梳理主干
- 从浏览器接收url到开启网络请求线程(这一部分可以展开浏览器的机制以及进程与线程之间的关系)
- 开启网络线程到发出一个完整的http请求(这一部分涉及到dns查询,tcp/ip请求,五层因特网协议栈等知识)
- 从服务器接收到请求到对应后台接收到请求(这一部分可能涉及到负载均衡,安全拦截以及后台内部的处理等等)
- 后台和前台的http交互(这一部分包括http头部、响应码、报文结构、cookie等知识,可以提下静态资源的cookie优化,以及编码解码,如gzip压缩等)
- 单独拎出来的缓存问题,http的缓存(这部分包括http缓存头部,etag,catch-control等)
- 浏览器接收到http数据包后的解析流程(解析html-词法分析然后解析成dom树、解析css生成css规则树、合并成render树,然后layout、painting渲染、复合图层的合成、GPU绘制、外链资源的处理、loaded和domcontentloaded等)
- CSS的可视化格式模型(元素的渲染规则,如包含块,控制框,BFC,IFC等概念)
- JS引擎解析过程(JS的解释阶段,预处理阶段,执行阶段生成执行上下文,VO,作用域链、回收机制等等)
- 其它(可以拓展不同的知识模块,如跨域,web安全,hybrid模式等等内容)
多进程的浏览器
区分进程和线程
线程和进程区分不清。先看看下面这个形象的比喻:进程是一个工厂,工厂有它的独立资源
- 工厂之间相互独立 线程是工厂中的工人,多个工人协作完成任务
- 工厂内有一个或多个工人 工人之间共享空间
一个进程由一个或多个线程组成
浏览器包含哪些进程:(注意说的是进程)
- Browser 进程:浏览器的主进程(负责协调、主控),只有一个。
- 浏览器界面显示,与用户交互。BOM
- 子进程管理:负责各个页面的管理
- 存储功能:数据持久层
- 网络进程:
- 发起和接收网络请求
- 第三方插件进程:每种类型的插件对应一个进程,仅当使用该插件时才创建
- GPU 进程:最多一个,用于 3D 绘制等
- 浏览器渲染进程(浏览器内核V8引擎)(Renderer 进程,内部是多线程的):
- 默认每个 Tab 页面一个进程(也是占用最多内存的模式),互不影响。主要作用为
- 页面渲染,脚本执行,事件处理等
- 同一个域名使用同一个进程
- tab里的站点使用同一个进程
- 浏览器引擎和渲染引擎共用一个进程
- 默认每个 Tab 页面一个进程(也是占用最多内存的模式),互不影响。主要作用为
- 首先,当我们是要浏览一个网页,我们会在浏览器的地址栏里输入 URL
- 这个时候 Browser Process 会向这个 URL 发送请求,获取这个 URL 的 HTML 内容(???)
- 然后将 HTML 交给 Renderer Process,Renderer Process 解析 HTML 内容,
- 解析遇到需要请求网络的资源又返回来交给 Browser Process 进行加载,同时通知 Browser Process,需要 Plugin Process 加载插件资源,执行插件代码。
- 解析完成后,Renderer Process 计算得到图像帧,并将这些图像帧交给 GPU Process,
-
