- 1001 害死人不偿命的(3n+1)猜想
- 1002 写出这个数
- 1003 我要通过!
- 1004 成绩排名
- 1005 继续(3n+1)猜想
- 1006 换个格式输出整数
- 1007 素数对猜想
- 1008 数组元素循环右移问题
- 1009 说反话
- 1010 一元多项式求导
- 1011 A+B 和 C
- 1012 数字分类
- 1013 数素数
- 1014 福尔摩斯的约会
- x1015 德才论
- 1016 部分A+B
- 1017 A除以B
- x1018 锤子剪刀布
- 1019 数字黑洞
- 1020 月饼
- 1021 个位数统计
- 1022 D进制的A+B
- 1023 组个最小数
- 1024 科学计数法
- x1025 反转链表
- 1026 程序运行时间
- 1027 打印沙漏
- 1028 人口普查
- 1029 旧键盘
- 1030 完美数列
- 1031 查验身份证
- x1032 挖掘机技术哪家强
- 1033 旧键盘打字
- 1034 有理数四则运算
- 1035 插入与归并
- 1036 跟奥巴马一起编程
- 1037 在霍格沃茨找零钱
- 1038 统计同成绩学生
- 1039 到底买不买
- 1040 有几个PAT
- 1041 考试座位号
- 1042 字符统计
- 1043 输出PATest
- 1044 火星数字
- 1045 快速排序
- 1046 划拳
- 1047 编程团体赛
- 1048 数字加密
- 1049 数列的片段和
头图:https://cdn.naraku.cn/imgs/Python_PAT0.jpg
PAT (Basic Level) Practice
题号前带x的为部分测试点超时。
1001 害死人不偿命的(3n+1)猜想
题目
卡拉兹(Callatz)猜想:对任何一个正整数 n,如果它是偶数,那么把它砍掉一半;如果它是奇数,那么把 3n+1砍掉一半。这样一直反复砍下去,最后一定在某一步得到 n=1。卡拉兹在 1950 年的世界数学家大会上公布了这个猜想,传说当时耶鲁大学师生齐动员,拼命想证明这个貌似很傻很天真的命题,结果闹得学生们无心学业,一心只证 3n+1,以至于有人说这是一个阴谋,卡拉兹是在蓄意延缓美国数学界教学与科研的进展……
我们今天的题目不是证明卡拉兹猜想,而是对给定的任一不超过 1000 的正整数 n,简单地数一下,需要多少步(砍几下)才能得到 n=1 ?
输入样例:
每个测试输入包含 1 个测试用例,即给出正整数 n 的值。
3
输出样例:
输出从 n 计算到 1 需要的步数。
5
代码
count = 0n = int(input())while n!=1:n = n/2 if n%2==0 else (3*n+1)/2count+=1print(count)
1002 写出这个数
题目
读入一个正整数 n,计算其各位数字之和,用汉语拼音写出和的每一位数字。
输入样例:
每个测试输入包含 1 个测试用例,即给出自然数 n 的值。这里保证 n 小于 10。
1234567890987654321123456789
输出样例:
在一行内输出 n 的各位数字之和的每一位,拼音数字间有 1 空格,但一行中最后一个拼音数字后没有空格。
yi san wu
代码
mapping = {0: "ling",1: "yi",2: "er",3: "san",4: "si",5: "wu",6: "liu",7: "qi",8: "ba",9: "jiu",}s = 0num_str = ""nums = input() # 用str存储,便于遍历且不会超出整数范围for num in nums:s += int(num)while s>0:n = s%10 # 取余得个位s //= 10 # /会返回浮点型num_str = mapping[n] + " " + num_strprint(num_str[:-1])
总结
- 除法
/会返回浮点数,//则会根据除数和被除数决定,其中一个是浮点数则返回浮点数,否则返回向下取整的整数。1003 我要通过!
题目
“答案正确”是自动判题系统给出的最令人欢喜的回复。本题属于 PAT 的“答案正确”大派送 —— 只要读入的字符串满足下列条件,系统就输出“答案正确”,否则输出“答案错误”。
得到“答案正确”的条件是:
- 字符串中必须仅有
P、A、T这三种字符,不可以包含其它字符; - 任意形如
xPATx的字符串都可以获得“答案正确”,其中x或者是空字符串,或者是仅由字母A组成的字符串; - 如果
aPbTc是正确的,那么aPbATca也是正确的,其中a、b、c均或者是空字符串,或者是仅由字母A组成的字符串。
现在就请你为 PAT 写一个自动裁判程序,判定哪些字符串是可以获得“答案正确”的。
输入样例:
每个测试输入包含 1 个测试用例。第 1 行给出一个正整数 n (<10),是需要检测的字符串个数。接下来每个字符串占一行,字符串长度不超过 100,且不包含空格。
8PATPAATAAPATAAAAPAATAAAAxPATxPTWhateverAPAAATAA
输出样例:
每个字符串的检测结果占一行,如果该字符串可以获得“答案正确”,则输出
YES,否则输出NO。
YESYESYESYESNONONONO
代码
strs = []flag = []def judge(s):char = ['P','A','T','p','a','t']for c in s:if c not in char: # 判断有没有其它字符return "NO"# 记录PT下标,并匹配abcp = s.find("P") if "P" in s else s.find("p")t = s.find("T") if "T" in s else s.find("t")a = s[:p]b = s[p+1:t]c = s[t+1:]if b == "":return "NO"if c != a*len(b):return "NO"return "YES"n = int(input())while n:value = input()strs.append(value)n -= 1for s in strs:flag.append(judge(s))for f in flag:print(f)
总结
- 思路:有形如xPyTx的字符串,x是空或仅由A组成的字符串,y是仅由A组成的字符串。以PT为分割线,P前段为a,P T之间为b,T之后为c,则若它是正确答案,有
c=a*len(b)1004 成绩排名
题目
读入n(>0)名学生的姓名、学号、成绩,分别输出成绩最高和成绩最低学生的姓名和学号。
输入样例:对每个测试用例输出 2 行,第 1 行是成绩最高学生的姓名和学号,第 2 行是成绩最低学生的姓名和学号,字符串间有 1 空格。
3Joe Math990112 89Mike CS991301 100Mary EE990830 95
输出样例:
Mike CS991301Joe Math990112
代码
n = int(input())dic = {}k = []while n:msg = input().split()dic[int(msg[2])] = msg[0] + " " + msg[1] # 以成绩为key,姓名学号为value存入字典n -= 1for key in dic.keys(): # 把key存入列表,目的是使用max和min函数得到最大最小值k.append(key)print(dic[max(k)]) # 以最大最小值为key输出字典中的valueprint(dic[min(k)])
总结
- 因为题目保证成绩不会相同,所以以成绩为key,姓名学号为value的字典形式保存学生信息。此处列表的作用是用于存储key并得到最大最小的key,从而得到输出的value。
1005 继续(3n+1)猜想
题目
卡拉兹(Callatz)猜想已经在1001中给出了描述。在这个题目里,情况稍微有些复杂。
当我们验证卡拉兹猜想的时候,为了避免重复计算,可以记录下递推过程中遇到的每一个数。例如对 n=3 进行验证的时候,我们需要计算 3、5、8、4、2、1,则当我们对 n=5、8、4、2 进行验证的时候,就可以直接判定卡拉兹猜想的真伪,而不需要重复计算,因为这 4 个数已经在验证3的时候遇到过了,我们称 5、8、4、2 是被 3“覆盖”的数。我们称一个数列中的某个数 n为“关键数”,如果 n 不能被数列中的其他数字所覆盖。
现在给定一系列待验证的数字,我们只需要验证其中的几个关键数,就可以不必再重复验证余下的数字。你的任务就是找出这些关键数字,并按从大到小的顺序输出它们。
输入样例:每个测试输入包含 1 个测试用例,第 1 行给出一个正整数 K (<100),第 2 行给出 K 个互不相同的待验证的正整数 n(1<n≤100)的值,数字间用空格隔开。
63 5 6 7 8 11
输出样例:
每个测试用例的输出占一行,按从大到小的顺序输出关键数字。数字间用 1 个空格隔开,但一行中最后一个数字后没有空格。
7 6
代码
n = input()nums = list(map(int,input().split())) # 转换成listmark = nums[:]for num in nums:k = numwhile k>1:k = k/2 if k%2==0 else (3*k+1)/2 # 找出k所覆盖的数并从列表中删除if k in mark:mark.remove(k)mark.sort(reverse=True)for i in range(len(mark)-1):print(mark[i],end=' ')print(mark[-1], end='')
总结
- map/filter函数在python2中返回列表,在python3中返回
map/filter迭代器,且在经过一次for循环遍历后,再次访问会返回空列表。
原因:由于Python中“没有指针,但是所有对象均为指针”,完成一次遍历后指针会移到最后一个元素上了。也就是说,D是一个map object,print(list(D))或者for循环打印D中的元素,都会导致迭代器从头走到尾(可以类比list[0]到list[n])。 而迭代器是一个单向的容器,走到尾部之后,不会自动再回到开始位置。 所以,对Map对象进行一次for循环之后,Map就相当于“空”了。
参考:Python3 循环遍历map
234
输出样例 1:
每个测试用例的输出占一行,用规定的格式输出n。
BBSSS1234
输入样例 2:
23
输出样例 2:
SS123
代码
num = int(input())n = num % 10 # 个位s = num % 100 //10 # 十位b = num // 100 # 百位strs = b*'B' + s*'S'for i in range(1, n+1):strs += str(i)print(strs)
1007 素数对猜想
题目
定义d为:d=p+1−p,其中p是第i个素数。显然有d=1,且对于n>1有d是偶数。“素数对猜想”认为“存在无穷多对相邻且差为2的素数”。
现给定任意正整数N(<10),请计算不超过N的满足猜想的素数对的个数。(素数:在大于1的自然数中,除了1和它本身以外不再有其他因数)
输入样例:
输入在一行给出正整数N。
20
输出样例:
在一行中输出不超过N的满足猜想的素数对的个数。
4
代码
运行
n = int(input())nums = []for i in range(2,n+1):for j in range(2,i): # 如果在for循环中含有break时则直接终止循环,并不会执行else子句if(i%j == 0):breakelse:nums.append(i)a = nums[:-1] # 取nums中0~n-1位b = nums[1:] # 取nums中1~n位c = [abs(a[i] - b[i]) for i in range(len(a))] # ab相减即nums相邻数相减,然后取绝对值并存入c中count = c.count(2)print(count)
优化
原理:
- 从
p=2开始,将2加入素数列表,并将所有2的倍数标记为0- 向后依次取标记为1的数,先将其加入素数列表,然后将其所有倍数标记为0
n = int(input())nums = []flag = [1] * (n + 2)p = 2while (p <= n):nums.append(p) # 将p加入素数列表,并将所有p的倍数标记为0for i in range(2 * p, n + 1, p):flag[i] = 0while True: # 向后依次取标记为1的数p += 1if (flag[p] == 1):breaka = nums[:-1] # 取nums中0~n-1位b = nums[1:] # 取nums中1~n位c = [abs(a[i] - b[i]) for i in range(len(a))] # ab相减即nums相邻数相减,然后取绝对值并存入c中count = c.count(2)print(count)
总结
- for-else语句
- 素数筛选优化
1008 数组元素循环右移问题
题目
一个数组A中存有N(>0)个整数,在不允许使用另外数组的前提下,将每个整数循环向右移M(≥0)个位置,即将A中的数据由(A A…A)变换为(A…A AA…A)(最后M个数循环移至最前面的M个位置)。如果需要考虑程序移动数据的次数尽量少,要如何设计移动的方法?
