HyperLogLog 并不是一种新的数据结构 (实际类型为字符串类型), 而是一种基数算法, 通过 HyperLogLog 可以利用极小的内存空间完成独立总数的统计, 数据集可以是 IP、Email、ID 等。
相关命令:
- pfadd
- pfcount
- pfmerge
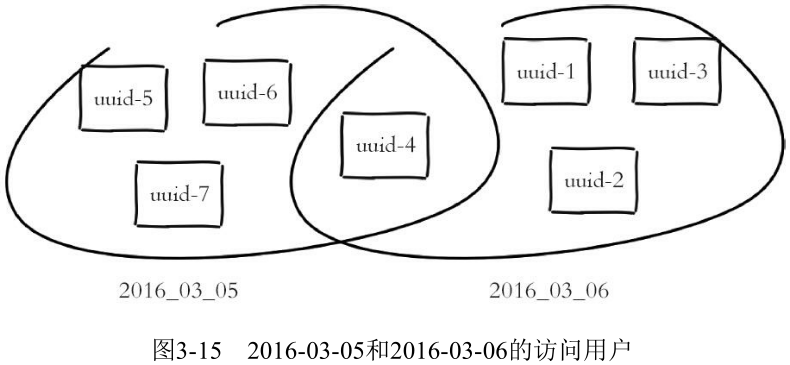
1. 添加
127.0.0.1:6379> pfadd 2016_03_06:unique:ids "uuid-1" "uuid-2" "uuid-3" "uuid-4"(integer) 1
2. 计算独立用户数
127.0.0.1:6379> pfcount 2016_03_06:unique:ids(integer) 4

Redis 官方给出的数字是0.81%的失误率
3. 合并
127.0.0.1:6379> pfadd 2016_03_06:unique:ids "uuid-1" "uuid-2" "uuid-3" "uuid-4"(integer) 1127.0.0.1:6379> pfadd 2016_03_05:unique:ids "uuid-4" "uuid-5" "uuid-6" "uuid-7"(integer) 1127.0.0.1:6379> pfmerge 2016_03_05_06:unique:ids 2016_03_05:unique:ids2016_03_06:unique:idsOK127.0.0.1:6379> pfcount 2016_03_05_06:unique:ids(integer) 7
使用 HyperLogLog 需要明确:
- 只为了计算独立总数, 不需要获取单条数据。
- 可以容忍一定误差率, 毕竟 HyperLogLog 在内存的占用量上有很大的优势。

若有收获,就点个赞吧
0 人点赞