重点是浏览器渲染进程(内核)
请牢记,浏览器的渲染进程是多线程的 包括:
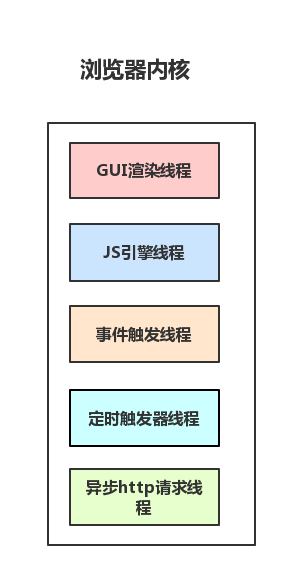
GUI 渲染线程
- 负责渲染浏览器界面,解析 HTML,CSS,构建 DOM 树和 RenderObject 树,布局和绘制等。
- 当界面需要重绘(Repaint)或由于某种操作引发回流 (reflow) 时,该线程就会执行
- 注意,GUI 渲染线程与 JS 引擎线程是互斥的,当 JS 引擎执行时 GUI 线程会被挂起(相当于被冻结了),GUI 更新会被保存在一个队列中等到 JS 引擎空闲时立即被执行。
- JS 引擎线程
- 也称为 JS 内核,负责处理 Javascript 脚本程序。(例如 V8 引擎)
- JS 引擎线程负责解析 Javascript 脚本,运行代码。
- JS 引擎一直等待着任务队列中任务的到来,然后加以处理,一个 Tab 页(renderer 进程)中无论什么时候都只有一个 JS 线程在运行 JS 程序
- 同样注意,GUI 渲染线程与 JS 引擎线程是互斥的,所以如果 JS 执行的时间过长,这样就会造成页面的渲染不连贯,导致页面渲染加载阻塞。
- 事件触发线程
- 归属于浏览器而不是 JS 引擎,用来控制事件循环(可以理解,JS 引擎自己都忙不过来,需要浏览器另开线程协助)
- 当 JS 引擎执行代码块如 setTimeOut 时(也可来自浏览器内核的其他线程,如鼠标点击、AJAX 异步请求等),会将对应任务添加到事件线程中
- 当对应的事件符合触发条件被触发时,该线程会把事件添加到待处理队列的队尾,等待 JS 引擎的处理
- 注意,由于 JS 的单线程关系,所以这些待处理队列中的事件都得排队等待 JS 引擎处理(当 JS 引擎空闲时才会去执行)
- 定时触发器线程
- 传说中的
setInterval与setTimeout所在线程 - 浏览器定时计数器并不是由 JavaScript 引擎计数的,(因为 JavaScript 引擎是单线程的,如果处于阻塞线程状态就会影响记计时的准确)
- 因此通过单独线程来计时并触发定时(计时完毕后,添加到事件队列中,等待 JS 引擎空闲后执行)
- 注意,W3C 在 HTML 标准中规定,规定要求 setTimeout 中低于 4ms 的时间间隔算为 4ms。
- 传说中的
- 异步 http 请求线程
- 在 XMLHttpRequest 在连接后是通过浏览器新开一个线程请求
- 将检测到状态变更时,如果设置有回调函数,异步线程就产生状态变更事件,将这个回调再放入事件队列中。再由 JavaScript 引擎执行。
看到这里,如果觉得累了,可以先休息下,这些概念需要被消化,毕竟后续将提到的事件循环机制就是基于事件触发线程的,所以如果仅仅是看某个碎片化知识,
可能会有一种似懂非懂的感觉。
再说一点,为什么 JS 引擎是单线程的?额,这个问题其实应该没有标准答案,譬如,可能仅仅是因为由于多线程的复杂性,譬如多线程操作一般要加锁,因此最初设计时选择了单线程。。。
解析页面流程
经过http交互,那么接下来就是浏览器获取到html,然后解析,渲染
流程简述
浏览器内核拿到内容后,渲染步骤大致可以分为以下几步:
1. 解析HTML,构建DOM树 2. 解析CSS,生成CSS规则树 3. 合并DOM树和CSS规则,生成render树 4. 布局render树(Layout/reflow),负责各元素尺寸、位置的计算 5. 绘制render树(paint),绘制页面像素信息 6. 浏览器会将各层的信息发送给GPU,GPU会将各层合成(composite),显示在屏幕上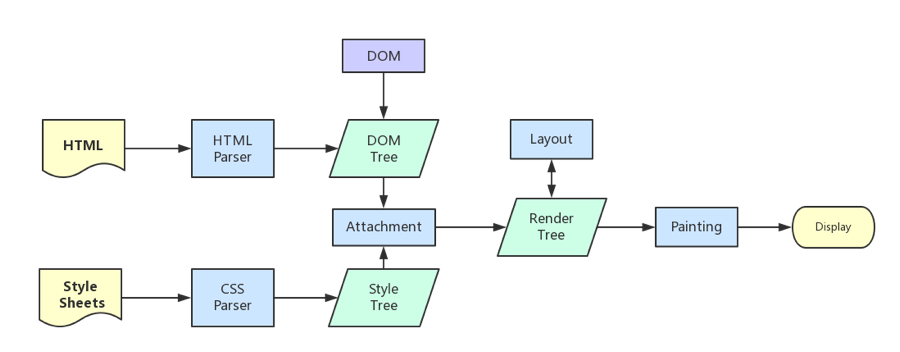
HTML解析,构建DOM
整个渲染步骤中,HTML解析是第一步。
简单的理解,这一步的流程是这样的:浏览器解析HTML,构建DOM树。
但实际上,在分析整体构建时,却不能一笔带过,得稍微展开。
解析HTML到构建出DOM当然过程可以简述如下:
Bytes → characters → tokens → nodes → DOM
譬如假设有这样一个HTML页面:(以下部分的内容出自参考来源,修改了下格式)
<html><head><meta name="viewport" content="width=device-width,initial-scale=1"><link href="style.css" rel="stylesheet"><title>Critical Path</title></head><body><p>Hello <span>web performance</span> students!</p><div><img src="awesome-photo.jpg"></div></body></html>
浏览器的处理如下: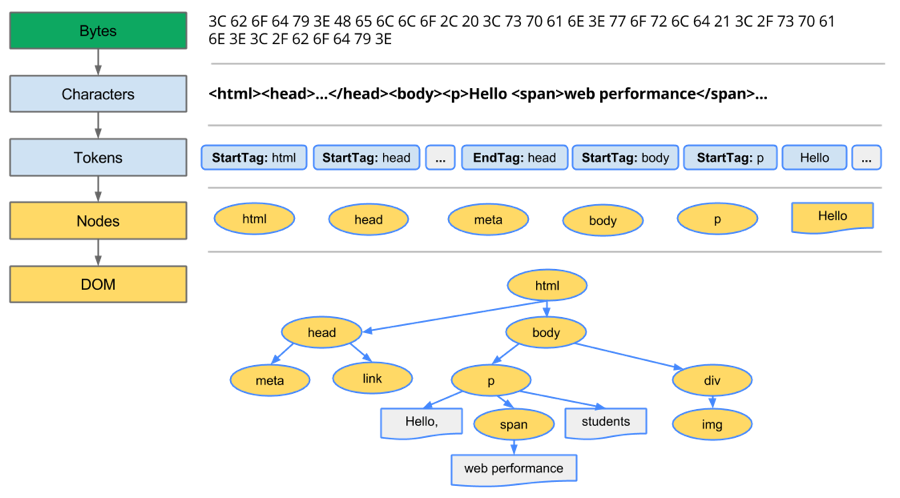
列举其中的一些重点过程:
1. Conversion转换:浏览器将获得的HTML内容(Bytes)基于他的编码转换为单个字符 2. Tokenizing分词:浏览器按照HTML规范标准将这些字符转换为不同的标记token。每个token都有自己独特的含义以及规则集 3. Lexing词法分析:分词的结果是得到一堆的token,此时把他们转换为对象,这些对象分别定义他们的属性和规则 4. DOM构建:因为HTML标记定义的就是不同标签之间的关系,这个关系就像是一个树形结构一样 例如:body对象的父节点就是HTML对象,然后段略p对象的父节点就是body对象
最后的DOM树如下: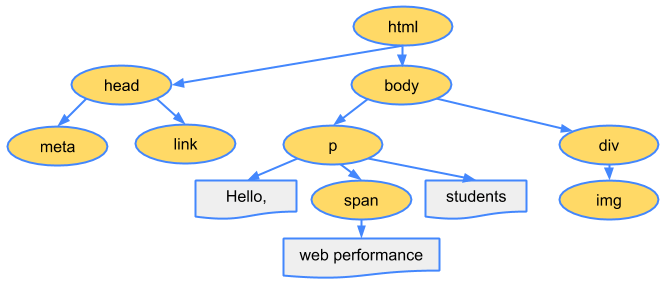
生成CSS规则
同理,CSS规则树的生成也是类似。简述为:
Bytes → characters → tokens → nodes → CSSOM
譬如style.css内容如下:
body { font-size: 16px }p { font-weight: bold }span { color: red }p span { display: none }img { float: right }
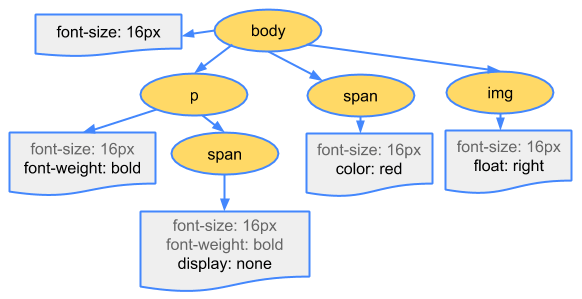
构建渲染树
当DOM树和CSSOM都有了后,就要开始构建渲染树了
一般来说,渲染树和DOM树相对应的,但不是严格意义上的一一对应
因为有一些不可见的DOM元素不会插入到渲染树中,如head这种不可见的标签或者display: none等