输入样例:每个输入包含一个测试用例,第1行输入N(1≤N≤100)和 M(≥0);第2行输入N个整数,之间用空格分隔。
6 21 2 3 4 5 6
输出样例:
在一行中输出循环右移M位以后的整数序列,之间用空格分隔,序列结尾不能有多余空格。
5 6 1 2 3 4
代码
n,m = map(int,input().split())m = m%n # 将m取余n,可得移动的步数。当m=0或n的倍数,即无需移动。nums = input().split()for i in range(n-1):print(nums[i-m],end=" ")print(nums[(n-1)-m],end="")
总结
因为Python支持负值索引,所以可以逐个遍历打印,无需使用另外的数组。
1009 说反话
题目
给定一句英语,要求你编写程序,将句中所有单词的顺序颠倒输出。
输入样例:
测试输入包含一个测试用例,在一行内给出总长度不超过 80 的字符串。字符串由若干单词和若干空格组成,其中单词是由英文字母(大小写有区分)组成的字符串,单词之间用 1 个空格分开,输入保证句子末尾没有多余的空格
Hello World Here I Come
输出样例:
每个测试用例的输出占一行,输出倒序后的句子。
Come I Here World Hello
代码
s = input().split()s.reverse() # 列表反转for i in range(len(s)-1):print(s[i],end=" ")print(s[-1],end="")
1010 一元多项式求导
题目
设计函数求一元多项式的导数。(注:x(n为整数)的一阶导数为nx-1 )
输入样例:
以指数递降方式输入多项式非零项系数和指数(绝对值均为不超过 1000 的整数)。数字间以空格分隔。
3 4 -5 2 6 1 -2 0
输出样例:
以与输入相同的格式输出导数多项式非零项的系数和指数。数字间以空格分隔,但结尾不能有多余空格。注意“零多项式”的指数和系数都是 0,但是表示为
0 0。
12 3 -10 1 6 0
代码
nums = list(map(int, input().split()))s = []i = 0# x^n => x=x*n, n-=1while i < len(nums):x = nums[i]*nums[i+1]n = nums[i+1]-1i += 2if n==-1: # 即原本的nums[i+1]=0,为常数项,所以不用添加进列表continues.append(x)s.append(n)if len(s)==0: # 零多项式print('0 0')else:for i in range(len(s)-1):print(s[i], end=" ")print(s[len(s)-1], end="")
1011 A+B 和 C
题目
给定区间 [−2,2] 内的 3 个整数 A、B 和 C,请判断 A+B 是否大于 C。
输入样例:
输入第 1 行给出正整数 T (≤10),是测试用例的个数。随后给出 T 组测试用例,每组占一行,顺序给出 A、B 和C。整数间以空格分隔。
41 2 32 3 42147483647 0 21474836460 -2147483648 -2147483647
输出样例:
对每组测试用例,在一行中输出
Case #X: true如果 A+B>C,否则输出Case #X: false,其中X是测试用例的编号(从 1 开始)。
Case #1: falseCase #2: trueCase #3: trueCase #4: false
代码
n = int(input())cases = ['false'] * nfor i in range(n):nums = list(map(int, input().split()))if nums[0]+nums[1]>nums[2]:cases[i] = 'true'for i,case in enumerate(cases):print(f"Case #{i+1}: {case}")
1012 数字分类
题目
给定一系列正整数,请按要求对数字进行分类,并输出以下 5 个数字:
- A1 = 能被 5 整除的数字中所有偶数的和;
- A2 = 将被 5 除后余 1 的数字按给出顺序进行交错求和,即计算 n1−n2+n3−n4⋯;
- A3 = 被 5 除后余 2 的数字的个数;
- A4 = 被 5 除后余 3 的数字的平均数,精确到小数点后 1 位;
- A5 = 被 5 除后余 4 的数字中最大数字。
输入样例 1:
每个输入包含 1 个测试用例。每个测试用例先给出一个不超过 1000 的正整数 N,随后给出N 个不超过 1000 的待分类的正整数。数字间以空格分隔。
13 1 2 3 4 5 6 7 8 9 10 20 16 18
输出样例 1:
对给定的 N个正整数,按题目要求计算 A1~A5 并在一行中顺序输出。数字间以空格分隔,但行末不得有多余空格。若其中某一类数字不存在,则在相应位置输出
N。
30 11 2 9.7 9
输入样例 2:
8 1 2 4 5 6 7 9 16
输出样例 2:
N 11 2 N 9
代码
nums = list(map(int, input().split()))[1:] # 这里第一个输入的是数字总数,不能加入计算A1 = list(filter(lambda n:n%5==0 and n%2==0, nums)) # 被5整除的数字中偶数的和A2 = list(filter(lambda n:n%5==1, nums)) # 被5除后余1的数,交错求和 n1-n2+n3-n4...A3 = list(filter(lambda n:n%5==2, nums)) # 被5除后余2的数的个数A4 = list(filter(lambda n:n%5==3, nums)) # 被5除后余3的数的平均数,精确小数点后1位A5 = list(filter(lambda n:n%5==4, nums)) # 被5除后余4的数中的最大数out = []out.append(sum(A1)) if A1 else out.append('N')if A2:flag = 1temp = 0for num in A2:temp += num*flagflag = -flagout.append(temp)else:out.append("N")out.append(len(A3)) if A3 else out.append('N')out.append(round(sum(A4)/len(A4),1)) if A4 else out.append('N')out.append(max(A5)) if A5 else out.append('N')for o in out[:-1]:print(o,end=' ')print(out[-1])
总结
round(), 保留小数点后几位
1013 数素数
题目
令 P表示第 i 个素数。现任给两个正整数M ≤ N ≤10,请输出 P 到 P 的所有素数。
输入样例:
输入在一行中给出 M 和 N,其间以空格分隔。
5 27
输出样例:
输出 P 到 P 的所有素数,每 10 个数字占 1 行,其间以空格分隔,但行末不得有多余空格。
11 13 17 19 23 29 31 37 41 4347 53 59 61 67 71 73 79 83 8997 101 103
代码
m,n = map(int,input().split())nums = []# 找出第1~第n个素数i = 2while len(nums)<n:for j in range(2, i):if(i%j == 0):breakelse:nums.append(i)i+=1# 输出第m~第n个素数nums_mn = nums[m-1:]for i,num in enumerate(nums_mn[:-1]):if (i+1) % 10 == 0:print(num)else:print(num,end=" ")print(nums_mn[-1])
优化
m,n = map(int,input().split())nums = []# 找出第1~第n个素数nums = []flag = [1] * 200000 # 此处小于200000时测试点4会非零返回p = 2while (len(nums)<n):nums.append(p) # 将p加入素数列表,并将所有p的倍数标记为0for i in range(2 * p, 200000, p):flag[i] = 0while True: # 向后依次取标记为1的数p += 1if (flag[p] == 1):break# 输出第m~第n个素数nums_mn = nums[m-1:]for i,num in enumerate(nums_mn[:-1]):if (i+1) % 10 == 0:print(num)else:print(num,end=" ")print(nums_mn[-1])
1014 福尔摩斯的约会
题目
大侦探福尔摩斯接到一张奇怪的字条:我们约会吧! 3485djDkxh4hhGE 2984akDfkkkkggEdsb s&hgsfdk d&Hyscvnm。大侦探很快就明白了,字条上奇怪的乱码实际上就是约会的时间星期四 14:04,因为前面两字符串中第 1 对相同的大写英文字母(大小写有区分)是第 4 个字母 D,代表星期四;第 2 对相同的字符是 E ,那是第 5 个英文字母,代表一天里的第 14 个钟头(于是一天的 0 点到 23 点由数字 0 到 9、以及大写字母 A 到 N 表示);后面两字符串第 1 对相同的英文字母 s 出现在第 4 个位置(从 0 开始计数)上,代表第 4 分钟。现给定两对字符串,请帮助福尔摩斯解码得到约会的时间。
输入样例:
输入在 4 行中分别给出 4 个非空、不包含空格、且长度不超过 60 的字符串。
3485djDkxh4hhGE2984akDfkkkkggEdsbs&hgsfdkd&Hyscvnm
输出样例:
在一行中输出约会的时间,格式为
DAY HH:MM,其中DAY是某星期的 3 字符缩写,即MON表示星期一,TUE表示星期二,WED表示星期三,THU表示星期四,FRI表示星期五,SAT表示星期六,SUN表示星期日。题目输入保证每个测试存在唯一解。
THU 14:04
代码
