在 JavaScript 中,原始数据类型是存储在栈空间中的,引用类型的数据是存储在堆空间中的。
通常情况下,垃圾数据回收分为手动回收和自动回收。
C/C++/Objective-C 使用的就是手动回收策略,何时分配内存、何时销毁内存都是由代码控制的。
在 C 语言中,我们要使用堆中的一块空间,我们首先需要调用 malloc 函数分配内存,然后在使用,当不需要这块数据的时候,则需要手动调用 free 函数来销毁,如果没有主动调用 free 函数来销毁,这种情况就是内存泄漏。
使用自动垃圾回收策略的语言有:JavaScript、Java、Python 等语言,产生的垃圾数据是由垃圾回收器来释放的。
调用栈中的数据是如何回收的?
function foo() {var a = 1var b = { name:"111" }function showName(){var c = 2var d = { name:"222" }}showName()}foo()
:::info
JavaScript 会记录当前执行状态的指针(ESP)。当被调用函数执行完成后,JavaScript 会将 ESP 指针下移到下一个调用函数的执行上下文,已达到销毁被调用函数的执行上下文的目的。
:::
如果执行到 showName 函数时,那么 JavaScript 引擎会创建 showName 函数的执行上下文,并将 showName 函数的执行上下文压入到调用栈中。
与此同时,还有一个记录当前执行状态的指针(称为 ESP),指向调用栈中 showName 函数的执行上下文,表示当前正在执行 showName 函数。
当 showName 函数执行完成之后,函数执行流程就进入了 foo 函数,那这时就需要销毁 showName 函数的执行上下文了。
JavaScript 会将 ESP 下移到 foo 函数的执行上下文,这个下移操作就是销毁 showName 函数执行上下文的过程。
当一个函数执行结束之后,JavaScript 引擎会通过向下移动 ESP 来销毁该函数保存在栈中的执行上下文。
调用堆中的数据是如何回收的?
代际假说和分代收集
要弄懂堆中的数据是如何收集的,首先要弄清楚什么是代际假说,后续垃圾回收的策略都是在该假说基础之上的。
代际假说的特点(存活特点):
- 大部分对象在内存中存在的时间很短。即:很多对象一经分配内存,很快就变得不可访问;
- 不死的对象,会活得更久。
ps:这两个特点不仅适用于 JavaScript,同样适用于大多数的动态语言。
根据以上基础,我们聊一聊 V8 是如何实现垃圾回收的。
通常,垃圾回收算法有很多种,但是并没有哪一种能胜任所有的场景,你需要权衡各种场景,根据对象的生存周期的不同而使用不同的算法,以便达到最好的效果。
所以,在 V8 中会把堆分为新生代(Young Gen)和老生代(Tenure Gen)两个区域,新生代中存放的是生存时间短的对象,老生代中存放的生存时间久的对象。
