1. A Neural Probabilistic Language Model
本文算是训练语言模型的经典之作,Bengio 将神经网络引入语言模型的训练中,并得到了词向量这个副产物。词向量对后面深度学习在自然语言处理方面有很大的贡献,也是获取词的语义特征的有效方法
其主要架构为三层神经网络,如下图所示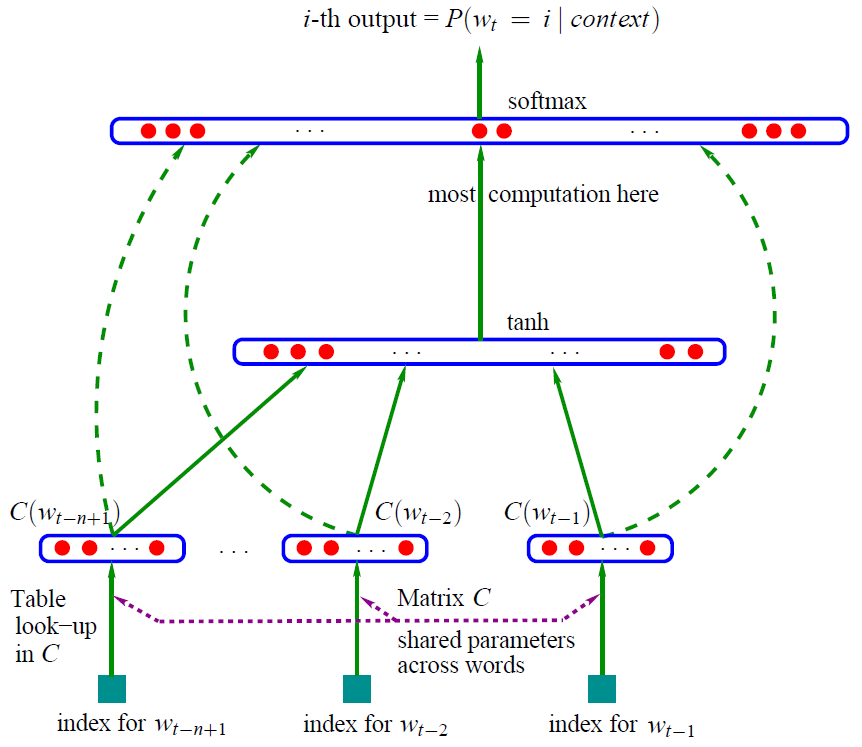
现在的任务是输入 wt−n+1,…,wt−1 这前 n-1 个单词,然后预测出下一个单词 wt
数学符号说明:
- C(i):单词 w 对应的词向量,其中 i 为词 w 在整个词汇表中的索引
- C:词向量,大小为 |V|×m 的矩阵
- |V|:词汇表的大小,即预料库中去重后的单词个数
- m:词向量的维度,一般是 50 到 200
- H:隐藏层的 weight
- d:隐藏层的 bias
- U:输出层的 weight
- b:输出层的 bias
- W:输入层到输出层的 weight
- h:隐藏层神经元个数
计算流程:
- 首先将输入的 n-1 个单词索引转为词向量,然后将这 n-1 个词向量进行 concat,形成一个 (n-1)*w 的向量,用 X 表示
- 将 X 送入隐藏层进行计算,hiddenout=tanh(d+X∗H)
- 输出层共有 |V| 个节点,每个节点 yi 表示预测下一个单词 i 的概率,y 的计算公式为 y=b+X∗W+hiddenout∗U
2.代码实现(PyTorch)
import torchimport torch.nn as nnimport torch.optim as optimimport torch.utils.data as Datadtype = torch.FloatTensorsentences = [ "i like dog", "i love coffee", "i hate milk"]word_list = " ".join(sentences).split() # ['i', 'like', 'dog', 'dog', 'i', 'love', 'coffee', 'i', 'hate', 'milk']word_list = list(set(word_list)) # ['i', 'like', 'dog', 'love', 'coffee', 'hate', 'milk']word2idx = {w: i for i, w in enumerate(word_list)} # {'i':0, 'like':1, 'dog':2, 'love':3, 'coffee':4, 'hate':5, 'milk':6}idx2word = {i: w for i, w in enumerate(word_list)} # {0:'i', 1:'like', 2:'dog', 3:'love', 4:'coffee', 5:'hate', 6:'milk'}VOCAB_SIZE = len(word_list) # number of Vocabulary, just like |V|, in this task n_class=7# NNLM(Neural Network Language Model) ParameterSEQ_LEN = len(sentences[0].split())-1 # n-1 in paper, look back n_step words and predict next word. In this task n_step=2HIDDEN_SIZE = 2 # h in paperEMBED_SIZE = 2 # m in paper, word embedding dimdef make_batch(sentences):input_batch = []target_batch = []for sen in sentences:word = sen.split()input = [word2idx[n] for n in word[:-1]] # [0, 1], [0, 3], [0, 5]target = word2idx[word[-1]] # 2, 4, 6input_batch.append(input) # [[0, 1], [0, 3], [0, 5]]target_batch.append(target) # [2, 4, 6]return input_batch, target_batchinput_batch, target_batch = make_batch(sentences)input_batch = torch.LongTensor(input_batch)target_batch = torch.LongTensor(target_batch)dataset = Data.TensorDataset(input_batch, target_batch)loader = Data.DataLoader(dataset=dataset, batch_size=16, shuffle=True)class NNLM(nn.Module):def __init__(self,vocab_size,embed_size,hidden_size,seq_len):super(NNLM, self).__init__()self.C = nn.Embedding(vocab_size, embed_size)self.H = nn.Parameter(torch.randn(seq_len*embed_size, hidden_size).type(dtype))self.W = nn.Parameter(torch.randn(seq_len*embed_size, vocab_size).type(dtype))self.d = nn.Parameter(torch.randn(hidden_size).type(dtype))self.U = nn.Parameter(torch.randn(hidden_size, vocab_size).type(dtype))self.b = nn.Parameter(torch.randn(vocab_size).type(dtype))def forward(self, X):'''X: [batch_size, n_step]'''X = self.C(X) # [batch_size, n_step] => [batch_size, seq_len, embed_size]X = X.view(-1,X.size(1)*X.size(2)) # [batch_size, seq_len*embed_size]hidden_out = torch.tanh(self.d + torch.mm(X, self.H)) # [batch_size, hidden_size]output = self.b + torch.mm(X, self.W) + torch.mm(hidden_out, self.U) # [batch_size, vocab_size]return outputmodel = NNLM(VOCAB_SIZE,EMBED_SIZE,HIDDEN_SIZE,SEQ_LEN)criterion = nn.CrossEntropyLoss()optimizer = optim.Adam(model.parameters(), lr=1e-3)# Trainingfor epoch in range(5000):for batch_x, batch_y in loader:optimizer.zero_grad()output = model(batch_x)# output : [batch_size, n_class], batch_y : [batch_size] (LongTensor, not one-hot)loss = criterion(output, batch_y)if (epoch + 1)%1000 == 0:print('Epoch:', '%04d' % (epoch + 1), 'cost =', '{:.6f}'.format(loss))loss.backward()optimizer.step()# Predictpredict = model(input_batch).data.max(1, keepdim=True)[1]# Testprint([sen.split()[:SEQ_LEN] for sen in sentences], '->', [idx2word[n.item()] for n in predict.squeeze()])

若有收获,就点个赞吧
0 人点赞