str1 = input()str2 = input()str3 = input()str4 = input()mark = []week = ['MON','TUE','WED','THU','FRI','SAT','SUN']# ord() 转换为Ascii码,A=65for i in range(min(len(str1),len(str2))):if (str1[i] == str2[i]) and ('A'<=str1[i]<='G'):mark.append(ord(str1[i]) - 64)breakfor j in range(i+1, min(len(str1),len(str2))):if (str1[j] == str2[j]) and ('A'<= str1[j] <='N'):mark.append(str(ord(str1[j]) - 55))breakelif (str1[j] == str2[j]) and ('0' <= str1[j] <= '9'):mark.append('0' + str1[j])breakfor i in range(min(len(str3),len(str4))):if str3[i] == str4[i] and str3[i].isalpha():if i<10:mark.append('0' + str(i))else:mark.append(str(i))print(f"{week[mark[0]-1]} {mark[1]}:{mark[2]}")
总结
ord()转换为ASCII码
x1015 德才论
题目
宋代史学家司马光在《资治通鉴》中有一段著名的“德才论”:“是故才德全尽谓之圣人,才德兼亡谓之愚人,德胜才谓之君子,才胜德谓之小人。凡取人之术,苟不得圣人,君子而与之,与其得小人,不若得愚人。”
现给出一批考生的德才分数,请根据司马光的理论给出录取排名。
输入样例:
输入第一行给出 3 个正整数,分别为:N(≤10),即考生总数;L(≥60),为录取最低分数线,即德分和才分均不低于 L 的考生才有资格被考虑录取;H(<100),为优先录取线——德分和才分均不低于此线的被定义为“才德全尽”,此类考生按德才总分从高到低排序;才分不到但德分到线的一类考生属于“德胜才”,也按总分排序,但排在第一类考生之后;德才分均低于 H,但是德分不低于才分的考生属于“才德兼亡”但尚有“德胜才”者,按总分排序,但排在第二类考生之后;其他达到最低线 L 的考生也按总分排序,但排在第三类考生之后。随后 N 行,每行给出一位考生的信息,包括:
准考证号 德分 才分,其中准考证号为 8 位整数,德才分为区间 [0, 100] 内的整数。数字间以空格分隔。
14 60 8010000001 64 9010000002 90 6010000011 85 8010000003 85 8010000004 80 8510000005 82 7710000006 83 7610000007 90 7810000008 75 7910000009 59 9010000010 88 4510000012 80 10010000013 90 9910000014 66 60
输出样例:
输出第一行首先给出达到最低分数线的考生人数 M,随后 M 行,每行按照输入格式输出一位考生的信息,考生按输入中说明的规则从高到低排序。当某类考生中有多人总分相同时,按其德分降序排列;若德分也并列,则按准考证号的升序输出。
1210000013 90 9910000012 80 10010000003 85 8010000011 85 8010000004 80 8510000007 90 7810000006 83 7610000005 82 7710000002 90 6010000014 66 6010000008 75 7910000001 64 90
代码
注:测试点2/3/4运行超时,据说是Python性能问题?
"""N 考生总数L 录取最低分数线H 优先录取线1. 德分和才分均不低于H -> 【才德全尽】,此类考生按德才总分从高到低排序2. 才分不到但德分到H ->【德胜才】,也按总分排序,但排在第一类考生之后3. 德才分均低于H,但是德分不低于才分 -> 【才德兼亡】,但尚有【德胜才】者,按总分排序4. 其他达到最低线 L 的考生也按总分排序,但排在第三类考生之后。考生总数 录取最低分数线 优先录取线准考证号 德分 才分..."""# def rank(s): # 排序方式# scores = s[1]+s[2]# return scores, s[1], -s[0] # 德才总分,德分,学号.因为分数降序,而同分学号从低到高,所以学号取负n,l,h = map(int, input().split())l1,l2,l3,l4 = [],[],[],[]while n:student = list(map(int,input().split()))if student[1]>=l and student[2]>=l: # 德才均及格if student[1]>=h and student[2]>=h:l1.append(student)elif student[1]>=h: # 前面判断了才分,这里可以不作判断l2.append(student)elif student[1]>=student[2]:l3.append(student)else:l4.append(student)n -= 1print(len(l1)+len(l2)+len(l3)+len(l4))for lis in (l1,l2,l3,l4):# lis.sort(key=rank,reverse=True)lis.sort(key=lambda s:(s[1]+s[2],s[1],-s[0]), reverse=True) # 将排序修改成lambda表达式返回元组for li in lis:print(f'{li[0]} {li[1]} {li[2]}')
总结
sort(),排序可以通过key参数传入一个函数来进行排序,且这个函数可返回多个值,排序时当第1个值相同时,会根据第2个值排序,以此类推;另外key若传入的是lambda表达式,返回多个值时需包装成元组来返回,如lis.sort(key=lambda s:(s[1]+s[2],s[1],-s[0]))
1016 部分A+B
题目
正整数 A 的“D(为 1 位整数)部分”定义为由 A 中所有 D 组成的新整数 P。例如:给定 A=3862767,D=6,则A的“6 部分”P 是 66,因为 A 中有 2 个 6。
现给定 A、D、B、D,请编写程序计算 P+P。
输入样例 1:
输入在一行中依次给出 A、D、B、D,中间以空格分隔,其中 0<A,B<10。
3862767 6 13530293 3
输出样例 1:
在一行中输出 P+P的值。
399
输入样例 2:
3862767 1 13530293 8
输出样例2:
0
代码
A,DA,B,DB = input().split()pA,pB = '0','0'for i in A:if i == DA:pA+=ifor i in B:if i == DB:pB+=iprint(int(pA)+int(pB))
1017 A除以B
题目
本题要求计算 A/B,其中 A 是不超过 1000 位的正整数,B*是 1 位正整数。你需要输出商数 Q 和余数 R,使得 A=B×Q+R 成立。
输入样例:
输入在一行中依次给出 A 和 B,中间以 1 空格分隔。
123456789050987654321 7
输出样例:
在一行中依次输出 Q 和 R,中间以 1 空格分隔。
17636684150141093474 3
代码
A,B = input().split()q = int(A) // int(B)r = int(A) % int(B)print(q,r)
x1018 锤子剪刀布
题目
大家应该都会玩“锤子剪刀布”的游戏:两人同时给出手势,胜负规则如图所示: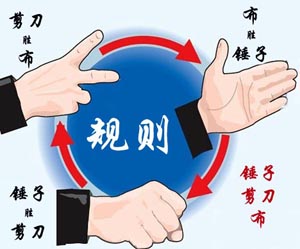
现给出两人的交锋记录,请统计双方的胜、平、负次数,并且给出双方分别出什么手势的胜算最大。
输入样例:
输入第 1 行给出正整数 N(≤10),即双方交锋的次数。随后 N 行,每行给出一次交锋的信息,即甲、乙双方同时给出的的手势。
C代表“锤子”、J代表“剪刀”、B代表“布”,第 1 个字母代表甲方,第 2 个代表乙方,中间有 1 个空格。
10C JJ BC BB BB CC CC BJ BB CJ J
输出样例:
输出第 1、2 行分别给出甲、乙的胜、平、负次数,数字间以 1 个空格分隔。第 3 行给出两个字母,分别代表甲、乙获胜次数最多的手势,中间有 1 个空格。如果解不唯一,则输出按字母序最小的解。
5 3 22 3 5B B
代码
注:测试点5运行超时,可能还是Python性能问题?
n = int(input())count= [0,0,0] # 记录甲胜平负,且甲输=乙胜win1,win2 = [],[] # 记录甲乙胜利手势out = []while n:p1,p2 = input().split()if p1==p2: # 平局count[1] += 1elif (p1,p2) in [('C','J'), ('J','B'), ('B','C')]: # 甲胜count[0] += 1win1.append(p1) # 记录甲胜手势else: # 乙胜count[2] += 1 # 甲负+1win2.append(p2) # 记录乙胜手势n -= 1for lst in [win1,win2]:if lst.count('B') >= lst.count('C') and lst.count('B') >= lst.count('J'):out.append("B")elif lst.count('C') >= lst.count('B') and lst.count('C') >= lst.count('J'):out.append("C")else:out.append("J")print(f'{count[0]} {count[1]} {count[2]}') # 甲胜平负print(f'{count[2]} {count[1]} {count[0]}') # 乙胜平负print(f'{out[0]} {out[1]}')
1019 数字黑洞
题目
给定任一个各位数字不完全相同的 4 位正整数,如果我们先把 4 个数字按非递增排序,再按非递减排序,然后用第 1 个数字减第 2 个数字,将得到一个新的数字。一直重复这样做,我们很快会停在有“数字黑洞”之称的 6174,这个神奇的数字也叫 Kaprekar 常数。
例如,我们从6767开始,将得到
7766 - 6677 = 10899810 - 0189 = 96219621 - 1269 = 83528532 - 2358 = 61747641 - 1467 = 6174... ...
