2.1 挑战分析与系统目标
边缘计算概念的提出为云计算模型的系统性能受制于有限网络带宽提供了解决办法,在边缘结点处理这些数据可以缩短响应时间、减轻网络负载、保证用户数据的私密性。当公司或团体想使用边缘计算设备综合区域数据进行学习训练时,联邦学习成为这一场景下的优先选择。在典型的Client/Server模式下的联邦学习中,聚合服务器端将每个参与训练的客户端更新的模型或梯度向量进行聚合并下发更新客户端的模型,这样得到的聚合模型成为数据聚合后的最优模型。但在边缘计算场景下应用经典联邦学习仍存在诸多问题,下文将列举一些已被提出的安全问题。在下面的讨论中,边缘计算节点简化为参与训练的客户端,企业或团体租用的云服务器为聚合服务器。
(1) 梯度泄露攻击
文献[Deep leakage from gradients]提出了一种迭代方法,可以通过仅在同一神经网络上截取相应的梯度来完全重构训练集,而该训练集本来是本地的和私有的。该技术被称为“梯度深泄漏”(DLG),因为它对用户数据的隐私造成了“深度”威胁。
DLG是一种基于梯度的特征重构攻击。 攻击者在第t轮收到其他参与者k的梯度更新 ,目的是从共享信息中窃取参与者k的训练集
,目的是从共享信息中窃取参与者k的训练集 。图【】展示了它如何用于基于图像数据集的联邦学习:该算法首先初始化具有与真实分辨率相同分辨率的虚拟图像,并初始化具有概率表示并带有softmax层的虚拟标签。 DLG在中间局部模型上对这种攻击进行了测试,以计算“虚拟”梯度。 对于大多数联邦学习应用程序,默认情况下共享模型架构F()和权重
。图【】展示了它如何用于基于图像数据集的联邦学习:该算法首先初始化具有与真实分辨率相同分辨率的虚拟图像,并初始化具有概率表示并带有softmax层的虚拟标签。 DLG在中间局部模型上对这种攻击进行了测试,以计算“虚拟”梯度。 对于大多数联邦学习应用程序,默认情况下共享模型架构F()和权重 。 然后计算虚拟梯度与真实梯度之间的梯度距离损失作为优化目标。 重构攻击的关键是迭代地优化虚拟图像和标签,以使攻击者的虚拟渐变将逼近实际渐变。 当梯度构造损失最小时,虚拟数据也将以高置信度收敛到训练数据。
。 然后计算虚拟梯度与真实梯度之间的梯度距离损失作为优化目标。 重构攻击的关键是迭代地优化虚拟图像和标签,以使攻击者的虚拟渐变将逼近实际渐变。 当梯度构造损失最小时,虚拟数据也将以高置信度收敛到训练数据。
(2)用户共谋攻击
在边缘计算环境下,部署的边缘计算终端将会按照程序设定进行计算任务,但是,许多应用边缘计算的具体场景如工业物联网、智慧城市等,部分终端设备自身安全防护能力薄弱、漏洞问题严重,存在着窃听攻击、控制夺权攻击等问题,这样部分终端就从训练“参与者”变成了“攻击者”。因而我们假设每个客户端都是半诚实且好奇的,多个参与训练的客户端可能会因为恶意攻击变成“傀儡”客户端对整个联邦学习系统进行共谋攻击。在这种情况下,某一方参与训练的客户端的信息很可能被窃取。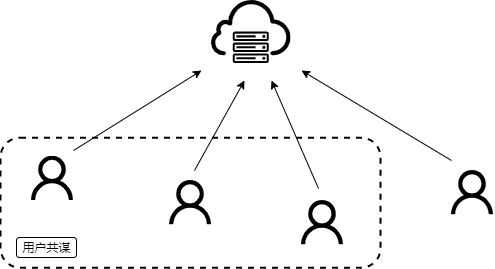
图需要
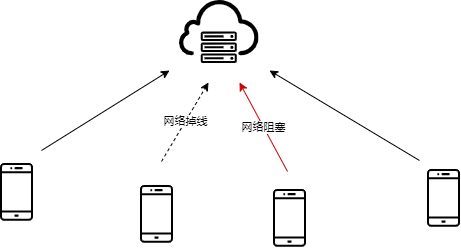
(3)用户掉线
在现实中,边缘计算节点的网络环境并不总是良好的,部分计算节点会存在网络带宽受限、网络截断、网络延迟等情况,计算节点掉线、通信资源有限的问题应该被纳入考量。
😑😑😑图需要改
(4)通信开销大
