本文主要介绍一篇将 CNN 应用到 NLP 领域的一篇论文 Convolutional Neural Networks for Sentence Classification,然后给出 PyTorch 实现
论文比较短,总体流程也不复杂,最主要的是下面这张图,只要理解了这张图,就知道如何写代码了。如果你不了解 CNN,请先看我的这篇文章 通俗理解CNN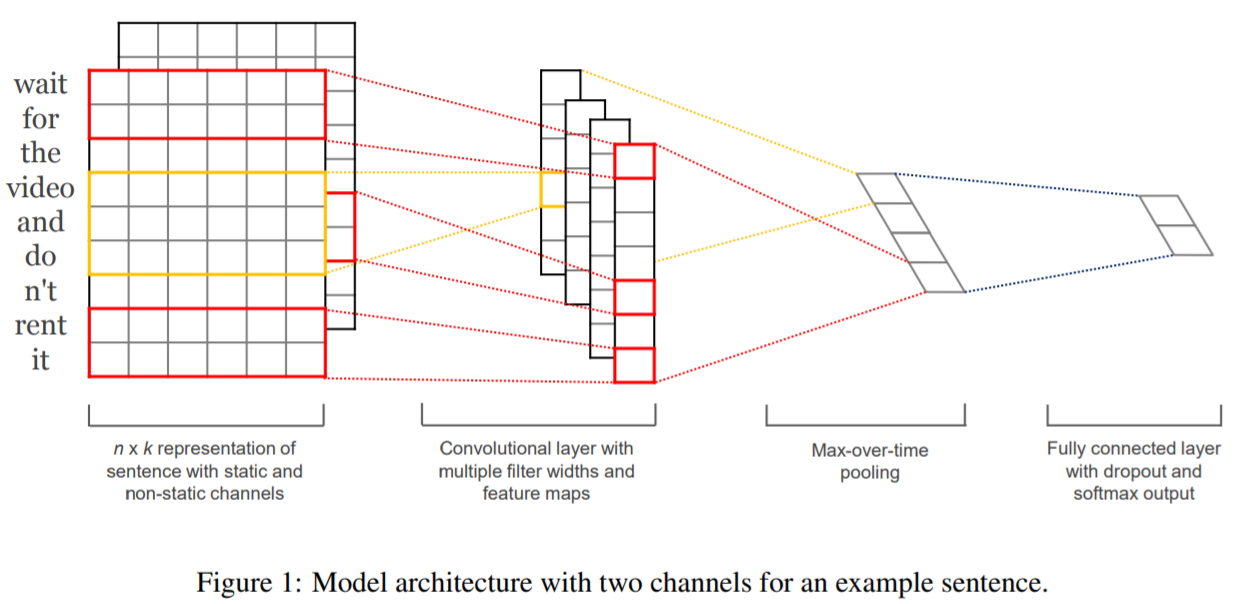
下图的 feature map 是将一句话中的各个词通过 WordEmbedding 得到的,feature map 的宽为 embedding 的维度,长为一句话的单词数量。例如下图中,很明显就是用一个 6 维的向量去编码每个词,并且一句话中有 9 个词
之所以有两张 feature map,你可以理解为 batchsize 为 2
其中,红色的框代表的就是卷积核。而且很明显可以看出,这是一个长宽不等的卷积核。有意思的是,卷积核的宽可以认为是 n-gram,比方说下图卷积核宽为 2,所以同时考虑了 “wait” 和 “for” 两个单词的词向量,因此可以认为该卷积是一个类似于 bigram 的模型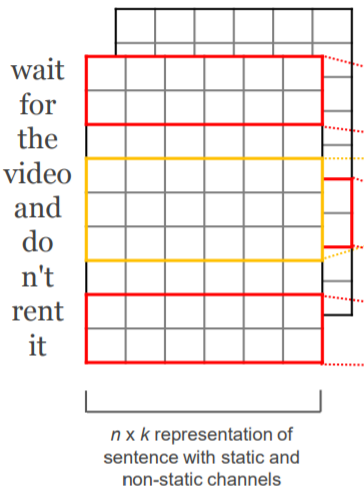
后面的部分就是传统 CNN 的步骤,激活、池化、Flatten,没什么好说的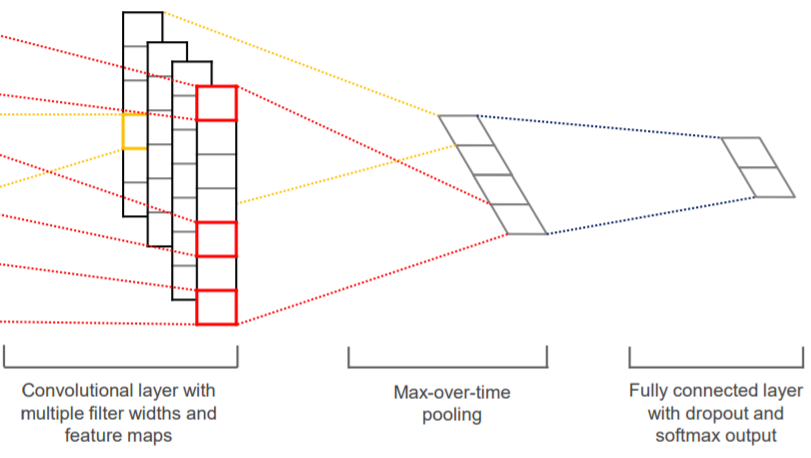
代码实现(PyTorch 版)
源码来自于 nlp-tutorial,我在其基础上进行了修改(原本的代码感觉有很多问题)
'''code by Tae Hwan Jung(Jeff Jung) @graykode, modify by wmathor'''import torchimport numpy as npimport torch.nn as nnimport torch.optim as optimimport torch.utils.data as Dataimport torch.nn.functional as Fdtype = torch.FloatTensordevice = torch.device("cuda" if torch.cuda.is_available() else "cpu")
下面代码就是定义一些数据,以及设置一些常规参数
# 3 words sentences (=sequence_length is 3)sentences = ["i love you", "he loves me", "she likes baseball", "i hate you", "sorry for that", "this is awful"]labels = [1, 1, 1, 0, 0, 0] # 1 is good, 0 is not good.# TextCNN ParameterSEQUENCE_LEN = len(sentences[0].split()) # every sentences contains sequence_length(=3) wordsNUM_CLASSES = len(set(labels)) # num_classes=2word_list = " ".join(sentences).split()vocab = list(set(word_list))word2idx = {w: i for i, w in enumerate(vocab)}VOCAB_SIZE = len(vocab)EMBEDDING_SIZE = 2batch_size = 3
数据预处理
