基本情况
这是在DeepLabV1、2基础上的再扩展;
V1 主要是将VGG最后两个的池化改成了stride=1,然后采用了空洞卷积来扩大感受野,上采样使用了双线性插值;
V2主要是在模型最后进行像素分类之前增加一个类似 Inception 的结构,即ASPP模块,通过不同rate得到不同尺度的特征图,再进行预测;
V3 主要是对之前模块的升级,从而提升性能。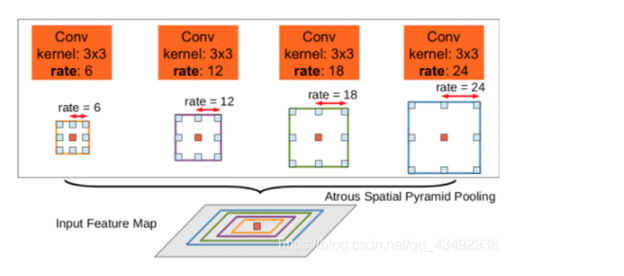
引言&相关工作
一般的分割存在两个挑战,一个是分辨率的下降(由下采样导致),常常采用空洞卷积来代替池化解决,效果不错;
另一个是存在多个尺度的物体,需要多尺度特征图融合,主要有以下四种模型: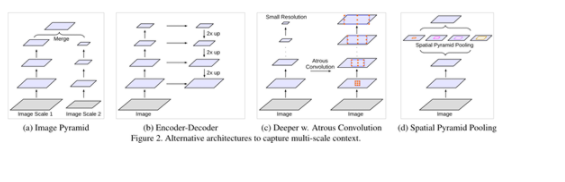
(a) Image Pyramid
相同的模型(通常共享权重)应用于多尺度输入,得到不同范围的上下文语义信息,再经过融合可以分割不同尺度的物体;例如,将Laplacian pyramid的输出当作网络的输入,一次来提取不同尺度的特征;主要的限制是,由于GPU内存有限,它无法在较大/较深的DCNN(例如ResNet)上很好地大范围使用,因此通常在推理阶段(也就是最后的预测的时候)使用。
(b) Encoder-decoder
如SegNet(记录池化索引)、U-Net(skip)、RefineNet等,通过将下采样过程中,不同深度的输出拼接到上采样的过程中的特征图上,就能得到不同尺度的上下文信息;这个限制不明显,算是一种通用类的框架,很多网络都是基于此搭建的;
(c) Context module
该模型包含级联的其他模块,以对对于大范围的(长距离的)语义信息进行编码。有效的且常用的方法是将DenseCRF(具有有效的高维滤波算法)合并到DCNN中。
(d) Spatial pyramid pooling
该模型采用空间金字塔池化来捕获多个范围的上下文。DeepLab v2提出了空洞空间金字塔池化(ASPP),即用不同rate的并行的空洞卷积层,捕获多尺度信息。最近,PSPNet在不同的尺度上进行空间池化,得到不同尺度的特征图。也有用LSTM来聚合全局信息的,同时SPP也被应用于目标检测领域。
这个论文中,主要探讨将空洞卷积作为一种上下文模块和一种空间金字塔池化的工具。
方法
Going Deeper with Atrous Convolution
这个论文里面用output_stride表示输入输出图分辨率的比例,就是缩小的倍数;当将一个pooling的stride从2变道1,那么后面的卷积就要使用rate=2的空洞卷积,这在deepLabv1中有描述;
下图为将Resnet的Block4(里面有3个33的卷积)进行复制,然后级联在网络后面构成Block5、Block6、Block7。(a)是没有使用空洞卷积,所以图像分辨率一直缩小(由经验可以,这种缩小对于信息的丢失是非常严重的),图(b)展示了在不改变分辨率以及感受野的情况下,利用空洞卷积达到了同样的效果。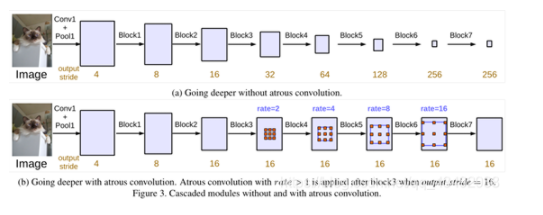
