6.4.1 读写分离
可能需要更改程序来实现读写分离.
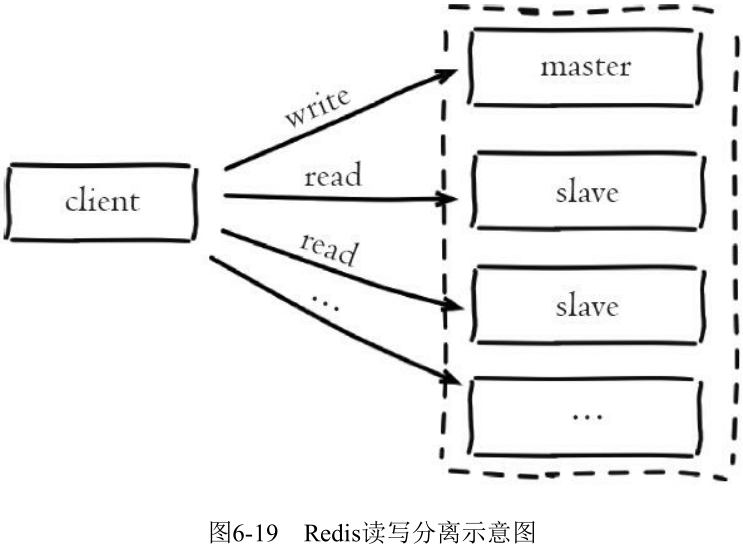
使用从节点的问题:
- 复制数据延迟
- 读到过期数据
- 从节点故障
1. 数据延迟
- 异步复制
利用监控程序监听主从节点的复制偏移量, 避免客户端读取延迟过高的从节点:
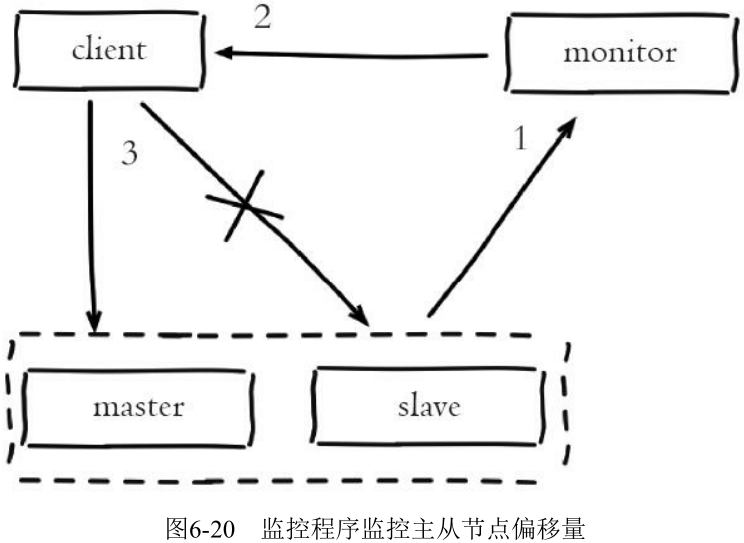
- 主节点偏移量在 info replication 的 master_repl_offset 指标记录
- 从节点偏移量可以查询主节点的 slave0 字段的 offset 指标
2. 读到过期数据
删除策略:
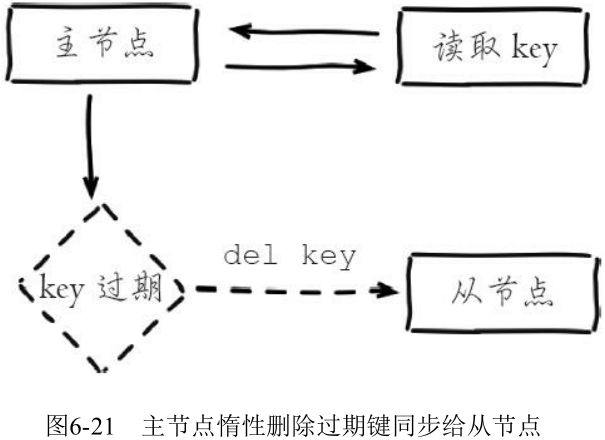
- 惰性删除: 主节点每次处理读取命令时, 都会检查键是否超时, 如果超时则执行 del 命令删除键对象, 之后 del 命令也会异步发送给从节点。需要注意的是为了保证复制的一致性, 从节点自身永远不会主动删除超时数据
- 定时删除: Redis 主节点在内部定时任务会循环采样一定数量的键, 当发现采样的键过期时执行 del 命令, 之后再同步给从节点
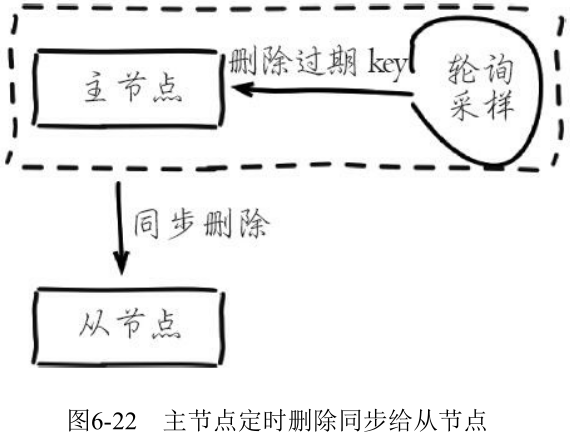
如果此时数据大量超时, 主节点采样速度跟不上过期速度且主节点没有读取过期键的操作, 那么从节点将无法收到 del 命令。这时在从节点上可以读取到已经超时的数据。Redis 在3.2版本解决了这个问题, 从节点读取数据之前会检查键的过期时间来决定是否返回数据, 可以升级到3.2版本来规避这个问题。
3. 从节点故障问题
对于从节点的故障问题, 需要在客户端维护可用从节点列表, 当从节点故障时立刻切换到其他从节点或主节点上。这个过程类似上文提到的针对延迟过高的监控处理, 需要开发人员改造客户端类库。
笔者建议大家在做读写分离之前, 可以考虑使用 Redis Cluster 等分布式解决方案, 这样不止扩展了读性能还可以扩展写性能和可支撑数据规模, 并且一致性和故障转移也可以得到保证, 对于客户端的维护逻辑也相对容易。
6.4.2 主从配置不一致
有些可以不一致.
