B 站视频讲解
本文介绍一下如何使用 PyTorch 复现 TextRNN,实现预测一句话的下一个词
参考这篇论文 Finding Structure in Time(1990),如果你对 RNN 有一定的了解,实际上不用看,仔细看我代码如何实现即可。如果你对 RNN 不太了解,请仔细阅读我这篇文章 RNN Layer,结合 PyTorch 讲的很详细
现在问题的背景是,我有 n 句话,每句话都由且仅由 3 个单词组成。我要做的是,将每句话的前两个单词作为输入,最后一词作为输出,训练一个 RNN 模型
导库
'''code by Tae Hwan Jung(Jeff Jung) @graykode, modify by wmathor'''import torchimport numpy as npimport torch.nn as nnimport torch.optim as optimimport torch.utils.data as Datadtype = torch.FloatTensor
准备数据
sentences=["i like dog","i love coffee","i hate milk"]word_list=" ".join(sentences).split()vocab_list=list(set(word_list))VOCAB_SIZE=len(vocab_list)n_class=VOCAB_SIZEword2idx={w:i for i,w in enumerate(vocab_list)}idx2word={i:w for i,w in enumerate(vocab_list)}
预处理数据,构建 Dataset,定义 DataLoader,输入数据用 one-hot 编码
def make_data(sentences):input_data=[]output_data=[]for sen in sentences:word=sen.split()input=[word2idx[w] for w in word[:-1]]output=[word2idx[word[-1]]]input_data.append(np.eye(n_class)[input])output_data.append(output)return input_data,output_datainput_data,output_data=make_data(sentences)input_data,output_data=torch.Tensor(input_data),torch.LongTensor(output_data)dataset=Data.TensorDataset(input_data,output_data)loader=Data.DataLoader(dataset,batch_size,True)
以上的代码我想大家应该都没有问题,接下来就是定义网络架构
class TextRNN(nn.Module):
def __init__(self,embed_size,hidden_size,vocab_size):
super(TextRNN,self).__init__()
self.rnn=nn.RNN(embed_size,hidden_size)
self.fc=nn.Linear(hidden_size,vocab_size)
def forward(self,hidden,x):
'''
hidden:[num_layers*num_directions,bitch_size,hidden_size]
x:[bitch_size,seq_len,embed_size]
'''
x=x.transpose(0,1) #x.shape:[seq_len,bitch_size,embed_size]
output,hidden=self.rnn(x,hidden)
#output:[seq_len,bitch_size,num_directions*hidden_size]
#hidden:[num_layers*num_directions,bitch_size,hidden_size]
output=output[-1] #shape:[bitch_size,num_directions*hidden_size]
pred=self.fc(output) #shape:[bitch_size,vocab_size]
return pred
以上代码每一步都值得说一下,首先是nn.RNN(input_size, hidden_size)的两个参数,input_size表示每个词的编码维度,由于我是用的 one-hot 编码,而不是 WordEmbedding,所以input_size就等于词库的大小len(vocab),即n_class。然后是hidden_size,这个参数没有固定的要求,你想将输入数据的维度转为多少维,就设定多少
对于通常的神经网络来说,输入数据的第一个维度一般都是 batch_size。而 PyTorch 中nn.RNN()要求将 batch_size 放在第二个维度上,所以需要使用x.transpose(0, 1)将输入数据的第一个维度和第二个维度互换
然后是 rnn 的输出,rnn 会返回两个结果,即上面代码的 out 和 hidden,关于这两个变量的区别,我在之前的博客也提到过了,如果不清楚,可以看我上面提到的 RNN Layer 这篇博客。这里简单说就是,out 指的是下图的红框框起来的所有值;hidden 指的是下图蓝框框起来的所有值。我们需要的是最后时刻的最后一层输出,即 Y3 的值,所以使用out=out[-1]将其获取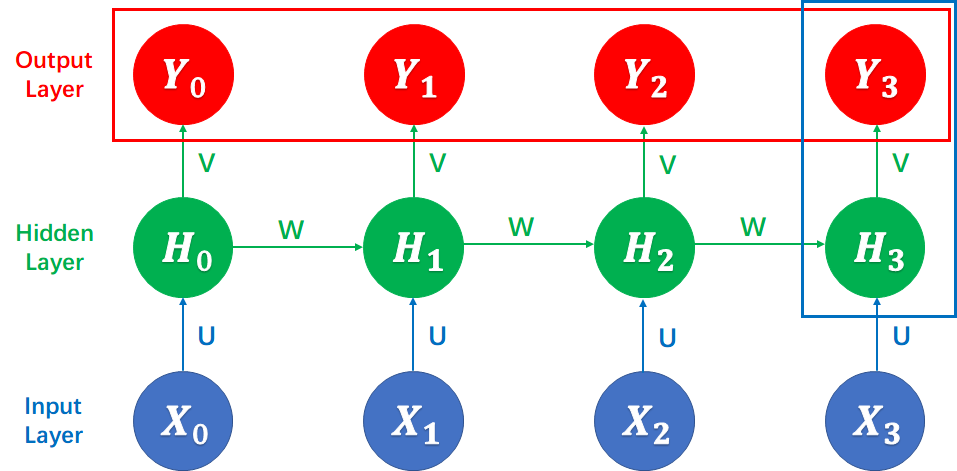
剩下的部分就比较简单了,训练测试即可
EMBED_SIZE=input_data.shape[2]
#TextRNN parameters
batch_size = 2
seq_len=2
HIDDEN_SIZE=5
model=TextRNN(EMBED_SIZE,HIDDEN_SIZE,VOCAB_SIZE)
criterion=nn.CrossEntropyLoss()
optimizer=optim.Adam(model.parameters(),lr=1e-3)
for epoch in range(5000):
for x,y in loader:
hidden=torch.zeros(1,x.shape[0],HIDDEN_SIZE)
pred=model(hidden,x) #shape:[bitch_size,vocab_size]
y=y.squeeze(1)
loss=criterion(pred,y)
if (epoch+1)%1000==0:
print('Epoch:','%04d'%(epoch+1),'loss:','{:.6f}'.format(loss))
optimizer.zero_grad()
loss.backward()
optimizer.step()
测试
sen='i like'
input=torch.Tensor(np.eye(VOCAB_SIZE)[[word2idx[w] for w in sen.split()]]).unsqueeze(0)
hidden=torch.zeros(1,input.shape[0],HIDDEN_SIZE)
predict=model(hidden,input).data
print(sen,'->',idx2word[predict.max(1)[1].item()])

若有收获,就点个赞吧
0 人点赞