现给定任意 4 位正整数,请编写程序演示到达黑洞的过程。
输入样例 1:
输入给出一个 (0,104) 区间内的正整数 N。
6767
输出样例 1:
如果 N 的 4 位数字全相等,则在一行内输出
N - N = 0000;否则将计算的每一步在一行内输出,直到6174作为差出现,输出格式见样例。注意每个数字按4位数格式输出。
7766 - 6677 = 10899810 - 0189 = 96219621 - 1269 = 83528532 - 2358 = 6174
输入样例 2:
2222
输出样例 2:
2222 - 2222 = 0000
代码
def hole(num):x = ''.join(sorted(num,reverse=True))y = x[::-1] # 反转z = str(int(x) - int(y))if len(z) < 4: # 补0z = (4-len(z)) * '0' + zprint(f'{x} - {y} = {z}')if z == '6174':returnelse: # 递归执行hole(z)num = input()if len(num) < 4: # 不足4位前面补0num = (4-len(num)) * '0' + numif num[0]==num[1]==num[2]==num[3]: # 4位相等print(f'{num} - {num} = 0000')else:hole(num)
总结
- 字符串s不能直接使用
s.sort()进行排序,会抛出AttributeError属性错误。但可以用sorted(s)来将其排序并返回一个列表,再通过''.join()将返回的列表添加到一个空字符串中,这样即可将某个字符串进行排序。
s = '9527's = ''.join(sorted(s))print(s) # '2579'
1020 月饼
题目
月饼是中国人在中秋佳节时吃的一种传统食品,不同地区有许多不同风味的月饼。现给定所有种类月饼的库存量、总售价、以及市场的最大需求量,请你计算可以获得的最大收益是多少。
注:销售时允许取出一部分库存。样例给出的情形是这样的:假如我们有 3 种月饼,其库存量分别为 18、15、10 万吨,总售价分别为 75、72、45 亿元。如果市场的最大需求量只有 20 万吨,那么我们最大收益策略应该是卖出全部 15 万吨第 2 种月饼、以及 5 万吨第 3 种月饼,获得 72 + 45/2 = 94.5(亿元)。
输入样例:
每个输入包含一个测试用例。每个测试用例先给出一个不超过 1000 的正整数 N 表示月饼的种类数、以及不超过 500(以万吨为单位)的正整数 D 表示市场最大需求量。随后一行给出 N 个正数表示每种月饼的库存量(以万吨为单位);最后一行给出 N 个正数表示每种月饼的总售价(以亿元为单位)。数字间以空格分隔。
3 2018 15 1075 72 45
输出样例:
对每组测试用例,在一行中输出最大收益,以亿元为单位并精确到小数点后 2 位。
94.50
代码
n,d = map(int, input().split())goods = list(map(float, input().split()))price = list(map(float, input().split()))unit_price = {i:price[i]/goods[i] for i in range(n)} # 单价sort_price = sorted(unit_price, key=lambda i:unit_price[i], reverse=True) # 单价排序profit = 0for i in sort_price:if d >= goods[i]: # 当前需求量>库存量 -> 全都要profit += price[i]d -= goods[i]else: # 当前需求量<库存量profit += d * unit_price[i] # 当前需求量*对应单价breakprint(f"{profit:.2f}")
总结
贪心算法:物品可以分割为任意大小,可选用贪心策略3: 选取单位价值最大的物品。 先计算出每种月饼的单价,再根据单价进行降序排序,最后从高到低进行销售,此时收益最大。
1021 个位数统计
题目
给定一个 k 位整数 N=d10+⋯+d10+d (0 ≤ d ≤ 9, i=0,⋯,k−1, d > 0),请编写程序统计每种不同的个位数字出现的次数。例如:给定 N=100311,则有 2 个 0,3 个 1,和 1 个 3。
输入样例:
每个输入包含 1 个测试用例,即一个不超过 1000 位的正整数 N。
100311
输出样例:
对 N 中每一种不同的个位数字,以
D:M的格式在一行中输出该位数字D及其在 N 中出现的次数M。要求按D的升序输出。
0:21:33:1
代码
num = input()count = [0] * 10for i in num:count[int(i)] += 1for i,c in enumerate(count):if c:print(f'{i}:{c}')
1022 D进制的A+B
题目
输入两个非负 10 进制整数 A 和 B (≤230−1),输出 A+B 的 D (1
输入在一行中依次给出 3 个整数 A、B 和 D。
123 456 8
输出样例:
输出 A+B 的 D 进制数。
1103
代码
a,b,d = map(int, input().split())n = a + bnums = [0,1,2,3,4,5,6,7,8,9,'A','B','C','D','E','F']out = []while True: # 不能while n直接跳出,因为可能会漏掉最后一个余数y = n % d # 余n //= d # 商out.append(y)if n==0:breakout.reverse()for o in out:print(nums[o],end="")
1023 组个最小数
题目
给定数字 0-9 各若干个。你可以以任意顺序排列这些数字,但必须全部使用。目标是使得最后得到的数尽可能小(注意 0 不能做首位)。例如:给定两个 0,两个 1,三个 5,一个 8,我们得到的最小的数就是 10015558。
现给定数字,请编写程序输出能够组成的最小的数。
输入样例:
输入在一行中给出 10 个非负整数,顺序表示我们拥有数字 0、数字 1、……数字 9 的个数。整数间用一个空格分隔。10 个数字的总个数不超过 50,且至少拥有 1 个非 0 的数字。
2 2 0 0 0 3 0 0 1 0
输出样例:
在一行中输出能够组成的最小的数。
10015558
代码
count = input().split()nums = []for index,c in enumerate(count):nums += int(c) * str(index) # 数量*下标(0~9)for i in range(len(nums)):if nums[i]!='0': # 将首位与第1位非0数交换nums[0],nums[i] = nums[i], nums[0]breakfor n in nums:print(n,end="")
1024 科学计数法
题目
科学计数法是科学家用来表示很大或很小的数字的一种方便的方法,其满足正则表达式 [+-][1-9].[0-9]+E[+-][0-9]+,即数字的整数部分只有 1 位,小数部分至少有 1 位,该数字及其指数部分的正负号即使对正数也必定明确给出。
现以科学计数法的格式给出实数 A,请编写程序按普通数字表示法输出 A,并保证所有有效位都被保留。
输入样例 1:
每个输入包含 1 个测试用例,即一个以科学计数法表示的实数 A。该数字的存储长度不超过 9999 字节,且其指数的绝对值不超过 9999。
+1.23400E-03
输出样例 1:
对每个测试用例,在一行中按普通数字表示法输出 A,并保证所有有效位都被保留,包括末尾的 0。
0.00123400
输入样例 2:
-1.2E+10
输出样例 2:
-12000000000
代码
n,powe = input().split('E')flag = '' if n[0]=='+' else '-' # 正负a,b = n[1:].split(".") # 整数.小数num = a + be = int(powe[1:]) # 指数大小,无+-号b_len = len(b) # 小数位数if e == 0:out = f'{flag}{n[1:]}' # 不直接使用n[:]的原因是正数不需输出+号elif powe[0] == '+':if e-b_len < 0:out = f'{flag}{num[:(e+1)]}.{num[(e+1):]}'else:out = f'{flag}{num}{(e-b_len)*"0"}'else:out = f'{flag}0.{(e-1)*"0"}{num}'print(out)
x1025 反转链表
题目
给定一个常数 K 以及一个单链表 L,请编写程序将 L 中每 K 个结点反转。例如:给定 L 为 1→2→3→4→5→6,K 为 3,则输出应该为 3→2→1→6→5→4;如果 K 为 4,则输出应该为 4→3→2→1→5→6,即最后不到 K 个元素不反转。
输入样例:
每个输入包含 1 个测试用例。每个测试用例第 1 行给出第 1 个结点的地址、结点总个数正整数 N (≤105)、以及正整数 K(≤N),即要求反转的子链结点的个数。结点的地址是 5 位非负整数,NULL 地址用 −1 表示。接下来有 N 行,每行格式为:
Address Data Next
其中 Address 是结点地址,Data 是该结点保存的整数数据,Next 是下一结点的地址。
00100 6 400000 4 9999900100 1 1230968237 6 -133218 3 0000099999 5 6823712309 2 33218
输出样例:
对每个测试用例,顺序输出反转后的链表,其上每个结点占一行,格式与输入相同。
00000 4 3321833218 3 1230912309 2 0010000100 1 9999999999 5 6823768237 6 -1
代码
注:测试点5运行超时
start,n,k = input().split()in_lines = [] # 暂时存放输入的列表sort_lines = [] # 排序的列表out_lines = [] # 输出的列表for i in range(int(n)):line = input().split()if line[0] == start:sort_lines.append(line) # 首位直接存入排序列表else:in_lines.append(line)# 将存放输入的列表按顺序存入排序列表while sort_lines[-1][2] != '-1':for li in in_lines:if li[0] == sort_lines[-1][2]: # 排序sort_lines.append(li)break# 从第0位开始,如果剩余结点满足k位,则反转后追加到输出列表;不满足则直接追加到输出列表后跳出for i in range(0, int(n), int(k)):if len(sort_lines[i:i+int(k)]) >= int(k):temp = sort_lines[i:i+int(k)]temp.reverse()out_lines += tempelse:out_lines += sort_lines[i:i+int(k)]break# 将next指针指向下一结点的地址,并将最后一个结点的next记为-1for i in range(len(out_lines)-1):out_lines[i][2] = out_lines[i+1][0]out_lines[-1][2] = '-1'# 输出for line in out_lines:print(f'{line[0]} {line[1]} {line[2]}')
1026 程序运行时间
题目
