B 站视频讲解
本文介绍一下如何使用 PyTorch 复现 Seq2Seq,实现简单的机器翻译应用,请先简单阅读论文 Learning Phrase Representations using RNN Encoder–Decoder for Statistical Machine Translation(2014),了解清楚 Seq2Seq 结构是什么样的,之后再阅读本篇文章,可达到事半功倍的效果
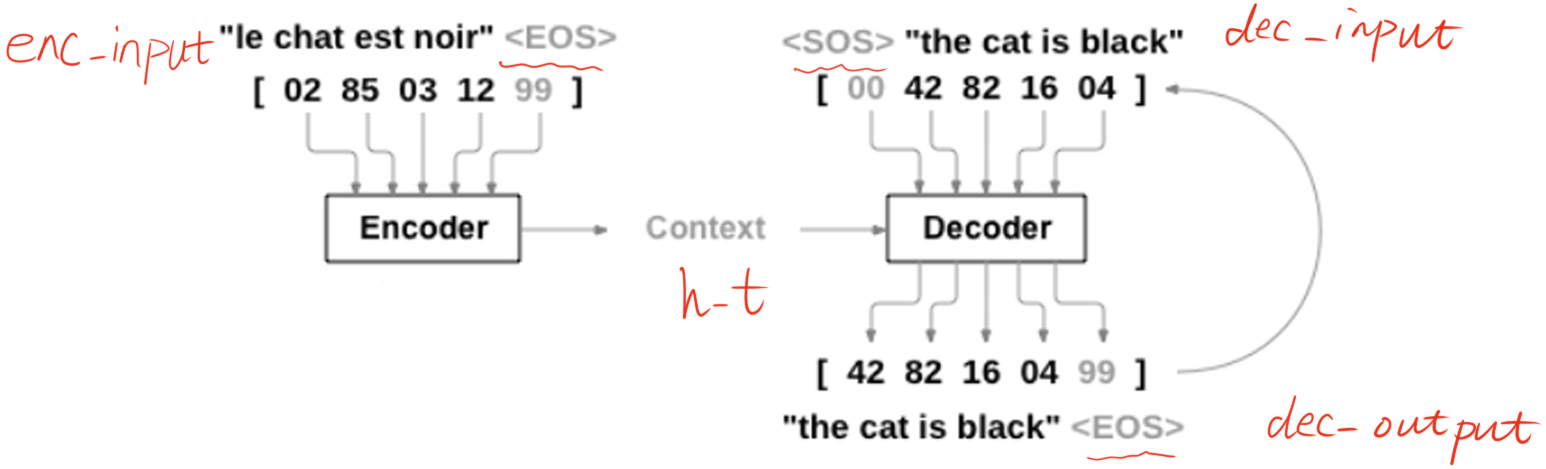
我看了很多 Seq2Seq 网络结构图,感觉 PyTorch 官方提供的这个图是最好理解的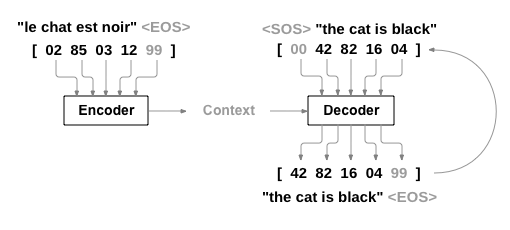
首先,从上面的图可以很明显的看出,Seq2Seq 需要对三个变量进行操作,这和之前我接触到的所有网络结构都不一样。我们把 Encoder 的输入称为 enc_input,Decoder 的输入称为 dec_input, Decoder 的输出称为 dec_output。下面以一个具体的例子来说明整个 Seq2Seq 的工作流程
下图是一个由 LSTM 组成的 Encoder 结构,输入的是 “go away” 中的每个字母(包括空格),我们只需要最后一个时刻隐藏状态的信息,即 ht 和 ct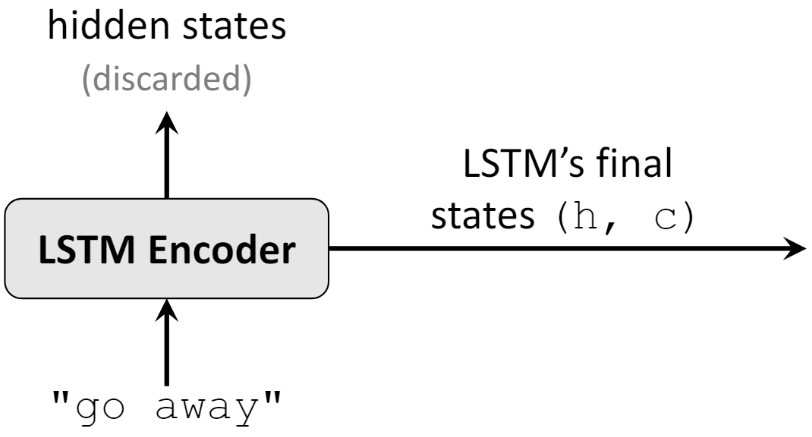
然后将 Encoder 输出的 ht 和 ct 作为 Decoder 初始时刻隐藏状态的输入 h0、c0,如下图所示。同时 Decoder 初始时刻输入层输入的是代表一个句子开始的标志(由用户定义,”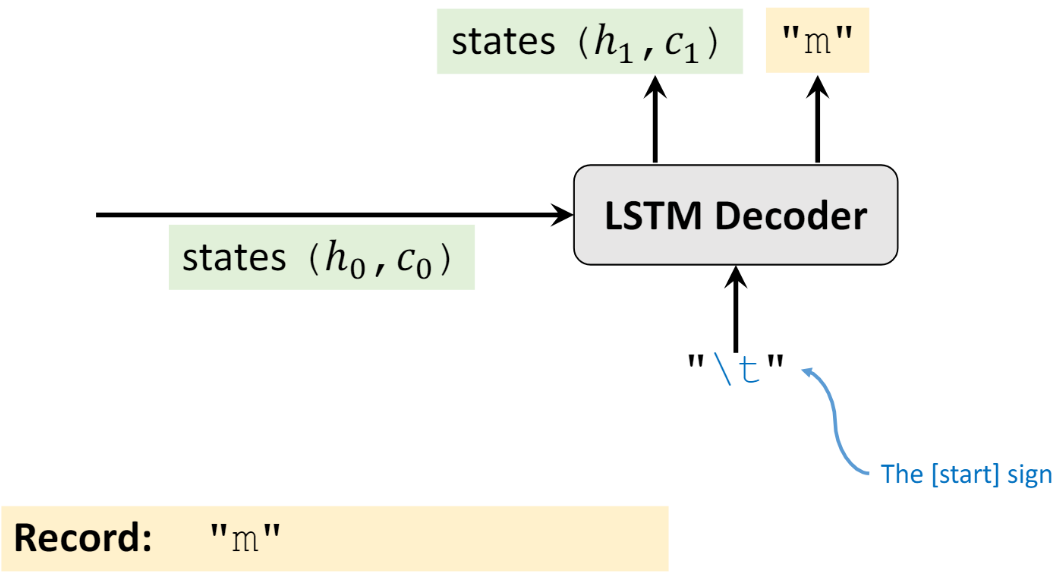
再将 h1、c1 和 “m” 作为输入,得到输入 “a”,以及新的隐藏状态 h2 和 c2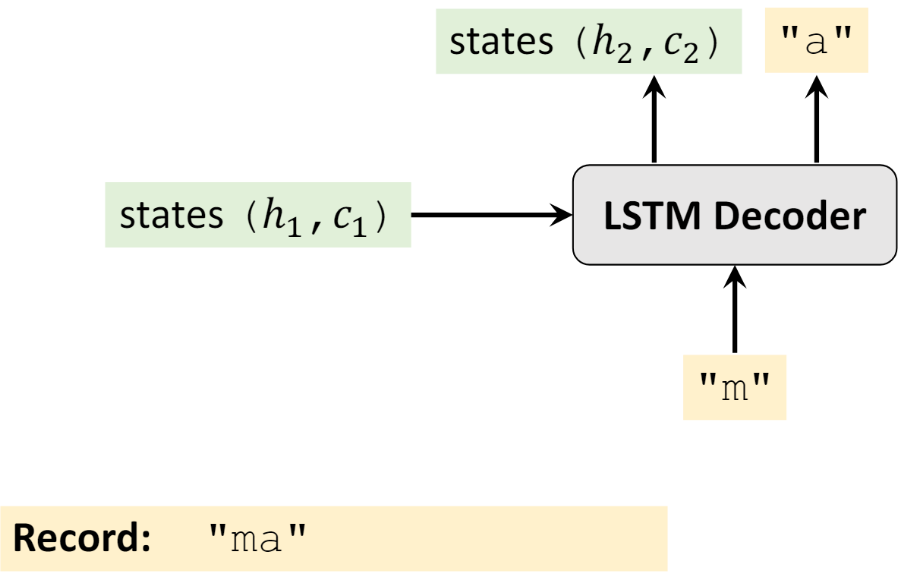
重复上述步骤,直到最终输出句子的结束标志(由用户定义,”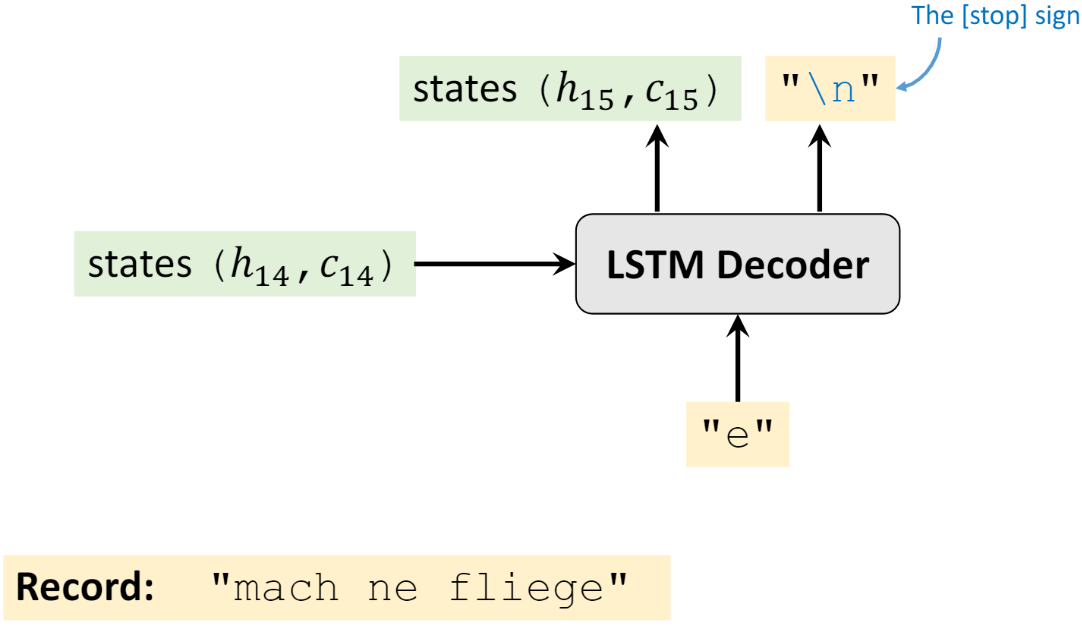
在 Decoder 部分,大家可能会有以下几个问题,我做下解答
- 训练过程中,如果 Decoder 停不下来怎么办?即一直不输出句子的终止标志
- 首先,训练过程中 Decoder 应该要输出多长的句子,这个是已知的,假设当前时刻已经到了句子长度的最后一个字符了,并且预测的不是终止标志,那也没有关系,就此打住,计算 loss 即可
- 测试过程中,如果 Decoder 停不下来怎么办?例如预测得到 “wasd s w \n sdsw \n……….(一直输出下去)”
- 不会停不下来的,因为测试过程中,Decoder 也会有输入,只不过这个输入是很多个没有意义的占位符,例如很多个 “
“。由于 Decoder 有有限长度的输入,所以 Decoder 一定会有有限长度的输出。那么只需要获取第一个终止标志之前的所有字符即可,对于上面的例子,最终的预测结果为 “wasd s w”
- 不会停不下来的,因为测试过程中,Decoder 也会有输入,只不过这个输入是很多个没有意义的占位符,例如很多个 “
- Decoder 的输入和输出,即