对于这两块区域,V8 分别适用两个不同的垃圾回收器以便更高效的实施垃圾回收。
- 副垃圾回收器,主要负责新生代的垃圾回收。
- 主垃圾回收器,主要负责老生代的垃圾回收。
垃圾回收器的工作流程
无论是主垃圾回收器,还是副垃圾回收器,都是通过采用可访问性算法来判断堆中是否存在活动对象的。它们都有一套共同的执行流程。
具体流程如下:
- 通过 GC Root 标记空间中活动对象和非活动对象。
- 回收被标记的非活动对象所占据的内存。
- 内存整理。
通过上述流程访问活动对象与非活动对象的算法也叫可访问性算法(reachability)
具体地讲,这个算法是将一些 GC Root 作为初始存活的对象的集合,从 GC Roots 对象出发,遍历 GC Root 中的所有对象:
- 通过 GC Root 遍历到的对象,我们成为该对象是可访问的,这些对象应该在内存中保留,这部分对象也叫活动对象。(标记为黑色)
- 通过 GC Roots 没有遍历到的对象,则是不可访问的,这些对象应该被回收,该对象也叫非活动对象。(标记为白色)
一般来说,频繁回收对象后,内存中就会存在大量不连续空间,我们把这些不连续的内存空间称为内存碎片。当内存中出现了大量的内存碎片之后,如果需要分配较大连续内存的时候,就有可能出现内存不足的情况。所以最后一步需要整理这些内存碎片,但这步其实是可选的,因为有的垃圾回收器不会产生内存碎片,如副垃圾回收器。
副垃圾回收器(Minor GC)
副垃圾回收器主要负责新生代的垃圾回收。即大多数小的对象都会分配到新生区。
新生代采用的是 Scavenge 算法来进行垃圾回收。
所谓 Scavenge 算法,是把新生代空间对半划分为两个区域,一半是对象区域(From Space),一半是空闲区域(To Space)。 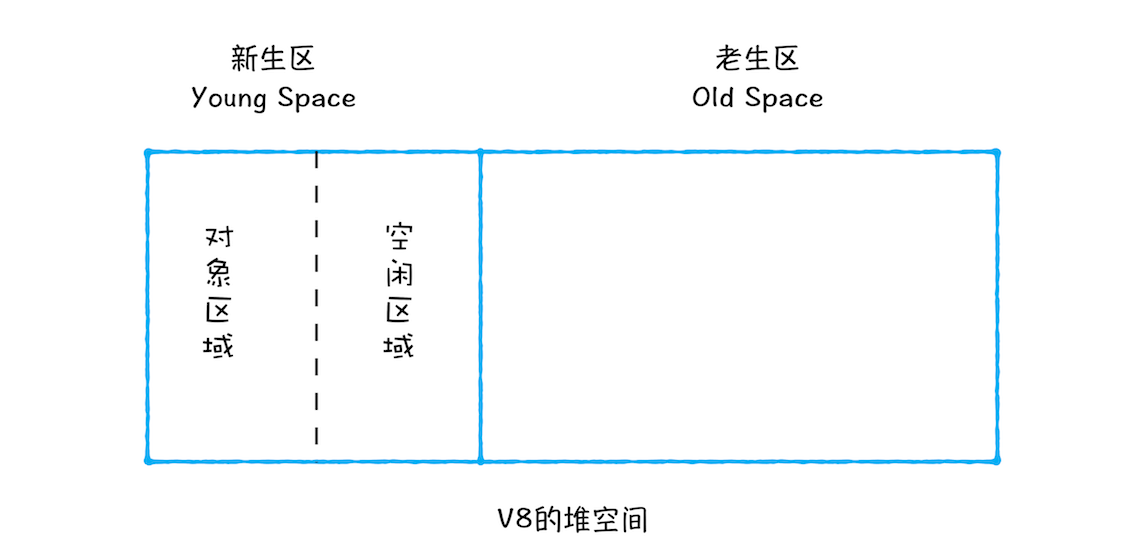
划分好分区后,具体操作如下:
- 新加入的对象都会存放到对象区域,当对象区域快被写满时,就需要执行一次垃圾清理操作。
- 在垃圾回收过程中,首先要对对象区域中的垃圾做标记;
- 标记完成之后,就进入垃圾清理阶段,副垃圾回收器会把这些存活的对象复制到空闲区域中,同时它还会把这些对象有序地排列起来
- 这个复制过程,也就相当于完成了内存整理操作,复制后空闲区域就没有内存碎片了。
- 完成复制后,会对两个区域的角色进行翻转,即新的空闲区就变成了对象区。
- 因为复制操作需要时间成本,如果新生代设置的很大的话,那么垃圾回收时间就很长,所以新生区一般设置的比较小,通常只有 1~8M的容量。
- 因为新生区很容易被小对象填满,所以 JavaScript 引擎采用了对象晋升策略,如果两次清理还存在存活的对象,则该对象会被移动到老生区中。