在目前联邦学习中最常用的迭代-收敛训练模式中,各边缘计算节点训练完本次迭代并提交局部梯度到聚合服务器后进入同步屏障,服务器收到所有计算节点的梯度后进行聚合,更新模型参数,而后解除同步屏障,并开始下一轮迭代。由此我们可以看出:第一,每次迭代都需要花费大量通信开销,文献[High-performance distributed ML at scale through parameter server]的研究表明,在32台机器上运行的隐含狄利克雷分布(Latent Dirichlet Allocation)主题建模中,参数通信所需时间最多达到了迭代计算所需时间的6倍;其次,下次迭代训练需要在所有计算节点都完成一次迭代计算后才会继续进行,因此对集群负载均衡度的要求非常高。然而文献[Project Adam:building an efficient and scalable deep learning system]的研究表明,即使负载均衡的集群中,一些节点也会变得随机和不可预测地比其它节点慢,导致计算性能的浪费。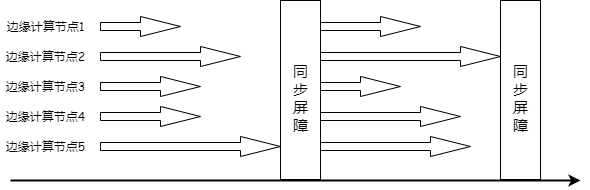
😉😉😉😉😉😉图需要改,算力不平衡,数据不平衡
综上所述,怎样设计一个合适的联邦学习方案解决好面临的难题是本系统的核心。在研究相关文献资料后,我们针对现阶段边缘计算场景下联邦学习存在的较为突出的问题提出以下目标:
(1) 在确保安全的前提下取得与原始联邦学习几乎相同的准确性。
联邦学习采用分布式计算方法,该方法能够让多个客户端协作开发模型,而且不需要彼此共享敏感的数据。在多次迭代过程中,共享模型所覆盖的数据范围会比任何一个组织内部拥有的数据都要大得多,因此联邦学习开发的模型具有准确性高的特点。为了使我们的系统在边缘计算环境下保持联邦学习的准确性,我们在上传参数加密时拟引入随机数聚合清零的思想。相比于差分隐私技术在参数中添加大量的随机化,使得数据的可用性下降,该方法虽然同样在参数上添加随机数,但在服务器参数整合时所有随机数加和后归零。这使得本系统在准确性上堪比原始联邦学习的准确性。
为此,我们拟研究如何在所有用户在线和不同数量用户掉线等情况下都能使得整合参数时所有随机数加和归零。
(2)减少通信开销。
相较于传统的云计算,由于边缘智能计算将数据在网络边缘侧进行处理而后上传参数,已大大减少了通信开销。但由于联邦学习在训练中需要多次上传和下载梯度参数,造成GB以上的通信开销,存在难以适用于带宽有限的边缘计算、物联网等场景的问题。
为此,我们拟研究在不影响算法精度的同时,如何设计一种训练优化策略来减小通信开销。
(3)保护模型参数的隐私,同时不增加通信开销。
使用传统的同态加密算法难以避免同态加密本身存在的一些问题,受到训练过程缓慢、同态电路深度有限、客户端和云端通信等诸多限制。
为此,我们拟研究diffie-hellman协议来加强隐私保护,并在此基础上引入周期性更新策略,使本系统能够在有效保护模型参数隐私的同时不增加通信开销。
(4)抵抗用户训练掉线。
训练过程中由于网络或其他方面原因易出现用户掉线等情况。
为此,我们拟研究增强算法在训练中的鲁棒性,以解决在不可信、不稳定网络环境下可能出现多用户互相共谋、用户在训练中突然掉线等问题。
2.2 方案总体构想
本作品将设计使用安全多方计算框架的联邦学习系统解决在边缘计算场景下训练全局机器学习模型的隐私泄露问题。该联邦学习将采用经典的Client/Server模式,系统包括聚合服务器和能够与之通信的多个客户端,其中我们假定聚合服务器可能是租用的云服务器,并不可信,因恶意攻击的存在,参与训练的客户端设定为”诚实且好奇”的半诚信模型。联邦学习通过最小化所有局部数据集的并集的损失风险来训练共享模型,即:
总体上本作品旨在研究提供一种面向边缘计算场景的安全联邦学习框架,解决在不可信、不稳定网络环境下可能出现梯度泄露、多客户端互相共谋、训练中突然掉线等问题。大体框架如下: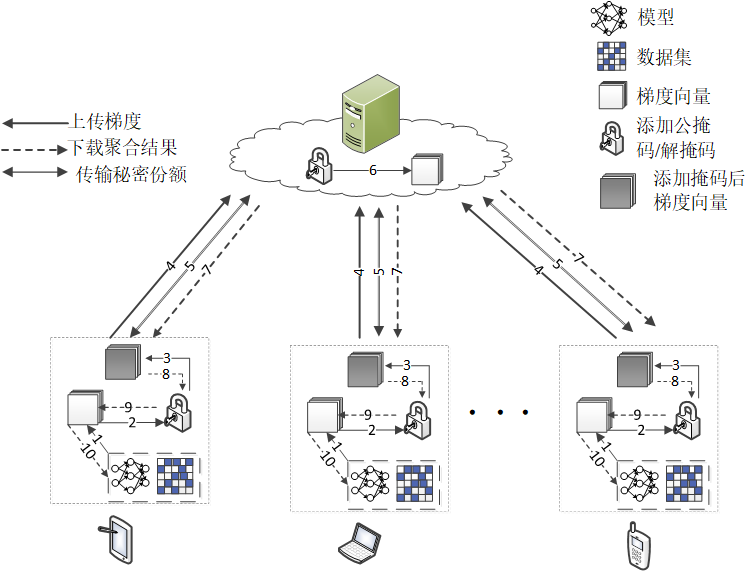
2.3 隐私保护框架
隐私保护框架是本方案的核心设计,该隐私保护框架将使用基于秘密共享的安全多方计算方案、签名、哈希算法、密钥协商等密码算法为旧有边缘计算场景下的联邦学习提供较强的隐私保护。
2.3.1 隐私保护框架设计
