1.URL解析
先进行 URL 解析,看看输入的内容是否符合 URL 规则(解析 URL 提取出协议、域名、端口号,对于一些特殊字符,在传递的时候需要进行编码解码)。
- encodeURI、decodeURI可以对中文、空格等编码解码,适用于 URL 本身
- encodeURIComponent、decodeURIComponent范围更广,会编码解码一些特殊字符如 :/?=+@#$,适用于给参数编码解码
2.缓存检查
URL 符合规则,浏览器进程会通过进程通信将 URL 请求发送给网络进程
- 通过Cache-Control和Expires来检查是否命中强缓存,命中则直接取本地磁盘的html(状态码为200 from disk(or memory) cache,内存or磁盘);
- 如果没有命中强缓存,则会向服务器发起请求(先进行下一步的TCP连接),服务器通过Etag和Last-Modify来与服务器确认返回的响应是否被更改(协商缓存),若无更改则返回状态码(304 Not Modified),浏览器取本地缓存;
-
3.DNS 解析
网络请求第一步就是先进行 DNS 解析,获取请求域名服务器的 IP 地址。
什么是 DNS 解析,每台计算机都有一个唯一 IP 地址,但是 IP 地址不方便记忆,所以采用更方便记忆的网址去查找其他计算机,将网址转换成 IP 地址的过程就是 DNS 解析。
域名解析是一个递归查询 + 迭代查询的过程。 浏览器缓存,向浏览器的缓存中读取上一次的访问记录
- 操作系统的缓存,查找存储在系统运行内存中的缓存
- 在 host 文件中查找
- 路由器缓存:有些路由器会把访问过的域名存在路由器上
- ISP互联网服务提供商缓存,比如 114.114.114.114,
- 缓存中找不到,则本地 DNS 服务器进行迭代查询:. 根 DNS 服务器 -> .com 顶级服务器 -> 主域名服务器 -> …,直到服务器返回对应的 IP
