6.3.1 复制过程
复制的流程:
(1) 保存主节点 (master) 信息
该阶段, slave 只是保存 master 的地址信息, 复制流程未开始.
查看复制信息: info replication
master_host:127.0.0.1master_port:6379master_link_status:down
(2) 建立连接
从节点 (slave) 内部通过每秒运行的定时任务维护复制相关逻辑, 当定时任务发现存在新的主节点后, 会尝试与该节点建立网络连接
图6-8中从节点建立了一个端口为24555的套接字, 专门用于接受主节点发送的复制命令
如果从节点无法建立连接, 定时任务会无限重试直到连接成功或者执行 slaveof no one 取消复制:
可以在从节点执行 info replication 查看 master_link_down_since_seconds 指标, 它会记录与主节点连接失败的系统时间.
连接失败的日志:
# Error condition on socket for SYNC: {socket_error_reason}
(3) 发送 ping 命令
目的:
- 检测主从之间网络套接字是否可用
- 检测主节点当前是否可接受处理命令
如果发送 ping 命令后, 从节点没有收到主节点的 pong 回复或者超时, 比如网络超时或者主节点正在阻塞无法响应命令, 从节点会断开复制连接, 下次定时任务会发起重连:
ping 命令成功的日志:
Master replied to PING, replication can continue...
(4) 权限验证
如果主节点设置了 requirepass 参数, 则需要密码验证,从节点必须配置 masterauth 参数保证与主节点相同的密码才能通过验证; 如果验证失败复制将终止, 从节点重新发起复制流程。
(5) 同步数据集
主从复制连接正常通信后, 对于首次建立复制的场景, 主节点会把持有的数据全部发送给从节点, 这部分操作是耗时最长的步骤。
- Redis在2.8 版本以后采用新复制命令 psync 进行数据同步, 原来的 sync 命令依然支持, 保证新旧版本的兼容性。
- 新版同步划分两种情况: 全量同步和部分同步
自动运行 psync 吗?
(6) 命令持续复制
当主节点把当前的数据同步给从节点后, 便完成了复制的建立流程。接下来主节点会持续地把写命令发送给从节点, 保证主从数据一致性。
6.3.2 数据同步
Redis在2.8 及以上版本使用 psync 命令完成主从数据同步, 同步过程分为: 全量复制和部分复制。
- 全量复制: 一般用于初次复制场景, Redis 早期支持的复制功能只有全量复制, 它会把主节点全部数据一次性发送给从节点, 当数据量较大时, 会对主从节点和网络造成很大的开销
- 部分复制: 用于处理在主从复制中因网络闪断等原因造成的数据丢失场景, 当从节点再次连上主节点后, 如果条件允许, 主节点会补发丢失数据给从节点。因为补发的数据远远小于全量数据, 可以有效避免全量复制的过高开销
psync 命令运行需要以下组件支持:
- 主从节点各自复制偏移量
- 主节点复制积压缓冲区
- 主节点运行 id
1. 复制偏移量
主节点 (master) 在处理完写入命令后, 会把命令的字节长度做累加记录, 统计信息在 info relication 中的 master_repl_offset 指标中:
127.0.0.1:6379> info replication# Replicationrole:master...master_repl_offset:1055130
从节点 (slave) 每秒钟上报自身的复制偏移量给主节点, 因此主节点也会保存从节点的复制偏移量, 统计指标如下:
127.0.0.1:6379> info replicationconnected_slaves:1slave0:ip=127.0.0.1,port=6380,state=online,offset=1055214,lag=1...
