1. DDL数据定义
2. 数据库
2.1. 创建数据库
-- 语法CREATE DATABASE [IF NOT EXISTS] database_name[COMMENT database_comment][LOCATION hdfs_path][WITH DBPROPERTIES (property_name=property_value, ...)];
create database test
comment "Just for test"
location '/testdb' -- 此库会在hdfs中此路径下映射
with dpproperties("aaa"="bbb"); -- 属性 不太常用 记录一个键值对
2.2. 查询数据库
show database; -- 查询所有库
desc database test; -- 查询指定数据库信息
desc database extended test; -- 查询指定库数据库详细信息
show databases like 'db_hive*'; -- 过滤显示查询的数据库
2.3. 切换数据库
use db_hive; -- 切换到指定库
2.4. 删除数据库
drop database test; -- 删除指定数据库 如果库中有数据不能删除 必须为空
drop database cascade test; -- 删除数据库 无论是否库中有数据 慎用
drop database if exists db_hive2; -- 删除前判断是否存在此库
2.5. 修改数据库
数据库的其他元数据信息都是不可更改的,包括数据库名和数据库所在的目录位置。只能修改数据库的DBPROPERTIES设置键-值对属性值
alter database db_hive set dbproperties('createtime'='20170830'); -- 修改指定库的键值对值
3. 表
3.1. 创建表
-- 语法
CREATE [EXTERNAL] TABLE [IF NOT EXISTS] table_name
[(col_name data_type [COMMENT col_comment], ...)]
[COMMENT table_comment]
[PARTITIONED BY (col_name data_type [COMMENT col_comment], ...)]
[CLUSTERED BY (col_name, col_name, ...)
[SORTED BY (col_name [ASC|DESC], ...)] INTO num_buckets BUCKETS]
[ROW FORMAT row_format]
[STORED AS file_format]
[LOCATION hdfs_path]
[TBLPROPERTIES (property_name=property_value, ...)]
[AS select_statement]
CREATE TABLE 创建一个指定名字的表。如果相同名字的表已经存在,则抛出异常;用户可以用 IF NOT EXISTS 选项来忽略这个异常。
EXTERNAL关键字可以让用户创建一个外部表,在建表的同时可以指定一个指向实际数据的路径(LOCATION),在删除表的时候,内部表的元数据和数据会被一起删除,而外部表只删除元数据,不删除数据。
COMMENT:为表和列添加注释。
PARTITIONED BY创建分区表
CLUSTERED BY创建分桶表
SORTED BY不常用,对桶中的一个或多个列另外排序
ROW FORMAT
DELIMITED [FIELDS TERMINATED BY char] [COLLECTION ITEMS TERMINATED BY char]
[[MAP KEYS TERMINATED BY char] [LINES TERMINATED BY char]
| SERDE serde_name [WITH SERDEPROPERTIES (property_name=property_value, property_name=property_value, …)]
用户在建表的时候可以自定义SerDe或者使用自带的SerDe。如果没有指定ROW FORMAT 或者 ROWFORMAT DELIMITED,将会使用自带的SerDe。在建表的时候,用户还需要为表指定列,用户在指定表的列 的同时也会指定自定义的SerDe,Hive通过SerDe确定表的具体的列的数据。
SerDe是Serialize/Deserilize的简称, hive使用Serde进行行对象的序列与反序列化。
STORED AS指定存储文件类型
常用的存储文件类型:SEQUENCEFILE(二进制序列文件)、TEXTFILE(文本)、RCFILE(列式存储格式文件)
如果文件数据是纯文本,可以使用STORED AS TEXTFILE。如果数据需要压缩,使用 STORED AS SEQUENCEFILE。LOCATION :指定表在HDFS上的存储位置。
AS:后跟查询语句,根据查询结果创建表。
LIKE允许用户复制现有的表结构,但是不复制数据。
create table test
(id int comment "ID", name string comment "Nmae")
comment "Test Table"
row format delimited fields terminated by '\t' -- 以\t划分切合
location "/test_table" -- 会映射在当前hdfs指定文件夹
tblproperties("aaa"="bbb");
3.2. 查询结果建表
create table stu_result as select * from stu_par where id=1001;
3.3. 查询表
show tables; -- 查询当前库所有表
desc test; -- 查看表信息
