10.1.1 数据分布理论
分布式数据库首先要解决把整个数据集按照分区规则映射到多个节点的问题, 即把数据集划分到多个节点上, 每个节点负责整体数据的一个子集。
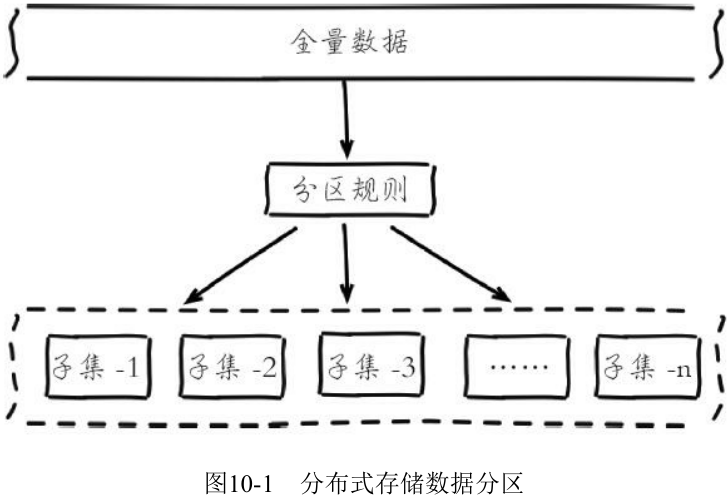
常见的分区规则:
- 哈希分区
- 顺序分区
表10-1 哈希分区和顺序分区对比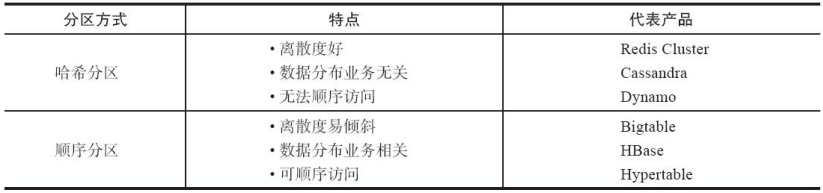
哈希分区:
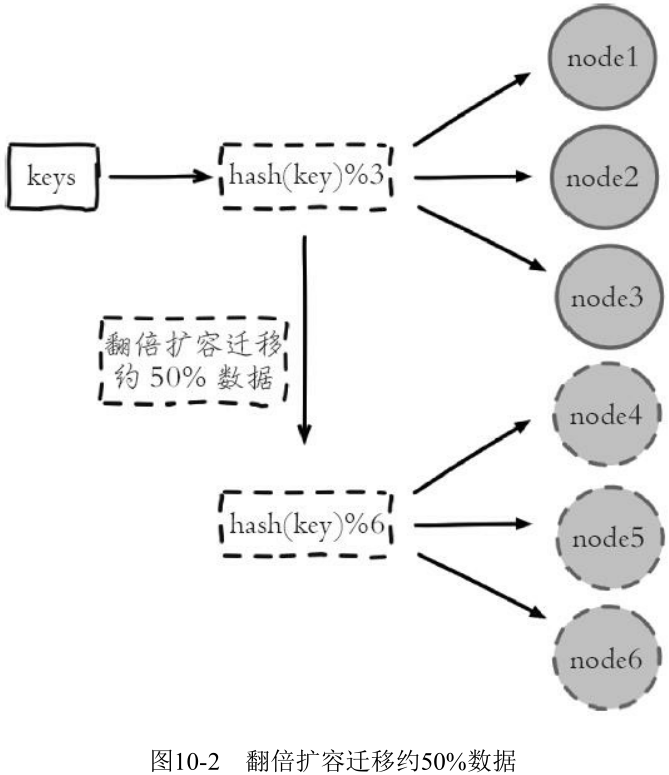
- 节点取余分区
- hash(key)%N
- 当节点数量变化时, 如扩容或收缩节点,数据节点映射关系需要重新计算, 会导致数据的重新迁移
- 一致性哈希分区
Distributed Hash Table
实现思路是为系统中每个节点分配一个 token, 范围一般在0~2 , 这些 token 构成一个哈希环。数据读写执行节点查找操作时, 先根据 key 计算 hash 值, 然后顺时针找到第一个大于等于该哈希值的 token 节点
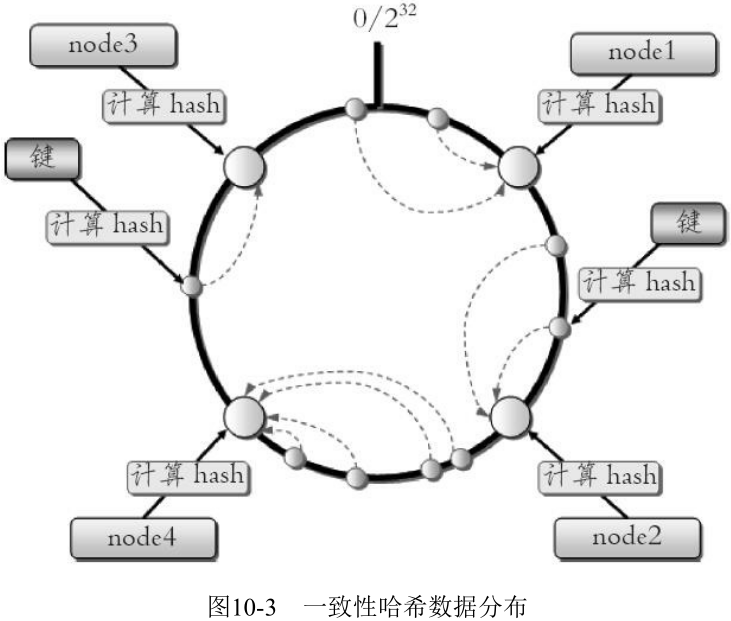
这种方式相比节点取余最大的好处在于加入和删除节点只影响哈希环中相邻的节点, 对其他节点无影响。
问题:
- 加减节点会造成哈希环中部分数据无法命中, 需要手动处理或者忽略这部分数据,因此一致性哈希常用于缓存场景
- 当使用少量节点时, 节点变化将大范围影响哈希环中数据映射, 因此这种方式不适合少量数据节点的分布式方案
- 普通的一致性哈希分区在增减节点时需要增加一倍或减去一半节点才能保证数据和负载的均衡
一些分布式系统采用虚拟槽对一致性哈希进行改进, 比如 Dynamo 系统.