基于秘密共享的安全多方计算框架是本隐私保护方案的核心要点。在现有研究中,安全多方计算框架可以通过同态加密、茫然传输、秘密共享等密码学基本算法实现。使用基于同态加密的安全多方计算框架的联邦学习计算开销较大,相较于在聚合服务器使用同态密码加密的梯度信息进行聚合,采用加随机数掩码的方案更加具有可取性。方案中使用DH密钥交换协议、基于拉格朗日插值的秘密共享方案、随机数生成器实现加随机数掩码的工作,首先使用基于DH密钥交换协议的函数 让每个客户端使用个人私钥
让每个客户端使用个人私钥 与其他客户端公钥
与其他客户端公钥 协商一个密钥
协商一个密钥 %22%20aria-hidden%3D%22true%22%3E%0A%20%3Cuse%20xlink%3Ahref%3D%22%23E1-MJMATHI-73%22%20x%3D%220%22%20y%3D%220%22%3E%3C%2Fuse%3E%0A%3Cg%20transform%3D%22translate(469%2C-150)%22%3E%0A%20%3Cuse%20transform%3D%22scale(0.707)%22%20xlink%3Ahref%3D%22%23E1-MJMATHI-75%22%20x%3D%220%22%20y%3D%220%22%3E%3C%2Fuse%3E%0A%20%3Cuse%20transform%3D%22scale(0.707)%22%20xlink%3Ahref%3D%22%23E1-MJMAIN-2C%22%20x%3D%22572%22%20y%3D%220%22%3E%3C%2Fuse%3E%0A%20%3Cuse%20transform%3D%22scale(0.707)%22%20xlink%3Ahref%3D%22%23E1-MJMATHI-76%22%20x%3D%22851%22%20y%3D%220%22%3E%3C%2Fuse%3E%0A%3C%2Fg%3E%0A%3C%2Fg%3E%0A%3C%2Fsvg%3E#card=math&code=s%7Bu%2Cv%7D&height=16&id=wnozu)(
%22%20aria-hidden%3D%22true%22%3E%0A%20%3Cuse%20xlink%3Ahref%3D%22%23E1-MJMATHI-73%22%20x%3D%220%22%20y%3D%220%22%3E%3C%2Fuse%3E%0A%3Cg%20transform%3D%22translate(469%2C-150)%22%3E%0A%20%3Cuse%20transform%3D%22scale(0.707)%22%20xlink%3Ahref%3D%22%23E1-MJMATHI-75%22%20x%3D%220%22%20y%3D%220%22%3E%3C%2Fuse%3E%0A%20%3Cuse%20transform%3D%22scale(0.707)%22%20xlink%3Ahref%3D%22%23E1-MJMAIN-2C%22%20x%3D%22572%22%20y%3D%220%22%3E%3C%2Fuse%3E%0A%20%3Cuse%20transform%3D%22scale(0.707)%22%20xlink%3Ahref%3D%22%23E1-MJMATHI-76%22%20x%3D%22851%22%20y%3D%220%22%3E%3C%2Fuse%3E%0A%3C%2Fg%3E%0A%3C%2Fg%3E%0A%3C%2Fsvg%3E#card=math&code=s%7Bu%2Cv%7D&height=16&id=wnozu)( 分别代表两个不同的客户端id号),使用该密钥作为随机数生成器种子生成与模型梯度向量同样维度的拓展掩码向量
分别代表两个不同的客户端id号),使用该密钥作为随机数生成器种子生成与模型梯度向量同样维度的拓展掩码向量 (其中
(其中 代表本客户端id,
