之前一直使用Typora+各种博客(Wordpress/Hexo/Typecho)来进行笔记和写作,后来接触并爱上了语雀,主要是贴图太方便了。(使用Typora的时候会搭配PicGo+云存储,但是有时候会粘贴了多余的图片或者想替换已有图片时,懒得打开云存储进行删除,久而久之就忘了,造成了一定的空间浪费。)
刚开始用语雀的时候还特地看了下,可以导出md格式的文章。但最近想批量导出知识库时,发现只能选择PDF或者语雀特定的格式,感觉不大放心。于是弄了个脚本通过语雀官方API导出了全部文章,并开始寻找本地存储的笔记软件。
结合个人情况进行筛选后发现Obsidian比较适合,但是由于一开始不会用,不会怎么处理图片路径的问题。语雀是没有目录这个概念的,所以导出的文章都放到了一起,然后图片等资源也统一放到了文章目录中的某一目录。而这也导致了如果我在Obsidian里通过建立多级文件夹的方式来分类文章,那么所有图片链接都要进行改动,差点弃坑了。还好在B站看了关于ob的视频,学到了通过索引的方式来进行管理
语雀文章导出
- 基于ExportMD进行了一些小改动,修复部分Bug以及适配Obsidian
- 使用方法:
- NameSpace:访问语雀个人主页
https://www.yuque.com/<xxx>中的xxx部分 - Token:访问语雀Token新建,只需要给读取权限即可。
```shell
$ python3 ExportMD.py
请输入语雀namespace: xxx 请输入语雀Token: xxx
- NameSpace:访问语雀个人主页
- `ExportMD.py`完整代码,感谢 [@杜大哥](https://github.com/dzh929/ExportMD-rectify-pics) 协助修复```python# -*- coding: UTF-8 -*-from prettytable import PrettyTableimport reimport osimport aiohttpimport asynciofrom urllib import parsefrom PyInquirer import prompt, Separatorfrom examples import custom_style_2from colr import colorfrom cfonts import render, sayclass ExportMD:def __init__(self):self.repo_table = PrettyTable(["知识库ID", "名称"])self.namespace, self.Token = self.get_UserInfo()self.headers = {"Content-Type": "application/json","User-Agent": "ExportMD","X-Auth-Token": self.Token}self.repo = {}self.export_dir = './yuque'def print_logo(self):output = render('ExportMD', colors=['red', 'yellow'], align='center')print(output)# 语雀用户信息def get_UserInfo(self):f_name = ".userinfo"if os.path.isfile(f_name):with open(f_name, encoding="utf-8") as f:userinfo = f.read().split("&")else:namespace = input("请输入语雀namespace:")Token = input("请输入语雀Token:")userinfo = [namespace, Token]with open(f_name, "w") as f:f.write(namespace + "&" + Token)return userinfo# 发送请求async def req(self, session, api):url = "https://www.yuque.com/api/v2" + api# print(url)async with session.get(url, headers=self.headers) as resp:result = await resp.json()return result# 获取所有知识库async def getRepo(self):api = "/users/%s/repos" % self.namespaceasync with aiohttp.ClientSession() as session:result = await self.req(session, api)for repo in result.get('data'):repo_id = str(repo['id'])repo_name = repo['name']self.repo[repo_name] = repo_idself.repo_table.add_row([repo_id, repo_name])# 获取一个知识库的文档列表async def get_docs(self, repo_id):api = "/repos/%s/docs" % repo_idasync with aiohttp.ClientSession() as session:result = await self.req(session, api)docs = {}for doc in result.get('data'):title = doc['title']slug = doc['slug']docs[slug] = titlereturn docs# 获取正文 Markdown 源代码async def get_body(self, repo_id, slug):api = "/repos/%s/docs/%s" % (repo_id, slug)async with aiohttp.ClientSession() as session:result = await self.req(session, api)body = result['data']['body']body = re.sub("<a name=\".*\"></a>","", body) # 正则去除语雀导出的<a>标签body = re.sub(r'\<br \/\>!\[image.png\]',"\n![image.png]",body) # 正则去除语雀导出的图片后紧跟的<br \>标签body = re.sub(r'\)\<br \/\>', ")\n", body) # 正则去除语雀导出的图片后紧跟的<br \>标签return body# 选择知识库def selectRepo(self):choices = [{"name": repo_name} for repo_name, _ in self.repo.items()]choices.insert(0, Separator('=== 知识库列表 ==='))questions = [{'type': 'checkbox','qmark': '>>>','message': '选择知识库','name': 'repo','choices': choices}]repo_name_list = prompt(questions, style=custom_style_2)return repo_name_list["repo"]# 创建文件夹def mkDir(self, dir):isExists = os.path.exists(dir)if not isExists:os.makedirs(dir)# 获取文章并执行保存async def download_md(self, repo_id, slug, repo_name, title):""":param repo_id: 知识库id:param slug: 文章id:param repo_name: 知识库名称:param title: 文章名称:return: none"""body = await self.get_body(repo_id, slug)new_body, image_list = await self.to_local_image_src(body)if image_list:# 图片保存位置: .yuque/<repo_name>/assets/<filename>save_dir = os.path.join(self.export_dir, repo_name, "assets")self.mkDir(save_dir)async with aiohttp.ClientSession() as session:await asyncio.gather(*(self.download_image(session, image_info, save_dir) for image_info in image_list))self.save(repo_name, title, new_body)print(" %s 导出成功!" % color(title, fore='green', style='bright'))# 将md里的图片地址替换成本地的图片地址async def to_local_image_src(self, body):body = re.sub(r'\<br \/\>!\[image.png\]',"\n![image.png]",body) # 正则去除语雀导出的图片后紧跟的<br \>标签body = re.sub(r'\)\<br \/\>', ")\n", body) # 正则去除语雀导出的图片后紧跟的<br \>标签pattern = r"!\[(?P<img_name>.*?)\]" \r"\((?P<img_src>https:\/\/cdn\.nlark\.com\/yuque.