主垃圾回收器(Major GC / Full GC)
主垃圾回收器主要负责老生区的垃圾回收。
除了新生区晋升的对象,一些大对象也会直接被分配到老生区中。
所以老生区有以下两个特点:
- 对象占用空间大
- 对象存活时间比较长
根据 Scavenge 算法的工作流程,很明显不适合对老生区的对象进行回收,因为老生区的对象太大了,回收一次效率太低,并且耗时很久,所以老生区主要采用其他的策略进行垃圾回收。
主垃圾回收器主要是采用标记-清除算法(Mark-Sweep)进行垃圾回收的。
标记清除算法的主要工作流程如下:
首先是标记过程阶段。标记阶段就是从一组根元素开始,递归遍历这组根元素,在这个遍历过程中,能到达的元素称为活动对象,没有到达的元素就可以判断为垃圾数据。
接下来就是垃圾的清除过程。它和副垃圾回收器的垃圾清除过程完全不同,你可以理解这个过程是清除掉红色标记数据的过程(即垃圾数据,非活动数据)
不过标记清除算法有一个缺点,就是频繁对一块内存多次执行标记清除算法时,会产生大量不连续的内存碎片,碎片太多会导致大对象无法分配到足够的内存中,所以又产生了一种算法,即标记-整理(Mark-Compact)
标记整理算法的标记过程和标记清楚算法基本是一致的,但后续不是直接对可回收对象进行整理,而是让所有存活对象向一端移动,然后直接清理掉端边界以外的内存。
全停顿(STW:Stop-The-World)
因为 JavaScript 脚本是运行在主线程之上的,一旦执行垃圾回收算法,正在主线程上执行的 JavaScript 脚本会全部暂停下来,等垃圾回收完毕后在恢复脚本执行,这种行为就叫全停顿。
一次完整的垃圾回收分为标记和清理两个阶段,垃圾数据标记之后,V8 会继续执行清理和整理操作,虽然主垃圾回收器和副垃圾回收器的处理方式稍微有些不同,但它们都是主线程上执行的,执行垃圾回收过程中,会暂停主线程上的其他任务。 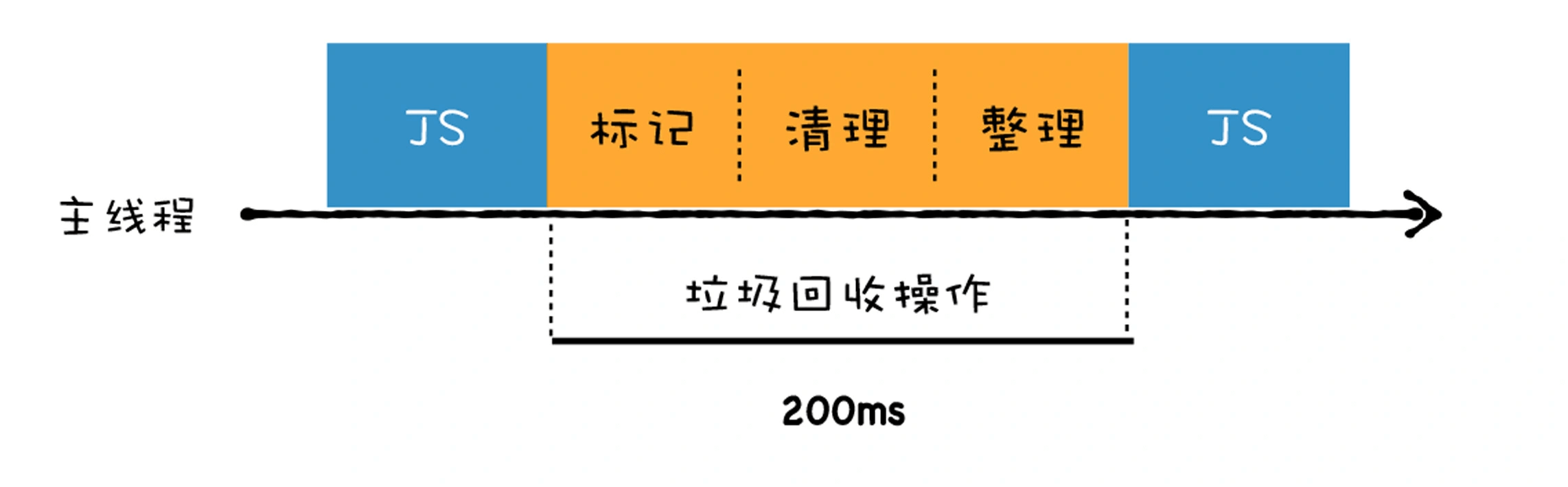
为了降低老生代的垃圾回收而造成的卡顿,V8 将标记过程分为一个个的子标记过程,同时让垃圾回收标记和 JavaScript 应用逻辑交替进行,直到标记阶段完成,我们把这个算法称为增量标记(incremental mark compactor)算法。
V8 团队经过这些年的努力,也向现有的垃圾回收器添加了并行、并发、增量等垃圾回收技术。
这些技术主要是从一下两方面解决垃圾回收效率问题的:
- 将一个完整的垃圾回收的任务拆分成多个小的任务,这样就消灭了单个长的垃圾回收任务
- 将标记对象、移动对象等任务转移到后台线程进行,这会大大减少主线程暂停的时间,改善页面卡顿的问题,让动画、滚动和用户交互更加流畅。
使用增量回标记算法,可以把一个完整的垃圾回收拆分为很多小的任务,这些小的任务执行时间比较短,可以穿插在其他的 JavaScript 任务中间执行,这样就会减轻一些卡顿的效果。