代表本客户端id, 代表所有其他客户端id),并要求当
代表所有其他客户端id),并要求当 时,
时, ;当
;当 时,
时, 。同时每个客户端使用基于拉格朗日插值的秘密共享方案
。同时每个客户端使用基于拉格朗日插值的秘密共享方案 生成秘密共享份额
生成秘密共享份额 并将各个秘密份额分给各个用户。将上面的过程记作添加个人掩码;为了防止服务器获得聚合结果,要求每个客户端使用
并将各个秘密份额分给各个用户。将上面的过程记作添加个人掩码;为了防止服务器获得聚合结果,要求每个客户端使用 生成一个随机数
生成一个随机数 ,并拓展为同维度向量
,并拓展为同维度向量 并分发给各个客户端,各个客户端计算
并分发给各个客户端,各个客户端计算 作为客户端公共掩码。过程图如下所示:
作为客户端公共掩码。过程图如下所示:
😉😉😉缺个图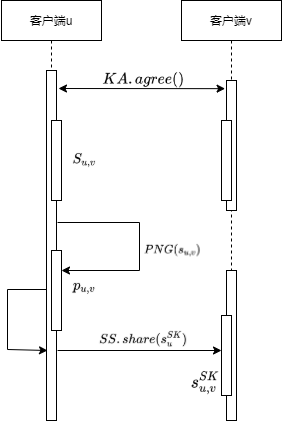
若每个用户都参与了训练,因为密钥交换协议使得 客户端协商了同一个
客户端协商了同一个 ,且
,且 。当
。当 时,
时, ;当
;当 时,
时, 。所以服务器进行聚合时所有个人掩码加和为0向量;倘若少于n-t人掉线,那么聚合服务器就可以收集掉线用户分发给其他t个客户端的私钥的秘密份额进行秘密重构
。所以服务器进行聚合时所有个人掩码加和为0向量;倘若少于n-t人掉线,那么聚合服务器就可以收集掉线用户分发给其他t个客户端的私钥的秘密份额进行秘密重构 (其中,
(其中, 是在线客户端的集合;
是在线客户端的集合; 代表掉线的客户端),恢复出
代表掉线的客户端),恢复出 ,服务器通过客户端的
,服务器通过客户端的 、公开的公钥信息和
、公开的公钥信息和 重构出掉线用户的
重构出掉线用户的 ,这样个人掩码加和为0向量。当聚合服务器使用联邦平均算法完成全局梯度向量聚合时,个人掩码向量加和为0向量不用考虑,发回的客户端的计算结果只需减去公共掩码向量
,这样个人掩码加和为0向量。当聚合服务器使用联邦平均算法完成全局梯度向量聚合时,个人掩码向量加和为0向量不用考虑,发回的客户端的计算结果只需减去公共掩码向量 即可得到全局梯度平均值。
即可得到全局梯度平均值。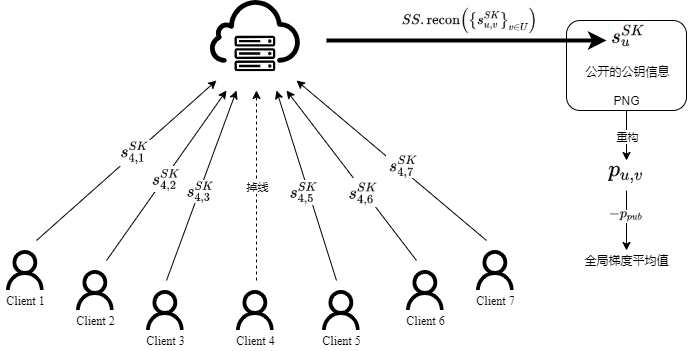
😀😀缺个图
这样,由于个人掩码的存在,联邦学习每个参与方都无法得知单个客户端上传的本地模型梯度,保证了各个客户端隐私安全;由于秘密共享算法的存在,任意少于 个用户都无法通过共谋攻击对系统中某一参与方攻击,这种安全是理论上保证的,与此同时,对于客户端掉线也具有一定冗余性;由于公共掩码的存在,可以保障全局模型梯度不被暴露在传输过程中,保证了全局模型梯度安全。
个用户都无法通过共谋攻击对系统中某一参与方攻击,这种安全是理论上保证的,与此同时,对于客户端掉线也具有一定冗余性;由于公共掩码的存在,可以保障全局模型梯度不被暴露在传输过程中,保证了全局模型梯度安全。
在本系统中,聚合服务器会与各个客户端进行部分通信,信息在传输过程中可能被窃取、中间人攻击、重放攻击、伪造,这对于系统训练是不安全的,在通信过程中会传递梯度信息、公钥信息、秘密份额等信息,梯度信息安全性可以有上述安全设计保证,但是秘密份额作为秘密信息 需要保证传输的机密性、完整性、不可否认性;公钥信息等公开信息
需要保证传输的机密性、完整性、不可否认性;公钥信息等公开信息 需要保证完整性、不可否认性。针对可公开信息
需要保证完整性、不可否认性。针对可公开信息 和秘密信息
和秘密信息 签名算法设计如下:
签名算法设计如下:
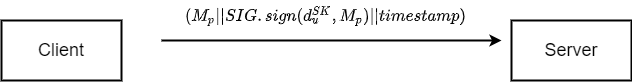

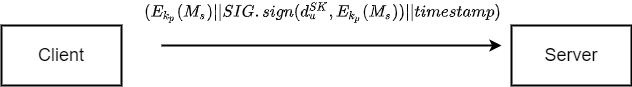
我们使用加密算法实现秘密信息的机密性,使用签名算法保证信息的不可否认性与完整性,同时针对可能的重放攻击需要添加新鲜因子避免重放攻击.
