#导入相关的包import torchimport numpy as npimport torch.nn as nnimport torch.optim as optimimport matplotlib.pyplot as pltimport torch.utils.data as Datadtype = torch.FloatTensordevice = torch.device("cuda" if torch.cuda.is_available() else "cpu")
文本预处理
sentences = ["jack like dog", "jack like cat", "jack like animal","dog cat animal", "banana apple cat dog like", "dog fish milk like","dog cat animal like", "jack like apple", "apple like", "jack like banana","apple banana jack movie book music like", "cat dog hate", "cat dog like"]word_sequence = " ".join(sentences).split() # ['jack', 'like', 'dog', 'jack', 'like', 'cat', 'animal',...]vocab = list(set(word_sequence)) # build words vocabularyword2idx = {w: i for i, w in enumerate(vocab)} # {'jack':0, 'like':1,...}
模型相关参数
# Word2Vec Parameters
batch_size = 8
embedding_size = 2 # 2 dim vector represent one word
C = 2 # window size
voc_size = len(vocab)
数据预处理
# 1.
skip_grams = []
for idx in range(C, len(word_sequence) - C):
center = word2idx[word_sequence[idx]] # center word
context_idx = list(range(idx - C, idx)) + list(range(idx + 1, idx + C + 1)) # context word idx
context = [word2idx[word_sequence[i]] for i in context_idx]
for w in context:
skip_grams.append([center, w])
# 2.
def make_data(skip_grams):
input_data = []
output_data = []
for i in range(len(skip_grams)):
input_data.append(np.eye(voc_size)[skip_grams[i][0]])
output_data.append(skip_grams[i][1])
return input_data, output_data
# 3.
input_data, output_data = make_data(skip_grams)
input_data, output_data = torch.Tensor(input_data), torch.LongTensor(output_data)
dataset = Data.TensorDataset(input_data, output_data)
loader = Data.DataLoader(dataset, batch_size, True)
假设所有文本分词,转为索引之后的 list 如下图所示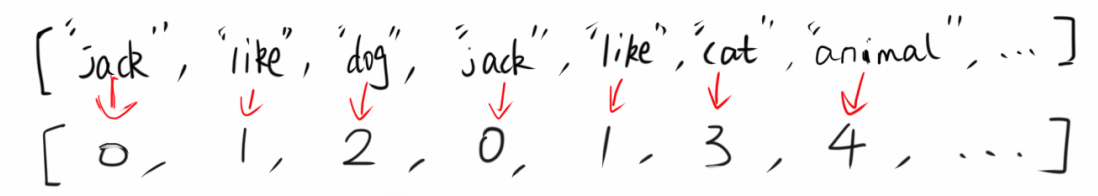
根据论文所述,我这里设定 window size=2,即每个中心词左右各取 2 个词作为背景词,那么对于上面的 list,窗口每次滑动,选定的中心词和背景词如下图所示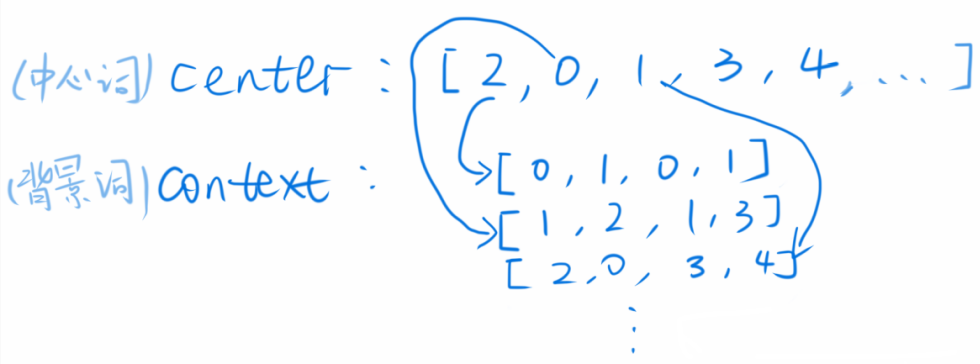
那么 skip_grams 变量里存的就是中心词和背景词一一配对后的 list,例如中心词 2,有背景词 0,1,0,1,一一配对以后就会产生 [2,0],[2,1],[2,0],[2,1]。skip_grams 如下图所示
由于 Word2Vec 的输入是 one-hot 表示,所以我们先构建一个对角全 1 的矩阵,利用np.eye(rows)方法,其中的参数 rows 表示全 1 矩阵的行数,对于这个问题来说,语料库中总共有多少个单词,就有多少行
