象出来了拦截器接口,用于用户自定义对请求的操作,比如,如果希望Http消息传递过程中被压缩,可以定义一个请求拦截器。**日志记录****补偿机制**Feign 内置了一个重试器,当HTTP请求出现IO异常时,Feign会有一个最大尝试次数发送请求。
Feign 真正发送HTTP请求是委托给 feign.Client 来做的。Feign 默认底层通过JDK 的 java.net.HttpURLConnection 实现了feign.Client接口类,在每次发送请求的时候,都会创建新的 HttpURLConnection 链接,这也就是为什么默认情况下Feign的性能很差的原因。可以通过拓展该接口,使用 Apache HttpClient 或者 OkHttp3 等基于连接池的高性能Http客户端。真正影响性能的,是处理Http请求的环节。4.1. GZIP压缩
Gzip 是一种数据格式,采用 deflate 算法压缩数据,当 Gzip 压缩到一个纯文本数据时,可以减少70%以上的数据大小。网络数据经过压缩后实际上降低了网络传输的字节数,最明显的好处就是可以加快网页加载的速度。只配置Feign请求-应答的Gzip压缩。# feign gzip# 局部配置。只配置feign技术相关的http请求-应答中的gzip压缩。# 配置的是application client和application service之间通讯是否使用gzip做数据压缩。# 和浏览器到application client之间的通讯无关。# 开启feign请求时的压缩, application client -> application servicefeign.compression.request.enabled=true# 开启feign技术响应时的压缩, application service -> application clientfeign.compression.response.enabled=true# 设置可以压缩的请求/响应的类型。feign.compression.request.mime-types=text/xml,application/xml,application/json# 当请求的数据容量达到多少的时候,使用压缩。默认是2048字节。feign.compression.request.min-request-size=512
4.2. 全局GZIP压缩
# spring boot gzip # 开启spring boot中的gzip压缩。就是针对和当前应用所有相关的http请求-应答的gzip压缩。 server.compression.enabled=true # 哪些客户端发出的请求不压缩,默认是不限制 server.compression.excluded-user-agents=gozilla,traviata # 配置想压缩的请求/应答数据类型,默认是 text/html,text/xml,text/plain server.compression.mime-types=application/json,application/xml,text/html,text/xml,text/plain # 执行压缩的阈值,默认为2048 server.compression.min-response-size=5124.3. 切换底层实现
开启feign技术对底层httpclient的依赖。feign.httpclient.enabled=true

若有收获,就点个赞吧
0 人点赞
