安装
Windows平台安装MongoDB
下载地址:https://www.mongodb.com/download-center/community
安装过程中,你可以通过点击 “Custom“ 按钮来设置你的安装目录,下一步安装时 “install mongoDB compass” 不勾选,否则可能要很长时间都一直在执行安装,MongoDB Compass 是一个图形界面管理工具,我们可以在后面自己到官网下载安装。
4.x之前的版本需要自己配置data、log文件夹,手动将MongoDB添加为Windows服务,4.x之后的版本在安装完成之后会自动生成好data、log文件夹,并且将MongoDB添加到Windows服务中。
安装完成之后需配置环境变量
Path:E:\Program Files\MongoDB\Server\4.0\bin
可视化工具
Robomongo
Robomongo 是一个基于 Shell 的跨平台开源 MongoDB 可视化管理工具,支持 Windows、Linux 和 Mac,嵌入了 JavaScript 引擎和 MongoDB mongo,只要你会使用 mongo shell,你就会使用 Robomongo,它还提供了语法高亮、自动补全、差别视图等。
MongoChef
MongoChef 是另一款强大的 MongoDB 可视化管理工具,支持 Windows、Linux 和 Mac。
MongoChef 下载地址,我们选择左侧的非商业用途的免费版下载。
MongoDB基本概念
不管我们学习什么数据库都应该学习其中的基础概念,在mongodb中基本的概念是文档、集合、数据库,下面我们挨个介绍。
下表将帮助您更容易理解Mongo中的一些概念:
| SQL术语/概念 | MongoDB术语/概念 | 解释/说明 |
|---|---|---|
| database | database | 数据库 |
| table | collection | 数据库表/集合 |
| row | document | 数据记录行/文档 |
| column | field | 数据字段/域 |
| index | index | 索引 |
| table joins | 表连接,MongoDB不支持 | |
| primary key | primary key | 主键,MongoDB自动将_id字段设置为主键 |
通过下图实例,我们也可以更直观的了解Mongo中的一些概念:
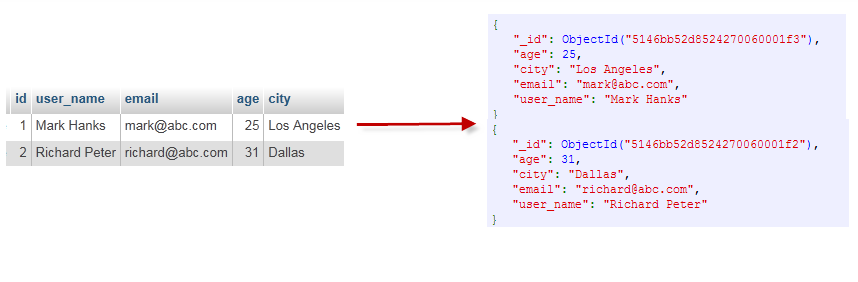
数据库(database)
MongoDB的默认数据库为”test”,该数据库存储在data目录中。
“show dbs” 命令可以显示所有数据库
> show dbslocal 0.078GBtest 0.078GB
执行 “db” 命令可以显示当前数据库对象或集合。
> dbtest
运行”use”命令,可以连接到一个指定的数据库。
> use localswitched to db local> dblocal
数据库也通过名字来标识。数据库名可以是满足以下条件的任意UTF-8字符串。
- 不能是空字符串(””)
- 不得含有’ ‘(空格)、.、$、/、\和\0 (空字符)
- 应全部小写
- 最多64字节
MongoDB默认会创建local、admin、config数据库,可以直接访问这些有特殊作用的数据库。
- admin: 从权限的角度来看,这是”root”数据库。要是将一个用户添加到这个数据库,这个用户自动继承所有数据库的权限。一些特定的服务器端命令也只能从这个数据库运行,比如列出所有的数据库或者关闭服务器。
- local: 这个数据永远不会被复制,可以用来存储限于本地单台服务器的任意集合
- config: 当Mongo用于分片设置时,config数据库在内部使用,用于保存分片的相关信息。
慎用local数据库
local数据库,从名字可以看出,它只会在本地存储数据,即local数据库里的内容不会同步到副本集里其他节点上去;目前local数据库主要存储副本集的配置信息、oplog信息,这些信息是每个Mongod进程独有的,不需要同步到副本集中其他节点。
在使用MongoDB时,重要的数据千万不要存储在local数据库中,否则当一个节点故障时,存储在local里的数据就会丢失。
另外,对于重要的数据,除了不能存储在local数据库,还要注意MongoDB默认的WriteConcern是{w: 1},即数据写到Primary上(不保证journal已经写成功)就向客户端确认,这时同样存在丢数据的风险。对于重要的数据,可以设置更高级别的如{w: "majority"}来保证数据写到大多数节点后再向客户端确认,当然这对写入的性能会造成一定的影响。
慎用admin数据库
当Mongod启用auth选项时,用户需要创建数据库帐号,访问时根据帐号信息来鉴权,而数据库帐号信息就存储在admin数据库下。
> use adminswitched to db admin> db.getCollectionNames()[ "system.users", "system.version" ]
- system.version存储authSchema的版本信息
- system.users存储了数据库帐号信息
- 如果用户创建了自定义的角色,还会有system.roles集合
用户可以在admin数据库下建立任意集合,存储任何数据,但强烈建议不要使用admin数据库存储应用业务数据,最好创建新的数据库。
