10.6.1 故障发现
Redis 集群内节点通过 ping/pong 消息实现节点通信, 消息不但可以传播节点槽信息, 还可以传播其他状态如: 主从状态、节点故障等。因此故障发现也是通过消息传播机制实现的, 主要环节包括: 主观下线 (pfail) 和客观下线 (fail)。
1. 主观下线
集群中每个节点都会定期向其他节点发送 ping 消息, 接收节点回复 pong 消息作为响应。如果在 cluster-node-timeout 时间内通信一直失败, 则发送节点会认为接收节点存在故障, 把接收节点标记为主观下线 (pfail) 状态。
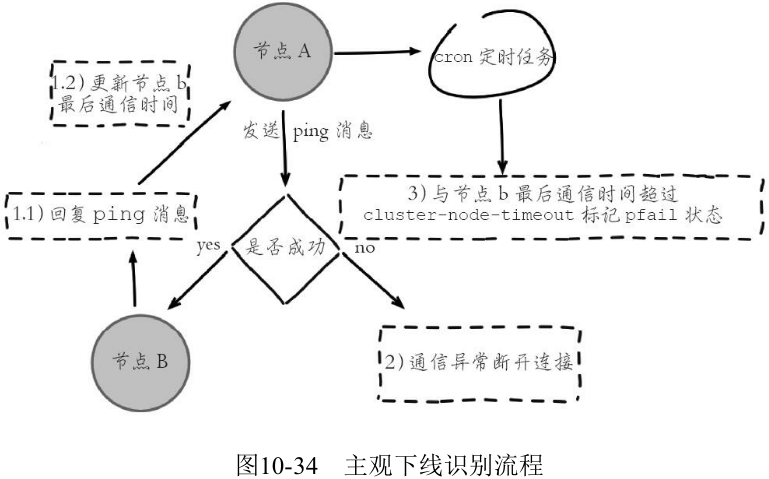
应该是恢复 pong 消息
状态信息保存在 clusterState 中:

flags 标志:

只有一个节点认为主观下线并不能准确判断是否故障:
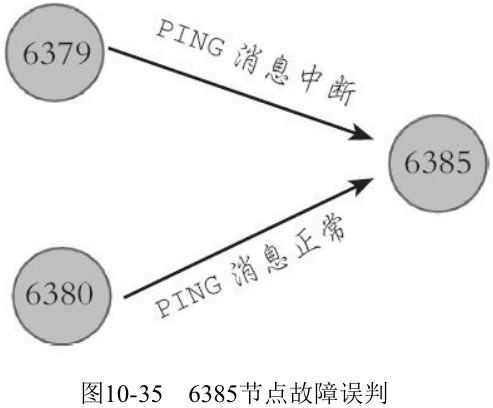
2. 客观下线
当某个节点判断另一个节点主观下线后, 相应的节点状态会跟随消息在集群内传播。ping/pong 消息的消息体会携带集群1/10的其他节点状态数据, 当接受节点发现消息体中含有主观下线的节点状态时, 会在本地找到故障节点的 ClusterNode 结构, 保存到下线报告链表中:

通过 Gossip 消息传播, 集群内节点不断收集到故障节点的下线报告。当半数以上持有槽的主节点都标记某个节点是主观下线时。触发客观下线流程。这里有两个问题:
- 为什么必须是负责槽的主节点参与故障发现决策?
因为集群模式下只有处理槽的主节点才负责读写请求和集群槽等关键信息维护, 而从节点只进行主节点数据和状态信息的复制。
从节点的消息被忽略.
- 为什么半数以上处理槽的主节点?