def make_data(sentences, labels):
inputs = []
for sen in sentences:
inputs.append([word2idx[n] for n in sen.split()])
targets = []
for out in labels:
targets.append(out) # To using Torch Softmax Loss function
return inputs, targets
input_batch, target_batch = make_data(sentences, labels)
input_batch, target_batch = torch.LongTensor(input_batch), torch.LongTensor(target_batch)
dataset = Data.TensorDataset(input_batch, target_batch)
loader = Data.DataLoader(dataset, batch_size, True)
构建模型
class TextCNN(nn.Module):
def __init__(self,vocab_size,embedding_size,input_channel,output_channel,filter_height, filter_width,sequence_len,num_classes):
super(TextCNN, self).__init__()
self.embed = nn.Embedding(vocab_size, embedding_size)
self.conv = nn.Sequential(
# conv : [input_channel(=1), output_channel, (filter_height, filter_width), stride=1]
nn.Conv2d(input_channel, output_channel, (filter_height,filter_width)),
nn.ReLU(),
# pool : ((filter_height, filter_width))
nn.MaxPool2d((sequence_len-filter_height+1,1))
)
# fc
self.fc = nn.Linear(output_channel, num_classes)
def forward(self, X):
'''
X: [batch_size, sequence_length]
'''
batch_size = X.shape[0]
embedding_X = self.embed(X) # [batch_size, sequence_length, embedding_size]
embedding_X = embedding_X.unsqueeze(1) # add channel(=1) [batch, channel(=1), sequence_length, embedding_size]
conved = self.conv(embedding_X) # [batch_size, output_channel]
flatten = conved.view(batch_size, -1)