dec_input和dec_output有什么关系?- 在训练阶段,不论当前时刻 Decoder 输出什么字符,下一时刻 Decoder 都按照原来的 “计划” 进行输入。举个例子,假设
dec_input="\twasted",首先输入 “\t” 之后,Decoder 输出的是 “m” 这个字母,记录下来就行了,并不会影响到下一时刻 Decoder 继续输入 “w” 这个字母 - 在验证或者测试阶段,Decoder 每一时刻的输出是会影响到输入的,因为在验证或者测试时,网络是看不到结果的,所以它只能循环的进行下去。举个例子,我现在要将英语 “wasted” 翻译为德语 “verschwenden”。那么 Decoder 一开始输入 “\t”,得到一个输出,假如是 “m”,下一时刻 Decoder 会输入 “m”,得到输出,假如是 “a”,之后会将 “a” 作为输入,得到输出…… 如此循环往复,直到最终时刻
- 在训练阶段,不论当前时刻 Decoder 输出什么字符,下一时刻 Decoder 都按照原来的 “计划” 进行输入。举个例子,假设
这里说句题外话,其实我个人觉得 Seq2Seq 与 AutoEncoder 非常相似
下面开始代码讲解
首先导库,这里我用’S’作为开始标志,’E’作为结束标志,如果输入或者输入过短,我使用’?’进行填充
# code by Tae Hwan Jung(Jeff Jung) @graykode, modify by wmathorimport torchimport numpy as npimport torch.nn as nnimport torch.utils.data as Datadevice = torch.device('cuda' if torch.cuda.is_available() else 'cpu')# S: Symbol that shows starting of decoding input# E: Symbol that shows starting of decoding output# ?: Symbol that will fill in blank sequence if current batch data size is short than n_step
定义数据集以及参数,这里数据集我设定的非常简单,可以看作是翻译任务,只不过是将英语翻译成英语罢了。n_step 保存的是最长单词的长度,其它所有不够这个长度的单词,都会在其后用’?’填充
#定义数据集及相关参数letter=[c for c in 'SE?abcdefghijklmnopqrstuvwxyz']letter_size=len(letter) #29letter2idx={c:i for i,c in enumerate(letter)}batch_size=3seq_data = [['man', 'women'], ['black', 'white'], ['king', 'queen'], ['girl', 'boy'], ['up', 'down'], ['high', 'low']]letter_len=max([max(len(i),len(j)) for i,j in seq_data]) #5hidden_size=128