2.3.2 安全多方计算框架
总体上,本边缘联邦学习系统主要由可信第三方、聚合服务器、训练参与客户端三类参与方,可信第三方为聚合服务器、客户端提供身份公证服务;聚合服务器为参与客户端提供训练结果聚合服务及相应公钥广播服务;参与客户端进行本地训练。接下来将从不同层次阐明本系统安全方案设计。
在联邦学习过程中,客户端与聚合服务器需要进行大量通信,为了保证信息完整性和真实性,需要对传输信息进行相关认证处理,保证消息在传递中未被未授权修改或者保证信息传递的完整一致性。所以,在系统设置中可信第三方的存在十分必要,可信第三方作为信任传递节点,可以进行证书签发、证书管理,将用户身份和用户公钥信息、公钥进行绑定,实现公钥与身份的唯一绑定关系。
总体的训练流程如下图所示
0、初始化阶段:
联邦学习进行之前,需要系统设定一些必要参数与相关设置,确保满足系统传输与安全需要。
- 全网基准统一授时。
- 由可信第三方TA生成客户端、聚合服务器公钥证书,进行身份公证,实现公钥与身份的唯一绑定关系,该公私钥对
 主要用于系统进行相关身份认证、消息认证等。
主要用于系统进行相关身份认证、消息认证等。 - 由可信第三方TA生成一个安全素数
 ,该安全素数选取原则为:
,该安全素数选取原则为: 必须具有大的素因子
必须具有大的素因子 的位数应该在1024位以上
的位数应该在1024位以上- 存在
 ,
, 也为素数,同时满足
也为素数,同时满足
- 规定一个有限域
 用于秘密共享算法。
用于秘密共享算法。 - 各个客户端与聚合服务器建立一个通信通路,在本实验中使用较为简单socket机制实现各个参与方的通信互联。
- 设定秘密分享协议中的数值
 和阈值
和阈值 。
。 - 客户端协商使用何种训练模型。
所有参与训练的客户端诚实的使用可信第三方TA提供的安全素数
 生成DH密钥交换协议的相关参数
生成DH密钥交换协议的相关参数
1、公钥共享:
客户端:
参与训练的客户端使用公钥生成算法生成两对公私钥对
 ,并且使用个人签名私钥对该公钥对进行签名
,并且使用个人签名私钥对该公钥对进行签名 。
。- 每一个客户端将生成的两对公钥
 、签名
、签名 、时间戳,拼接后得
、时间戳,拼接后得 ,经base64编码后通过socket连接发送给聚合服务器。
,经base64编码后通过socket连接发送给聚合服务器。
聚合服务器:
- 聚合服务器收集参与训练客户端发来的信息。
聚合服务器在信息收集到一定时间后,且记录的训练客户端数目未达到
 个及以上时,中断本次聚合训练;否则,聚合服务器广播训练客户端集合
个及以上时,中断本次聚合训练;否则,聚合服务器广播训练客户端集合 和签名公钥信息
和签名公钥信息 。
。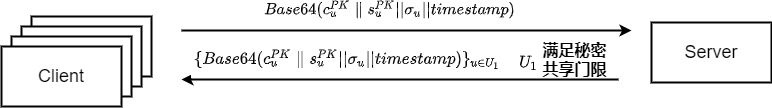
2、密钥协商:
客户端:
- 参与训练客户端收到聚合服务器广播的客户端集合
 和签名公钥信息集合
和签名公钥信息集合 ,对时间戳进行检查检验消息新鲜性 ; 对签名公钥集合信息进行认证
,对时间戳进行检查检验消息新鲜性 ; 对签名公钥集合信息进行认证 ,如若通过验证即进入下一步,否则中断训练。
,如若通过验证即进入下一步,否则中断训练。 - 参与训练客户端使用随机数发生器
 生成一个属于有限域
生成一个属于有限域  的随机数
的随机数  。
。 - 客户端生成一个在有限域
 上次数为
上次数为 的秘密多项式
的秘密多项式 ,通过秘密共享算法生成秘密共享份额
,通过秘密共享算法生成秘密共享份额
- 客户端对于每一个其他客户端
 ,计算
,计算
- 客户端对密文
 使用
使用 杂凑算法取消息摘要并使用签名公钥
杂凑算法取消息摘要并使用签名公钥 进行签名
进行签名
- 客户端将消息
 通过socket连接发送给聚合服务器。
通过socket连接发送给聚合服务器。
聚合服务器:
- 聚合服务器收集至少
 条密文信息,记录参与训练客户端为集合
条密文信息,记录参与训练客户端为集合 。否则中止本次训练。
。否则中止本次训练。 - 检查
 与否,如若不成立,终止,否则继续下一步.
与否,如若不成立,终止,否则继续下一步. -
3、添加掩码
客户端:
参与训练客户端从聚合服务器接收
 并存为列表。
并存为列表。- 客户端检验密文列表信息的新鲜性、完整性,并对密文签名进行认证,确保信息来源正确。以上检验若未通过则终止。
- 客户端解密密文
 ,将解密得到的其他客户端
,将解密得到的其他客户端 发送的秘密份额
发送的秘密份额 和随机数
和随机数 进行保存。
进行保存。 - 对于所有其他客户端
 ,计算
,计算 并使用
并使用 将该值扩展为随机向量
将该值扩展为随机向量 ,其中当
,其中当 时
时 ,当
,当 时
时 (注意
(注意 )。
)。 - 客户端使用各个客户端的
 拓展为随机向量
拓展为随机向量 ,并计算公共掩码向量
,并计算公共掩码向量 。
。 - 计算加入掩码的掩码梯度向量
 。
。 - 对掩码权重向量进行压缩并使用签名公钥进行签名,

如果上述任何过程失败,则中止训练,否则,将
 发送到服务器并移动到下一轮。
发送到服务器并移动到下一轮。
聚合服务器:
服务器接受至少t条签名掩码权重向量信息,并将这些客户端记录为集合
 ,否则终止本次训练。
,否则终止本次训练。- 检查
 与否,如若不成立,终止,否则,继续下一步.