那么 V8 具体是如何向现有的垃圾回收器添加并行(parallel)、并发(concurrent)、增量(incremental)技术,来提升回收执行效率的呢?
并行回收
既然执行一次完整的垃圾回收过程比较耗时,那么解决效率问题,第一个思路就是主线程在执行垃圾回收的任务时,引入多个辅助线程来并行处理。
所谓并行回收,也就是指垃圾回收器在主线程上执行的过程中,开启多个协助线程,同时执行同样的回收工作,其工作模式如下图所示: 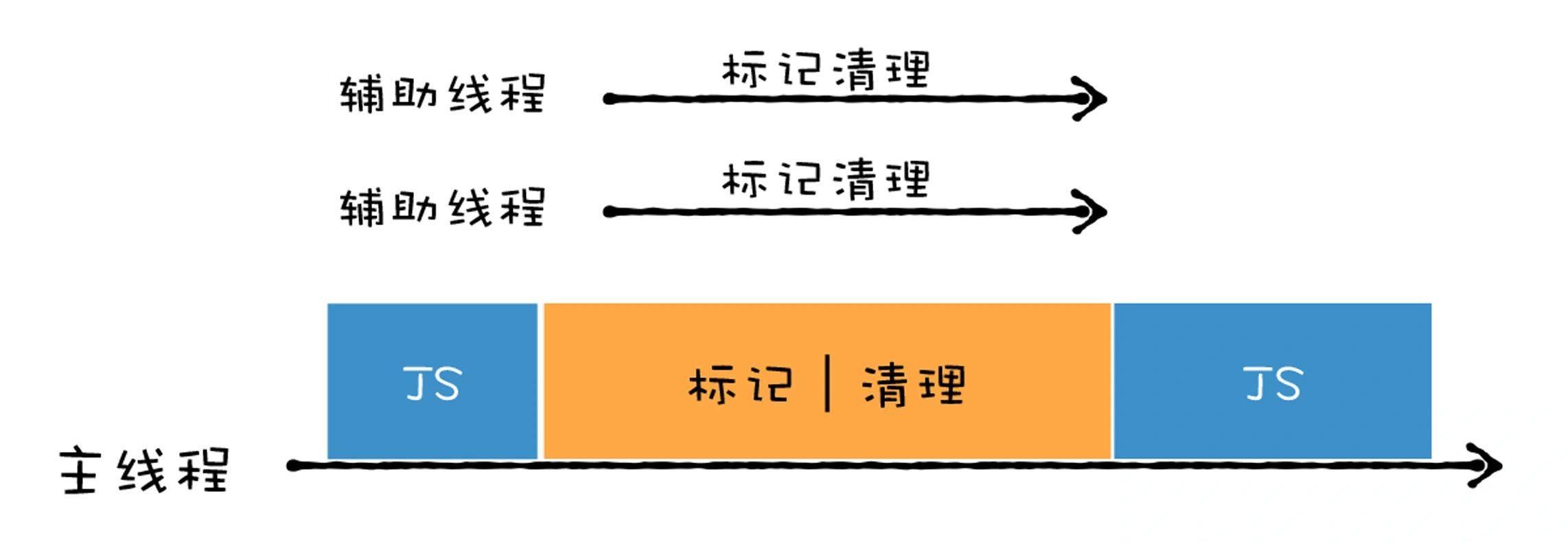
V8 的副垃圾回收器就是采用这样的策略,在 Scavenge 算法的基础上,开启多个辅助线程来进行垃圾回收,即 Parallel Scavenge 算法。由于数据的地址发生了改变,所以还需要同步更新引用这些对象的指针。
增量回收
虽然并行回收策略增加了垃圾回收的效率,但还是一种全停顿的垃圾回收方式,仍然会存在效率问题。比如在老生代上存放一些大对象,如DOM、Window这种,完整的执行老生代的垃圾回收时间仍然会很久。所以 2011 年,v8 在 mark compactor 算法(标记整理)的基础上,又引入了增量标记整理的方式。
所谓增量式垃圾回收,是指垃圾收集器将标记工作分解为更小的块,并且穿插在主线程不同的任务之间执行。采用增量垃圾回收时,垃圾回收器没有必要一次执行完整的垃圾回收过程,每次执行的只是整个垃圾回收过程中的一小部分工作,具体流程你可以参看下图: 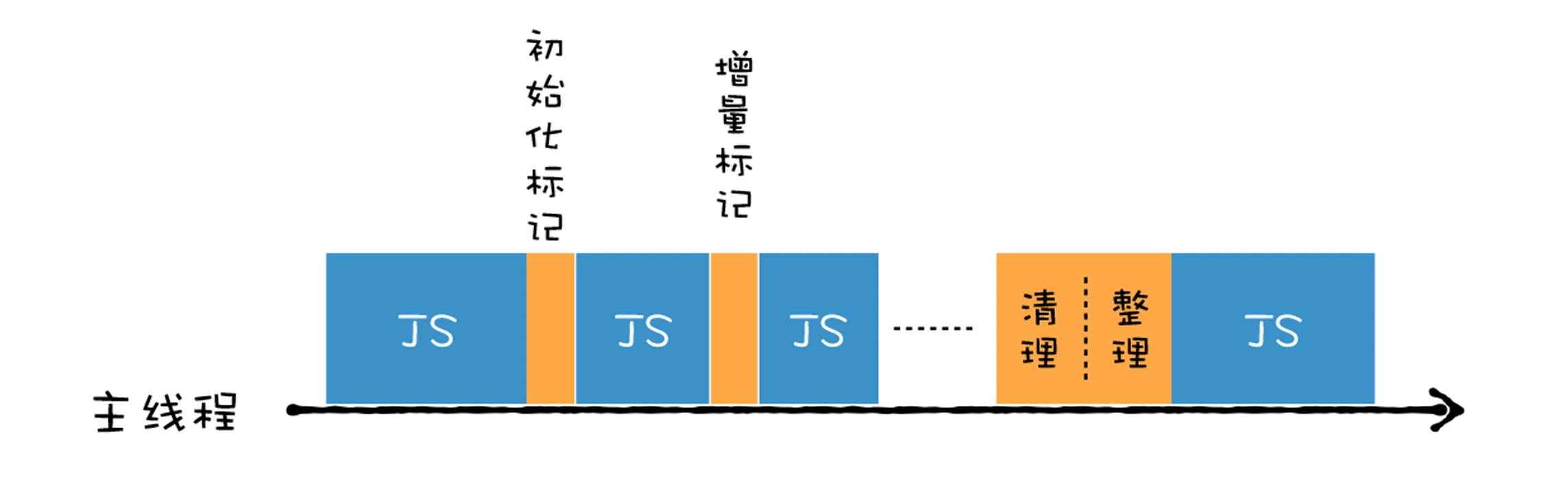
增量回收本质是并发的,要想实现增量执行,需要满足以下两点要求:
- 垃圾回收可以被随时暂停和重启,暂停时需要保存当时的扫描结果,等下一波垃圾回收来了之后,才能继续启动。
- 在暂停期间,被标记好的垃圾数据如果被 JavaScript 代码修改了,那么垃圾回收器需要能够正确地处理。
GC 循环的状态图如下: 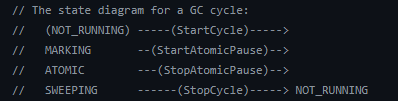
在没有采用增量算法之前,v8 使用黑色和白色来标记数据。
在执行一次完整的垃圾回收之前,v8 会将所有的对象都标记为白色。然后通过 GC Roots 触发,将所有能访问到的对象都标记为黑色,那么未标记的白色对象就是垃圾对象了。
因为增量算法需要满足垃圾回收可以被随时暂停可重启,如果暂停了垃圾回收器,再次重启后,此时的垃圾回收器就无法知道从哪里开始执行了。
为了解决这个问题,增量回收引用了三色标记法。即:
- 黑色节点表示节点被 GC Root 引用到了,并且该节点的子节点已经被标记完成
- 灰色节点表示节点被 GC Root 引用到了,但子节点没有被标记完成,也就是重启垃圾回收器前处理中的节点
- 白色节点表示未被 GC Root 引用到的节点。
仅仅采用三色标记法,就能完美的支持增量回收吗?