另外,对于每一个block里面的3个卷积层的rate的设置是不同的,文章设置了一个基准系数Multi Grid = (1, 2, 4),那么对应Block4,它的三个卷积层的rate=2 (1, 2, 4)=(2, 4, 8),可以自行设置。设置的时候尽量错开,在Understanding Convolution for Semantic Segmentation中说存在“gridding issue”,所以后面的乘子设置时应要考虑到此问题;
Atrous Spatial Pyramid Pooling
在Net的最后,ASPP以不同的rate能够有效地捕捉多尺度信息,但是随着Block的深入,空洞卷积的rate的变大,就会导致卷积核退化为1 1。例如,现在一个3 3 的空洞卷积核,rate=30,但是前一层的特征图只有65 65,那么当将这个3 3的卷积核应用于此特征图的时候,就只会有中心点在特征图内,其他的卷积核参数,已经到了0填充区域,没有意义了,因为已经捕获不到全局信息了。
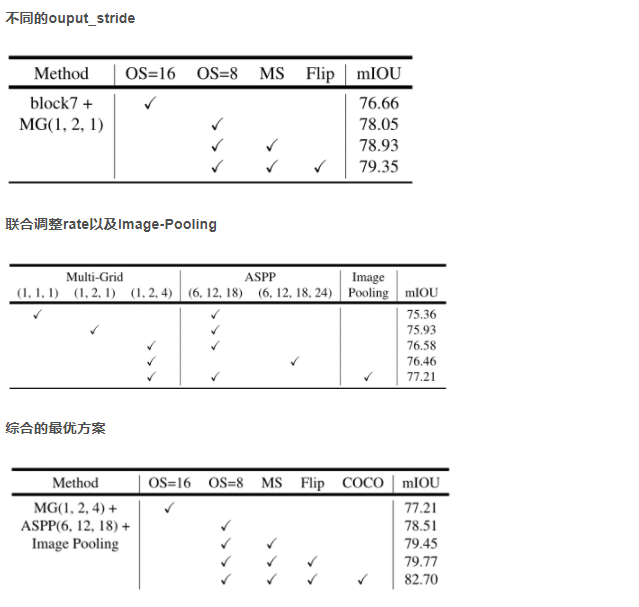
为了解决由于rate增大带来的问题,添加了Image-Level 图像级别的特征,集体就是,对于输入进来的特征图的每一个通道做全局平均池化,然后再通过256个1 1的卷积核构成新的(1, 1, 256)的特征图,然后通过双线性插值得到需要的分辨率的图(如(b)所示),这么做的目的相当于通过这个来弥补rate太大的时候,丢失的信息,也可以理解成,给特征图添加了一个基本量。(a)的部分包括一个1 1和rate分别为6、12、18的空洞卷积,卷积之后都跟了对应的BN层(这对于训练很重要)。最后将(a)和(b)进行concat,然后再通过256个1 * 1 的卷积核,得到新的特征图,然后上采样后,进行损失的计算。(在V1和V2是将label进行下采样的,是一种特立独行的操作)。如果只想将图像下采样到1/8,那么rate就要扩大2倍。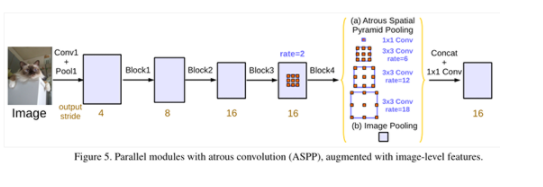
试验
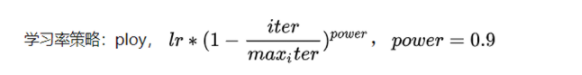
- 分阶段训练,设置不同的学习率参数;
- 图像裁剪为指定大小513 * 513;
- BN;
- 随即缩放和翻转来进行数据增强;
- 上采样;
- 对于hard class进行了复制,以及bootstrapping的方式;
对于深度空洞卷积的试验
逐渐增加模块数量效果越来越好
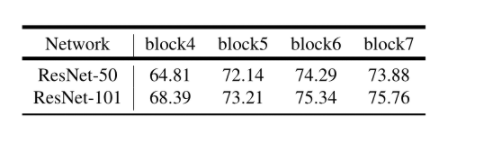
不同的Multi Grid基准系数(ResNet101)
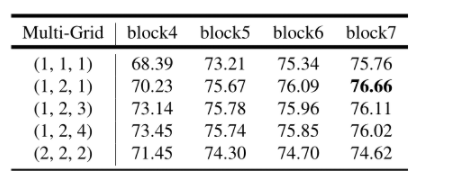
ASPP
————————————————
版权声明:本文为CSDN博主「蜡笔小楚」的原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接及本声明。
原文链接:https://blog.csdn.net/qq_43492938/article/details/111183906

若有收获,就点个赞吧
0 人点赞