下面是对数据进行处理,主要做的是,首先对单词长度不够的,用’?’进行填充;然后将 Encoder 的输入数据末尾添加终止标志’E’,Decoder 的输入数据开头添加开始标志’S’,Decoder 的输出数据末尾添加结束标志’E’,其实也就如下图所示
def make_data(seq_data):enc_input_all,dec_input_all,dec_output_all=[],[],[]for seq in seq_data:#每当我传入一条数据,把翻译前后的序列长度变为letter_lenfor i in range(2):seq[i]=seq[i]+'?'*(letter_len-len(seq[i]))#给相应的序列编码enc_input=[letter2idx[c] for c in (seq[0]+'E')]dec_input=[letter2idx[c] for c in ('S'+seq[1])]dec_output=[letter2idx[c] for c in (seq[1]+'E')]#获取一个batch的数据enc_input_all.append(np.eye(letter_size)[enc_input]) #[letter_len+1,letter_size]dec_input_all.append(np.eye(letter_size)[dec_input]) #[letter_len+1,letter_size]dec_output_all.append(np.eye(letter_size)[dec_output]) #[letter_len+1,letter_size]return torch.Tensor(enc_input_all),torch.Tensor(dec_input_all),torch.LongTensor(dec_output_all)'''
由于这里有三个数据要返回,所以需要自定义 DataSet,具体来说就是继承torch.utils.data.Dataset类,然后实现里面的__len__以及__getitem__方法
class TranslateDataSet(Data.Dataset):
def __init__(self, enc_input_all, dec_input_all, dec_output_all):
super(TranslateDataSet,self).__init__()
self.enc_input_all = enc_input_all
self.dec_input_all = dec_input_all
self.dec_output_all = dec_output_all
def __len__(self): # return dataset size
return len(self.enc_input_all)
def __getitem__(self, idx):
return self.enc_input_all[idx], self.dec_input_all[idx], self.dec_output_all[idx]
enc_input_all, dec_input_all, dec_output_all = make_data(seq_data)
loader = Data.DataLoader(TranslateDataSet(enc_input_all, dec_input_all, dec_output_all), batch_size, True)