要获得一个 C 语言程序的运行时间,常用的方法是调用头文件 time.h,其中提供了 clock() 函数,可以捕捉从程序开始运行到 clock() 被调用时所耗费的时间。这个时间单位是 clock tick,即“时钟打点”。同时还有一个常数 CLK_TCK,给出了机器时钟每秒所走的时钟打点数。于是为了获得一个函数 f 的运行时间,我们只要在调用 f 之前先调用 clock(),获得一个时钟打点数 C1;在 f 执行完成后再调用 clock(),获得另一个时钟打点数 C2;两次获得的时钟打点数之差 (C2-C1) 就是 f 运行所消耗的时钟打点数,再除以常数 CLK_TCK,就得到了以秒为单位的运行时间。这里不妨简单假设常数 CLK_TCK 为 100。现给定被测函数前后两次获得的时钟打点数,请你给出被测函数运行的时间。
输入样例:
输入在一行中顺序给出 2 个整数 C1 和 C2。注意两次获得的时钟打点数肯定不相同,即 C1 < C2,并且取值在 [0,107]。
123 4577973
输出样例:
在一行中输出被测函数运行的时间。运行时间必须按照
hh:mm:ss(即2位的时:分:秒)格式输出;不足 1 秒的时间四舍五入到秒。
12:42:59
代码
CLK_TCK = 100a,b = map(int, input().split())time =round((b-a)/CLK_TCK) # 取整hh = time//3600mm = time//60%60ss = time%60print('%02d:%02d:%02d' % (hh,mm,ss)) # 格式化,不足2位需补0
1027 打印沙漏
题目
本题要求你写个程序把给定的符号打印成沙漏的形状。例如给定17个*,要求按下列格式打印
*****************
所谓“沙漏形状”,是指每行输出奇数个符号;各行符号中心对齐;相邻两行符号数差2;符号数先从大到小顺序递减到1,再从小到大顺序递增;首尾符号数相等。给定任意N个符号,不一定能正好组成一个沙漏。要求打印出的沙漏能用掉尽可能多的符号。
输入样例:
输入在一行给出1个正整数N(≤1000)和一个符号,中间以空格分隔。
19 *
输出样例:
首先打印出由给定符号组成的最大的沙漏形状,最后在一行中输出剩下没用掉的符号数。
*****************2
代码
n,star = input().split()out = [star] # 将1颗星存入输出列表n = int(n)-1 # 剩余数量i = 3 # 下一层星数while n>0:if (n - i*2)<=0:breakelse:n = n - i*2out.insert(0, i*star) # 分别在头尾插入out.append(i*star)i += 2for i in out:print("%s%s" % (" "*((len(out[0])-len(i))//2),i)) # (第1层长度-当前层长度)/2,即为空格数量print(n)
1028 人口普查
题目
某城镇进行人口普查,得到了全体居民的生日。现请你写个程序,找出镇上最年长和最年轻的人。
这里确保每个输入的日期都是合法的,但不一定是合理的——假设已知镇上没有超过 200 岁的老人,而今天是 2014 年 9 月 6 日,所以超过 200 岁的生日和未出生的生日都是不合理的,应该被过滤掉。
输入样例:
输入在第一行给出正整数 N,取值在(0,105];随后 N 行,每行给出 1 个人的姓名(由不超过 5 个英文字母组成的字符串)、以及按
yyyy/mm/dd(即年/月/日)格式给出的生日。题目保证最年长和最年轻的人没有并列。
5John 2001/05/12Tom 1814/09/06Ann 2121/01/30James 1814/09/05Steve 1967/11/20
输出样例:
在一行中顺序输出有效生日的个数、最年长人和最年轻人的姓名,其间以空格分隔。
3 Tom John
代码
注:同样的代码,Python3最后一项超时,Python2反而不会超时。
# Python3n = int(input())count = 0max_day = ['','2014/09/06']min_day = ['','1814/09/06']while n:person = input().split()if '1814/09/06' <= person[1] <= "2014/09/06":count += 1if person[1] < max_day[1]:max_day = personif person[1] > min_day[1]:min_day = personn -= 1if count:print(f'{count} {max_day[0]} {min_day[0]}')else:print("0")
优化
# Python2n = int(raw_input())count = 0max_day = ['', '2014/09/06']min_day = ['', '1814/09/06']while n:person = raw_input().split()if '1814/09/06' <= person[1] <= '2014/09/06':count += 1if person[1] < max_day[1]:max_day = personif person[1] > min_day[1]:min_day = personn -= 1if count:print count, max_day[0], min_day[0]else:print '0'
1029 旧键盘
题目
旧键盘上坏了几个键,于是在敲一段文字的时候,对应的字符就不会出现。现在给出应该输入的一段文字、以及实际被输入的文字,请你列出肯定坏掉的那些键。
输入样例:
输入在 2 行中分别给出应该输入的文字、以及实际输入的文字。每段文字是不超过 80 个字符的串,由字母 A-Z(包括大、小写)、数字 0-9、以及下划线
_(代表空格)组成。题目保证 2 个字符串均非空。
7_This_is_a_test_hs_s_a_es
输出样例:
按照发现顺序,在一行中输出坏掉的键。其中英文字母只输出大写,每个坏键只输出一次。题目保证至少有 1 个坏键。
7TI
代码
str1 = input() # 应该输入的文字str2 = input() # 实际输入的文字no_exist = []for s in str1:if s not in str2:s = s.upper() if s.isalpha() else sif s not in no_exist:no_exist.append(s)for i in no_exist:print(i,end="")
1030 完美数列
题目
给定一个正整数数列,和正整数 p,设这个数列中的最大值是 M,最小值是 m,如果 M≤mp,则称这个数列是完美数列。
现在给定参数 p 和一些正整数,请你从中选择尽可能多的数构成一个完美数列。
输入样例:
输入第一行给出两个正整数 N 和 p,其中 N(≤10)是输入的正整数的个数,p(≤10)是给定的参数。第二行给出 N 个正整数,每个数不超过 10。
10 82 3 20 4 5 1 6 7 8 9
输出样例:
在一行中输出最多可以选择多少个数可以用它们组成一个完美数列。
8
代码
x = [int(i) for i in input().split()]n = x[0]p = x[1]nums = input().split()nums = sorted(map(int, nums))count = 0for i in range(n):while count + i < n:if nums[i] * p >= nums[i + count]:count += 1else:breakprint(count)
1031 查验身份证
题目
一个合法的身份证号码由17位地区、日期编号和顺序编号加1位校验码组成。校验码的计算规则如下:
首先对前17位数字加权求和,权重分配为:{7,9,10,5,8,4,2,1,6,3,7,9,10,5,8,4,2};然后将计算的和对11取模得到值Z;最后按照以下关系对应Z值与校验码M的值:
Z:0 1 2 3 4 5 6 7 8 9 10M:1 0 X 9 8 7 6 5 4 3 2
现在给定一些身份证号码,请你验证校验码的有效性,并输出有问题的号码。
输入样例1:
输入第一行给出正整数N(≤100)是输入的身份证号码的个数。随后N行,每行给出1个18位身份证号码。
432012419880824005612010X19890101123411010819671130186637070419881216001X
输出样例1:
按照输入的顺序每行输出1个有问题的身份证号码。这里并不检验前17位是否合理,只检查前17位是否全为数字且最后1位校验码计算准确。如果所有号码都正常,则输出
All passed。
12010X19890101123411010819671130186637070419881216001X
输入样例2:
2320124198808240056110108196711301862
输出样例2:
All passed
分析
题目要求通过计算身份证前17位数和权重加权求和,得到加权和再取余11得到
z,再通过关系表得到M,最后判断M是否与身份证的第18位相等,且如果全部身份证都有效,需输出All passed。另外题目提示只检查前17位是否全为数字且最后1位校验码计算准确,因此只需遍历身份证的每一位,当存在非数字则可直接记为错误并输出;若全为数字,则计算并判断校验码的准确性即可。
代码
weight = [7, 9, 10, 5, 8, 4, 2, 1, 6, 3, 7, 9, 10, 5, 8, 4, 2] # 权重ZM = ['1','0','X','9','8','7','6','5','4','3','2'] # 记录ZM对应关系error = 0n = int(input())for i in range(n):num = input()count = 0flag = 1 # 记录是否全为数字for index in range(17):if num[index].isdigit(): # 判断是否数字count += weight[index]*int(num[index])else: # 存在非数字flag设为0print(num)error = 1flag = 0breakif flag:count %= 11if num[-1] != ZM[count]: # 判断校验码有效性print(num)error = 1if error==0:print("All passed")
x1032 挖掘机技术哪家强
题目
为了用事实说明挖掘机技术到底哪家强,PAT 组织了一场挖掘机技能大赛。现请你根据比赛结果统计出技术最强的那个学校。
输入样例:
输入在第 1 行给出不超过 105 的正整数 N,即参赛人数。随后 N 行,每行给出一位参赛者的信息和成绩,包括其所代表的学校的编号(从 1 开始连续编号)、及其比赛成绩(百分制),中间以空格分隔。
63 652 801 1002 703 403 0
输出样例:
在一行中给出总得分最高的学校的编号、及其总分,中间以空格分隔。题目保证答案唯一,没有并列。
2 150
分析
利用字典存储编号-分数,如果对应的键(编号)存在,则对应的值(分数)增加。最后输出最大的值和对应键。
代码
最后一项运行超时。
n = int(input())dic = {} # 字典存储编号和分数for i in range(n):num,score = input().split()if num in dic.keys():dic[num] += int(score)else:dic[num] = int(score)max_key = max(dic, key=dic.get)max_value = dic[max_key]print(max_key,max_value)
1033 旧键盘打字
题目
旧键盘上坏了几个键,于是在敲一段文字的时候,对应的字符就不会出现。现在给出应该输入的一段文字、以及坏掉的那些键,打出的结果文字会是怎样?