必须半数以上是为了应对网络分区等原因造成的集群分割情况, 被分割的小集群因为无法完成从主观下线到客观下线这一关键过程, 从而防止小集群完成故障转移之后继续对外提供服务。
假设节点 a 标记节点 b 为主观下线, 一段时间后节点 a 通过消息把节点 b 的状态发送到其他节点, 当节点 c 接受到消息并解析出消息体含有节点 b 的 pfail 状态时, 会触发客观下线流程:
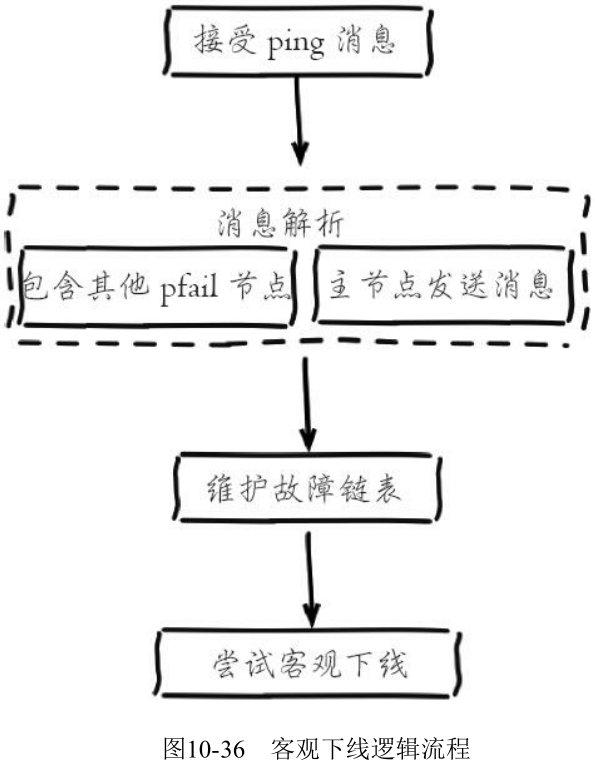
这里针对维护下线报告和尝试客观下线逻辑进行详细说明:
- 维护下线报告链表
每个节点 ClusterNode 结构中都会存在一个下线链表结构, 保存了其他主节点针对当前节点的下线报告
**
每个下线报告都存在有效期, 每次在尝试触发客观下线时, 都会检测下线报告是否过期, 对于过期的下线报告将被删除。如果在 cluster-node-time*2 的时间内该下线报告没有得到更新则过期并删除.
- 下线报告的有效期限是 server.cluster_node_timeout*2, 主要是针对故障误报的情况
- 不建议将 cluster-node-time 设置得过小
- 尝试客观下线
集群中的节点每次接收到其他节点的 pfail 状态, 都会尝试触发客观下线:
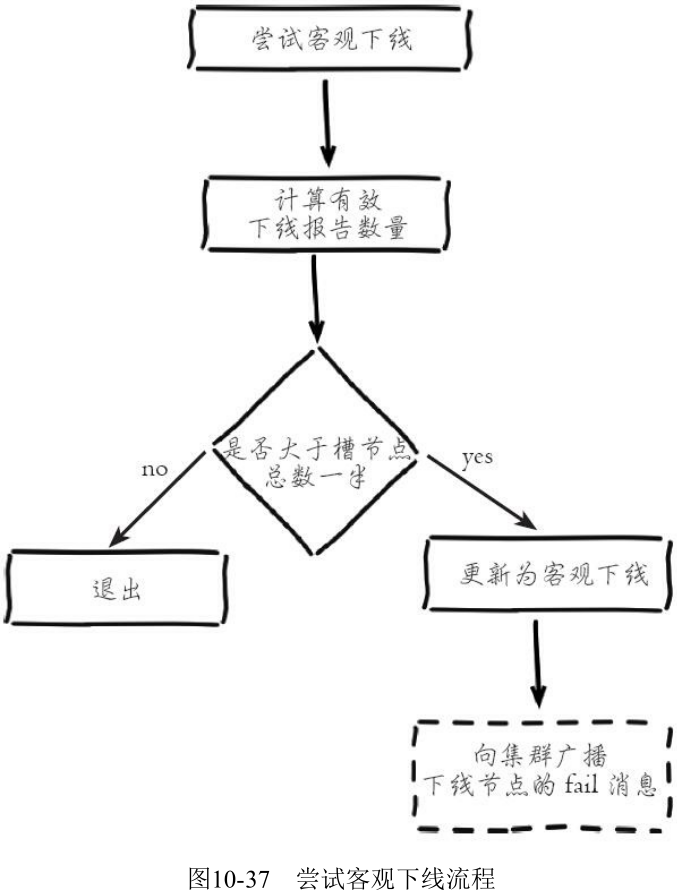
广播 fail 消息是客观下线的最后一步, 它承担着非常重要的职责:
- 通知集群内所有的节点标记故障节点为客观下线状态并立刻生效
- 通知故障节点的从节点触发故障转移流程
需要理解的是, 尽管存在广播 fail 消息机制, 但是集群所有节点知道故障节点进入客观下线状态是不确定的。比如当出现网络分区时有可能集群被分割为一大一小两个独立集群中。大的集群持有半数槽节点可以完成客观下线并广播 fail 消息, 但是小集群无法接收到 fail 消息:
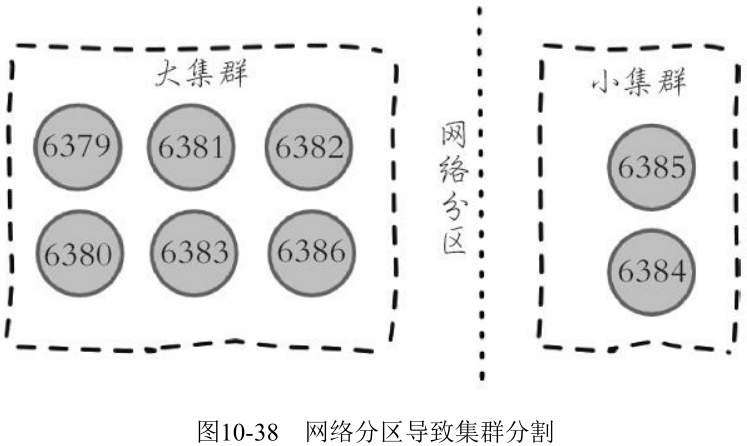
10.6.2 故障恢复
故障节点变为客观下线后, 如果下线节点是持有槽的主节点则需要在它的从节点中选出一个替换它, 从而保证集群的高可用。下线主节点的所有从节点承担故障恢复的义务, 当从节点通过内部定时任务发现自身复制的主节点进入客观下线时, 将会触发故障恢复流程:
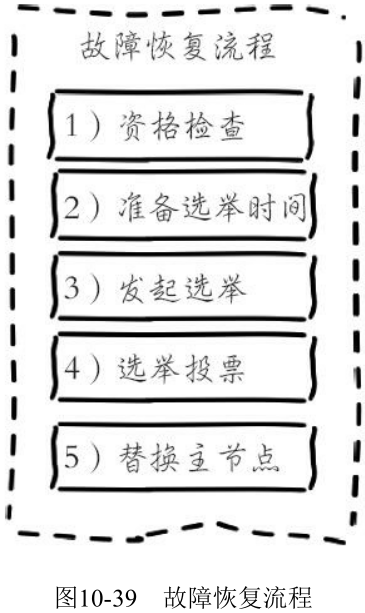
1. 资格检查
每个从节点都要检查最后与主节点断线时间, 判断是否有资格替换故障的主节点。如果从节点与主节点断线时间超过 cluster-node-timecluster-slave-validity-factor, 则当前从节点不具备*故障转移资格。
- 参数 cluster-slave-validity-factor 用于从节点的有效因子, 默认为10。
2. 准备选举时间
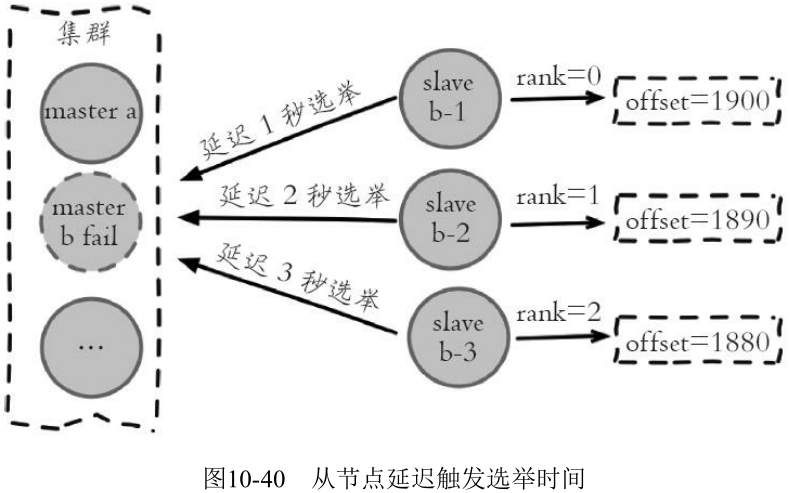
当从节点符合故障转移资格后, 更新触发故障选举的时间, 只有到达该时间后才能执行后续流程。故障选举时间相关字段如下:

所有的从节点中复制偏移量最大的将提前触发故障选举流程:
3. 发起选举
当从节点定时任务检测到达故障选举时间 (failover_auth_time) 到达后, 发起选举流程如下:
- 更新配置纪元
查看纪元:

- 广播选举消息
在集群内广播选举消息 (FAILOVER_AUTH_REQUEST), 并记录已发送过消息的状态, 保证该从节点在一个配置纪元内只能发起一次选举。消息内容如同 ping 消息只是将 type 类型变为 FAILOVER_AUTH_REQUEST。
4. 选举投票