从节点在接收到主节点发送的命令后, 也会累加记录自身的偏移量。统计信息在 info relication 中的 slave_repl_offset 指标中:
127.0.0.1:6380> info replication# Replicationrole:slave...slave_repl_offset:1055214
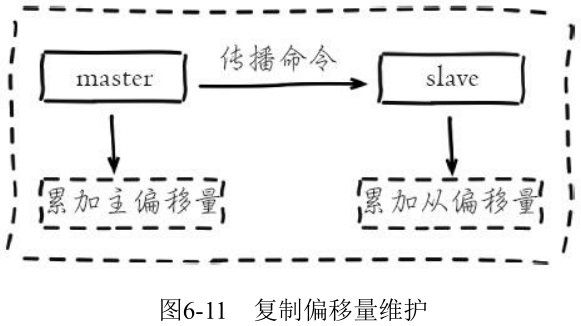
通过对比主从节点的复制偏移量, 可以判断主从节点数据是否一致
2. 复制积压缓冲区
复制积压缓冲区是保存在主节点上的一个固定长度的队列, 默认大小为 1MB, 当主节点有连接的从节点 (slave) 时被创建, 这时主节点 (master) 响应写命令时, 不但会把命令发送给从节点, 还会写入复制积压缓冲区
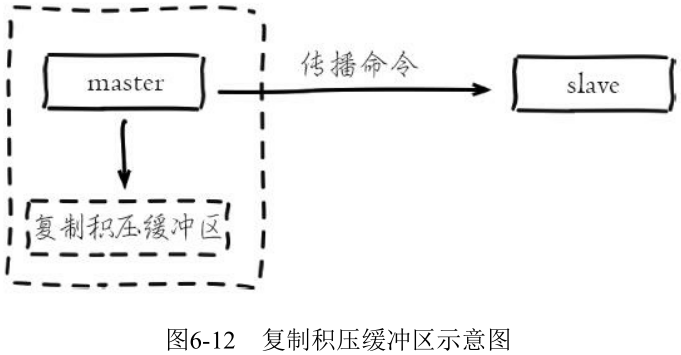
由于缓冲区本质上是先进先出的定长队列, 所以能实现保存最近已复制数据的功能, 用于部分复制和复制命令丢失的数据补救。复制缓冲区相关统计信息保存在主节点的 info replication 中:
127.0.0.1:6379> info replication# Replicationrole:master...repl_backlog_active:1 // 开启复制缓冲区repl_backlog_size:1048576 // 缓冲区最大长度repl_backlog_first_byte_offset:7479 // 起始偏移量,计算当前缓冲区可用范围repl_backlog_histlen:1048576 // 已保存数据的有效长度。
根据统计指标, 可算出复制积压缓冲区内的可用偏移量范围:
[repl_backlog_first_byte_offset, repl_backlog_first_byte_offset+repl_backlog_histlen]
更多复制缓冲区的细节见6.3.4节 “部分复制”.
3. 主节点运行 ID
每个 Redis 节点启动后都会动态分配一个40位的十六进制字符串作为运行 ID。运行 ID 的主要作用是用来唯一识别 Redis 节点.
- master 节点重启后, ID 会变, 当运行 ID 变化后从节点将做全量复制
- 如果只使用 ip+port 的方式识别主节点, 那么主节点重启变更了整体数据集 (如替换 RDB/AOF 文件), 从节点再基于偏移量复制数据将是不安全的
ID 用来识别节点是否重启过.
可以运行 info server 命令查看当前节点的运行 ID:
127.0.0.1:6379> info server# Serverredis_version:3.0.7...run_id:545f7c76183d0798a327591395b030000ee6def9
如何在不改变运行ID的情况下重启呢?