DNS 负载均衡:
网站对应的 IP 不止一个,DNS 可以根据每台机器的负载量、距离用户的距离等返回一个合适的服务器 IP 给用户 这个过程就是 DNS 负载均衡,又叫做 DNS 重定向。 CDN 就是利用 DNS 的重定向技术, DNS 会返回一个用户最接近的点的 IP 给用户。
4.TCP 连接三次握手
拿到 IP 后,(检查当前域名是否达到 TCP 连接上限),通过三次握手进行 TCP 连接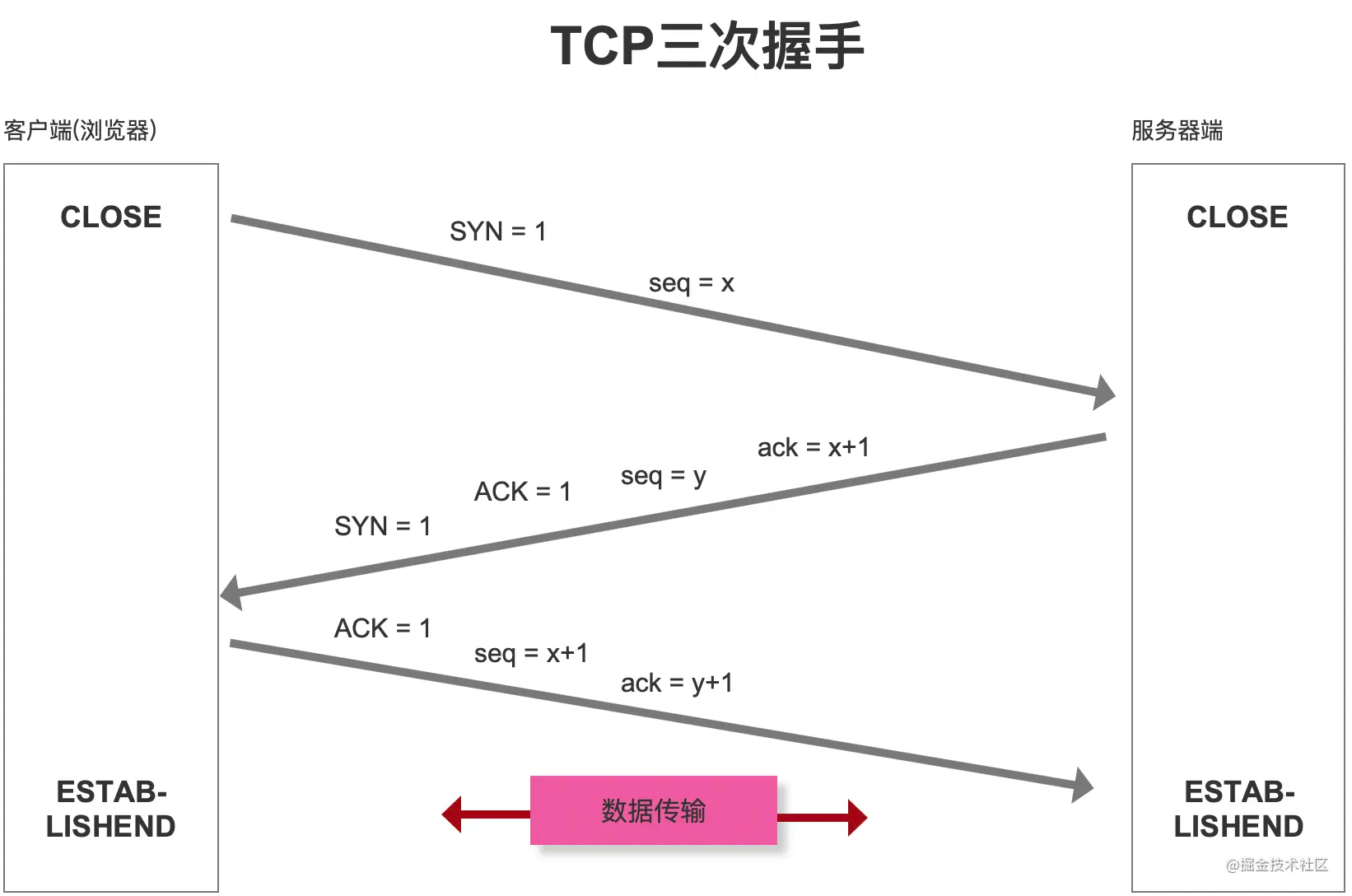
三次握手:
- 第一次:客户端发送 SYN 包和初始序号 seq = x 给服务端,此时客户端状态为 SYN-SENT
- 第二次:服务端收到 SYN 包后,将标识位 SYN 和 ACK 置为1,确认序号 ack = x + 1, 初始序号 seq = y 发送给客户端,此时服务端状态为 SYN-RECEIVED
- 第三次:客户端收到后,将标识位 ACK 置为1, 确认序号 ack = y + 1, 自己的序号 seq = x + 1, 发送给服务端,服务端收到后也将状态切换为 ESTABLISHED
三次握手抽象版:
- 客户端:你是服务端吗
- 服务端:是的,我是服务端,你是客户端吗
- 客户端:是的,我是客户端
- seq序号,用来标识从TCP源端向目的端发送的字节流,发起方发送数据时对此进行标记
- ack确认序号,只有ACK标志位为1时,确认序号字段才有效,ack=seq+1
标识位:
- ACK:确认标识,用于表示对数据包的成功接收。
- SYN:同步标识,表示 TCP 连接已初始化,发起一个新连接。
- FIN:完成标识,释放一个连接,用于拆除上一个 SYN 标识。一个完整的TCP连接过程一定会有 SYN 和 FIN 包。
为什么不能两次握手?
