
0.隐私保护主要方式:happy:
0.1.K-匿名(Latanya Sweeney 和 Pierangela Samarati 1998)
通过混淆数据的属性, 解决了“给定一个原始数据集, 生成一个匿名化的数据集, 它可以在保证数据的实验可用性的条件下, 保证其中的个体身份不会被恢复出来”
- 优点:使得包含在匿名化数据集中的每一个个体信息都不能从其他k-1个个体信息中区分开。
- 缺点:k-匿名中不包含任何的随机化属性, 所以攻击者依然可以从满足k-匿名性质的数据集中推断出与个体有关的隐私信息。
- 缺点:k-匿名还容易遭受到一致性攻击与背景知识攻击。
0.2.L-多样性(Machanavajjhala 等人 2007)
L-多样性是指, 一个等价类中最少有L个可以很好代替的敏感属性的值
- 不能完全的保护用户隐私不被泄露, 因为在一个真实的数据集中, 属性值很有可能是偏斜的或者语义相近的。
0.3.T-相近(李宁辉等人 )
指一个等价类中的属性分布和整张表中的属性分布之间的距离不超过门限t
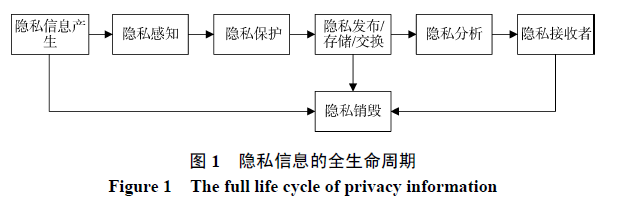
0.4.差分隐私(Dwork 2006)
差分隐私有定量化模型,不依赖攻击者所拥有的背景知识,提供了更高级的语义安全。
1.差分隐私基础
差分隐私不只对整个数据集进行保护,而且对数据集中的每个个体隐私提供保护。
核心概念:要求每一个单一元素在数据集中对输出的结果的影响都是有限的!!
-差分隐私,其中
叫做隐私保护预算,从式子中可以看出隐私保护预算与保护程度成反比。
%20%5Cin%20S_m%5D%20%5Cleq%20e%5E%7B%5Cepsilon%7DPr%5BM(D’)%5D%20%5Cin%20S_m%0A#card=math&code=Pr%5BM%28D%29%20%5Cin%20S_m%5D%20%5Cleq%20e%5E%7B%5Cepsilon%7DPr%5BM%28D%27%29%5D%20%5Cin%20S_m%0A&id=hoqzv)
差分隐私机制能够将一个正常查询函数#card=math&code=f%28%2A%29&id=G4p6q)的查询结果,映射到一个随机化的值域上,并以一定概率分布来给用户返回一个查询结果,可以通过调整参数
来调整一对相邻数据及上的概率分布的接近程度,使得在相邻数据库中一次查询返回结果近乎一致。
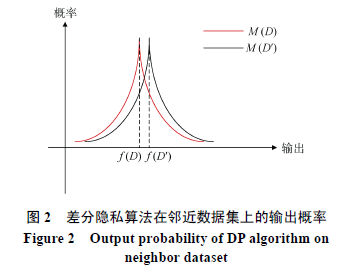
差分隐私的性质
- 顺序合成性:当有一个算法序列同时作用在一个数据集上时, 最终的差分隐私预算等价于算法序列中所有算法的预算的和

- 平行合成性:当有多个算法序列分别作用在一个数据集上多个不同子集上时, 最终的差分隐私预算等价于算法序列中所有算法预算的最大值

- 差分隐私对于后处理算法具有免疫性, 如果一个算法的结果满足
-差分隐私, 那么在这个结果上进行的任何处理都不会对隐私保护有所影响

- 如果有2 个不同的差分隐私算法, 都提供了足够的不确定性来保护隐私, 那么可以通过选择任意的算法来应用到数据上实现对数据的隐私保护, 只要选择的算法和数据是独立的。

