摘要
定义
本质
数组
散列表用的是数组支持按照下标随机访问数据的特性,所以散列表其实就是数组的一种扩展,由数组演化而来。可以说,如果没有数组,就没有散列表。
原理:
散列表用的就是数组支持按照下标随机访问的时候,时间复杂度是0(1)的特性。我们通过散列函数把元素的键值映射为下标,然后将数据存储在数组中对应下标的位置。当我们按照键值查询元素时,我们用同样的散列函数,将键值转化数组标标,从对应的数组下标的位置取数据。
散列函数
散列函数计算得到的散列值是一个非负整数;.
如果key1 = key2,那hash(key1) == hash(key2);
如果key1 != key2,那hash(key1) != hash(key2),
散列函数的设计不能太复杂,散列函数生成值要尽可能随机并且均匀分布
负载因子 load factor
衡量哈希表的 空/满 程度,一定程度上也可以体现查询的效率
负载因子 = 总键值对数 / 箱子个数
负载因子越大,意味着哈希表越满,越容易导致冲突,性能也就越低。因此,一般来说,当负载因子大于某个常数(可能是 1,或者 0.75 等)时,哈希表将自动扩容。
重哈希 rehash
在自动扩容时,一般会创建两倍于原来个数的箱子,因此即使 key 的哈希值不变,对箱子个数取余的结果也会发生改变,因此所有键值对的存放位置都有可能发生改变
特性
哈希冲突 Hash Collision
不同的键在哈希函数作用下映射到相同的槽,即出现多对一。
拉链法
Open Hashing,链表法 Chaining
每个”桶(bucket) “或者”槽(slot) “会对应一条链表,所有散列值相同的元素我们都放到相同槽位对应的链表中。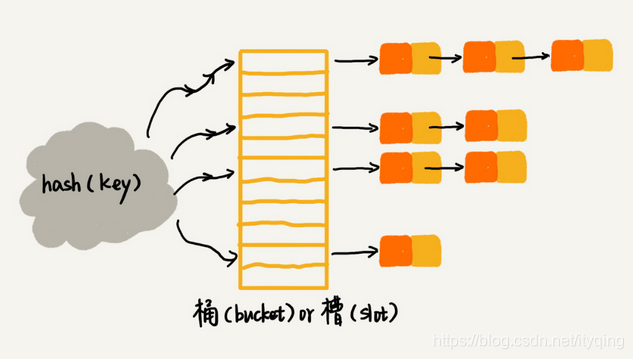
用链表延展存储
优点
- 处理简单,无堆积现象(即非同义词决不会发生冲突)?,平均查找长度较短
- 链表删除结点简单
缺点
- 链表内存分配会降低运行效率
开放寻址法 Open Addressing
Closed Hashing,开地址法
不在本身之外开辟新空间,而是重新选择一个空闲位置哈希桶 Bucket Hashing
普通哈希表满足:一个桶Bucket仅一个槽slot。
哈希桶:一个桶Bucket多个槽slot。即可看做将重复部分添加每个槽后
相同映射值依次填充桶内的slot,当填满后填充值overflow内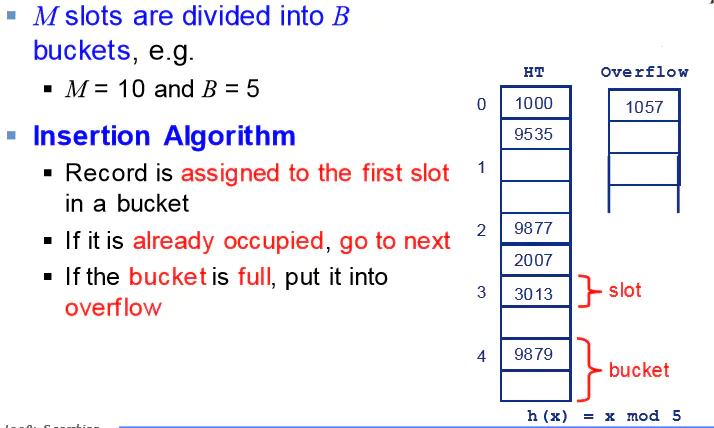
探测 Probing
应用
作为字典dict的底层实现
- Java中HashMap
- Objective-C中的NSDictionary
- Redis中dict

若有收获,就点个赞吧
0 人点赞