output = self.fc(flatten)
return output
下面详细介绍一下数据在网络中流动的过程中维度的变化。输入数据是个矩阵,矩阵维度为 [batch_size, seqence_length],输入矩阵的数字代表的是某个词在整个词库中的索引(下标)
首先通过 Embedding 层,也就是查表,将每个索引转为一个向量,比方说 12 可能会变成 [0.3,0.6,0.12,…],因此整个数据无形中就增加了一个维度,变成了 [batch_size, sequence_length, embedding_size]
之后使用unsqueeze(1)函数使数据增加一个维度,变成 [batch_size, 1, sequence_length, embedding_size]。现在的数据才能做卷积,因为在传统 CNN 中,输入数据就应该是[batch_size, in_channel, height, width] 这种维度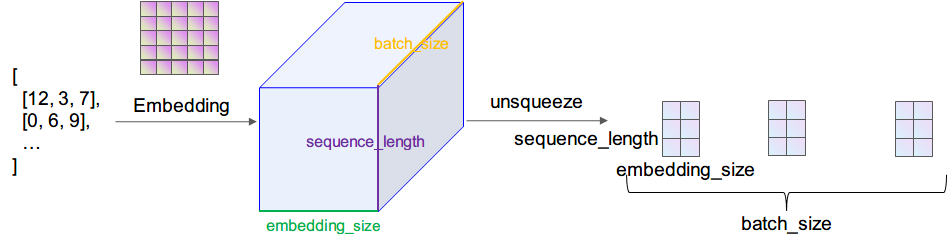
[batch_size, 1, 3, 2] 的输入数据通过nn.Conv2d(1, 3, (2, 2))的卷积之后,得到的就是 [batch_size, 3, 2, 1] 的数据,由于经过 ReLU 激活函数是不改变维度的,所以就没画出来。最后经过一个nn.MaxPool2d((2, 1))池化,得到的数据维度就是 [batch_size, 3, 1, 1]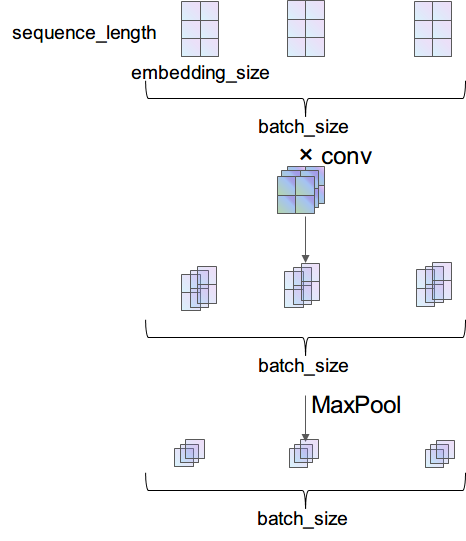
训练
model = TextCNN().to(device)
criterion = nn.CrossEntropyLoss().to(device)
optimizer = optim.Adam(model.parameters(), lr=1e-3)
# Training
for epoch in range(5000):
for batch_x, batch_y in loader:
batch_x, batch_y = batch_x.to(device), batch_y.to(device)
pred = model(batch_x)
loss = criterion(pred, batch_y)
if (epoch + 1) % 1000 == 0:
print('Epoch:', '%04d' % (epoch + 1), 'loss =', '{:.6f}'.format(loss))
optimizer.zero_grad()
loss.backward()
optimizer.step()
测试
# Test
test_text = 'i hate me'
tests = [[word2idx[n] for n in test_text.split()]]
test_batch = torch.LongTensor(tests).to(device)
# Predict
model = model.eval()
predict = model(test_batch).data.max(1, keepdim=True)[1]
if predict[0][0] == 0:
print(test_text,"is Bad Mean...")
else:
print(test_text,"is Good Mean!!")

若有收获,就点个赞吧
0 人点赞