TCP 的特点的可靠传输,服务端和客户端都需要可靠传输,就需要确认双方的发送和接收能力,第一次握手确认了客户端的发送能力,第二次确认了服务端的发送和接收能力,第三次确认了客户端的接收能力
两次握手,服务器不能确定客户端已经收到了确认请求,不能确认是否建立好了连接。服务器认为建立好了连接,发送数据包,结果发的包客户端没收到,那么攻击服务器就很容易了,只发包不收包。
TCP 和 UDP 的区别:
- TCP 是一个面向连接的、可靠的、基于字节流的传输层协议,TCP 会精准记录哪些数据发送了,哪些数据被对方接收了,哪些没有被接收到,而且保证数据包按序到达,不允许半点差错。这是有状态, 当意识到丢包了或者网络环境不佳,TCP 会根据具体情况调整自己的行为,控制自己的发送速度或者重发。这是可控制。
- UDP 是一个面向无连接的传输层协议,无状态、不可控。
5.HTTP请求
TCP 连接建立之后,浏览器端会构建请求行、 请求头等信息,并把和该域名相关的 Cookie 等数据附加到请求头中,然后向服务器发送构建的请求信息。如果是 HTTPS,还需要进行 TSL 协商。
服务器检查 HTTP 请求头是否包含缓存验证信息进行协商缓存:
协商缓存
Last-Modified 和 If-Modified-Since:
Last_Modified 表示本地文件的最后修改时间,If-Modified-Since 会将 Last-Modified 的值发送给服务器询问该资源是否有更新,如果有更新就会将新的资源发送回来,否则返回 304 状态码,代表资源无更新,继续使用缓存文件。
Last-Modified 弊端:
- 如果文件只是被打开,没有修改,也会造成 Last-Modified 修改,服务器不能命中缓存。
- 只能以秒计时,如果在毫秒级的时间内修改了文件,服务器 Last-Modified 的值并不会修改,会返回304,浏览器就会是自己的缓存 。
ETag 和 If-No-Match
ETag 是文件指纹,If-No-Match 会将 ETag 发送给服务器,查询该资源 ETag 是否变动,有变动的话就将新的资源发送回来。ETag 优先级高于 Last-Modified。
启发式缓存
如果什么缓存都没设置,浏览器通常会响应头中的 Date 减去 Last-Modified 值的 10% 作为缓存时间。
状态码
状态码用于表示服务器对请求的处理结果
- 1xx:指示信息——表示请求已经接受,继续处理
- 100 Continue 一般在发送 post 请求时,已发送了 http header 之后服务端返回此信息,表示确认,之后发送具体参数信息。
- 2xx:成功
- 200 OK 正常返回信息
- 201 Created 请求成功并且服务器创建了新的资源
- 202 Accepted 服务器已接受请求,但尚未处理
- 3xx:重定向
- 301 Moved Permanently 永久重定向
- 302 Found 临时重定向
- 303 See Other 临时重定向,且总是使用 GET 请求新的 URI
- 304 Not Modified 请求内容未改动,走缓存
- 4xx:客户端错误
- 400 Bad Request 服务器无法理解请求格式
- 401 Unauthorized 请求未授权
- 403 Forbidden 禁止访问
- 404 Not Found 找不到与 URI 相匹配的资源
- 5xx:服务器错误。
http1.0 中默认 Connection 并不是 keep-alive,需要手动处理,但是 HTTP1.1 之后,Connection:keep-alive 已经被列入了规范,现在基本都是默认就是长连接,前提是同一个源,向不同源发送请求要重新建立通道。