与否,如若不成立,终止,否则,继续下一步. -
4、一致性检验
客户端
客户端从服务器接收至少由
 个用户(包括其自身)组成的列表
个用户(包括其自身)组成的列表 。如果
。如果 小于
小于 ,则中止。
,则中止。-
聚合服务器
从至少
 个用户处收集
个用户处收集 (用
(用 表示这组用户)。向
表示这组用户)。向 中的每个用户发送集合
中的每个用户发送集合 。
。
5、解掩码
客户端:
从服务器接收集合
 。验证
。验证 ,
, ,验证消息新鲜性,根据每个客户端的签名验证公钥进行验证
,验证消息新鲜性,根据每个客户端的签名验证公钥进行验证 表示所有
表示所有 (否则中止)。
(否则中止)。-
聚合服务器
收集至少
 个用户的响应,用
个用户的响应,用 记录这些客户端。
记录这些客户端。- 对于
 中的每个用户,重构
中的每个用户,重构 并使用它(连同在AdvertiseKeys中接收的公钥)使用
并使用它(连同在AdvertiseKeys中接收的公钥)使用 重新计算所有
重新计算所有 的
的 。
。 - 对于每个用户
 ,重构
,重构 ,然后使用
,然后使用 重新计算
重新计算 。
。 - 计算并输出
 为
为 。
。 -
客户端:
参与训练的客户端收到聚合服务器发来的信息,并进行签名验证。
客户端计算联邦聚合梯度
 ,并加载到本地模型,准备进行下一轮联邦训练。
,并加载到本地模型,准备进行下一轮联邦训练。
2.4 系统模块设计
2.4.1 本地数据管理模块
数据分布描述的是数据的统计状态,根据数据样本的不同分布情况,可以将数据分为IID数据和Non-IID数据。IID(Independent Identically Distribution)数据指在数据集中,所有的数据样本都服从于同一分布,并且样本和样本之间相互独立。区别于IID数据,在Non-IID(Non - Independent Identically Distribution)数据集中,数据样本之间非独立,非同分布。
传统的分布式机器学习利用IID数据进行模型训练,训练得到的模型是基于数据独立同分布的假设之上,然而在实际的边缘计算场景中,计算设备属于不同的个体、企业,由于不同客户端时间和空间等方面的差别,其数据的分布往往具有很大的差异,同时用户群体和地域的关联又使数据的分布存在一定的联系,此时数据不满足独立同分布,即为Non-IID数据,可以看出Non-IID数据是更符合实际边缘计算的应用场景的。
在本边缘计算背景下非独立同分数据有如下特点:标签分布偏斜(先验概率偏移):即使
 相同,边际分布
相同,边际分布 也会因客户端而异。例如当客户绑定到特定地理区域时,标签在客户之间的分布会有所不同:对于袋鼠只在澳大利亚或动物园;一个人的脸只在全球的少数地方出现;对于移动设备键盘,某些人群使用某些表情符号,而其他人群则不使用。
也会因客户端而异。例如当客户绑定到特定地理区域时,标签在客户之间的分布会有所不同:对于袋鼠只在澳大利亚或动物园;一个人的脸只在全球的少数地方出现;对于移动设备键盘,某些人群使用某些表情符号,而其他人群则不使用。- 数量偏斜或不平衡:处在不同环境下的客户端所采集到的数据集时远远不同的:布设在地铁站的人脸识别设备可以捕捉到许多人的人脸数据,而放在小区电梯中的人脸识别设备只能捕捉数量相对有限的人脸数据。
 与客户端集合
与客户端集合 。
。
 与客户端集合
与客户端集合 。
。
 到服务器。
到服务器。
 。
。
 ,将
,将 进行广播。
进行广播。
为了突出体现两种数据在联邦学习模型训练中的差异,在独立同分布数据集(IID)下,该联邦学习系统可以获得较传统分布式学习近似相同的准确性;在非独立同分布数据集(Non-IID)下,该使用安全多方计算框架的联邦学习可以获得较传统联邦学习近似的全局准确度。该在实验中我们使用了MNIST和CIFAR数据集,用两种划分手段将60000个数据样本分别划分为IID和Non-IID格式,并将这些样本分配给100个用户。在IID格式中,我们将数据打乱,按照模拟的客户端数量 随机分成
随机分成 份独立同分布数据集(IID)供客户端进行训练。在Non-IID格式中,我们首先利用数字标签将数据排序,将其按照系统模拟客户端数量进行按标签划分。
份独立同分布数据集(IID)供客户端进行训练。在Non-IID格式中,我们首先利用数字标签将数据排序,将其按照系统模拟客户端数量进行按标签划分。
