DeepLab 使用DeepLab的一个主要动机是在帮助控制信号抽取的同时执行图像分割 —— 减少样本的数量和网络必须处理的数据量。另一个动机是启用多尺度上下文特征学习 —— 从不同尺度的图像中聚合特征。DeepLab使用ImageNet预训练的ResNet进行特征提取。DeepLab使用空洞卷积而不是规则的卷积。每个卷积的不同扩张率使ResNet块能够捕获多尺度的上下文信息。DeepLab由三个部分组成:
- Atrous convolutions — 使用一个因子,可以扩展或收缩卷积滤波器的视场。
- ResNet — 微软的深度卷积网络(DCNN)。它提供了一个框架,可以在保持性能的同时训练数千个层。ResNet强大的表征能力促进了计算机视觉应用的发展,如物体检测和人脸识别。
Atrous spatial pyramid pooling (ASPP) — 提供多尺度信息。它使用一组具有不同扩展率的复杂函数来捕获大范围的上下文。ASPP还使用全局平均池(GAP)来合并图像级特征并添加全局上下文信息。
DeepLab 是 Google 在这个领域一系列的工作。
DeepLabv1:具体的细节:
- 2015-04-09 发表在arXiv上
- ICLR 2015
- DeepLabv1: Semantic image segmentation with deep convolutional nets and fully connected CRFs
- Deeplab v1是在vgg-16的基础上做了修改。
- 将vgg16的全连接层转为卷积
- 移除原网络最后两个池化层,使用rate=2 的空洞卷积采样
- 是在ImageNet上预训练的vgg16权重上做 finetune

- DeepLabv2:Deeplab v2 的具体细节:

- 2017-05-12 发表在arXiv上
- TPAMI2017
- DeepLabv2:DeepLab: Semantic Image Segmentation with Deep Convolutional Nets, Atrous Convolution, and Fully Connected CRFs
- 用多尺度获得更好的分割效果(用ASPP)
- 提取特征的基础CNN改为ResNet
- 使用不同的学习策略
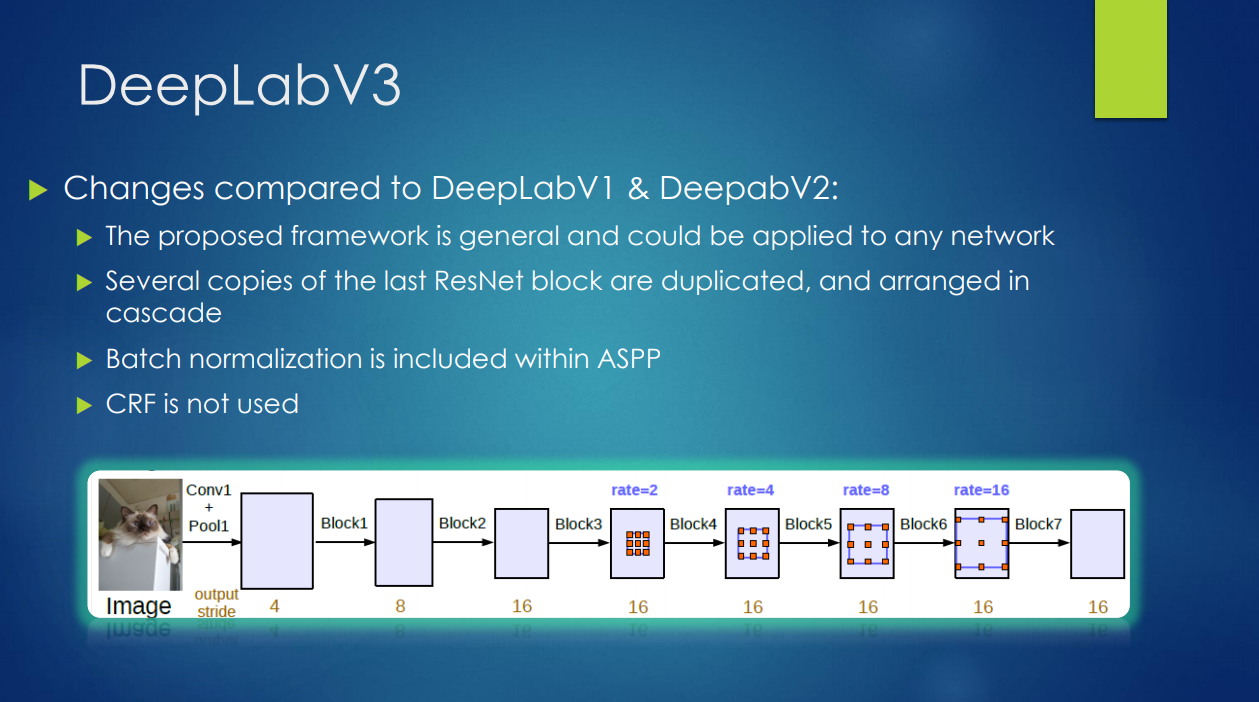
- DeepLabv3具体细节:
- 2017-12-05 发表在arXiv上
- DeepLabv3:Rethinking Atrous Convolution for Semantic Image Segmentation
- 这是一种更加通用的框架
- 级联了多个ResNet中的block单元
- 在ASPP中加入了BN层
- 去掉了CRF

若有收获,就点个赞吧
0 人点赞