2.差分隐私模型
2.1.敏感度
敏感度是决定加入噪声大小的关键参数,它指删除数据集中任一记录对查询结果造成的最大改变。差分隐私中定义了两种敏感度,即全局敏感度和局部敏感度。
2.1.1.全局敏感度:
全局敏感度反映了一个查询函数在一对相邻数据集上进行查询时变化的最大范围。它与数据集无关, 只由查询函数本身决定。
对于一个查询函数,他的形式为:
,其中
为一个数据集,
是查询函数的返回结果,在一堆任意的相邻数据集
和
中,他的全局敏感度定义如下:
%3D%5Cmax%7BD%2CD’%7D%20%5C%7C%20f(D)%20-%20f(D’)%20%5C%7C_1%0A#card=math&code=GS%28f%29%3D%5Cmax%7BD%2CD%27%7D%20%5C%7C%20f%28D%29%20-%20f%28D%27%29%20%5C%7C_1%0A&id=suG3x)
展示在不同隐私预算下拉普拉斯噪声的概率密度函数:
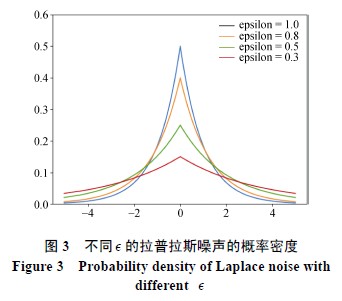
可以看出,隐私预算越小,密度越平滑,添加0的概率越小,混淆越大。
函数的全局敏感度由函数本身决定,不同的函数会有不同的全局敏感度。一些函数的全局敏感度较小,因此只需要加入少量的噪声即可掩盖因一个记录被删除对查询结果所产生的的影响。但某些函数的全局敏感度较大,必须在函数输出中添加足够大的噪声才能保证隐私安全,导致数据可用性较差。因此提出了局部敏感度的概念。
2.1.2.局部敏感度
局部敏感是由查询函数和给定数据集共同决定的,局部差分隐私只对于一个数据集做变化
对于一个查询函数,它的形式为:
, 其中
为一数据集,
是查询函数的返回结果。在一给定的数据集
和与它相邻的任意数据集
上, 它的局部敏感度定义如下:
%3D%5Cmax%7BD’%7D%20%5C%7Cf(D)-f(D’)%5C%7C_1%0A#card=math&code=LS_f%28D%29%3D%5Cmax%7BD%27%7D%20%5C%7Cf%28D%29-f%28D%27%29%5C%7C_1%0A&id=U0SVg)
局部敏感度和全局敏感度的关系可表示为:
%3D%5Cmax_D%20%5C%7BLS_f(D)%5C%7D%0A#card=math&code=GS%28f%29%3D%5Cmax_D%20%5C%7BLS_f%28D%29%5C%7D%0A&id=Rp3GB)
2.1.3.平滑敏感度
局部敏感度在一定程度上体现了数据集的数据分布特征,如果直接应用局部敏感度来计算噪声量则会泄露数据集中的敏感信息,因此局部敏感度的平滑上界被用来与局部敏感度一起确定噪声量的大小。
平滑上界. 给定一个$\beta \gt 0 F:D \rightarrow R
f$上, 如果它满足如下条件:
%20%5Cgeq%20LS_f(D)%20%5C%5C%0A%5Cforall%20D%2CD’%3AF(D)%20%5Cleq%20e%5E%7B%5Cbeta%7D%20%5Ctimes%20LS_f(D’)%0A#card=math&code=%5Cforall%20D%3AF%28D%29%20%5Cgeq%20LS_f%28D%29%20%5C%5C%0A%5Cforall%20D%2CD%27%3AF%28D%29%20%5Cleq%20e%5E%7B%5Cbeta%7D%20%5Ctimes%20LS_f%28D%27%29%0A&id=TNyUS)
则称函数是一个在查询函数
上的
-平滑上界。
平滑敏感度. 对于一个 , 一个查询函数
的
-平滑敏感度为:
%3D%5Cmax%7By%20%5Cin%20D%5En%7D%20%5C%7BLS_f(y)%20%5Ctimes%20e%5E%7B-%20%5Cbeta%20%5Ctimes%20d(D%2Cy)%7D%20%5C%7D%0A#card=math&code=S%5E%2A_f%28D%29%3D%5Cmax%7By%20%5Cin%20D%5En%7D%20%5C%7BLS_f%28y%29%20%5Ctimes%20e%5E%7B-%20%5Cbeta%20%5Ctimes%20d%28D%2Cy%29%7D%20%5C%7D%0A&id=OSpgg)
是和给定数据集
维度相同的任意数据集,函数
返回数据集
和
中的不同元素的个数。实际上, 平滑敏感度就是可以满足平滑上界条件的最小函数。
2.2.实现机制


若有收获,就点个赞吧
0 人点赞
