头图:[https://cdn.naraku.cn/imgs/Python_requests-html0.jpg](https://cdn.naraku.cn/imgs/Python_requests-html0.jpg)
简介
Requests是模拟HTTP的测试库,玩过Python爬虫的同学一定听过或者用过,但是Requests只负责网络请求,不会对响应结果进行解析。而该库的作者后来基于现有的框架进行二次封装,又发布了一个更好用的Requests-html库用于解析HTML。Requests-html具有以下特性
- 完全支持 JavaScript
- CSS、xPath 选择器
- 模拟用户代理
- 自动跟踪重定向
-
安装
pip install requests-html
开始使用
爬取博客内全部链接,此处会返回一个
set集合类型的全部链接from requests_html import HTMLSessionsession = HTMLSession()response = session.get("https://www.naraku.cn/")# 获取页面Base_URLbase_url = response.html.base_urlprint(base_url)# 获取网页内的所有链接links = response.html.linksprint(links)# 获取网页内的所有链接绝对路径形式ab_links = response.html.absolute_linksprint(ab_links)
选取元素
上面返回一大堆链接,杂乱且不好利用,不如单纯爬取文章标题和对应的链接吧。
request-html支持CSS选择器和xPath两种语法来选取HTML元素。CSS选择器 - find()
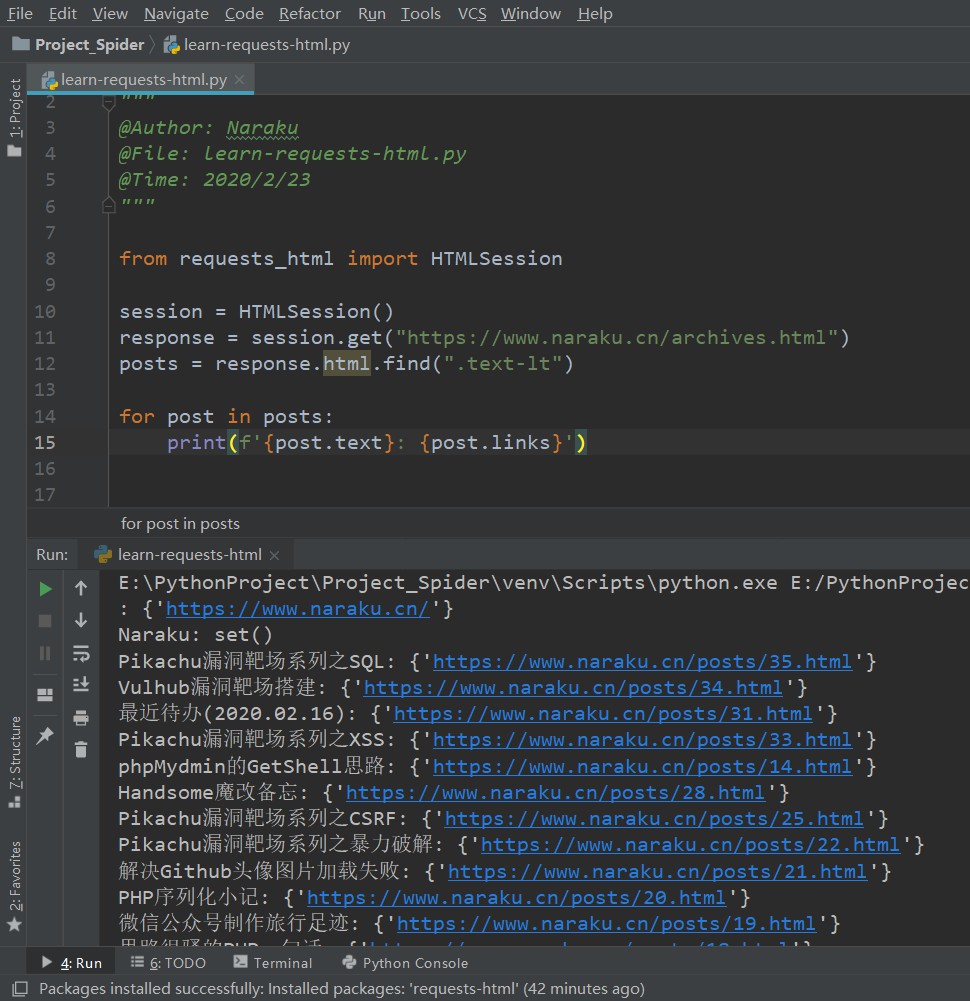
先用CSS选择器来看看吧
from requests_html import HTMLSessionsession = HTMLSession()response = session.get("https://www.naraku.cn/archives.html")posts = response.html.find(".text-lt")for post in posts:print(f'{post.text}: {post.links}')
xPath选择器 - xpath()
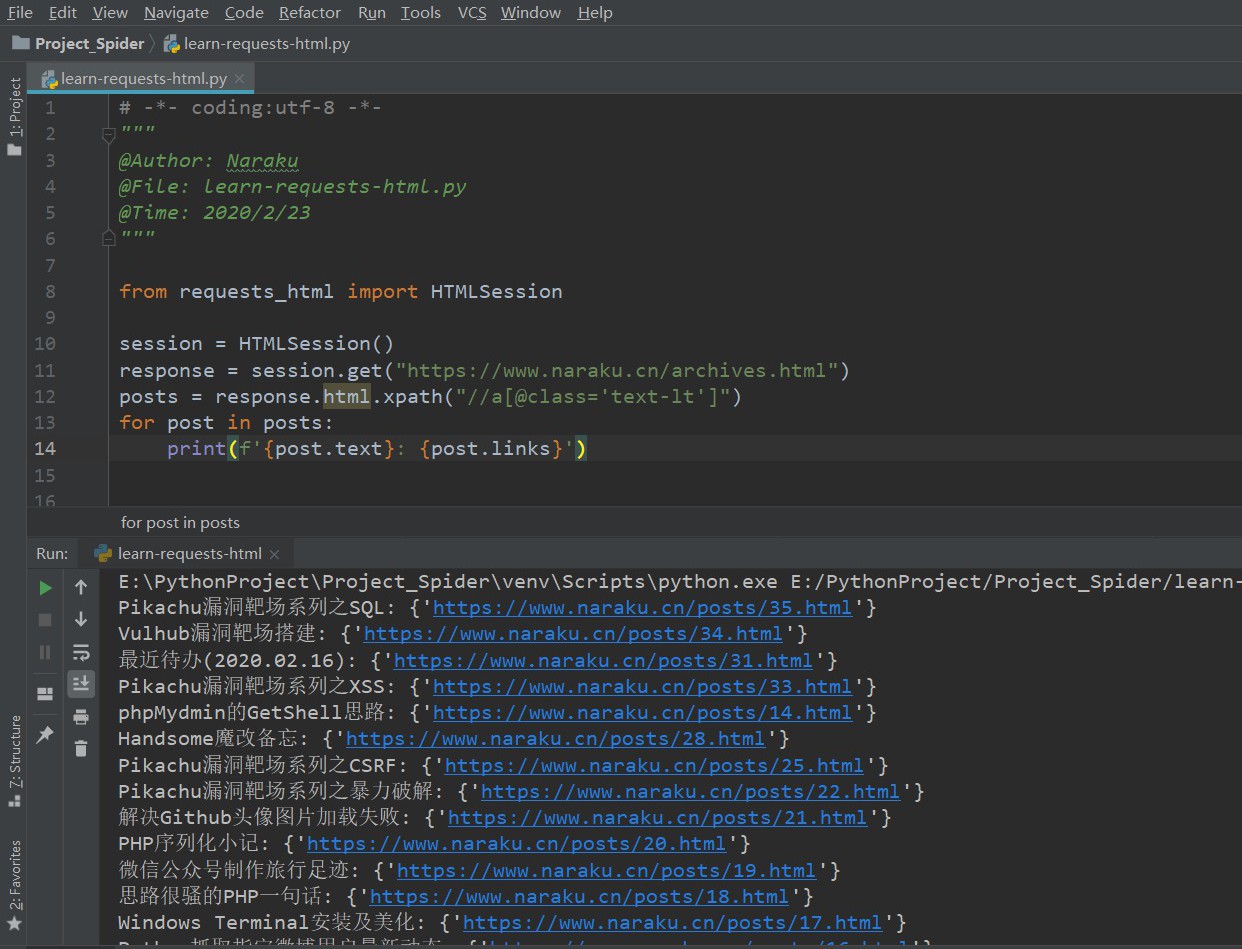
上面写的CSS语法匹配到的不是很精确,因为页面内其它地方也调用了
text-lt这个类,导致前面2行出现了奇怪的东西。所以使用xPath语法来更精确地匹配一下。不熟悉此语法的可以参考xPath用法总结整理from requests_html import HTMLSessionsession = HTMLSession()response = session.get("https://www.naraku.cn/archives.html")posts = response.html.xpath("//a[@class='text-lt']")for post in posts:print(f'{post.text}: {post.links}')
实战
这里尝试爬取一下闲读。进入页面后通过点击下方分页并观察URL,可以发现分页结构为
[http://gank.io/xiandu/wow/page/{](http://gank.io/xiandu/wow/page/%7B)页面数},通过修改页面数即可实现分页。此处只爬取前2页以作演示from requests_html import HTMLSessionif __name__ == '__main__':pages_dict = {} # 保存文章标题及链接session = HTMLSession()for index in range(1, 3):url = f"https://gank.io/xiandu/wow/page/{index}"response = session.get(url)