输入样例:
输入在 2 行中分别给出坏掉的那些键、以及应该输入的文字。其中对应英文字母的坏键以大写给出;每段文字是不超过 105 个字符的串。可用的字符包括字母 [
a-z,A-Z]、数字0-9、以及下划线_(代表空格)、,、.、-、+(代表上档键)。题目保证第 2 行输入的文字串非空。 注意:如果上档键坏掉了,那么大写的英文字母无法被打出。
7+IE.7_This_is_a_test.
输出样例:
在一行中输出能够被打出的结果文字。如果没有一个字符能被打出,则输出空行。
_hs_s_a_tst
分析
因为坏键都是大写的,所以将输入的字符若为字母则变为大写,非字母则不变,并临时存储到
temp。再判断temp是否存在于坏键中。若不存在则再判断+是否存在或原字符是否非大写从而输出。
代码
str1 = input()str2 = input()out = ''for s in str2:if s.lower():temp = s.upper()else:temp = sif temp not in str1:if ('+' not in str1) or (s<'A' or s>'Z'):out += sprint(out)
1034 有理数四则运算
题目
本题要求编写程序,计算 2 个有理数的和、差、积、商。
输入样例 1:
输入在一行中按照
a1/b1 a2/b2的格式给出两个分数形式的有理数,其中分子和分母全是整型范围内的整数,负号只可能出现在分子前,分母不为 0。
2/3 -4/2
输出样例 1:
分别在 4 行中按照
有理数1 运算符 有理数2 = 结果的格式顺序输出 2 个有理数的和、差、积、商。注意输出的每个有理数必须是该有理数的最简形式k a/b,其中k是整数部分,a/b是最简分数部分;若为负数,则须加括号;若除法分母为 0,则输出Inf。题目保证正确的输出中没有超过整型范围的整数。
2/3 + (-2) = (-1 1/3)2/3 - (-2) = 2 2/32/3 * (-2) = (-1 1/3)2/3 / (-2) = (-1/3)
输入样例 2:
5/3 0/6
输出样例 2:
1 2/3 + 0 = 1 2/31 2/3 - 0 = 1 2/31 2/3 * 0 = 01 2/3 / 0 = Inf
分析
使用欧几里得算法
gcd()计算最大公约数,函数fmt()格式化输出,yf()对分数进行约分
代码
def gcd(a, b): # 欧几里德算法计算最大公约数while a != 0:a, b = b % a, areturn bdef yf(nums): # 约分for num in nums:if num[0] == 0:num[0] = 0num[1] = 1else:k = gcd(abs(num[0]),num[1]) # 公约数if num[0] < 0:num[0] = - (abs(num[0])//k)else:num[0] = num[0]//knum[1] = num[1]//kdef fmt(m,n): # 格式化输出if m == "Inf":return mif m<0 and n<0:m = -mn = -na = 0 # 整数部分b = [] # 分数部分str1 = ""x = abs(m)y = abs(n)if x == 0:str1 = "0"else:a = x//yb = [x-a*y,y]if m<0 or n<0:if a == 0:str1 = "(-"+str(b[0])+"/"+str(b[1])+")"elif b[0] == 0:str1 = "(-"+str(a)+")"else:str1 = "(-"+str(a)+" "+str(b[0])+"/"+str(b[1])+")"else:if a == 0:str1 = str(b[0])+"/"+str(b[1])elif b[0] == 0:str1 = str(a)else:str1 = str(a)+" "+str(b[0])+"/"+str(b[1])return str1n = input().split()nums = []symbols = ['+','-','*','/']for i in n:nums.append([int(j) for j in i.split('/')])yf(nums)ret = []if nums[1][0] != 0:ret.append([nums[0][0]*nums[1][1] + nums[1][0]*nums[0][1], nums[0][1]*nums[1][1]])ret.append([nums[0][0]*nums[1][1] - nums[1][0]*nums[0][1], nums[0][1]*nums[1][1]])ret.append([nums[0][0]*nums[1][0], nums[0][1]*nums[1][1]])ret.append([nums[0][0]*nums[1][1], nums[0][1]*nums[1][0]])yf(ret)else:ret.append(nums[0])ret.append(nums[0])ret.append([0,0])ret.append(['Inf', 'Inf'])for i in range(4):s1 = fmt(nums[0][0], nums[0][1])s2 = fmt(nums[1][0], nums[1][1])r = fmt(ret[i][0], ret[i][1])print(f'{s1} {symbols[i]} {s2} = {r}')
1035 插入与归并
题目
根据维基百科的定义:
插入排序是迭代算法,逐一获得输入数据,逐步产生有序的输出序列。每步迭代中,算法从输入序列中取出一元素,将之插入有序序列中正确的位置。如此迭代直到全部元素有序。
归并排序进行如下迭代操作:首先将原始序列看成 N 个只包含 1 个元素的有序子序列,然后每次迭代归并两个相邻的有序子序列,直到最后只剩下 1 个有序的序列。
现给定原始序列和由某排序算法产生的中间序列,请你判断该算法究竟是哪种排序算法?
输入样例 1:
输入在第一行给出正整数 N (≤100);随后一行给出原始序列的 N 个整数;最后一行给出由某排序算法产生的中间序列。这里假设排序的目标序列是升序。数字间以空格分隔。
103 1 2 8 7 5 9 4 6 01 2 3 7 8 5 9 4 6 0
输出样例 1:
首先在第 1 行中输出
Insertion Sort表示插入排序、或Merge Sort表示归并排序;然后在第 2 行中输出用该排序算法再迭代一轮的结果序列。题目保证每组测试的结果是唯一的。数字间以空格分隔,且行首尾不得有多余空格。
Insertion Sort1 2 3 5 7 8 9 4 6 0
输入样例 2:
103 1 2 8 7 5 9 4 0 61 3 2 8 5 7 4 9 0 6
输出样例 2:
Merge Sort1 2 3 8 4 5 7 9 0 6
代码
参考:1035 插入与归并
def Isort(n,m):x = 0for i in range(1,len(n)):k = n[:i+1]k.sort()k.extend(n[i+1:])if x==1:return kif k==m:x = 1return Falsedef Msort(n,m):x = 0n = [[i] for i in n]while len(n)>1:k = []for j in range(0,len(n),2):try:n[j].extend(n[j+1])k.append(n[j])except:k.append(n[j])for i in k:i = i.sort()n = k[:]result = []for i in k:for l in i:result.append(l)if x==1:return resultif result==m:x = 1n = input()a = [int(i) for i in input().split()]b = [int(i) for i in input().split()]a1 = a[:]m = Isort(a,b)if m!=False:print("Insertion Sort")for i in range(len(m)-1):print(m[i],end=" ")print(m[i+1],end="")else:m = Msort(a1,b)print("Merge Sort")for i in range(len(m)-1):print(m[i],end=" ")print(m[i+1],end="")
1036 跟奥巴马一起编程
题目
美国总统奥巴马不仅呼吁所有人都学习编程,甚至以身作则编写代码,成为美国历史上首位编写计算机代码的总统。2014 年底,为庆祝“计算机科学教育周”正式启动,奥巴马编写了很简单的计算机代码:在屏幕上画一个正方形。现在你也跟他一起画吧!