然后根据 skip_grams 每行第一列的值,取出相应全 1 矩阵的行。将这些取出的行,append 到一个 list 中去,最终的这个 list 就是所有的样本 X。标签不需要 one-hot 表示,只需要类别值,所以只用把 skip_grams 中每行的第二列取出来存起来即可
最后第三步就是构建 dataset,然后定义 DataLoader
构建模型
# Model
class Word2Vec(nn.Module):
def __init__(self):
super(Word2Vec, self).__init__()
# W and V is not Traspose relationship
self.W = nn.Parameter(torch.randn(voc_size, embedding_size).type(dtype))
self.V = nn.Parameter(torch.randn(embedding_size, voc_size).type(dtype))
def forward(self, X):
# X : [batch_size, voc_size] one-hot
# torch.mm only for 2 dim matrix, but torch.matmul can use to any dim
hidden_layer = torch.matmul(X, self.W) # hidden_layer : [batch_size, embedding_size]
output_layer = torch.matmul(hidden_layer, self.V) # output_layer : [batch_size, voc_size]
return output_layer
model = Word2Vec().to(device)
criterion = nn.CrossEntropyLoss().to(device)
optimizer = optim.Adam(model.parameters(), lr=1e-3)
训练
# Training
for epoch in range(2000):
for i, (batch_x, batch_y) in enumerate(loader):
batch_x = batch_x.to(device)
batch_y = batch_y.to(device)
pred = model(batch_x)
loss = criterion(pred, batch_y)
if (epoch + 1) % 1000 == 0:
print(epoch + 1, i, loss.item())
optimizer.zero_grad()
loss.backward()
optimizer.step()
由于我这里每个词是用的 2 维的向量去表示,所以可以将每个词在平面直角坐标系中标记出来,看看各个词之间的距离
for i, label in enumerate(vocab):
W, WT = model.parameters()
x,y = float(W[i][0]), float(W[i][1])
plt.scatter(x, y)
plt.annotate(label, xy=(x, y), xytext=(5, 2), textcoords='offset points', ha='right', va='bottom')
plt.show()
完整代码如下:
'''
code by Tae Hwan Jung(Jeff Jung) @graykode, modify by wmathor
6/11/2020
'''
import torch
import numpy as np
import torch.nn as nn
import torch.optim as optim
import matplotlib.pyplot as plt
import torch.utils.data as Data
dtype = torch.FloatTensor
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
sentences = ["jack like dog", "jack like cat", "jack like animal",
"dog cat animal", "banana apple cat dog like", "dog fish milk like",
"dog cat animal like", "jack like apple", "apple like", "jack like banana",
"apple banana jack movie book music like", "cat dog hate", "cat dog like"]
word_sequence = " ".join(sentences).split() # ['jack', 'like', 'dog', 'jack', 'like', 'cat', 'animal',...]