window.a = Object() window.a.b = Object() window.a.b.c=Object()
按照上面的代码,当执行到该代码时,垃圾回收器的标记结果会如下图所示: 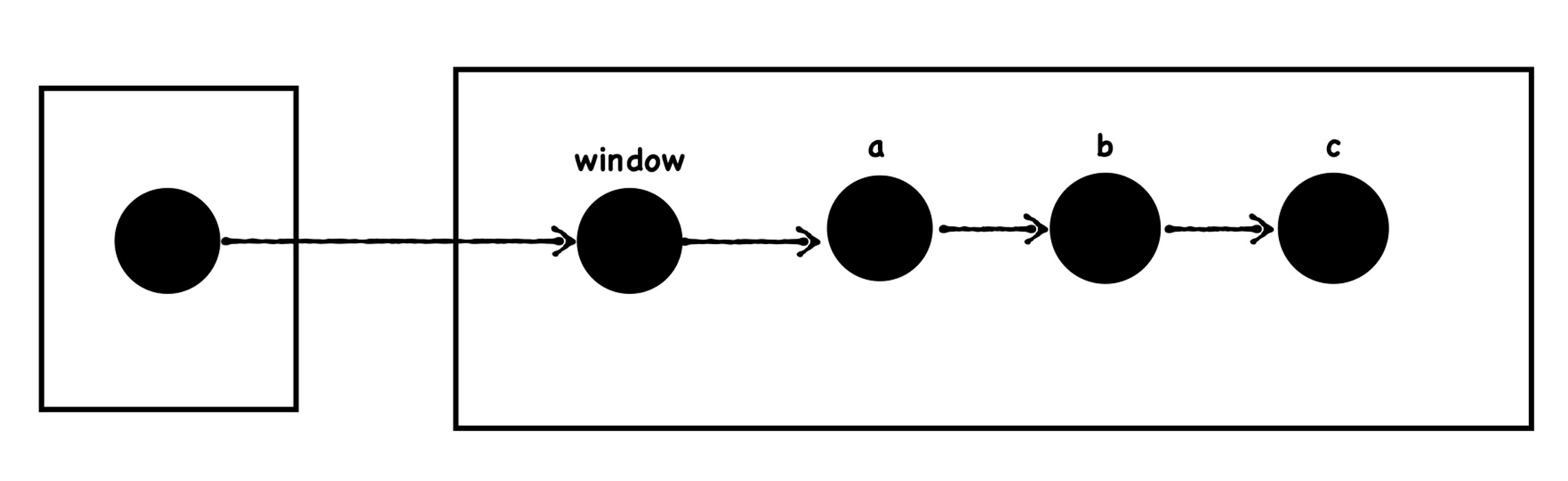
如果此时又执行了下面的代码:
window.a.b = Object() //d
执行完之后,垃圾回收器又恢复执行了增量标记过程,由于 b 重新指向了 d 对象,所以 b 和 c 对象的连接就断开了。这时候代码的应用如下图所示: 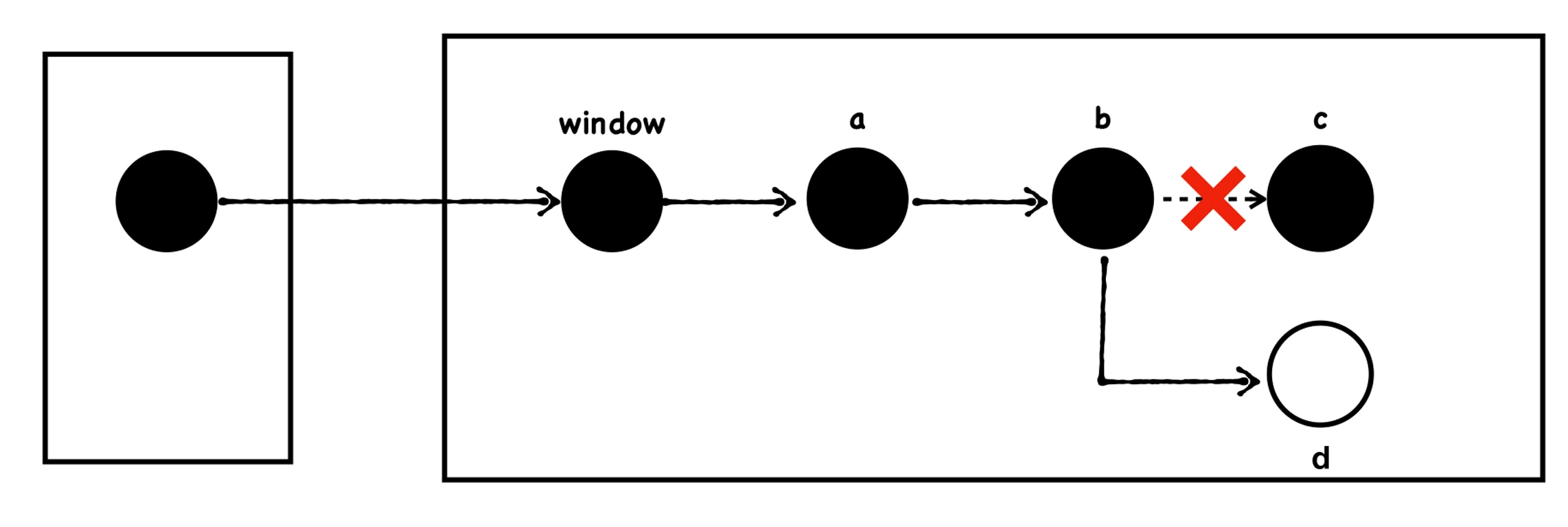
问题就来了,如果垃圾回收器将某个节点标记成了黑色,但是这个黑色的节点又被续上了一个白色的节点 d,那么垃圾回收器就不会再次将这个白色节点标记成黑色节点了,因为 GC Root 已经走过这个路径了。
为了解决这个问题,增量垃圾回收又增加了一个约束,即写屏障(Write-Barrier)机制。
写屏障机制的作用就是将上述的白色节点 d 强制变成灰色的,这种方法也被称为强三色不变性。
并发回收
虽然三色标记法和写屏障机制能够很好的实现增量回收,但由于这些操作都是在主线程上执行的,如果主线程繁忙的时候,还是会出现全停顿,增量回收依然会增加主线程处理任务的吞吐量。
为了解决这一问题,所以引入了并发回收的策略。
所谓并发回收,是指主线程在执行 JavaScript 的过程中,辅助线程能够在后台完成执行垃圾回收的操作。 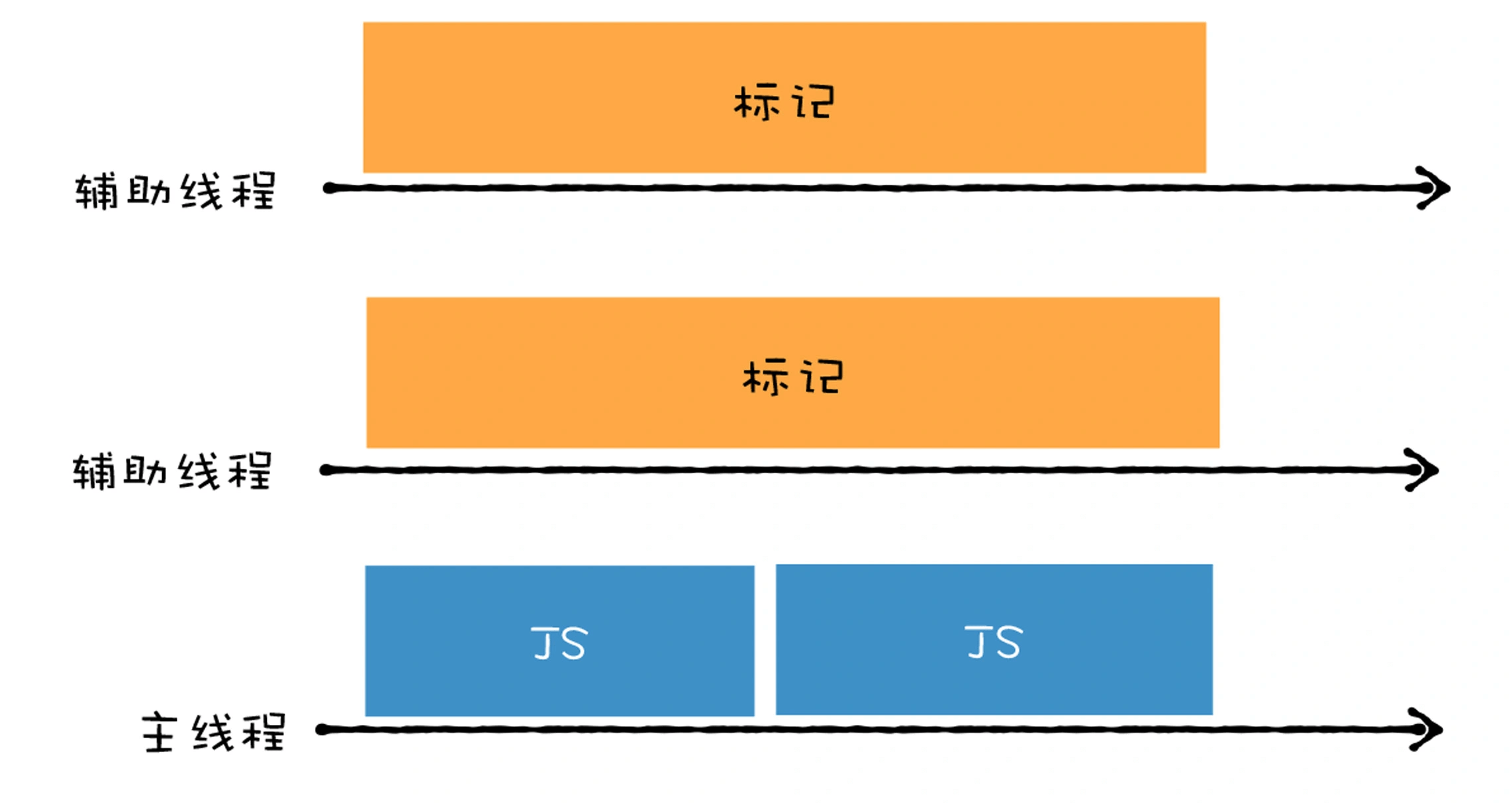
并发回收的优势非常明显,主线程不会被挂起,JavaScript 可以自由地执行 ,在执行的同时,辅助线程可以执行垃圾回收操作。
在实际使用中,并行回收,增量回收,并发回收技术通常是一起使用。具体工作如下图: 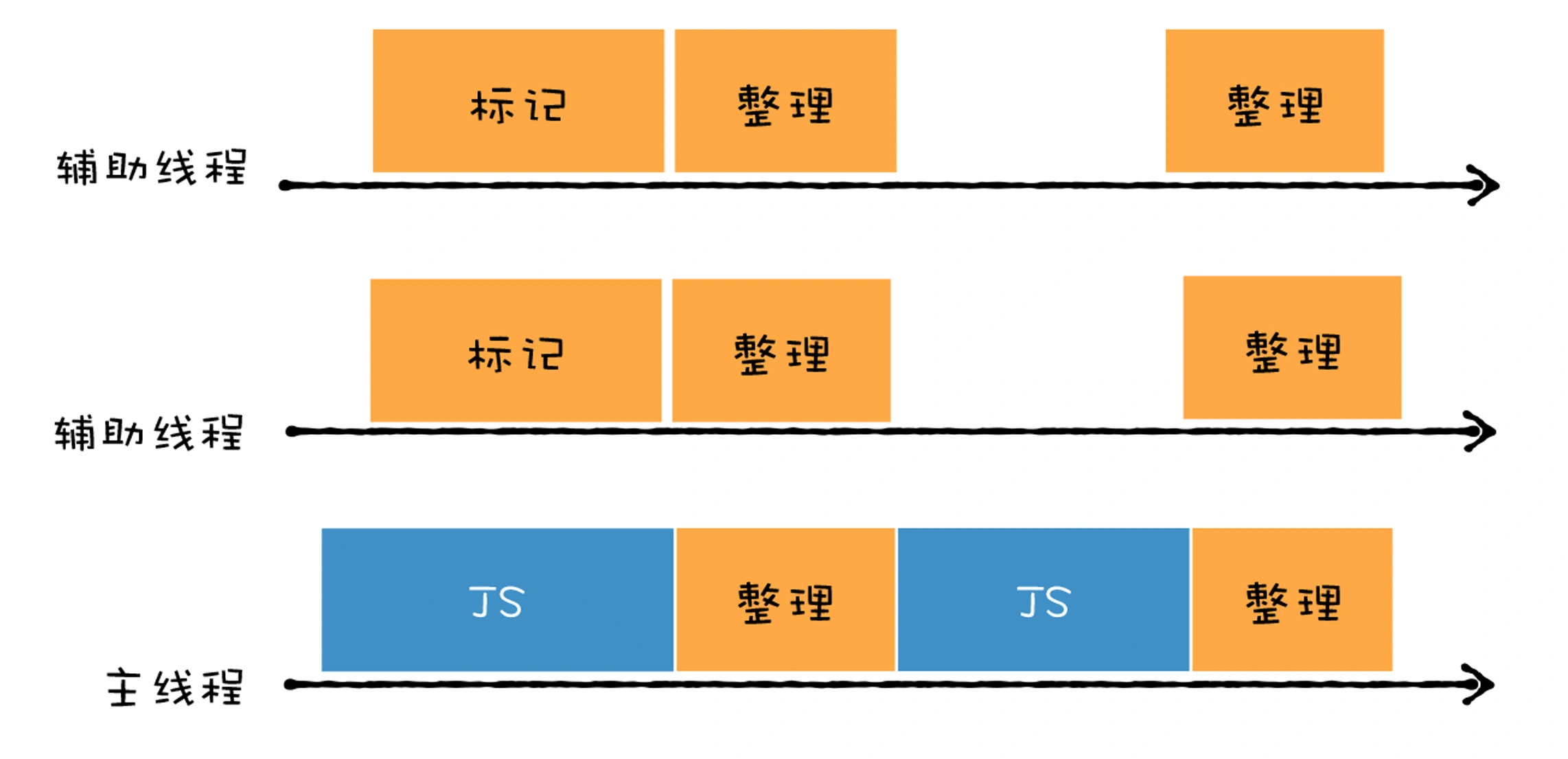
具体流程如下:
- 主垃圾回收器主要使用并发标记,在主线程执行 JavaScript,辅助线程就开始执行标记操作了,所以说标记是在辅助线程中完成的。