6.4.3 规避全量复制
全量复制的场景:
- 第一次建立复制: 由于是第一次建立复制, 从节点不包含任何主节点数据, 因此必须进行全量复制才能完成数据同步。对于这种情况全量复制无法避免。当对数据量较大且流量较高的主节点添加从节点时,建议在低峰时进行操作, 或者尽量规避使用大数据量的 Redis 节点
- 节点运行 ID 不匹配: 当主从复制关系建立后, 从节点会保存主节点的运行 ID, 如果此时主节点因故障重启, 那么它的运行 ID 会改变, 从节点发现主节点运行 ID 不匹配时, 会认为自己复制的是一个新的主节点从而进行全量复制。对于这种情况应该从架构上规避, 比如提供故障转移功能。当主节点发生故障后, 手动提升从节点为主节点或者采用支持自动故障转移的哨兵或集群方案
- 复制积压缓冲区不足: 当主从节点网络中断后, 从节点再次连上主节点时会发送 psync{offset}{runId} 命令请求部分复制, 如果请求的偏移量不在主节点的积压缓冲区内, 则无法提供给从节点数据, 因此部分复制会退化为全量复制。
- 针对这种情况需要根据网络中断时长, 写命令数据量分析出合理的积压缓冲区大小。
- 网络中断一般有闪断、机房割接、网络分区等情况。这时网络中断的时长一般在分钟级 (net_break_time)。写命令数据量可以统计高峰期主节点每秒 info replication 的 master_repl_offset 差值获取 (write_size_per_minute)。
- 积压缓冲区默认为 1MB,对于大流量场景显然不够,这时需要增大积压缓冲区, 保证 repl_backlog_size > net_break_time * write_size_per_minute, 从而避免因复制积压缓冲区不足造成的全量复制
6.4.4 规避复制风暴
复制风暴是指大量从节点对同一主节点或者对同一台机器的多个主节点短时间内发起全量复制的过程。
1. 单主节点复制风暴
单主节点复制风暴一般发生在主节点挂载多个从节点的场景。当主节点重启恢复后, 从节点会发起全量复制流程.
Redis 中的优化:
- 只产生一份 RDB (多个从共享)
同时向多个从节点发送 RDB 快照, 可能使主节点的网络带宽消耗严重,造成主节点的延迟变大, 极端情况会发生主从节点连接断开, 导致复制失败.
解决方案:
- 减少从节点
- 采用树状复制结构
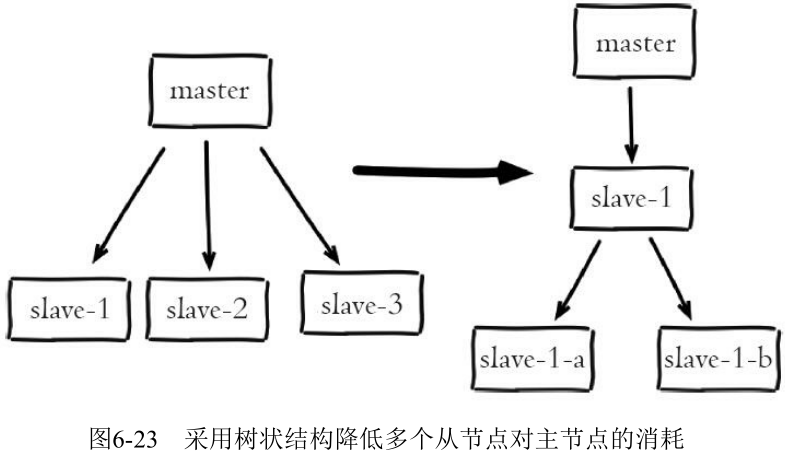
2. 单机器复制风暴
由于 Redis 的单线程架构, 通常单台机器会部署多个 Redis 实例。当一台机器 (machine) 上同时部署多个主节点 (master) 时, 如果这台机器出现故障或网络长时间中断, 当它重启恢复后, 会有大量从节点 (slave) 针对这台机器的主节点进行全量复制, 会造成当前机器网络带宽耗尽。
解决方案:
- 应该把主节点尽量分散在多台机器上, 避免在单台机器上部署过多的主节点
- 当主节点所在机器故障后提供故障转移机制, 避免机器恢复后进行密集的全量复制

若有收获,就点个赞吧
0 人点赞