输入样例:
输入在一行中给出正方形边长 N(3≤ N ≤20)和组成正方形边的某种字符 C,间隔一个空格。
10 a
输出样例:
输出由给定字符 C 画出的正方形。但是注意到行间距比列间距大,所以为了让结果看上去更像正方形,我们输出的行数实际上是列数的 50%(四舍五入取整)。
aaaaaaaaaaa aa aa aaaaaaaaaaa
分析
先求出总列数和总行数,再求出中间部分只输出头尾的行数(去掉头尾两行,即总行数-2),然后在头尾两行输出总列数个的字符,中间部分只输出头尾两列字符。
代码
col,c = input().split()col = int(col) # 列if col%2!=0: # 行row = col//2+1else:row = col//2row -= 2 # 中间部分行数print(col*c) # 第一行for i in range(row): # 中间部分print(f'{c}{" "*(col-2)}{c}')print(col*c) # 最后一行
1037 在霍格沃茨找零钱
题目
如果你是哈利·波特迷,你会知道魔法世界有它自己的货币系统 —— 就如海格告诉哈利的:“十七个银西可(Sickle)兑一个加隆(Galleon),二十九个纳特(Knut)兑一个西可,很容易。”现在,给定哈利应付的价钱 P 和他实付的钱 A,你的任务是写一个程序来计算他应该被找的零钱。
输入样例 1:
输入在 1 行中分别给出 P 和 A,格式为
Galleon.Sickle.Knut,其间用 1 个空格分隔。这里Galleon是 [0, 10] 区间内的整数,Sickle是 [0, 17) 区间内的整数,Knut是 [0, 29) 区间内的整数。
10.16.27 14.1.28
输出样例 1:
在一行中用与输入同样的格式输出哈利应该被找的零钱。如果他没带够钱,那么输出的应该是负数。
3.2.1
输入样例 2:
14.1.28 10.16.27
输出样例 2:
-3.2.1
分析
先转化为最小的
Knut来计算差值,然后将得到的值再转化为Galleon.Sickle.Knut,最后通过应付和实付的Galleon值来判断正负。
代码
P,A = input().split() # 应付P,实付APGalleon, PSickle, PKnut = P.split('.')AGalleon, ASickle, AKnut = A.split('.')Px = int(PGalleon)*17*29 + int(PSickle)*29 + int(PKnut)Ax = int(AGalleon)*17*29 + int(ASickle)*29 + int(AKnut)ret = abs(Ax - Px) # 差值retGalleon = ret//29//17 # Galleonret -= retGalleon*17*29retSickle = ret//29 # Sickleret -= retSickle*29retKnut = ret # Knutif Px>Ax: # 应付>实付,输出为负retGalleon = -retGalleonprint(f"{retGalleon}.{retSickle}.{retKnut}")
1038 统计同成绩学生
题目
本题要求读入N名学生的成绩,将获得某一给定分数的学生人数输出。
输入样例:
输入在第 1 行给出不超过 10 的正整数 N,即学生总人数。随后一行给出 N 名学生的百分制整数成绩,中间以空格分隔。最后一行给出要查询的分数个数 K(不超过 N 的正整数),随后是 K 个分数,中间以空格分隔。
1060 75 90 55 75 99 82 90 75 503 75 90 88
输出样例:
在一行中按查询顺序给出得分等于指定分数的学生人数,中间以空格分隔,但行末不得有多余空格。
3 2 0
分析
一开始想到的是字典,将需要查询的分数作为键,然后分数列表内每有一个与对应键相等,则其值加1,但是测试点3运行超时。后来考虑到统计的是分数,便构建了一个
0~100并初始化为0的列表,运行通过。
代码
n = input()scores = list(map(int, input().split())) # 分数check = list(map(int, input().split())) # 查询的分数count = [0 for i in range(101)] # 构造0~100的列表for score in scores:count[score] += 1for c in check[1:-1]:print(count[c],end=" ")print(count[check[-1]], end="")
1039 到底买不买
题目
小红想买些珠子做一串自己喜欢的珠串。卖珠子的摊主有很多串五颜六色的珠串,但是不肯把任何一串拆散了卖。于是小红要你帮忙判断一下,某串珠子里是否包含了全部自己想要的珠子?如果是,那么告诉她有多少多余的珠子;如果不是,那么告诉她缺了多少珠子。
为方便起见,我们用[0-9]、[a-z]、[A-Z]范围内的字符来表示颜色。例如在图1中,第3串是小红想做的珠串;那么第1串可以买,因为包含了全部她想要的珠子,还多了8颗不需要的珠子;第2串不能买,因为没有黑色珠子,并且少了一颗红色的珠子。
输入样例 1:
每个输入包含 1 个测试用例。每个测试用例分别在 2 行中先后给出摊主的珠串和小红想做的珠串,两串都不超过 1000 个珠子。
ppRYYGrrYBR2258YrR8RrY
输出样例 1:
如果可以买,则在一行中输出
Yes以及有多少多余的珠子;如果不可以买,则在一行中输出No以及缺了多少珠子。其间以 1 个空格分隔。
Yes 8
输入样例 2:
ppRYYGrrYB225YrR8RrY
输出样例 2:
No 2
分析
先定义两个变量存储摊主的珠串
x和想要的珠串y,然后遍历y。若想要的珠子不存在于x中,则记录下来,否则将该珠子从x中去除掉。最后count若不为0,则count的值便为缺少的珠子数,否则x便为剩下的多余珠子。
代码
x = list(input())y = list(input())count = 0for i in y:if i not in x:count += 1else:x.remove(i)if count:print(f'No {count}')else:print(f'Yes {len(x)}')
1040 有几个PAT
题目
字符串 APPAPT 中包含了两个单词 PAT,其中第一个 PAT 是第 2 位(P),第 4 位(A),第 6 位(T);第二个 PAT 是第 3 位(P),第 4 位(A),第 6 位(T)。现给定字符串,问一共可以形成多少个 PAT?
输入样例:
输入只有一行,包含一个字符串,长度不超过105,只包含
P、A、T三种字母。
APPAPT
输出样例:
在一行中输出给定字符串中包含多少个
PAT。由于结果可能比较大,只输出对 1000000007 取余数的结果。
2
代码
n = input()count_P = 0count_PA = 0count_PAT = 0for i in n:if 'P' == i:count_P += 1elif 'A' == i:count_PA += count_Pelse:count_PAT += count_PAprint(count_PAT % 1000000007)
1041 考试座位号
题目
每个 PAT 考生在参加考试时都会被分配两个座位号,一个是试机座位,一个是考试座位。正常情况下,考生在入场时先得到试机座位号码,入座进入试机状态后,系统会显示该考生的考试座位号码,考试时考生需要换到考试座位就座。但有些考生迟到了,试机已经结束,他们只能拿着领到的试机座位号码求助于你,从后台查出他们的考试座位号码。
输入样例:
输入第一行给出一个正整数 N(≤1000),随后 N 行,每行给出一个考生的信息:
准考证号 试机座位号 考试座位号。其中准考证号由 16 位数字组成,座位从 1 到 N 编号。输入保证每个人的准考证号都不同,并且任何时候都不会把两个人分配到同一个座位上。考生信息之后,给出一个正整数 M(≤N),随后一行中给出 M 个待查询的试机座位号码,以空格分隔。
43310120150912233 2 43310120150912119 4 13310120150912126 1 33310120150912002 3 223 4
输出样例:
对应每个需要查询的试机座位号码,在一行中输出对应考生的准考证号和考试座位号码,中间用 1 个空格分隔。
3310120150912002 23310120150912119 1
分析
分别用3个列表存储
准考证、试机号、考试号,然后通过遍历需要查询的试机号,从试机号列表中得到下标,然后通过下标从准考证列表和考试号列表中得到对应的值。
代码
n = int(input())nums = []shiji = []kaoshi = []for i in range(n):num,s,k = input().split()nums.append(num)shiji.append(s)kaoshi.append(k)m = int(input())checks = list(input().split())for check in checks: # 遍历需要查询的试机座位号,并得到其相应下标index = shiji.index(check)print(f'{nums[index]} {kaoshi[index]}')
1042 字符统计
题目
请编写程序,找出一段给定文字中出现最频繁的那个英文字母。
输入样例:
输入在一行中给出一个长度不超过 1000 的字符串。字符串由 ASCII 码表中任意可见字符及空格组成,至少包含 1 个英文字母,以回车结束(回车不算在内)。
This is a simple TEST. There ARE numbers and other symbols 1&2&3...........
输出样例:
在一行中输出出现频率最高的那个英文字母及其出现次数,其间以空格分隔。如果有并列,则输出按字母序最小的那个字母。统计时不区分大小写,输出小写字母。
e 7
分析
建立一个包含26个0的列表,用于存储记录26个字母出现的次数。然后遍历所输入的字符是否英文字母,若是则将其转化为小写,然后通过
ord()函数得到其ASCII码,再与a字母的ASCII码相减,得到的值作为下标,然后在前面记录字母次数的列表中对应的值+1作为记录,(如某个字符为'a',ord(a)-ord(a)=0,则列表中的第0位+1)。遍历完成后,通过max()函数得到列表中的最大值,再将最大值传入index()函数得到第一个最大值的下标,因为该列表是通过ASCII码记录字母出现次数的,所以若存在并列,index()返回的第一个最大值即为字母序最小的字母下标。最后再通过chr()函数将其转换为ASCII码。
代码
strs = input()alpha = list(0 for i in range(26)) # 记录26个字母出现次数for s in strs:if s.isalpha():s = s.lower()alpha[ord(s)-ord('a')] += 1 # 对应位置+1max_count = max(alpha) # 得到出现频率最高的次数max_index = alpha.index(max_count) # 通过最大值得到下标max_ascii = chr(97+max_index) # 将下标转换为ASCII码print(f'{max_ascii} {max_count}')
总结
ord() # 将字符转换成ASCII码chr() # 将ASCII码转换为字符List.index(value) # 返回value在List中第一次出现的下标
1043 输出PATest
题目
给定一个长度不超过 10 的、仅由英文字母构成的字符串。请将字符重新调整顺序,按 PATestPATest.... 这样的顺序输出,并忽略其它字符。当然,六种字符的个数不一定是一样多的,若某种字符已经输出完,则余下的字符仍按 PATest 的顺序打印,直到所有字符都被输出。
输入样例:
输入在一行中给出一个长度不超过 10 的、仅由英文字母构成的非空字符串。
redlesPayBestPATTopTeePHPereatitAPPT
输出样例:
在一行中按题目要求输出排序后的字符串。题目保证输出非空。
PATestPATestPTetPTePePee
分析
先求出
PATest分别在字符串中出现的次数并存于PATest_count,然后循环遍历PATest_count,当值不为0时,将PATest字符串中对应下标的字符加入到输出字符out中,且对应的值减1。若PATest_count内的值全为0时跳出循环并输出out。
代码
strs = input()PATest = 'PATest'out = ''PATest_count = list(map(lambda s:strs.count(s), PATest)) # 字符串中PATest分别出现的次数while PATest_count.count(0) != 6: # 当PATest_count全为0时跳出循环for index,num in enumerate(PATest_count):if num != 0:out += PATest[index]PATest_count[index] -= 1print(out)
1044 火星数字
题目
火星人是以 13 进制计数的:
- 地球人的 0 被火星人称为 tret。
- 地球人数字 1 到 12 的火星文分别为:jan, feb, mar, apr, may, jun, jly, aug, sep, oct, nov, dec
- 火星人将进位以后的 12 个高位数字分别称为:tam, hel, maa, huh, tou, kes, hei, elo, syy, lok, mer, jou
例如地球人的数字 29 翻译成火星文就是 hel mar;而火星文 elo nov 对应地球数字 115。为了方便交流,请你编写程序实现地球和火星数字之间的互译。
输入样例:
输入第一行给出一个正整数 N(<100),随后 N 行,每行给出一个 [0, 169) 区间内的数字 —— 或者是地球文,或者是火星文。
4295elo novtam
输出样例:
对应输入的每一行,在一行中输出翻译后的另一种语言的数字。
hel marmay11513
分析
进制转换问题,因为题目限定输入的数字范围为
0~169,所以转换时只需考虑个位和十位。先判断输入的是数字还是字符串。若为数字则先将其转换为13进制,然后从前面定义的转换列表中找到对应的值输出。若为字符串,则遍历并根据字符在转换列表中的下标来得到对应的13进制的数字,最后将数字转为10进制即可。
代码
low = ['tret', 'jan', 'feb', 'mar', 'apr', 'may', 'jun', 'jly', 'aug', 'sep', 'oct', 'nov', 'dec']high = ['','tam', 'hel', 'maa', 'huh', 'tou', 'kes', 'hei', 'elo', 'syy', 'lok', 'mer', 'jou']n = int(input())for i in range(n):words = input()out = ''if words.isdigit(): # 数字words = int(words)x = words // 13 # 十位y = words % 13 # 个位if x == 0: # 十位为0out += low[y]else: # 个位为0if y == 0:out += high[x]else:out = out + high[x] + ' ' + low[y]else:words = words.split()if len(words) == 1: # 只有1位if words[0] in low: # 只有1位个位out = low.index(words[0])else: # 只有1位十位out = high.index(words[0]) * 13else:out = high.index(words[0])*13 + low.index(words[1])print(out)
1045 快速排序
题目
著名的快速排序算法里有一个经典的划分过程:我们通常采用某种方法取一个元素作为主元,通过交换,把比主元小的元素放到它的左边,比主元大的元素放到它的右边。 给定划分后的 N 个互不相同的正整数的排列,请问有多少个元素可能是划分前选取的主元?