admin数据库里的system.users、system.roles2个集合的数据,MongoDB会cache在内存里,这样不用每次鉴权都从磁盘加载用户角色信息。目前cache的维护代码,只有在保证system.users、system.roles的写入都串行化的情况下才能正确工作,详情参考官方issue SERVER-16092
MongoDB将将admin数据库上的意向写锁(MODE_IX)直接升级为写锁(MODE_X),也就是说admin数据库的写入操作的锁级别只能到DB级别,不支持多个collection并发写入,在写入时也不支持并发读取。如果用户在admin数据库里存储业务数据,则可能遭遇性能问题。
集合(collections)
集合就是 MongoDB 文档组,类似于 RDBMS (关系数据库管理系统:Relational Database Management System)中的表。
集合存在于数据库中,集合没有固定的结构,这意味着你在对集合可以插入不同格式和类型的数据,但通常情况下我们插入集合的数据都会有一定的关联性。
比如,我们可以将以下不同数据结构的文档插入到集合中:
{"site":"www.baidu.com"}{"site":"www.google.com","name":"Google"}{"site":"www.runoob.com","name":"菜鸟教程","num":5}
当第一个文档插入时,集合就会被创建。
合法的集合名:
- 集合名不能是空字符串””
- 集合名不能含有\0字符(空字符),这个字符表示集合名的结尾
- 集合名不能以”system.”开头,这是为系统集合保留的前缀
- 用户创建的集合名字不能含有保留字符。有些驱动程序的确支持在集合名里面包含,这是因为某些系统生成的集合中包含该字符。除非你要访问这种系统创建的集合,否则千万不要在名字里出现$。
如下实例:
db.col.findOne()
文档(document)
文档是一组键值对,MongoDB 的文档不需要设置相同的字段,并且相同的字段不需要相同的数据类型,这与关系型数据库有很大的区别,也是 MongoDB 非常突出的特点。
一个简单的文档例子如下:
{"site":"www.runoob.com", "name":"菜鸟教程"}
下表列出了 RDBMS 与 MongoDB 对应的术语:
| RDBMS | MongoDB |
|---|---|
| 数据库 | 数据库 |
| 表格 | 集合 |
| 行 | 文档 |
| 列 | 字段 |
| 表联合 | 嵌入文档 |
| 主键 | 主键 (MongoDB 提供了 key 为 _id ) |
需要注意的是:
- 文档中的键/值对是有序的
- 文档中的值不仅可以是在双引号里面的字符串,还可以是其他几种数据类型(甚至可以是整个嵌入的文档)
- MongoDB区分类型和大小写
- MongoDB的文档不能有重复的键。
- 文档的键是字符串,除了少数例外情况,键可以使用任意UTF-8字符
文档键命名规范:
- 键不能含有\0 (空字符)。这个字符用来表示键的结尾
- .和$有特别的意义,只有在特定环境下才能使用
- 以下划线”_”开头的键是保留的(不是严格要求的)
MongoDB 数据类型
MongoDB通过BSON(Binary JSON)来描述和存放数据。BSON是一种可进行二进制序列化的,类JSON格式的文档对象,下表为MongoDB中常用的几种数据类型:
| 数据类型 | 描述 |
|---|---|
| String | 字符串,在 MongoDB 中,只支持UTF-8 编码的字符串 |
| Integer | 整数值,根据你所采用的服务器,可分为 32 位或 64 位 |
| Double | 双精度浮点数,数字默认都是双精度浮点数 |
| Boolean | 布尔值 |
| Array | 数组 |
| Object | 对象 |
| Null | 表示空对象 |
| Date | 日期(UTC 时间) |
| Timestamp | 时间戳,记录文档修改或添加的具体时间 |
| ObjectId | 对象 ID,一般用于默认主键 |
| Binary Data | 二进制数据 |
| Code | 代码类型,用于在文档中存储 JavaScript 代码 |
下面说明下几种重要的数据类型。
ObjectId
ObjectId 类似唯一主键,包含 12 bytes,含义是:
- 前 4 个字节表示 Unix 时间戳 (UTC 时间,比北京时间晚了 8 个小时)
- 接下来的 3 个字节是机器标识码
- 紧接的两个字节由进程 id 组成(PID)
- 最后三个字节是随机数

MongoDB 中存储的文档必须有一个 _id 键。这个键的值可以是除数组外的任何类型,默认是个 ObjectId 对象。
由于 ObjectId 中保存了文档创建的时间戳,所以你不需要为你的文档保存时间戳字段,你可以通过 getTimestamp 函数来获取文档的创建时间:
> var newObject = ObjectId()> newObject.getTimestamp()ISODate("2017-11-25T07:21:10Z")
ObjectId 转为字符串
> newObject.str5a1919e63df83ce79df8b38f
字符串
BSON 字符串都是 UTF-8 编码。
时间戳
BSON 有一个特殊的时间戳类型用于 MongoDB 内部使用,与普通的 日期 类型不相关。 时间戳值是一个 64 位的值。其中:
- 前32位是一个 time_t 值(与Unix新纪元相差的秒数)
- 后32位是在某秒中操作的一个递增的
序数
在单个 mongod 实例中,时间戳值通常是唯一的。
在复制集中, oplog 有一个 ts 字段。这个字段中的值使用BSON时间戳表示了操作时间。