vocab = list(set(word_sequence)) # build words vocabulary
word2idx = {w: i for i, w in enumerate(vocab)} # {'jack':0, 'like':1,...}
# Word2Vec Parameters
batch_size = 8
embedding_size = 2 # 2 dim vector represent one word
C = 2 # window size
voc_size = len(vocab)
skip_grams = []
for idx in range(C, len(word_sequence) - C):
center = word2idx[word_sequence[idx]] # center word
context_idx = list(range(idx - C, idx)) + list(range(idx + 1, idx + C + 1)) # context word idx
context = [word2idx[word_sequence[i]] for i in context_idx]
for w in context:
skip_grams.append([center, w])
def make_data(skip_grams):
input_data = []
output_data = []
for i in range(len(skip_grams)):
input_data.append(np.eye(voc_size)[skip_grams[i][0]])
output_data.append(skip_grams[i][1])
return input_data, output_data
input_data, output_data = make_data(skip_grams)
input_data, output_data = torch.Tensor(input_data), torch.LongTensor(output_data)
dataset = Data.TensorDataset(input_data, output_data)
loader = Data.DataLoader(dataset, batch_size, True)
# Model
class Word2Vec(nn.Module):
def __init__(self):
super(Word2Vec, self).__init__()
# W and V is not Traspose relationship
self.W = nn.Parameter(torch.randn(voc_size, embedding_size).type(dtype))
self.V = nn.Parameter(torch.randn(embedding_size, voc_size).type(dtype))
def forward(self, X):
# X : [batch_size, voc_size] one-hot
# torch.mm only for 2 dim matrix, but torch.matmul can use to any dim
hidden_layer = torch.matmul(X, self.W) # hidden_layer : [batch_size, embedding_size]
output_layer = torch.matmul(hidden_layer, self.V) # output_layer : [batch_size, voc_size]
return output_layer
model = Word2Vec().to(device)
criterion = nn.CrossEntropyLoss().to(device)
optimizer = optim.Adam(model.parameters(), lr=1e-3)
# Training
for epoch in range(2000):
for i, (batch_x, batch_y) in enumerate(loader):
batch_x = batch_x.to(device)
batch_y = batch_y.to(device)
pred = model(batch_x)
loss = criterion(pred, batch_y)
if (epoch + 1) % 1000 == 0:
print(epoch + 1, i, loss.item())
optimizer.zero_grad()
loss.backward()
optimizer.step()
for i, label in enumerate(vocab):
W, WT = model.parameters()
x,y = float(W[i][0]), float(W[i][1])
plt.scatter(x, y)
plt.annotate(label, xy=(x, y), xytext=(5, 2), textcoords='offset points', ha='right', va='bottom')
plt.show()
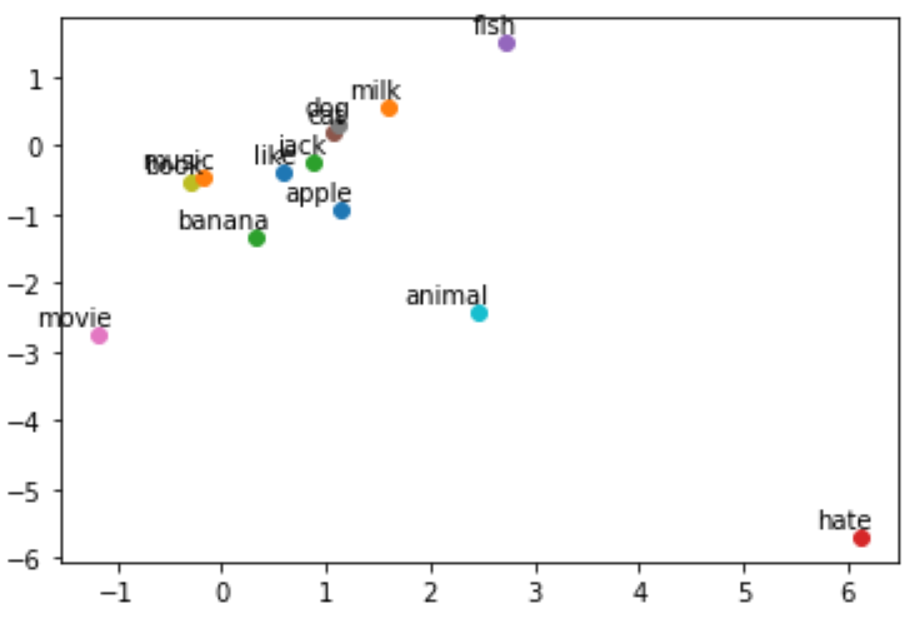

若有收获,就点个赞吧
0 人点赞