下面定义 Seq2Seq 模型,我用的是简单的 RNN 作为编码器和解码器。如果你对 RNN 比较了解的话,定义网络结构的部分其实没什么说的,注释我也写的很清楚了,包括数据维度的变化
#模型的定义
class Seq2Seq(nn.Module):
def __init__(self,letter_size,hidden_size):
super(Seq2Seq,self).__init__()
self.encoder=nn.RNN(input_size=letter_size,hidden_size=hidden_size,dropout=0.5)
self.decoder=nn.RNN(input_size=letter_size,hidden_size=hidden_size,dropout=0.5)
self.fc=nn.Linear(in_features=hidden_size,out_features=letter_size)
def forward(self,encoder_input,decoder_input,h_0):
'''
encoder_input:[batch_size,letter_len+1,letter_size]
dncoder_input:[batch_size,letter_len+1,letter_size]
h_0:[num_layers*num_directional,batch_size,hidden_size]
'''
#shape:[letter_len+1,batch_size,letter_size]
encoder_input=encoder_input.transpose(0,1)
#shape:[letter_len+1,batch_size,letter_size]
decoder_input=decoder_input.transpose(0,1)
_,h_t=self.encoder(encoder_input,h_0) #h_t的shape同h_0
output,_=self.decoder(decoder_input,h_t) #output:[letter_len+1,batch_size,hidden_size]
output=self.fc(output)
return output
下面是训练,由于输出的 pred 是个三维的数据,所以计算 loss 需要每个样本单独计算,因此就有了下面 for 循环的代码
model=Seq2Seq(LETTER_SIZE,HIDDEN_SIZE).to(device)
criterion=nn.CrossEntropyLoss().to(device)
optimizer=torch.optim.Adam(model.parameters(),lr=1e-3)
#训练
for epoch in range(5000):
for encoder_input_all,decoder_input_all,decoder_output_all in loader:
h_0=torch.zeros(1,batch_size,HIDDEN_SIZE).to(device)
encoder_input_all=encoder_input_all.to(device)