BSON 时间戳类型主要用于 MongoDB 内部使用。在大多数情况下的应用开发中,你可以使用 BSON 日期类型。
日期
表示当前距离 Unix新纪元(1970年1月1日)的毫秒数。日期类型是有符号的, 负数表示 1970 年之前的日期。
> var mydate1 = new Date() //格林尼治时间> mydate1ISODate("2018-03-04T14:58:51.233Z")> typeof mydate1object> var mydate2 = ISODate() //格林尼治时间> mydate2ISODate("2018-03-04T15:00:45.479Z")> typeof mydate2object
这样创建的时间是日期类型,可以使用 JS 中的 Date 类型的方法。
返回一个时间类型的字符串:
> var mydate1str = mydate1.toString()> mydate1strSun Mar 04 2018 14:58:51 GMT+0000 (UTC)> typeof mydate1strstring
或者
> Date()Sun Mar 04 2018 15:02:59 GMT+0000 (UTC)
MongoDB基本操作(数据库、集合)
创建数据库
语法
use DATABASE_NAME
如果数据库不存在,则创建数据库,否则切换到指定数据库。
实例
以下实例我们创建了数据库 runoob:
> use runoobswitched to db runoob> dbrunoob>
如果你想查看所有数据库,可以使用 show dbs 命令:
> show dbsadmin 0.000GBlocal 0.000GB>
可以看到,我们刚创建的数据库 runoob 并不在数据库的列表中, 要显示它,我们需要向 runoob 数据库插入一些数据。
> db.runoob.insert({"name":"菜鸟教程"})WriteResult({ "nInserted" : 1 })> show dbslocal 0.078GBrunoob 0.078GBtest 0.078GB>
MongoDB 中默认的数据库为 test,如果你没有创建新的数据库,集合将存放在 test 数据库中。
删除数据库
语法
db.dropDatabase()
删除当前数据库,默认为 test,你可以使用 db 命令查看当前数据库名。
实例
以下实例我们删除了数据库 runoob。
首先,查看所有数据库:
> show dbslocal 0.078GBrunoob 0.078GBtest 0.078GB
接下来我们切换到数据库 runoob:
> use runoobswitched to db runoob>
执行删除命令:
> db.dropDatabase(){ "dropped" : "runoob", "ok" : 1 }
最后,我们再通过 show dbs 命令数据库是否删除成功:
> show dbslocal 0.078GBtest 0.078GB>
创建集合
语法
db.createCollection(name, options)
参数说明:
- name: 要创建的集合名称
- options: 可选参数, 指定有关内存大小及索引的选项
options 可以是如下参数:
| 字段 | 类型 | 描述 |
|---|---|---|
| capped | 布尔 | (可选)如果为 true,则创建固定集合。固定集合是指有着固定大小的集合,当达到最大值时,它会自动覆盖最早的文档。 当该值为 true 时,必须指定 size 参数。 |
| autoIndexId | 布尔 | (可选)如为 true,自动以 _id 字段创建索引。默认为 false。 |
| size | 数值 | (可选)为固定集合指定一个最大值(以字节计)。 如果 capped 为 true,也需要指定该字段。 |
| max | 数值 | (可选)指定固定集合中包含文档的最大数量。 |
在插入文档时,MongoDB 首先检查固定集合的 size 字段,然后检查 max 字段。
实例
在 test 数据库中创建 runoob 集合:
> use testswitched to db test> db.createCollection("runoob"){ "ok" : 1 }>
如果要查看已有集合,可以使用 show collections 命令:
> show collectionsrunoobsystem.indexes
下面是带有几个关键参数的 createCollection() 的用法:
创建固定集合 mycol,整个集合空间大小 6142800 KB, 文档最大个数为 10000 个。
> db.createCollection("mycol", { capped : true, autoIndexId : true, size :6142800, max : 10000 } ){ "ok" : 1 }>
在 MongoDB 中,可以不需要显式创建集合。当你插入一些文档时,MongoDB 会自动创建集合。
> db.col.insert({"name" : "菜鸟教程"})> show collectionscol...
删除集合
语法
db.collection.drop()
参数说明:
- 无
返回值
如果成功删除选定集合,则 drop() 方法返回 true,否则返回 false。
实例
在数据库 mydb 中,我们可以先通过 show collections 命令查看已存在的集合:
>use mydbswitched to db mydb>show collectionsmycolmycol2system.indexesrunoob>
接着删除集合 mycol2 :
>db.mycol2.drop()true>
通过 show collections 再次查看数据库 mydb 中的集合:
>show collectionsmycolsystem.indexesrunoob>
从结果中可以看出 mycol2 集合已被删除。
MongoDB基本操作之CRUD
插入文档
MongoDB 中文档的数据结构和 JSON 基本一样,所有存储在集合中的数据都是BSON格式,BSON 是一种类似 JSON 的二进制形式的存储格式,是 Binary JSON 的简称。
语法
db.collection.insert(document or array of documents)
实例
以下文档可以存储在 MongoDB 的 test 数据库 的 col 集合中:
db.col.insert({title: 'MongoDB 教程',description: 'MongoDB 是一个 Nosql 数据库',by: '菜鸟教程',url: 'http://www.runoob.com',tags: ['mongodb', 'database', 'NoSQL'],likes: 100})
以上实例中 col 是我们的集合名,如果该集合不在该数据库中, MongoDB 会自动创建该集合并插入文档。
查看已插入文档:
> db.col.find(){"_id": ObjectId("56064886ade2f21f36b03134"),"title": "MongoDB 教程","description": "MongoDB 是一个 Nosql 数据库","by": "菜鸟教程","url": "http://www.runoob.com","tags": ["mongodb", "database", "NoSQL"],"likes": 100}
我们也可以将数据定义为一个变量,如下所示:
> document=({title: 'MongoDB 教程',description: 'MongoDB 是一个 Nosql 数据库',by: '菜鸟教程',url: 'http://www.runoob.com',tags: ['mongodb', 'database', 'NoSQL'],likes: 100});
执行后显示结果如下:
{"title": "MongoDB 教程","description": "MongoDB 是一个 Nosql 数据库","by": "菜鸟教程","url": "http://www.runoob.com","tags": ["mongodb", "database", "NoSQL"],"likes": 100}
执行插入操作:
> db.col.insert(document)WriteResult({ "nInserted" : 1 })
一次插入多条数据
1、先创建数组
2、将数据放在数组中
3、一次 insert 到集合中
var arr = [];for(var i = 1; i<=20000; i++){ arr.push({num: i}); }db.numbers.insert(arr);
其他语法
3.2 版本后还有以下几种语法可用于插入文档:
- db.collection.insertOne():向指定集合中插入一条文档数据
- db.collection.insertMany():向指定集合中插入多条文档数据
// 插入单条数据> var document = db.collection.insertOne({"a": 3})> document{"acknowledged": true,"insertedId": ObjectId("571a218011a82a1d94c02333")}// 插入多条数据> var res = db.collection.insertMany([{"b": 3}, {'c': 4}])> res{"acknowledged": true,"insertedIds": [ObjectId("571a22a911a82a1d94c02337"),ObjectId("571a22a911a82a1d94c02338")]}
插入文档你也可以使用 db.col.save(document) 命令。如果不指定 _id 字段 save() 命令将会调用insert() 命令,创建新文档。
db.col.save({"title": "MongoDB 新教程","description": "MongoDB 是一个 Nosql 数据库","by": "菜鸟教程","url": "http: //www.runoob.com","tags": ["mongodb", "database", "NoSQL"],"likes": 1000})
查询文档
语法
MongoDB 查询数据的语法格式如下:
db.collection.find(query, projection)
- query :可选,使用查询操作符指定查询条件的文档
- projection :可选,使用投影操作符指定返回的键值。查询时返回文档中所有键值, 只需省略该参数即可(默认省略)。
如果你需要以易读的方式来读取数据,可以使用 pretty() 方法,语法格式如下:
>db.col.find().pretty()
pretty() 方法以格式化的方式来显示所有文档。
实例
以下实例我们查询了集合 col 中的数据:
> db.col.find().pretty(){"_id": ObjectId("56063f17ade2f21f36b03133"),"title": "MongoDB 教程","description": "MongoDB 是一个 Nosql 数据库","by": "菜鸟教程","url": "http://www.runoob.com","tags": ["mongodb", "database", "NoSQL"],"likes": 100}
除了 find() 方法之外,还有一个 findOne() 方法,它只返回一个文档。
// 匹配查询db.col.find({title: 'MongoDB 教程'})// 模糊匹配查询// 查询 title 包含"MongoDB"字的文档:db.col.find({title:/MongoDB/})// 查询 title 字段以"MongoDB"字开头的文档:db.col.find({title:/^MongoDB/})// 查询 titl e字段以"教程"字结尾的文档:db.col.find({title:/教程$/})
文档投影
db.collection.find(query, projection)
若不指定 projection,则默认返回所有键,指定 projection 格式如下,有两种模式
db.collection.find(query, {title: 1, by: 1}) // inclusion模式 指定返回的键,不返回其他键db.collection.find(query, {title: 0, by: 0}) // exclusion模式 指定不返回的键,返回其他键
_id 键默认返回,需要主动指定 _id: 0 才会隐藏
两种模式不可混用(因为这样的话无法推断其他键是否应返回)
db.collection.find(query, {title: 1, by: 0}) // 错误
只能全1或全0,除了在inclusion模式时可以指定_id为0
db.collection.find(query, {_id:0, title: 1, by: 1}) // 正确
若不想指定查询条件参数 query 可以 用 {} 代替,但是需要指定 projection 参数:
querydb.collection.find({}, {title: 1})
$slice操作符可以返回数组字段中的部分元素
db.col.find({title:/^MongoDB/}, {_id:0, title: 1, tags: {$slice: 1}})
查询操作符
比较操作符
语法:
{ field: {$<opetator>: value} }
$eq:匹配字段值相等的文档
$ne:匹配字段不等的文档($ne也会筛选出不包含查询字段的文档,如复合主键)
$gt:匹配字段值大于查询值的文档
$gte:匹配字段值大于或等于查询值的文档
$lt:匹配字段值小于查询值的文档
$lte:匹配字段值小于或等于查询值的文档
$in:匹配字段值与任一查询值相等的文档
$nin:匹配字段值与任何查询值都不等的文档(nin也会筛选出不包含查询字段的文档,如复合主键)
// 比较运算符db.col.find({title: {$eq: 'MongoDB 教程'}})db.col.find({title: 'MongoDB 教程'})db.col.find({title: {$ne: 'MongoDB 教程'}})db.col.find({likes: {$gt: 80}})db.col.find({likes: {$gte: 70}})db.col.find({likes: {$lt: 70}})db.col.find({likes: {$lte: 10}})db.col.find({likes: {$lte: 10}})db.col.find({likes: {$in: [10, 100]}})db.col.find({likes: {$nin: [10, 100]}})
逻辑操作符
逻辑操作符都是元操作符,意味着他们可以放在其他任何操作符之上
$not
语法:
{ field: { $not: { <operator-expression> } } }
$not 会筛选出不包含查询字段的文档,如复合主键
$and
语法:
{ $and: [ { <expression1> }, { <expression2> } , ... , { <expressionN> } ] }
简写:
{ <expression1> }, { <expression2> } , ... , { <expressionN> }
$or
语法:
{ $or: [ { <expression1> }, { <expression2> }, ... , { <expressionN> } ] }
- 第一个expression1应匹配尽量多的结果
- 使用$or查询,每个expression可以优先选用其自己的索引(而非符合索引)
- 除非所有的expression都对应相应的索引,不然$or没有办法使用索引
- 因为text查询必须使用索引,所以当同时使用or和$text的时候,必须所有的expression都有索引,不然会抛出错误
- 如果有可能,尽量用in代替or
$nor
语法:
{ $nor: [ { <expression1> }, { <expression2> }, ... { <expressionN> } ] }
- 当使用$nor去查询时,不仅包括不符合这个表达式的,还包括不存在于这个表达式中的field字段
- 可以和$exists配合使用,例如:
db.inventory.find( { $nor: [{ price: 1.99 }, { price: { $exists: false } },{ sale: true }, { sale: { $exists: false } }] } )
// 逻辑操作符db.col.find({'likes': {$not: {$lte: 70}}})db.col.find({$and:[{'likes': {$lte: 70}}, {'title': 'MongoDB 教程'}]})db.col.find({'title': 'MongoDB 教程', 'likes': {$lte: 70})db.col.find({'likes': {$lte: 70}, 'title': 'MongoDB 教程'}) // 简写db.col.find( { 'likes': { $lt: 70 , $gt: 10}} ) // 简写db.col.find({$or:[{'likes': {$lte: 70}}, {'title': 'MongoDB 教程'}]})db.col.find({$nor:[{'likes': {$gt: 70}}, {'title': 'MongoDB进阶'}]})
字段操作符
$exists
语法: { field: { $exists: <boolean> } }
匹配包含该字段的文档,即使该字段的值为null
$type
语法:
{ field: { $type: <BSON type> } },
{ field: { $type: [ <BSON type1> , <BSON type2>, ... ] } }
匹配字段类型符合查询值的文档
// 字段操作符db.col.find({'_id.type': {$exists: true}})db.col.find({"title" : {$type : 'string'}})
数组操作符
$all
语法: { <field>: { $all: [ <value1> , <value2> ... ] } }
匹配数组字段中包含所有查询值的文档
$elemMatc
语法: { <field>: { $elemMatch: { <query1>, <query2>, ... } } }
匹配数组字段中至少存在一个值满足筛选条件的文档
$size
语法: { <field>: { $size: length} }
匹配满足指定数组的长度的文档,只能是固定值,不能是范围
运算操作符
$regex
{ : { $regex: /pattern/, $options: ‘’ } }
{ : { $regex: /pattern/ } }
兼容PCRE v8.41正则表达库,在和$in操作符一起使用时,只能使用 /pattern/,不能使用 $regex 运算符表达式。
在设置索弓的字段上进行正则匹配可以提高查询速度,而且当正则表达式使用的是前缀表达式时,查询速度会进一步提高,例如:{ name: { $regex: /^a/ }。
option参数的含义:
| 选项 | 含义 | 使用要求 |
|---|---|---|
| i | 大小写不敏感 | |
| m | 多行匹配模式 | |
| x | 忽视所有空白字符 | 要求 |
| s | 单行匹配模式 | 要求 |
// 运算操作符db.col.find({title: { $in: [/^M/i, /阶$/]}})db.col.find({title: { $regex: /^m/, $options: 'i'}})
文档游标
基本概念
db.collection.find()返回一个文档集合的游标
在不遍历游标的情况下,只列出20个文档,我们可以使用游标下标直接访问文档集合中的某个文档
游标的销毁
- 客户端发来信息让其销毁
- 游标迭代完毕
- 默认游标超过10分钟自动清除
可以使用noCursorTimeout()函数来保持游标一直有效,在不遍历游标的情况下,你需要主动关闭游标,否则会一直在数据库中消耗服务器资源
// 文档游标var myCursor = db.col.find()var myCursor = db.col.find().noCursorTimeout()myCursor // 前 20 条文档myCursor.close()
游标函数
cursor.hasNext() 判断游标是否取到尽头
cursor.next() 获取游标的下一个单元
// 游标遍历while(myCursor.hasNext()){printjson(myCursor.next())}myCursor.forEach(function(item){printjson(item)})
cursor.limit() 读取指定数量的数据记录,参数为 0 相当于不使用limit
cursor.skip() 跳过指定数量的数据
db.col.find().limit(1)db.col.find().limit(0) // 参数为 0 相当于不使用limitdb.col.find().limit(1).skip(1)
cursor.count() 获取游标中总的文档数量
默认情况下,为false,即cursor.count()不会考虑limit()、skip()的效果,在不提供筛选条件时,cursor.count(会从)集合的元数据Metadata中取得结果。当数据库分布式结构较为复杂时,元数据中的文档数量可能不准确,所有我们应该避免使用不提供筛选条件的cursor.count()函数,而使用聚合管道来计算文档数量。
cursor.sort() 对游标中的文档进行排序,定义了排序要求 { field: ordering}
1表示从小到大正向排序,-1表示从大到小逆向排序
组合使用时注意:
- cursor.skip()在cursor.limit()之前执行
- cursor.sort()在cursor.skip()和cursor.limit()之前执行
- 当结合在一起使用时,游标函数的应用顺序是sort()、skip()、limit()
db.col.find().limit(1).skip(1).count()db.col.find().limit(1).skip(1).count(true)db.col.find().sort({likes: 1})db.col.find().sort({likes: 1}).limit(4).skip(1)
更新文档
MongoDB 使用 update() 和 save() 方法来更新集合中的文档。更新一个文档有两种方式,一种是替换现有的文档内容,另外一种是利用更新操作符对部分字段进行修改。
update() 方法
update() 方法用于更新已存在的文档。语法格式如下:
db.collection.update(<query>,<update>,<upsert>,<multi>,<writeConcern>)
参数说明:
- query : update的查询条件,类似sql update查询内where后面的。
- update : 新的文档或者是使用更新操作符对某一个文档进行修改(如
inc…)。
- upsert : 可选,默认情况下,如果update命令的筛选条件没有匹配任何文档,则不会进行任何操作,将upsert设置为true,如果update命令的筛选条件没有匹配任何文档,则会创建新文档。
- multi : 可选,mongodb 默认是false,只更新找到的第一条文档,如果这个参数为true,就把按条件查出来多条文档全部更新。
- writeConcern : 可选,安全写级别,等级越高,其数据的安全性就越高。
注意:MongoDB只能保证单个文档操作的原子性,不能保证多个文档操作的原子性,更新多个文档虽然在单一线程中执行,但是线程在执行过程中可能被挂起,以便其他线程也有机会对数据进行操作,如果需要保证多个文档操作的原子性,需要使用MongoDB 4.0版本引入的事务功能进行操作。有关事务功能的讲解,可以参考MongoDB 4.0新特性课程。
实例
我们在集合 col 中插入如下数据:
>db.col.insert({title: 'MongoDB 教程',description: 'MongoDB 是一个 Nosql 数据库',by: '菜鸟教程',url: 'http://www.runoob.com',tags: ['mongodb', 'database', 'NoSQL'],likes: 100})
接着我们通过 update() 方法来更新标题(title):
更新整个文档
db.col.update({'title':'MongoDB 教程'},{{'title':'MongoDB'}})WriteResult({ "nMatched" : 1, "nUpserted" : 0, "nModified" : 1 }) # 输出信息db.col.find().pretty(){"title" : "MongoDB",}
通过字段更新操作符更新title字段
>db.col.update({'title':'MongoDB 教程'},{$set:{'title':'MongoDB'}})WriteResult({ "nMatched" : 1, "nUpserted" : 0, "nModified" : 1 }) # 输出信息> db.col.find().pretty(){"_id" : ObjectId("56064f89ade2f21f36b03136"),"title" : "MongoDB","description" : "MongoDB 是一个 Nosql 数据库","by" : "菜鸟教程","url" : "http://www.runoob.com","tags" : ["mongodb","database","NoSQL"],"likes" : 100}
可以看到标题(title)由原来的 “MongoDB 教程” 更新为了 “MongoDB”。
以上语句只会修改第一条发现的文档,如果你要修改多条相同的文档,则需要设置 multi 参数为 true。
>db.col.update({'title':'MongoDB 教程'},{$set:{'title':'MongoDB'}},{multi:true})
save() 方法
save() 方法通过传入的文档来替换已有文档。语法格式如下:
db.collection.save(<document>,<writeConcern>)
参数说明:
- document : 文档数据,如果document中包含了_id字段,save()命令将会调用update()命令,且upsert选项为true,如果文档中的_id字段没有匹配到任何文档,则会创建新文档。
- writeConcern:可选,安全写级别,等级越高,其数据的安全性就越高。
实例
以下实例中我们替换了 _id 为 56064f89ade2f21f36b03136 的文档数据:
>db.col.save({"_id" : ObjectId("56064f89ade2f21f36b03136"),"title" : "MongoDB","description" : "MongoDB 是一个 Nosql 数据库","by" : "Runoob","url" : "http://www.runoob.com","tags" : ["mongodb","NoSQL"],"likes" : 110})