- 标记完成之后,再执行并行清理操作。主线程在执行清理操作时,多个辅助线程也在执行清理操作。
另外,主垃圾回收器还采用了增量标记的方式,清理的任务会穿插在各种 JavaScript 任务之间执行。
Minor Mark-Compact
其实在我们阅读 v8 垃圾回收的源码会发现,除了 Scavenge 算法,Mark-Compactor(标记整理)Incremental-Mark-Compactor (增量标记整理)算法外,还有一种 Minor-Mark-Compactor 算法。由于笔者能力有限,并未发现该算法的调用时机及作用,所以本文不做赘述。
https://github.com/v8/v8/blob/main/src/heap/gc-tracer.cc ```javascript void GCTracer::StartCycle(GarbageCollector collector,GarbageCollectionReason gc_reason,const char* collector_reason, MarkingType marking) {
// We cannot start a new cycle while there’s another one in its atomic pause. DCHECKNE(Event::State::ATOMIC, current.state); // We cannot start a new cycle while a young generation GC cycle has // already interrupted a full GC cycle. DCHECK(!younggc_while_full_gc);
younggc_while_full_gc = current_.state != Event::State::NOT_RUNNING;
DCHECKIMPLIES(young_gc_while_full_gc,
Heap::IsYoungGenerationCollector(collector) &&!Event::IsYoungGenerationEvent(current_.type));
Event::Type type; switch (collector) { case GarbageCollector::SCAVENGER:
type = Event::SCAVENGER;break;
case GarbageCollector::MINOR_MARK_COMPACTOR:
type = Event::MINOR_MARK_COMPACTOR;break;
case GarbageCollector::MARK_COMPACTOR:
type = marking == MarkingType::kIncremental? Event::INCREMENTAL_MARK_COMPACTOR: Event::MARK_COMPACTOR;break;
}
DCHECKIMPLIES(!young_gc_while_full_gc,
current_.state == Event::State::NOT_RUNNING);
DCHECKEQ(Event::State::NOT_RUNNING, previous.state);
previous = current; current_ = Event(type, Event::State::MARKING, gc_reason, collector_reason);
switch (marking) { case MarkingType::kAtomic:
DCHECK(IsInObservablePause());// TODO(chromium:1154636): The start_time of the current event contains// currently the start time of the observable pause. This should be// reconsidered.current_.start_time = start_of_observable_pause_;current_.reduce_memory = heap_->ShouldReduceMemory();break;