*\/(?P<slug>\d+)\/(?P<filename>.*?\.[a-zA-z]+)).*\)"repl = r""images = [_.groupdict() for _ in re.finditer(pattern, body)]new_body = re.sub(pattern, repl, body)return new_body, images# 下载图片async def download_image(self, session, image_info: dict, save_dir: str):img_src = image_info['img_src']filename = image_info["filename"]async with session.get(img_src) as resp:with open(os.path.join(save_dir, filename), 'wb') as f:f.write(await resp.read())# 保存文章def save(self, repo_name, title, body):# 将不能作为文件名的字符进行编码def check_safe_path(path: str):for char in r'/\<>?:"|*':path = path.replace(char, parse.quote_plus(char))return pathrepo_name = check_safe_path(repo_name)title = check_safe_path(title)save_path = "./yuque/%s/%s.md" % (repo_name, title)with open(save_path, "w", encoding="utf-8") as f:f.write(body)async def run(self):self.print_logo()await self.getRepo()repo_name_list = self.selectRepo()self.mkDir(self.export_dir) # 创建用于存储知识库文章的文件夹# 遍历所选知识库for repo_name in repo_name_list:dir_path = self.export_dir + "/" + repo_name.replace("/", "%2F")dir_path.replace("//", "/")self.mkDir(dir_path)repo_id = self.repo[repo_name]docs = await self.get_docs(repo_id)await asyncio.gather(*(self.download_md(repo_id, slug, repo_name, title) for slug, title in docs.items()))print("\n" + color('导出完成!', fore='green', style='bright'))print("已导出到:" + color(os.path.realpath(self.export_dir), fore='green', style='bright'))if __name__ == '__main__':export = ExportMD()loop = asyncio.get_event_loop()loop.run_until_complete(export.run())
可能出现的报错
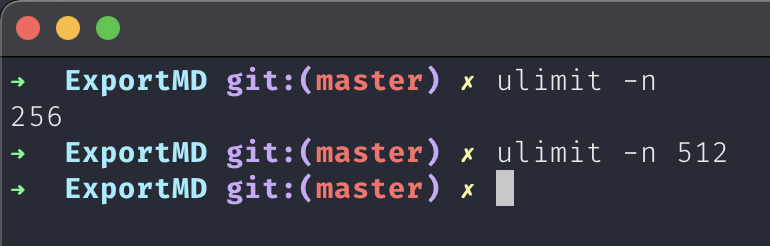
- 运行脚本时出现如下错误:

- 原因是默认的最大打开文件数不够,修复方法: ```shell $ ulimit -n # 查看当前最大打开数文件 $ ulimit -n 512 # 设置多一点
<a name="cIIQ1"></a>## 建立索引> 这里以语雀目录为内容,批量添加`obsidian`的内链格式`[[xxx]]`,以建立索引- 先复制语雀全部文档的标题,然后利用以下脚本批量添加内链格式,最后根据情况进行手动调整。```python# -*- coding: UTF-8 -*-file = "list.txt"new_file = "list2.txt"datas = []with open(file, "r") as f:lines = f.readlines()for line in lines:data = "[[" + line.strip() + "]]"datas.append(data)with open(new_file, "w") as f2:for line in datas:f2.writelines(line + "\n")
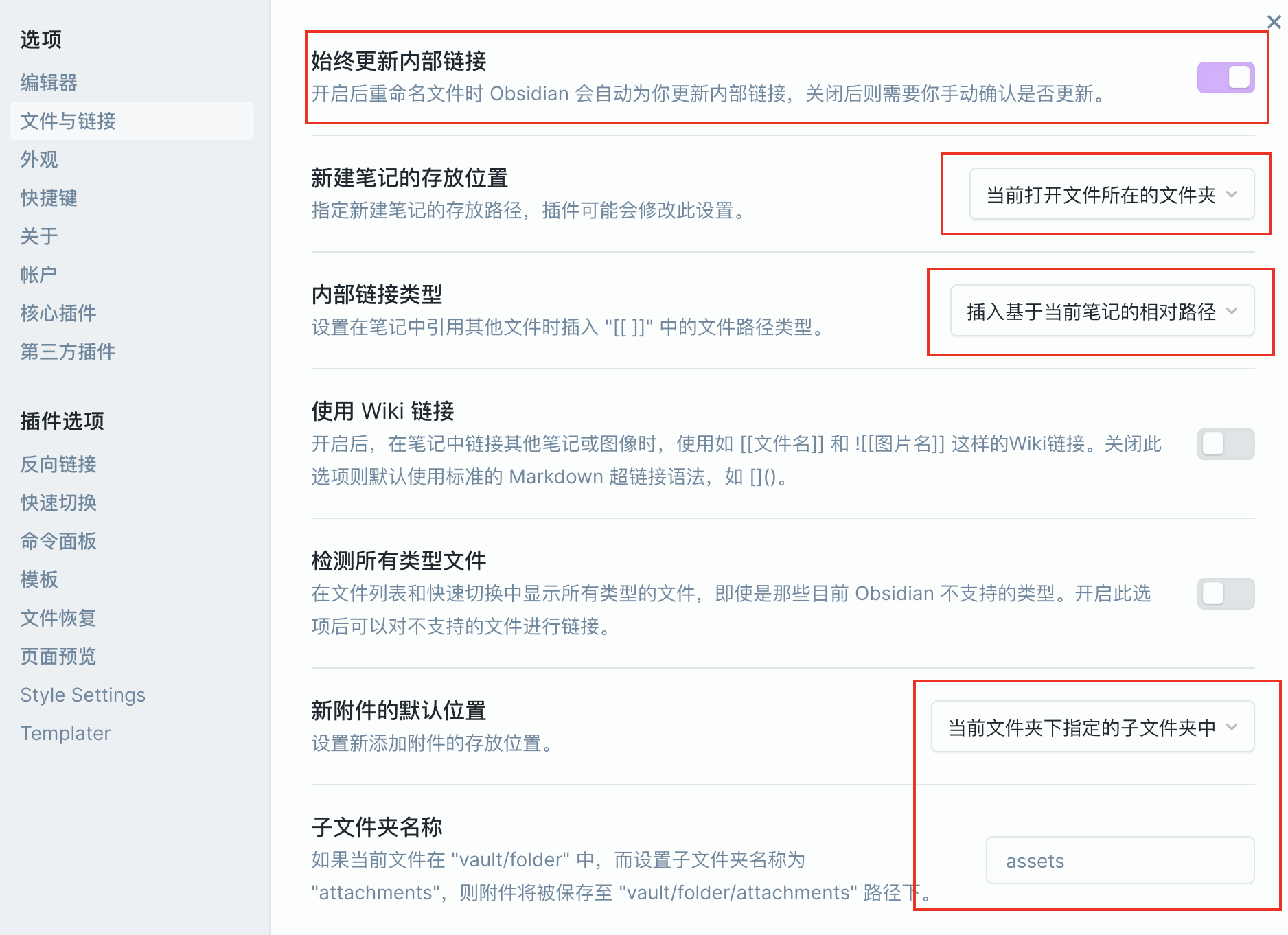
- obsidian一些配置

若有收获,就点个赞吧
0 人点赞