# noniid数据划分举例def mnist_noniid(dataset, num_users):print('minist noniid')"""对Mnist数据集进行noniid数据划分:param dataset::param num_users::return:"""num_shards, num_imgs = 200, 300idx_shard = [i for i in range(num_shards)]dict_users = {i: np.array([], dtype='int64') for i in range(num_users)}idxs = np.arange(num_shards*num_imgs)labels = dataset.train_labels.numpy()# 标签排序idxs_labels = np.vstack((idxs, labels))idxs_labels = idxs_labels[:,idxs_labels[1,:].argsort()]idxs = idxs_labels[0,:]# 划分和指派for i in range(num_users):rand_set = set(np.random.choice(idx_shard, 2, replace=False))idx_shard = list(set(idx_shard) - rand_set)for rand in rand_set:dict_users[i] = np.concatenate((dict_users[i], idxs[rand*num_imgs:(rand+1)*num_imgs]), axis=0)return dict_users
2.4.2 本地训练模块
应用了联邦学习的边缘计算背景下的机器学习训练,可以获得较好的全局模型,但这并不代表本地训练算法设计、训练策略设计不重要。在本地训练中,本作品针对不同的应用场景和需求,提供了两种可供选择的训练模型:结构较为简单的MLP(Multilayer Perceptron) 和结构较为复杂的CNN(Convolutional Neural Network),以实现参数在客户端的更新。为了得到更高的训练效率,我们在模型中采用的训练算法为随机梯度下降算法(SGD)。随机梯度下降算法是对整个数据集的一个极小子集的进行梯度计算的一种极端简化,在最简单的情况下,与最大随机性对应,在每个优化步骤中随机选择一个数据样本[privacy-preserving deep learning].一般线性回归函数的假设函数为: ,对应的损失函数形式为:
,对应的损失函数形式为:

利用每个样本的损失函数对θ求偏导得到对应的梯度,来更新θ: ,相较于非随机算法,SGD能够有效地利用信息,在样本容量很大的情况下仍能较快地达到模型的收敛。
,相较于非随机算法,SGD能够有效地利用信息,在样本容量很大的情况下仍能较快地达到模型的收敛。
另外,联邦学习系统中所使用的分布式梯度下降方法要求客户端每迭代一次与服务器共享其局部参数来更新模型,这就造成在一次模型构建中需要客户端与中央服务器进行多次通信,而在边缘计算场景中,联邦学习系统往往由大量设备组成,比如数百万部智能手机[Communication-Efficient and Privacy-Preserving Federated],大量的通信不但会增大通信开销,还会影响模型的训练效率。为了解决这种问题,本作品使用了周期性更新策略,通过增加本地训练次数来减少客户端和服务器间的通信次数,在这种方法中,客户端每经过T次训练迭代才会向服务器发送更新信息,如果在客户端中共进行了K次迭代,那么只需与服务器进行K/T次通信,[a Communication-efficient Federated learning algorithm with Periodic Averaging and Quantization, FedPAQ]这就使得通信成本和通信时间都减少到了原来的1/T。
2.4.3 通信模块