case MarkingType::kIncremental:
// The current event will be updated later.DCHECK(!Heap::IsYoungGenerationCollector(collector));DCHECK(!IsInObservablePause());break;
}
if (Heap::IsYoungGenerationCollector(collector)) { epochyoung = nextepoch(); } else { epoch_full = next_epoch(); } }
参考链接
JVM GC 四大算法:
- 复制算法(Copying / Scavenge)新生代(Eden区、Survivor 区,From Space(对象区)、To Space(空闲区))
- 标记清除(Mark-Sweep)老生代
- 标记整理(Mark-Compact)老生代
- 引用计数
如何判断 Java 对象是否存活?
- 引用计数法
- 根搜索法:GC Root 搜索通过的路径形成引用链(Reference Chain)
v8/gc-tracer.cc at main · v8/v8 (github.com)
13 | 垃圾回收:垃圾数据是如何自动回收的? (geekbang.org)
20 | 垃圾回收(一):V8的两个垃圾回收器是如何工作的? (geekbang.org)
21 | 垃圾回收(二):V8是如何优化垃圾回收器执行效率的? (geekbang.org)
Minor GC(Young GC)、Full GC、Major GC、Old GC - 大浪不惊涛 - 博客园 (cnblogs.com)
(117条消息) GC四大算法详解_AtlantisChina-CSDN博客_gc的四大算法

若有收获,就点个赞吧
0 人点赞