整体来说可以看图: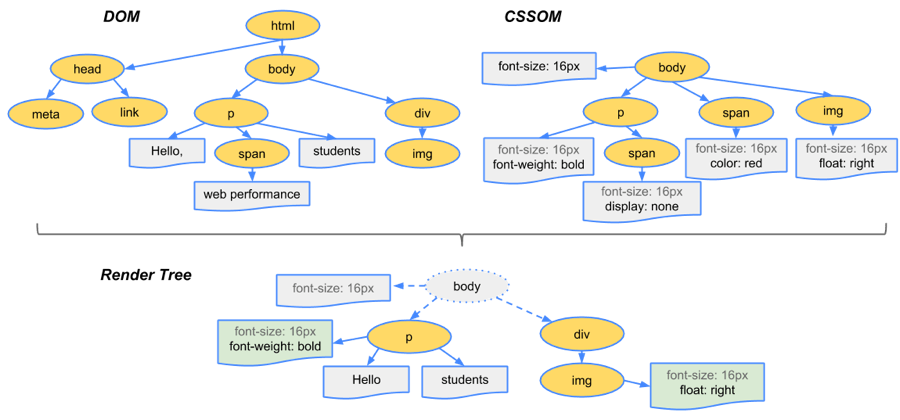
渲染
有了render树,接下来就是开始渲染,基本流程如下: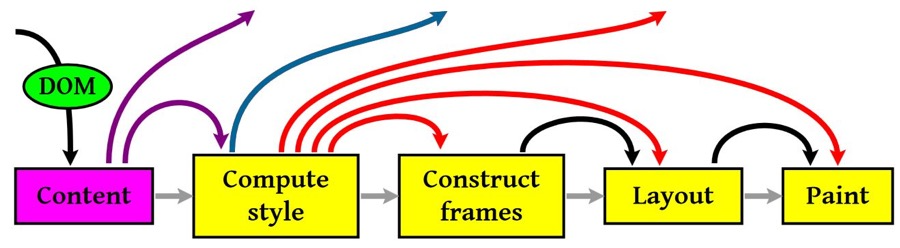
图中重要的四个步骤就是:
1. 计算CSS样式 2. 构建渲染树 3. 布局,主要定位坐标和大小,是否换行,各种position overflow z-index属性 4. 绘制,将图像绘制出来
然后,图中的线与箭头代表通过js动态修改了DOM或CSS,导致了重新布局(Layout)或渲染(Repaint)
Layout和Repaint的概念是有区别的:
- Layout,也称为Reflow,即回流。一般意味着元素的内容、结构、位置或尺寸发生了变化,需要重新计算样式和渲染树
- Repaint,即重绘。意味着元素发生的改变只是影响了元素的一些外观之类的时候(例如,背景色,边框颜色,文字颜色等),此时只需要应用新样式绘制这个元素就可以了
回流的成本开销要高于重绘,而且一个节点的回流往往回导致子节点以及同级节点的回流, 所以优化方案中一般都包括,尽量避免回流。
什么会引起回流?
1.页面渲染初始化 2.DOM结构改变,比如删除了某个节点 3.render树变化,比如减少了padding 4.窗口resize 5.最复杂的一种:获取某些属性,引发回流, 很多浏览器会对回流做优化,会等到数量足够时做一次批处理回流, 但是除了render树的直接变化,当获取一些属性时,浏览器为了获得正确的值也会触发回流,这样使得浏览器优化无效, 包括 (1)offset(Top/Left/Width/Height) (2) scroll(Top/Left/Width/Height) (3) cilent(Top/Left/Width/Height) (4) width,height (5) 调用了getComputedStyle()或者IE的currentStyle
回流一定伴随着重绘,重绘却可以单独出现
所以一般会有一些优化方案,如:
- 减少逐项更改样式,最好一次性更改style,或者将样式定义为class并一次性更新
- 避免循环操作dom,创建一个documentFragment或div,在它上面应用所有DOM操作,最后再把它添加到window.document
- 避免多次读取offset等属性。无法避免则将它们缓存到变量
- 将复杂的元素绝对定位或固定定位,使得它脱离文档流,否则回流代价会很高
注意:改变字体大小会引发回流
再来看一个示例:
var s = document.body.style;s.padding = "2px"; // 回流+重绘s.border = "1px solid red"; // 再一次 回流+重绘s.color = "blue"; // 再一次重绘s.backgroundColor = "#ccc"; // 再一次 重绘s.fontSize = "14px"; // 再一次 回流+重绘// 添加node,再一次 回流+重绘document.body.appendChild(document.createTextNode('abc!'));

若有收获,就点个赞吧
0 人点赞