在边缘计算场景下,本地训练结果需要进行可靠的通信方法传回聚合服务器,我们选取了socket机制进行通信。Socket(套接字)可以看成是两个网络应用程序进行通信时,各自通信连接中的端点,这是一个逻辑上的概念。它是网络环境中进程间通信的API(应用程序编程接口),也是可以被命名和寻址的通信端点,使用中的每一个套接字都有其类型和一个与之相连进程。通信时其中一个网络应用程序将要传输的一段信息写入它所在主机的 Socket中,该 Socket通过与网络接口卡(NIC)相连的传输介质将这段信息送到另外一台主机的 Socket中,使对方能够接收到这段信息。在实现中,我们使用socketIO_client库中的类实现通信,使用其中的emit方法实现各个阶段事件的触发,一轮联邦训练的总体通信过程为: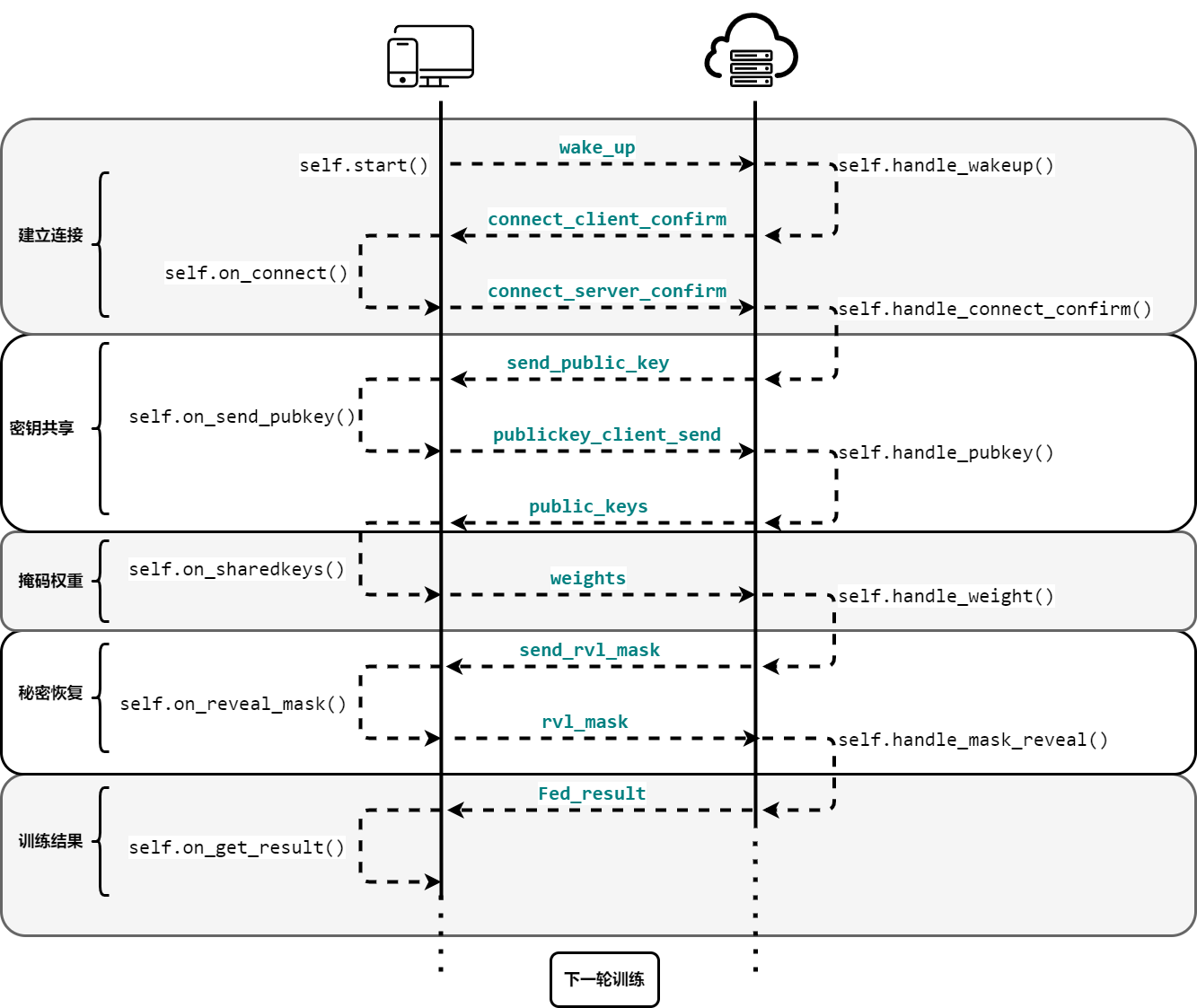
全部在线:

2.4.3权重掩码模块
客户端所传递的模型权重被第三方恶意截获后,随着时间,恶意攻击者可以通过模型权重的变化推算出模型梯度。这样,客户端数据部分分布特征就会因梯度泄露攻击泄露给第三方。为了保护客户端隐私,防止恶意攻击者进行梯度泄露攻击,依照隐私保护方案设计,在客户端本地设定了权重掩码模块,权重掩码是保护权重的核心要素。添加掩码原理公式如下所示:


在实现中,我们通过如下代码实现给模型权重添加掩码的功能,为模型权重提供保护。generate_weight通过调用numpy包中的random.rand函数,以seed为输入变量生成了与模型权重矩阵维数相同的随机数矩阵,实现了公式中 进行拓展为随机向量的功能;由于pytorch生成的权重矩阵为orderdict类型,因而,我们需要对每一个键值对进行处理,通过函数
进行拓展为随机向量的功能;由于pytorch生成的权重矩阵为orderdict类型,因而,我们需要对每一个键值对进行处理,通过函数shift_local_w对权重矩阵中每一值取出,并调用generate_weight实现生成一个完整的与权重参数相同的随机的orderdict类型掩码;在prepare_weights中,简单通过(shared_keys[sid] ** self.secretkey) % self.mod)实现了DH密钥交换协议协商随机数 ,并通过调用前两个函数实现生成一个添加掩码的权重矩阵。
,并通过调用前两个函数实现生成一个添加掩码的权重矩阵。
通过添加掩码,客户端发送的模型权重被很好的保护起来免受恶意攻击,且较于同态加密来讲,计算开销更小。
def generate_weights(seed, x, y):np.random.seed(seed) # 生成与模型权重参数相同的随机数矩阵return np.float32(np.random.rand(int(x), int(y))) # 形状为<x,x>的(0,1)之间的随机矩阵def shift_local_w(self, p_key): # 生成掩码矩阵weight = deepcopy(self.weights)for k, v in weight.items():test = copy.deepcopy(v).numpy().tolist()if len(np.array(test).shape) == 1:weight[k] = torch.Tensor(self.generate_weights(p_key, 1, len(test)))else:weight[k] = torch.Tensor(self.generate_weights(p_key, len(test), len(test[0])))return weightdef prepare_weights(self, shared_keys, myid):# mask the weightself.keys = shared_keysself.id = myidwghts = deepcopy(self.weights)for sid in shared_keys:if sid > myid:wghts = ord_dic_tensor_add(wghts,self.shift_local_w((shared_keys[sid] ** self.secretkey) % self.mod))elif sid < myid:wghts = ord_dic_tensor_sub(wghts,self.shift_local_w((shared_keys[sid] ** self.secretkey) % self.mod))wghts = ord_dic_tensor_add(wghts, self.shift_local_w(self.sndkey))return wghts

若有收获,就点个赞吧
0 人点赞

{kind=link}