bigkey 是指 key 对应的 value 所占的内存空间比较大.
- 字符串类型: 体现在单个 value 值很大, 一般认为超过 10KB 就是 bigkey, 但这个值和具体的 OPS 相关
- 非字符串类型: 哈希、列表、集合、有序集合, 体现在元素个数过多
12.4.1 bigkey 的危害
- 内存空间不均匀 (平衡): 例如在 Redis Cluster 中, bigkey 会造成节点的内存空间使用不均匀
- 超时阻塞: 由于 Redis 单线程的特性, 操作 bigkey 比较耗时, 也就意味着阻塞 Redis 可能性增大
- 每次获取 bigkey 产生的网络流量较大
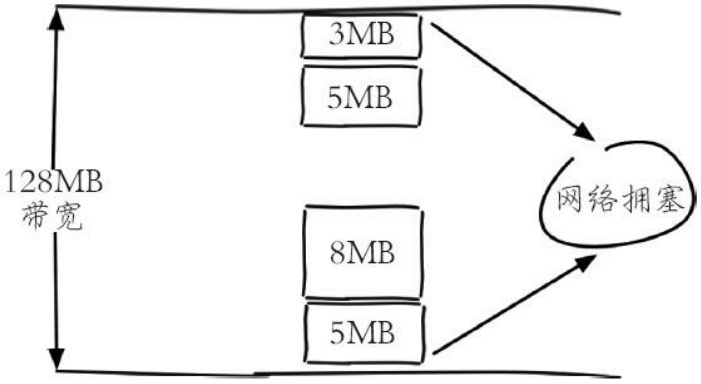
图12-3 bigkey 造成网络拥塞示意图
12.4.2 如何发现
redis-cli —bigkeys 可以命令统计 bigkey 的分布.
判断一个 key 是否为 bigkey, 只需要执行 debug object key 查看 serializedlength 属性即可, 它表示 key 对应的value 序列化之后的字节数:
127.0.0.1:6379> debug object keyValue at:0x7fc06c1b1430 refcount:1 encoding:raw serializedlength:1256350 lru:11686193lru_seconds_idle:20
在实际生产环境中发现 bigkey 的两种方式如下:
- 被动收集: 开发人员通过对异常的分析通常能找到异常原因可能是 bigkey, 不推荐
- 主动检测: scan+debug object: 如果怀疑存在 bigkey, 可以使用 scan 命令渐进的扫描出所有的 key, 分别计算每个 key 的 serializedlength, 找到对应 bigkey 进行相应的处理和报警, 这种方式是比较推荐的方式
开发提示:
- 如果键值个数比较多, scan+debug object 会比较慢, 可以利用 Pipeline 机制完成
- 对于元素个数较多的数据结构, debug object 执行速度比较慢, 存在阻塞 Redis 的可能
- 如果有从节点, 可以考虑在从节点上执行
12.4.3 如何删除
删除测试:

表12-4 删除 hash、list、set、sorted set 四种数据结构不同数量不同元素大小的耗时
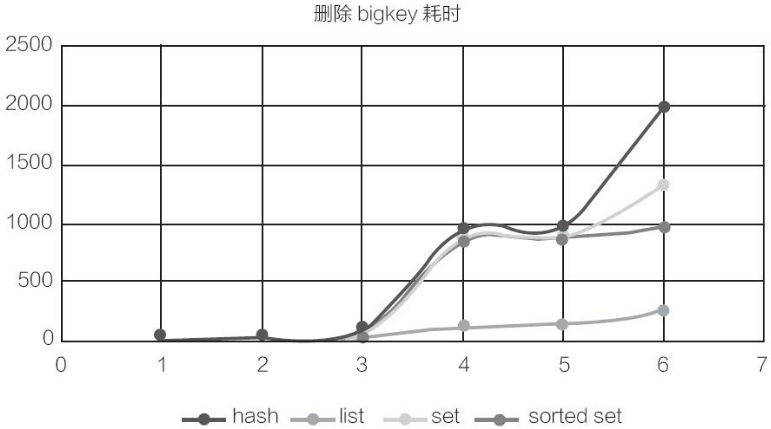
图12-4 删除hash、list、set、sorted set 四种数据结构不同数量不同元素大小的耗时
以优雅的方式进行删除:
- scan
- sscan
- hscan
- zscan
1. string
直接使用 del 一般不会阻塞:
del bigkey
2. hash、list、set、sorted set
以 hash 为例, 可以结合 pipeline:

12.4.4 最佳实践思路
- 通过合理的检测机制及时找到 bigkey
- 应该在数据结构的选择和设计上更加合理
- Redis 将在4.0版本支持 lazy delete free 的模式, 那时删除 bigkey 不会阻塞 Redis

若有收获,就点个赞吧
0 人点赞