decoder_input_all=decoder_input_all.to(device)
decoder_output_all=decoder_output_all.to(device)
pred=model(encoder_input_all,decoder_input_all,h_0) #letteer_len,batch_size,letter_size
pred=pred.transpose(0,1) #[batch_size,letter_len,letter_size]
loss=0
for i in range(len(decoder_output_all)):
#pred[i]:[letter_len,letter_size]
#decoder_output_all[i]:[letter_len]
loss+=criterion(pred[i],decoder_output_all[i])
optimizer.zero_grad()
loss.backward()
optimizer.step()
if epoch+1==5000:
print('epoch:','%04d'%(epoch+1),'loss=','{:.6f}'.format(loss))
从下面测试的代码可以看出,在测试过程中,Decoder 的 input 是没有意义占位符,所占位置的长度即最大长度 n_step 。并且在输出中找到第一个终止符的位置,截取在此之前的所有字符
# Test
def translate(word):
enc_input, dec_input, _ = make_data([[word, '?' * n_step]])
enc_input, dec_input = enc_input.to(device), dec_input.to(device)
# make hidden shape [num_layers * num_directions, batch_size, n_hidden]
hidden = torch.zeros(1, 1, n_hidden).to(device)
output = model(enc_input, hidden, dec_input)
# output : [n_step+1, batch_size, n_class]
predict = output.data.max(2, keepdim=True)[1] # select n_class dimension
decoded = [letter[i] for i in predict]
translated = ''.join(decoded[:decoded.index('E')])
return translated.replace('?', '')
print('test')
print('man ->', translate('man'))
print('mans ->', translate('mans'))
print('king ->', translate('king'))
print('black ->', translate('black'))
print('up ->', translate('up'))

若有收获,就点个赞吧
0 人点赞