例如给定 N = 5, 排列是1、3、2、4、5。则:
- 1 的左边没有元素,右边的元素都比它大,所以它可能是主元;
- 尽管 3 的左边元素都比它小,但其右边的 2 比它小,所以它不能是主元;
- 尽管 2 的右边元素都比它大,但其左边的 3 比它大,所以它不能是主元;
- 类似原因,4 和 5 都可能是主元。
因此,有 3 个元素可能是主元。
输入样例:
输入在第 1 行中给出一个正整数 N(≤10); 第 2 行是空格分隔的 N 个不同的正整数,每个数不超过 10。
51 3 2 4 5
输出样例:
在第 1 行中输出有可能是主元的元素个数;在第 2 行中按递增顺序输出这些元素,其间以 1 个空格分隔,行首尾不得有多余空格。
31 4 5
分析
遍历列表,若当前元素比最大元素则添加进临时列表,并将当前元素设为最大元素。若当前元素比最大元素小,则从右往左遍历临时列表,如果存在比当前元素大的元素则删除。因为遍历原始列表时是从左往右的,若当前元素比前面已经添加进临时列表的元素小的话,则说明之前添加进临时列表的数存在右边的数比它小,所以该元素不是主元。 参考:1045 快速排序 Python实现
代码
n = int(input())nums = list(map(int, input().split()))pivots = []max_num = 0for num in nums:if num > max_num:pivots.append(num)max_num = numelse:for i in range(len(pivots)-1,-1,-1):if pivots[i] >= num:del pivots[i]else:breakpivots.sort()print(len(pivots))if len(pivots)!=0:for p in pivots[:-1]:print(p,end=" ")print(pivots[-1])else:print("")
1046 划拳
题目
划拳是古老中国酒文化的一个有趣的组成部分。酒桌上两人划拳的方法为:每人口中喊出一个数字,同时用手比划出一个数字。如果谁比划出的数字正好等于两人喊出的数字之和,谁就赢了,输家罚一杯酒。两人同赢或两人同输则继续下一轮,直到唯一的赢家出现。
下面给出甲、乙两人的划拳记录,请你统计他们最后分别喝了多少杯酒。
输入样例:
输入第一行先给出一个正整数 N(≤100),随后 N 行,每行给出一轮划拳的记录,格式为:
甲喊 甲划 乙喊 乙划
其中
喊是喊出的数字,划是划出的数字,均为不超过 100 的正整数(两只手一起划)。
58 10 9 125 10 5 103 8 5 1212 18 1 134 16 12 15
输出样例:
在一行中先后输出甲、乙两人喝酒的杯数,其间以一个空格分隔。
1 2
分析
只需计算出每局的两人所喊数之和,再分别与两人所划进行比较,当满足只有一个人所划的数字与两人喊数的和相等,则另一个人需要喝的酒数+1。
代码
n = int(input())jia = 0yi = 0for i in range(n):nums = list(map(int, input().split()))sum_num = nums[0] + nums[2] # 甲乙喊的和# print(sum_num)if nums[1] == sum_num and nums[3]!=sum_num: # 甲赢yi += 1elif nums[1] != sum_num and nums[3]==sum_num: # 乙赢jia += 1else:continueprint(jia,yi)
1047 编程团体赛
题目
编程团体赛的规则为:每个参赛队由若干队员组成;所有队员独立比赛;参赛队的成绩为所有队员的成绩和;成绩最高的队获胜。
现给定所有队员的比赛成绩,请你编写程序找出冠军队。
输入样例:
输入第一行给出一个正整数 N(≤10),即所有参赛队员总数。随后 N 行,每行给出一位队员的成绩,格式为:
队伍编号-队员编号 成绩,其中队伍编号为 1 到 1000 的正整数,队员编号为 1 到 10 的正整数,成绩为 0 到 100 的整数。
63-10 9911-5 87102-1 0102-3 10011-9 893-2 61
输出样例:
在一行中输出冠军队的编号和总成绩,其间以一个空格分隔。注意:题目保证冠军队是唯一的。
11 176
分析
使用字典存储
队伍编号-成绩键值对,并通过max()函数得到字典最大值的键并输出。
代码
n = int(input())dic = {} # 存放成绩for i in range(n):data = input().split()score = int(data[1]) # 成绩nums = data[0].split('-')team = int(nums[0]) # 队伍编号if team in dic:dic[team] += scoreelse:dic[team] = scoremax_team = max(dic,key=dic.get)print(f'{max_team} {dic[max_team]}')
1048 数字加密
题目
本题要求实现一种数字加密方法。首先固定一个加密用正整数 A,对任一正整数 B,将其每 1 位数字与 A 的对应位置上的数字进行以下运算:对奇数位,对应位的数字相加后对 13 取余——这里用 J 代表 10、Q 代表 11、K 代表 12;对偶数位,用 B 的数字减去 A 的数字,若结果为负数,则再加 10。这里令个位为第 1 位。
输入样例:
输入在一行中依次给出 A 和 B,均为不超过 100 位的正整数,其间以空格分隔。
1234567 368782971
输出样例:
在一行中输出加密后的结果。
3695Q8118
分析
先将列表反转,计算完后再将需要输出的字符串反转。需要注意的是两个长度可能不等,需要通过补0使多余的位数正常输出。
代码
s = input().split()A = s[0][::-1]B = s[1][::-1]out = ''jqk = ['J', 'Q', 'K']length = max([len(A), len(B)])if len(A) >= len(B):B += '0' * (len(A)-len(B))else:A += '0' * (len(B)-len(A))for i in range(length):if (i+1) % 2 != 0: # 奇数位char = (int(A[i])+int(B[i])) % 13if char < 10:out += str(char)else:out += jqk[char-10]else: # 偶数位char = int(B[i])-int(A[i])if char >= 0:out += str(char)else:out += str(char+10)print(out[::-1])
1049 数列的片段和
题目
给定一个正数数列,我们可以从中截取任意的连续的几个数,称为片段。例如,给定数列 { 0.1, 0.2, 0.3, 0.4 },我们有 (0.1) (0.1, 0.2) (0.1, 0.2, 0.3) (0.1, 0.2, 0.3, 0.4) (0.2) (0.2, 0.3) (0.2, 0.3, 0.4) (0.3) (0.3, 0.4) (0.4) 这 10 个片段。
给定正整数数列,求出全部片段包含的所有的数之和。如本例中 10 个片段总和是 0.1 + 0.3 + 0.6 + 1.0 + 0.2 + 0.5 + 0.9 + 0.3 + 0.7 + 0.4 = 5.0。
输入样例:
输入第一行给出一个不超过 10 的正整数 N,表示数列中数的个数,第二行给出 N 个不超过 1.0 的正数,是数列中的数,其间以空格分隔。
40.1 0.2 0.3 0.4
输出样例:
在一行中输出该序列所有片段包含的数之和,精确到小数点后 2 位。
5.00
分析
网上看到的规律:第一个数出现n次,其余的数是
(前一个数的出现次数+n-2*(该数在序列中的位置))。所以只需要用一个数组存储每个数出现的次数,然后将每个数乘以出现次数,再相加,即为总和。
代码
n = int(input())nums = list(map(float, input().split()))count = []nums_sum = 0for i in range(n):if i == 0:count.append(n)else:temp = count[i-1] + n - 2*icount.append(temp)for i in range(n):nums_sum += nums[i] * count[i]print("%.2f" % nums_sum)

若有收获,就点个赞吧
0 人点赞

{kind=link}