由于爬取的数量过多,这里添加一个随机UA,需要引入
requests_html库requests_html.user_agent(style=None):返回一个指定风格的合法UA,默认Chrome风格from requests_html import HTMLSessionimport requests_htmlif __name__ == '__main__':pages_dict = {} # 保存文章标题及链接session = HTMLSession()ua = requests_html.user_agent() # 随机UAheaders = {'User-Agent': ua}for index in range(1, 3):url = f"https://gank.io/xiandu/wow/page/{index}"response = session.get(url, headers=headers)
定义一个函数用于解析页面,并将文章的标题和链接存到字典中。这里依然使用xPath语法
def parse_html(r):pages = r.html.xpath("//a[@class='site-title']")for page in pages:pages_dict[page.text] = list(page.links)[0]
最后将字典写入
json,此处需引入json库import jsondef save_data():pages_json = json.dumps(pages_dict, ensure_ascii=False) # 转为json对象with open("Pages_Dic.json", "w", encoding='utf-8') as f:f.write(pages_json)
完整代码
# -*- coding:utf-8 -*-"""@Author: Naraku@File: learn-requests-html.py@Time: 2020/2/23"""from requests_html import HTMLSessionimport requests_htmlimport jsondef parse_html(r):pages = r.html.xpath("//a[@class='site-title']")for page in pages:pages_dict[page.text] = list(page.links)[0]def save_data():pages_json = json.dumps(pages_dict, ensure_ascii=False) # 转为json对象with open("Pages_Dic.json", "w", encoding='utf-8') as f:f.write(pages_json)if __name__ == '__main__':pages_dict = {} # 用于保存文章标题及链接session = HTMLSession()ua = requests_html.user_agent() # 随机UAheaders = {'User-Agent': ua}for index in range(1, 3):url = f"https://gank.io/xiandu/wow/page/{index}"response = session.get(url, headers=headers)parse_html(response)save_data() # 保存为json文件

若有收获,就点个赞吧
0 人点赞