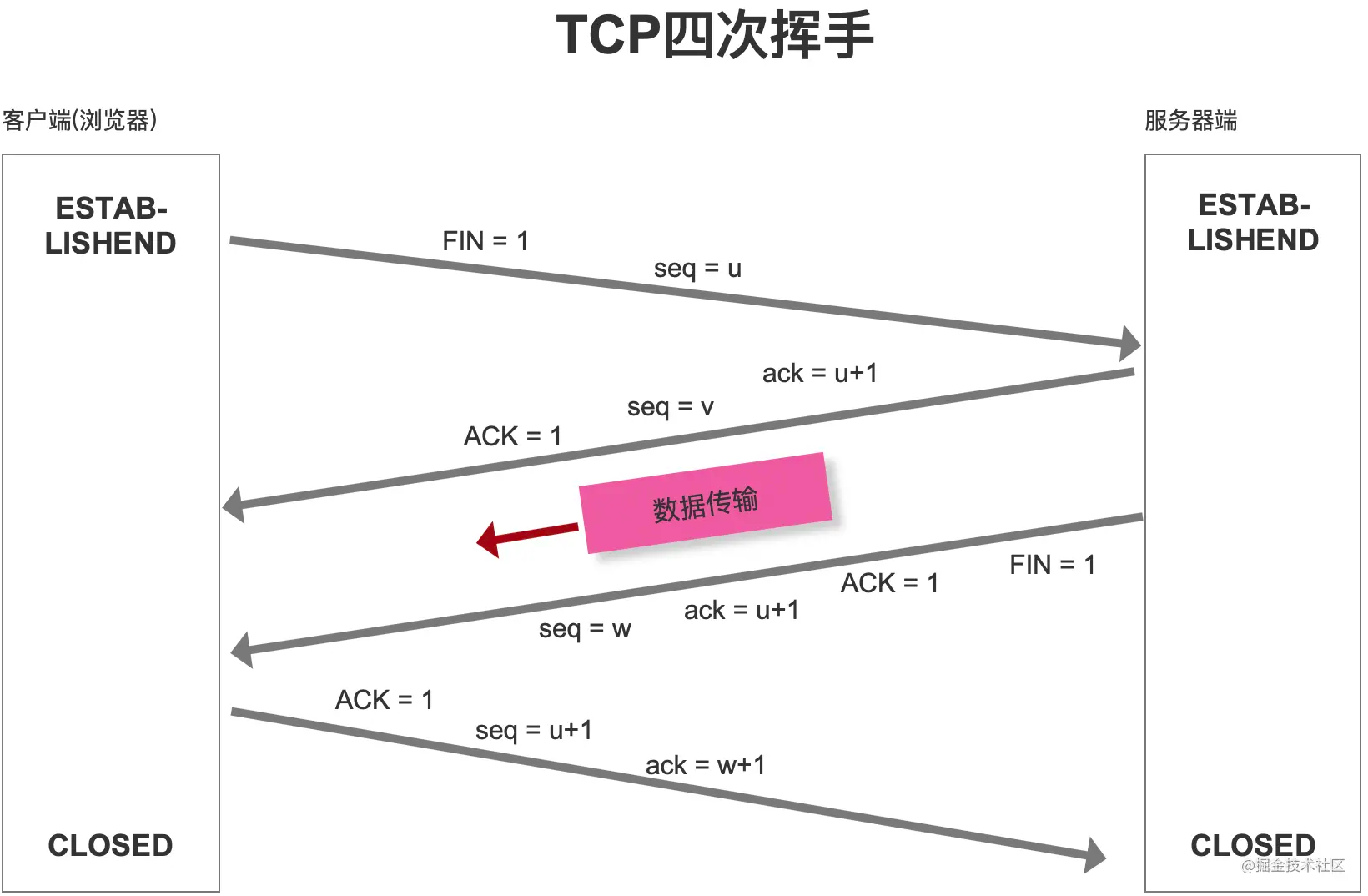
四次挥手:
- 第一次:客户端主动关闭放发送一个 FIN,用来关闭客户端到服务端的数据传输,告诉服务端我不会给你发送数据了
- 第二次:服务端收到 FIN 包后,发送一个 ACK 给客户端,确认序号为收到序号 + 1
- 第三次:服务端发送完数据后,服务端发送一个 FIN,用来关闭服务端到客户端的数据传输,告诉客户端我不会给你发数据了
- 第四次:客户端收到 FIN 后,发送一个 ACK 给服务端,确认序号为收到序号 + 1,完成四次挥手
四次挥手抽象版:
- 客户端:服务端,我要和你断开连接
- 服务端:好的,断吧
- 服务端:我也要和你断开连接
- 客户端:好的,断吧
四次握手后,客户端还会等待 2MSL(MSL:最长报文段寿命,一般2min) 的时间,为了保证客户端发送的 ACK 报文能够到达服务器,因为这个报文可能会丢失,服务器收不到确认会超时重传 FIN + ACK 报文段,客户端能在 2MSL 时间内收到这个重传的报文段,然后客户端重新确认。
为什么连接的时候是三次握手,关闭的时候却是四次挥手?
- 服务端接收到客户端的 SYN 连接请求报文后,可以直接发送 SYN + ACK 报文
但是关闭连接时,当服务端接收到 FIN 报文时,很可能并不会立即关闭连接,所以只能先回复一个 ACk 报文,告诉客户端你发的 FIN 报文我收到了,只有等服务端所有的报文发送完了,我才能发送 FIN 报文,因此不能一起发送,所以需要四次。
7.浏览器解析资源
浏览器拿到资源会根据资源类型进行处理,比如是 gzip 压缩后的文件则进行解压缩,如果响应头 Content-type 为 text/html,则开始解析 HTML
HTML Parser 对 HTML 文件进行处理,根据 HTML 标记关系构建 DOM 树。 - 解析过程中遇到图片、link、script会启动下载。 - script标签会阻塞 DOM 树的构建,所以一般将 script 放在底部,或者添加 async 、defer 标识。 - css 下载时异步,不会阻塞浏览器构建 DOM 树,但是会阻塞渲染,在构建布局树时,会等待 css 下载解析完毕后才进行。
- 渲染引擎将 CSS 样式表转化为浏览器可以理解的 styleSheets,转换样式表中的属性使其标准化em => px; bold => 700。
- 根据 DOM 树和 styleSheets 构建布局树,计算出元素的布局信息,display: none不可见节点以及 head 这种不可见标签不会插入到布局树里
- 构建 DOM 树、构建 CSSOM 树、构建树并不是严格的先后顺序,为了让用户能尽快看到网页内容,都是并行推进的
- 对布局树进行分层,生成图层树。
- position: fixed/absolute、z-index:2、filter: blue(5px)、opacity: .5等拥有层叠上下文属性的元素会进行分层、或者内容需要裁减
- 绘制图层需要一个个绘制指令,渲染线程将包含绘制指令的绘制列表提交给合成线程,绘制操作是由合成线程来完成的
- 合成线程将图层划分为一个个图块,优先处理靠近视口的图块,对其进行栅格化处理生成位图
- 通常,栅格化过程会采用 GPU 加速生成,渲染进程把生成图块的指令发送给 GPU 进程,GPU 生成最终的位图并保存在内存之中
- 一旦所有图块都被光栅化,合成线程向浏览器进程提交一个绘制图块的命令,将其内容绘制到内存之中,最后显示在屏幕上
优化