desc formatted test; -- 查询表的详细信息
3.4. 修改表
- 重命名表
ALTER TABLE table_name RENAME TO new_table_name -- 语法
alter table test rename to new_test;
- 更新列
ALTER TABLE table_name CHANGE [COLUMN] col_old_name col_new_name column_type [COMMENT col_comment] [FIRST|AFTER column_name] -- 语法
alter table test change id id string; -- 将test表中的id列改为string类型
- 增加列和替换列
ALTER TABLE table_name ADD|REPLACE COLUMNS (col_name data_type [COMMENT col_comment], ...) -- 语法
alter table test add columns(class string); -- 在表中增加class类 string类型 可以添加多列
alter table test replace columns(id double, name string); -- 将指定表的结构体换成指定结构体 原先的列不保留
3.5. 删除表
drop table test;
4. 内外部表
我们默认创建的表是内部表 当建表时加上external关键字 则创建一个外部表
create external table test
(id int, name string)
row format delimited fields terminated by '\t';
# 向test表导入数据
load data local inpath "/opt/module/datas/student.txt" into table test;
外部表,当删除该表并不会删除掉这份数据,不过描述表的元数据信息会被删除掉。而表数据存放在hdfs上 元数据存储在mysql中
4.1. 外部表和内部表转换
alter table test set tblproperties('EXTERNAL'='TRUE'); -- true为外部表 flase为内部表
5. 分区表
-- 创建分区表
create table stu_par
(id int, name string)
partitioned by(class string) -- 设置为分区表 区名为class 类型为sring
row format delimited fields terminated by '\t';
向表插入数据
load data local inpath "/opt/module/datas/student.txt" into table stu_par partition(class='01'); -- 插入指定分区
此时会在表文件夹中以 class=01 为文件名存放数据
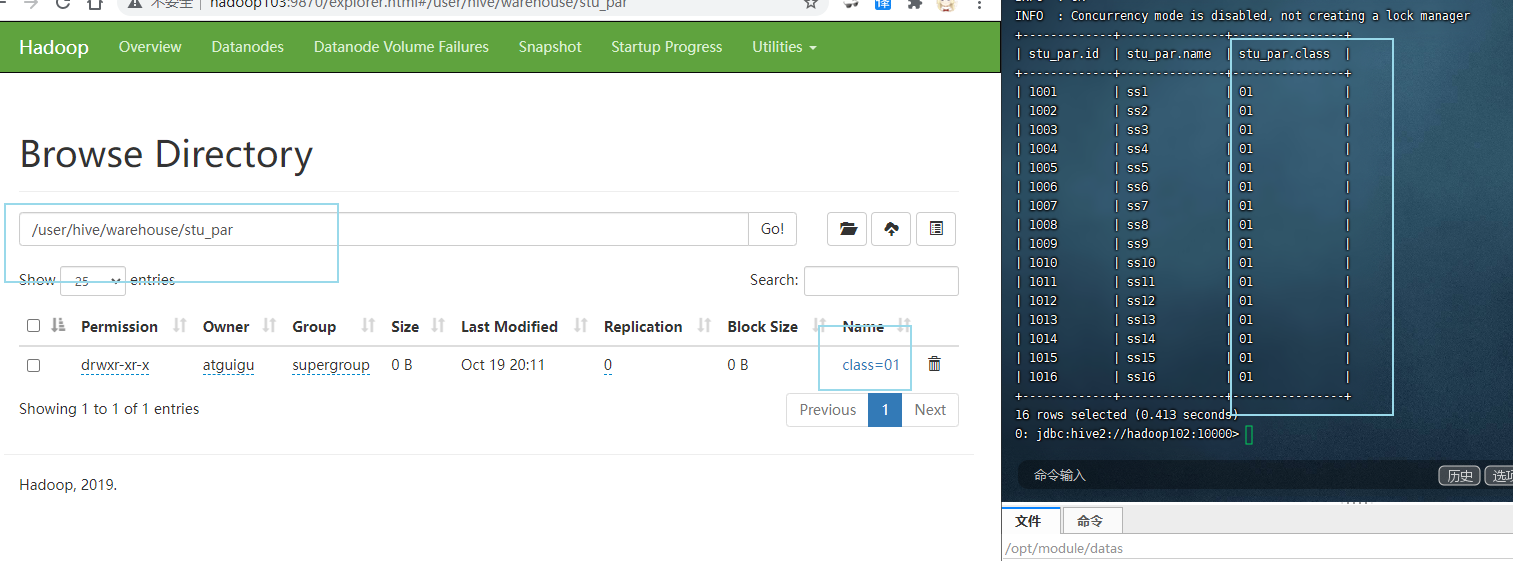
本质上是以文件来划分分区(分组) 但此表整合到一起 并以指定分区名区分
如果数据结构不同 也会整合一起
5.1. 分区的作用
在hive没有索引的概念 所有默认查询是全表扫描 如果数据庞大那么查询效率会很低 我们可以通过分区表来查询表中指定分区中的数据
-- 查询表时 指定分区 可以减少数据扫描量
select * from stu_par where class="01";
5.2. 查询分区表的分区
show partitions stu_par;
5.3. 修复分区
如果提前准备数据, 但是没有元数据 在hive是查询不到 我们可以通过修复 来导入文件数据
- 添加分区
alter table stu_par add partition(class="03"); -- 表文件夹中的分区文件夹名称必须与这里一致 否则无法映射
- 直接修复
msck repair table stu_par; -- 会自动扫描当前表下的文件夹 只要以分区名=xx为关键字的都会被添加到分区当中
- 上传时带分区
load data local inpath "/opt/module/datas/student.txt" into table stu_par partition(class='04');
5.4. 二级分区
create table stu_par2
(id int, name string)
partitioned by(grade string,class string) -- 二级分区
row format delimited fields terminated by '\t';

插入数据
load data local inpath "/opt/module/datas/student.txt" into table stu_par2 partition(grade='01',class='03');
目录结构为 stu_par2 —> grade=01 —> class=03 —> student.txt(数据文件)
多少个分区就多少个键值对文件夹

5.5. 分区的增删
- 增加分区
alter table stu_par add partition(class="04"); -- 增加分区
alter table stu_par add partition(class="05") partition(class='06'); -- 增加多个分区 注意是空格间隔
- 删除分区
alter table stu_par drop partition(class="05");
alter table stu_par drop partition(class="05"),partition(class="07"); -- 删除多个分区 注意是逗号间隔

若有收获,就点个赞吧
0 人点赞