当需要调优一些内存相关配置, 例如: hash-max-ziplist-value 等, 这些配置需要 Redis 重新加载才能优化已存在的数据, 这时可以使用 debug reload 命令重新加载 RDB 并保持运行 ID 不变, 从而有效避免不必要的全量复制。命令如下:
# redis-cli -p 6379 info server | grep run_idrun_id:2b2ec5f49f752f35c2b2da4d05775b5b3aaa57ca# redis-cli debug reloadOK# redis-cli -p 6379 info server | grep run_idrun_id:2b2ec5f49f752f35c2b2da4d05775b5b3aaa57ca
- debug reload 命令会阻塞当前 Redis 节点主线程, 阻塞期间会生成本地 RDB 快照并清空数据之后再加载 RDB 文件。因此对于大数据量的主节点和无法容忍阻塞的应用场景, 谨慎使用。
4. psync 命令
从节点使用 psync 命令完成部分复制和全量复制功能, 命令格式:
psync {runId} {offset}
- runId: 从节点所复制主节点的运行 id
- offset: 当前从节点已复制的数据偏移量
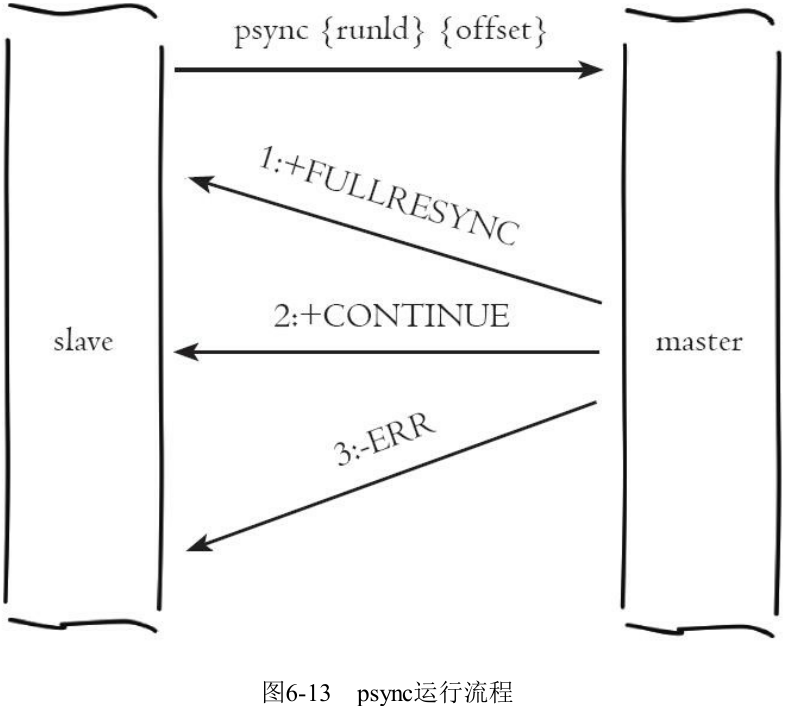
- +FULLRESYNC: 全量复制
- +CONTINUE: 部分复制
- -ERR: master 节点版本低于 Redis2.8, 无法识别 psync 命令
- slave 将发送旧版 sync 命令
6.3.3 全量复制
触发全量复制的命令是 sync, psync
psync 的复制流程:
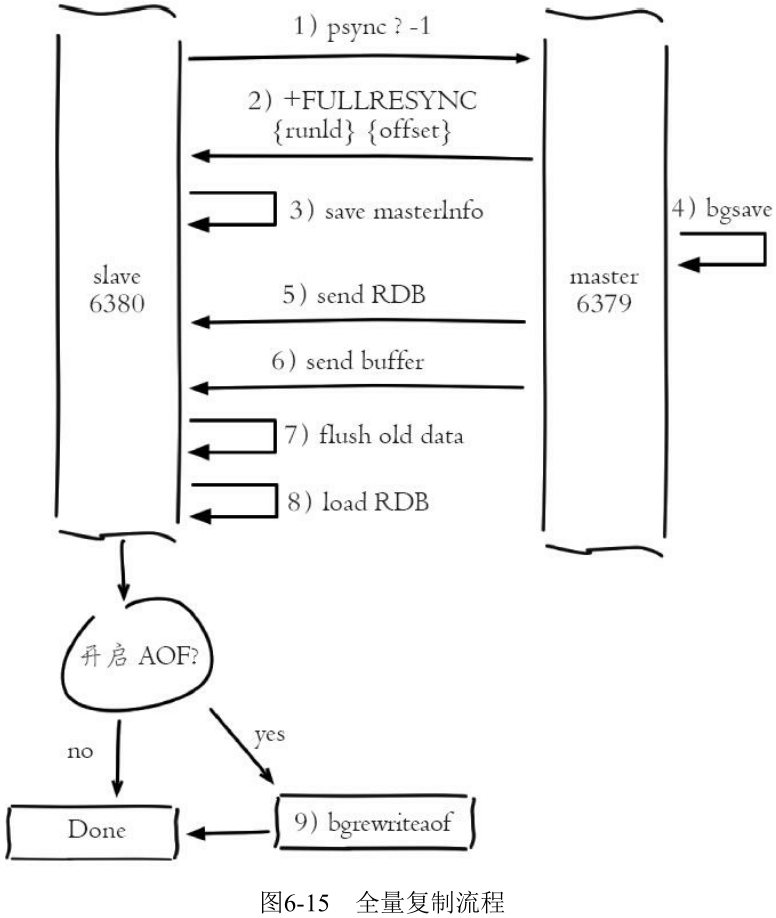
Redis3.0 之后在输出的日志开头会有 M、S、C 等标识, 对应的含义是:
- M=当前为主节点日志
- S=当前为从节点日志
- C=子进程日志
如果复制总时间超过 repl-timeout 所配置的值 (默认60秒), 从节点将放弃接受 RDB 文件并清理已经下载的临时文件, 导致全量复制失败