- 尽早的把 CSS 下载到客户端,充分利用 HTTP 多请求并发机制,且 CSS 下载并不会阻塞渲染,style、link、@import 放到页面顶部
- 避免 JS 加载阻塞渲染,添加 async、defer 标识,标签放到页面底部
- 减少 DOM 的回流和重绘
async 和 defer 都是异步的,使用 async 标志的脚本文件一旦加载完成,会立即执行;而使用了 defer 标记的脚本文件,需要在 DOMContentLoaded 事件之前执行。
重绘:元素样式的改变,但是宽高、大小、位置等不变,比如:color、background、visibility 等
回流:元素的大小或者位置发送了变化,触发了页面的重新布局,甚至调用方法或属性getComputedStyle、clientWidth,为了保证得到的结果是即使性和准确性,导致布局树重新计算布局和渲染。
优化策略:
- 减少回流范围:避免使用 table 布局,因为一个小改动可能会造成整个 table 的重新布局
- 避免逐条改变样式,使用类名去合并样式
- 使用 documentFragment 操作 dom,操作完成后再添加到文档中
- 避免频繁读取会引发回流/重绘的属性,如果确实需要多次使用,就用一个变量缓存起来。
- 动画效果应用到 position 属性为 absolute、fixed 元素上,脱离文档流,单独渲染区域
- CSS3 硬件加速, transform、opacity 等属性会触发 GPU 加速,不会引发回流和重绘,但是过多使用可能会占用大量内存,性能消耗严重
现代浏览器会自己缓存一个 flush 队列,然后一次性清空。
性能优化
DNS 优化
DNS 预解析
- 采用 CDN,DNS 负载均衡
网络连接优化
- 分服务器部署,区分 web 服务器、资源服务器、数据服务器,增加 HTTP 并发性
减少 TCP 的三次握手和四次挥手:HTTP1.1默认开启的 Connection: keep-alive
数据缓存
对于静态资源文件实现强缓存和协商缓存
-
数据传输
减少数据传输的大小
- 利用工具如 webpack 对传输内容进行压缩
- 服务端开发 GZIP 压缩,一般能压缩 60% 左右
- 大批量数据分批次请求,下拉刷新,分页
- 减少 HTTP 请求的次数
- 资源文件合并处理
- 小图片转成 base64,但是可能会造成图片大小增加 1/3
采用 HTTP2.0
HTTP1.1 虽然在串行请求可以通过 Connection: keep-alive 复用同一个 TCP 连接,如果是并行发送多个请求,会建立多个连接,但是浏览器一般限制会限制同一域名下最多同时可以建立6个连接。
- 请求阻塞:在并发请求达最大限制时,请求必须等到上一个请求完成后,才可以复用这个 TCP 发出下一个请求,所以会受到前面请求的阻塞。
- 线头阻塞:请求响应的顺序必须和请求发送的顺序一致,如果后发送的请求响应完成了,也要等前面的阻塞的请求返回。
多路复用:允许同时通过单一的 HTTP2.0 连接发起的多重请求 - 响应消息,连接通道是共享的
HTTP2.0 的传输是基于二进制帧的,每个 TCP 连接中,都有多个双向流通的流,每个流都有独一无二的标识和优先级,而流就是由二进制帧组成的。二进制帧会标识自己是属于哪个流的,所以这些流可以交错传输,在接收端根据帧头组装成完整的信息,解决线头堵塞的问题。
头部压缩:HTTP1.x 的 header 中带有大量的信息,每次都要重复发送,HTTP2.0 使用 HPACK 算法对 header 数据进行压缩,减少需要传输的 header 大小,通讯双方各自缓存一个头部字典表,可以差异化更新头部,减少需要传输数据的大小
参考文章

若有收获,就点个赞吧
0 人点赞
