并发concurrency
很多人都是冲着Go大肆宣扬的高并发而忍不住跃跃欲试,但其实从源码的解析来看,goroutine只是官方实现的超级“线程池”而已。不过话说回来,每个实例4-5KB的栈内存占用和由于实现机制而大幅减少的创建和销毁开销,是制造Go号称高并发的根本原因。另外,goroutine的简单易用,也在语言层面上给予了开发者巨大的便利。
并发不是并行:
并发主要由切换时间片来实现“同时”运行,而并行则是直接利用多核实现多线程的运行,但Go可以设置使用核数,以发挥多核计算机的能力。
Goroutine奉行通过通信来共享内存,而不是共享内存来通信。
Channel
Channel是goroutine沟通的桥梁,大都是阻塞同步的
通过make创建,close关闭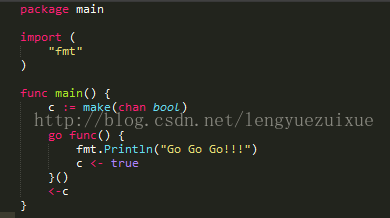
Channel是引用类型
可以使用for range来迭代不断操作channel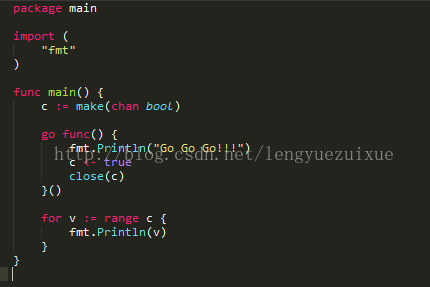
可以设置单向或双向通道
可以设置缓存大小,在未被填满之前不会发生阻塞(无缓存的是同步的, 有缓存的是异步的)
Select
可处理一个或多个channel的发送与接收
同时有多个可用的channel时按随机处理
可用空的select来阻塞main函数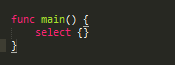
可设置超时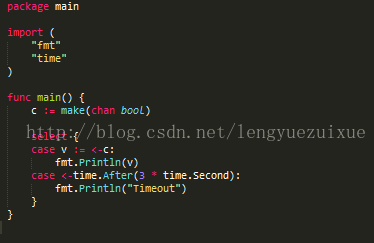
Go语言中并发程序依靠的是:goroutine和channel
goroutine
对于初选者,goroutine直接理解成线程就可以了。当对一个函数调用go,启动一个goroutine的时候,就相当于启动了一个线程,执行这个函数。
实际上,一个goroutine并不相当于一个线程,goroutine的出现正是为了替代原来的线程概念称为最小的调度单位。一旦运行goroutine时,先去当前线程查找,如果线程阻塞了,则被分配到空闲的线程,如果没有空闲的线程,那么就会新建一个线程。值得注意的是,当goroutine执行完毕后,线程不会回收退出,而是成了空闲的线程。
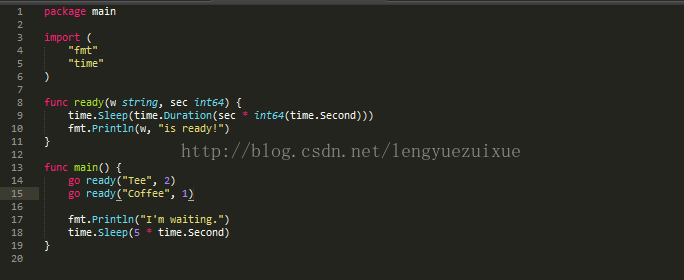
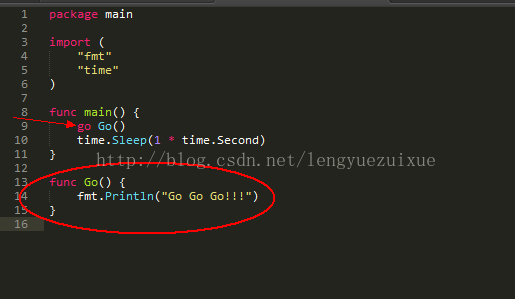
这里的第18行为什么要sleep?这里是为了等上面两个go ready处理完成
Channel
channel的意思可以这么理解:主线程告诉大家你开goroutine可以,但是我在我的主线程开了一个管道,你做完了你要做的事情之后,往管道里面塞个东西告诉我你已经完成了。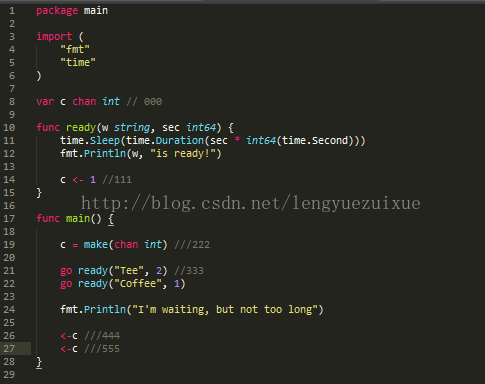
从上面的程序得到几点信息
1.channel只能使用make来进行创建
基本格式是 c := make(chan int)
int是说明这个管道能传输什么类型的数据
2.往channel中插入数据的操作
c <- 1
3.从channel中输入数据
<-c
4.为什么要输出两次(26和27行)
因为21和22行启动了两个goroutine,每个goroutine都往管道输出一个1,因此主线程要接收两次才能说明两个goroutine都结束了
channel分为两种,一种是有buffer的,一种是没有buffer的,默认的是没有buffer的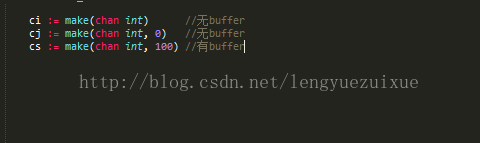
有buffer的channel,要注意“放”先于“取”
var a stringvar c = make(chan int, 10)func f() {a = "hello, world"c <- 0}func main() {go f()<-cprint(a)}
无buffer的channel,要注意“取”先于“放”
var a stringvar c = make(chan int)func f() {a = "hello, world"<-c}func main() {go f()c <- 0print(a)}


若有收获,就点个赞吧
0 人点赞