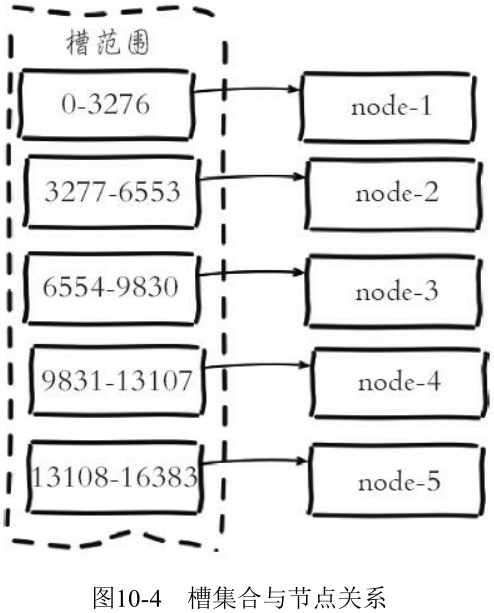
- 虚拟槽分区
- slot
- 槽是集群内数据管理和迁移的基本单位
- 采用大范围槽的主要目的是为了方便数据拆分和集群扩展
- 每个节点会负责一定数量的槽
- Redis Cluster 槽范围是0~16383
10.1.2 Redis 数据分区
计算公式: slot=CRC16(key)&16383
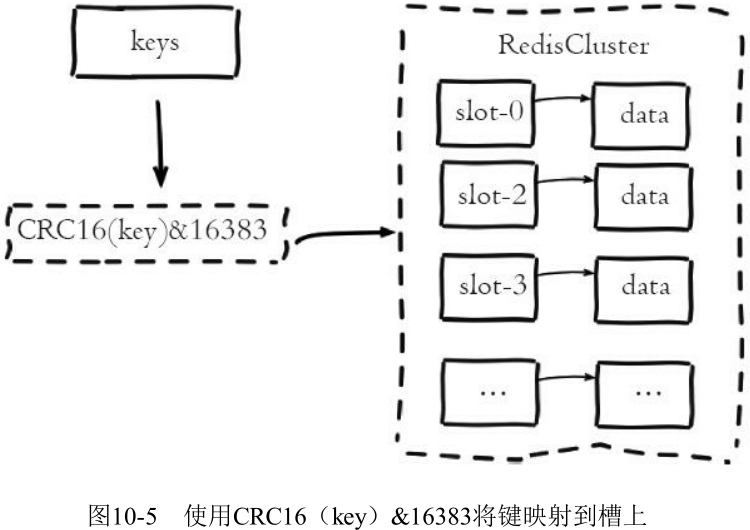
Redis 虚拟槽分区的特点:
- 解耦数据和节点之间的关系, 简化了节点扩容和收缩难度
- 节点自身维护槽的映射关系, 不需要客户端或者代理服务维护槽分区元数据
- 支持节点、槽、键之间的映射查询, 用于数据路由、在线伸缩等场景
10.1.3 集群功能限制
- key 批量操作支持有限。如mset、mget, 目前只支持具有相同 slot 值的 key 执行批量操作。对于映射为不同 slot 值的 key 由于执行 mset、mget 等操作可能存在于多个节点上因此不被支持
- key 事务操作支持有限。同理只支持多 key 在同一节点上的事务操作, 当多个 key 分布在不同的节点上时无法使用事务功能
- key 作为数据分区的最小粒度, 因此不能将一个大的键值对象如 hash、list 等映射到不同的节点
- 不支持多数据库空间。单机下的 Redis 可以支持16个数据库, 集群模式下只能使用一个数据库空间, 即 db0
- 复制结构只支持一层, 从节点只能复制主节点, 不支持嵌套树状复制结构

若有收获,就点个赞吧
0 人点赞