只有持有槽的主节点才会处理故障选举消息 (FAILOVER_AUTH_REQUEST), 因为每个持有槽的节点在一个配置纪元
内都有唯一的一张选票, 当接到第一个请求投票的从节点消息时回复 FAILOVER_AUTH_ACK 消息作为投票, 之后相同配置纪元内其他从节点的选举消息将忽略。
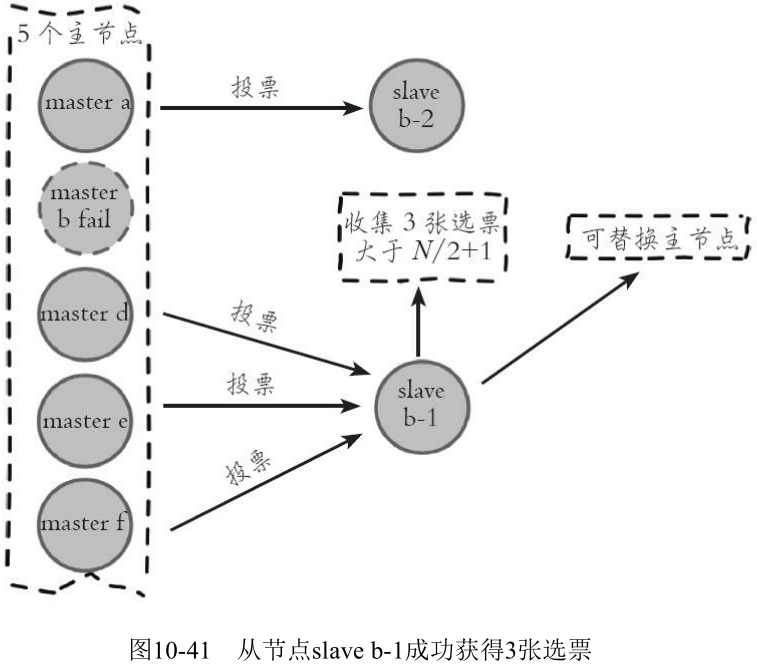
当从节点收集到 N/2+1 个持有槽的主节点投票时, 从节点可以执行替换主节点操作, 例如集群内有5个持有槽的主节点, 主节点 b 故障后还有4个, 当其中一个从节点收集到3张投票时代表获得了足够的选票可以进行替换主节点操作:
投票作废: 每个配置纪元代表了一次选举周期, 如果在开始投票之后的 cluster-node-timeout*2 时间内从节点没有获取足够数量的投票, 则本次选举作废。从节点对配置纪元自增并发起下一轮投票,直到选举成功为止。
5. 替换主节点
当从节点收集到足够的选票之后, 触发替换主节点操作:
- 当前从节点取消复制变为主节点
- 执行 clusterDelSlot 操作撤销故障主节点负责的槽, 并执行 clusterAddSlot 把这些槽委派给自己
- 向集群广播自己的 pong 消息, 通知集群内所有的节点当前从节点变为主节点并接管了故障主节点的槽信息
10.6.3 故障转移时间
- 主观下线 (pfail) 识别时间=cluster-node-timeout
- 主观下线状态消息传播时间<=cluster-node-timeout/2
- 从节点转移时间<=1000毫秒
根据以上分析可以预估出故障转移时间, 如下:
failover-time( 毫秒 ) ≤ cluster-node-timeout + cluster-node-timeout/2 + 1000
10.6.4 故障转移演练
跳过

若有收获,就点个赞吧
0 人点赞