关于无盘复制: 为了降低主节点磁盘开销, Redis 支持无盘复制, 生成的 RDB 文件不保存到硬盘而是直接通过网络发送给从节点, 通过 repl-diskless-sync 参数控制, 默认关闭。无盘复制适用于主节点所在机器磁盘性能较差但网络带宽较充裕的场景。注意无盘复制目前依然处于试验阶段, 线上使用需要做好充分测试。
复制缓冲区大小: 默认配置为 client-output-buffer-limit slave 256MB 64MB 60, 如果60秒内缓冲区消耗持续大于 64MB 或者直接超过 256MB 时, 主节点将直接关闭复制客户端连接, 造成全量同步失败
对于线上做读写分离的场景, 从节点也负责响应读命令。如果此时从节点正出于全量复制阶段或者复制中断, 那么从节点在响应读命令可能拿到过期或错误的数据。对于这种场景, Redis复制提供了 slave-serve-stale-data 参数:
- 默认开启状态。如果开启则从节点依然响应所有命令。
- 对于无法容忍不一致的应用场景可以设置 no 来关闭命令执行, 此时从节点除了 info 和 slaveof 命令之外所有的命令只返回 “SYNC with master in progress” 信息。
对全量复制时间开销的总结:
- 主节点 bgsave 时间
- RDB 文件网络传输时间
- 从节点清空数据时间
- 从节点加载 RDB 的时间
- 可能的 AOF 重写时间
6.3.4 部分复制
psync {runId} {offset}
如果出现网络闪断或者命令丢失等异常情况时, 从节点会向主节点要求补发丢失的命令数据, 如果主节点的复制积压缓冲区内存在这部分数据则直接发送给从节点,这样就可以保持主从节点复制的一致性.
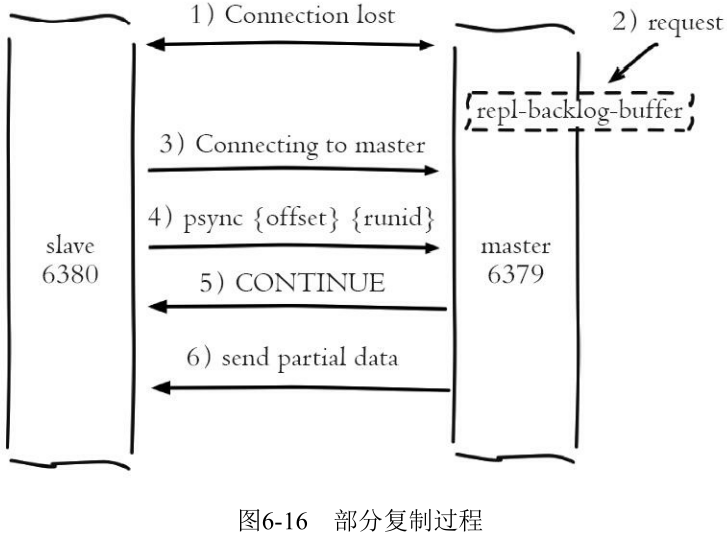
当主从节点之间网络出现中断时,如果超过 repl-timeout 时间, 主节点会认为从节点故障并中断复制连接
书中没有写如果 slave 发送的偏移不在复制积压缓冲区时的情况, 猜测后续步骤是使用全量复制.
6.3.5 心跳
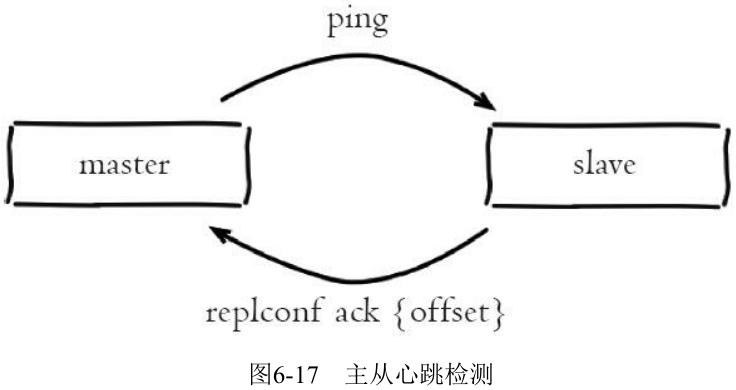
主从心跳判断机制:
- 主从节点彼此都有心跳检测机制, 各自模拟成对方的客户端进行通信, 通过 client list 命令查看复制相关客户端信息, 主节点的连接状态为 flags=M, 从节点连接状态为 flags=S
- 主节点默认每隔10秒对从节点发送 ping 命令, 判断从节点的存活性和连接状态。可通过参数 repl-ping-slave-period 控制发送频率
- 从节点在主线程中每隔1秒发送 replconf ack{offset} 命令, 给主节点上报自身当前的复制偏移量
- 实时监测主从节点网络状态
- 上报自身复制偏移量, 检查复制数据是否丢失, 如果从节点数据丢失, 再从主节点的复制缓冲区中拉取丢失数据
- 实现保证从节点的数量和延迟性功能, 通过 min-slaves-to-write、min-slaves-max-lag 参数配置定义
6.3.6 异步复制
主节点不但负责数据读写,还负责把写命令同步给从节点。写命令的发送过程是异步完成, 也就是说主节点自身处理完写命令后直接返回给客户端, 并不等待从节点复制完成
**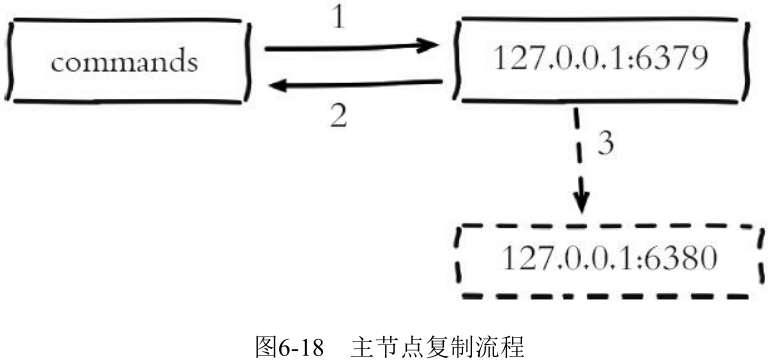
由于主从复制过程是异步的, 就会造成从节点的数据相对主节点存在延迟。具体延迟多少字节, 我们可以在主节点执行 info replication 命令查看相关指标获得:
slave0:ip=127.0.0.1,port=6380,state=online,offset=841,lag=1master_repl_offset:841

若有收获,就点个赞吧
0 人点赞