替换成功后,我们可以通过 find() 命令来查看替换后的数据
>db.col.find().pretty(){"_id": ObjectId("56064f89ade2f21f36b03136"),"title": "MongoDB","description": "MongoDB 是一个 Nosql 数据库","by": "Runoob","url": "http://www.runoob.com","tags": ["mongodb", "NoSQL"],"likes": 110}
更新操作符
字段更新操作符
| 操作符 | 功能 |
|---|---|
| $set | 更新、新增字段(字段不存在时) |
| $unset | 删除字段 |
| $rename | 重命名字段(可用于更改字段位置,不能操作为数组元素的字段) |
| $inc | 加、减字段值,取决于更新值得正负 |
| $mul | 相乘字段值 |
| $min | 比较字段值和更新值取最小值 |
| $max | 比较字段值和更新值取最大值 |
注意事项:
- inc和mul操作符只能应用于数值字段上,用在非数值字段上会报错,如果被更新的字段不存在,inc操作会把更新的字段添加进文档中,并且字段值取0然后加上更新值。对于mul字段值取0会乘上更新值,所以得到的字段值将会是0。
- min和max操作符不局限于数值字段,如果被更新的字段和更新值类型不一致,min和max会按照BSON数据类型的排序规则进行比较,同样的,当被更新字段不存在时,min和max会创建字段,并且将字段值设为更新值。
- BSON排序规则 | 最小 | Null | | —- | —- | | | Number(ints, longs, doubles, decimals) | | | Symbol, String | | | Object | | | Array | | | BinData | | | ObjectId | | | Boolean | | | Date | | | Timestamp | | 最大 | Regular Expression |
// 字段更新操作符db.col.update({title: 'MongoDB 教程'},{$set: {likes: 300}})db.col.update({'title':'MongoDB 教程'},{$set:{'title':'MongoDB'}}, false, true)db.col.updateMany({'title':'MongoDB'},{$set:{'title':'MongoDB 教程'}})db.col.updateMany({'title':'MongoDB 教程'},{$set:{'info': {date: Date(), adress: 'ZH'}}})db.col.updateMany({'title':'MongoDB 教程'},{$set:{'tags.0': 'mongo'}})db.col.updateMany({'title':'MongoDB 教程'},{$set:{'info.adress': 'AS'}})db.col.updateMany({'title':'MongoDB 教程'},{$unset:{'arr': ''}})db.col.updateMany({'title':'MongoDB 教程'},{$rename:{'title':'article'}})db.col.updateMany({'article':'MongoDB 教程'},{$rename:{'info.adress': 'adress', 'article': 'info.article'}})
数组更新操作符
| 操作符 | 功能 |
|---|---|
| $ | 占位符 |
| $push | 添加元素到数组 |
| $addToSet | 添加元素到数组 |
| $pop | 删除数组第一个或最后一个元素 |
| $pull | 删除数组中匹配的元素 |
| $pullAll | 删除数组中匹配的多个元素 |
| $each | 结合 $push 和 $addToSet 操作多个值 |
| $position | 结合 $push 将元素插入数组中指定的位置 |
| $sort | 结合 push、each 对数组进行排序 |
| $slice | 结合push、each 截取部分数组 |
position、sort、$slice可以一起使用:
这三个操作符的执行顺序是:position、sort、$slice,写在命令中的操作符顺序并不重要,并不会影响命令的执行顺序
// 更新文档// 匹配更新db.col.update({title: 'MongoDB 进阶'},{name: 'gongyz'})db.col.update({name:'gongyz'},{adress: '江西'}, {upsert: true})// 如果从筛选条件中可以确定字段值,那么新创建的文档将包含筛选条件涉及的字段db.col.update({name:'gongyz'},{$set: {adress: '江西'}}, {upsert: true})// 不过,如果无法从筛选条件中推断出确定的字段值,那么新创建的文档就不会包含筛选条件涉及的字段db.col.update({num: {$gt: 20000}},{$set: {name: 'nick'}}, {upsert: true})// 字段更新操作符db.col.update({title: 'MongoDB 教程'},{$set: {likes: 300}})db.col.update({'title':'MongoDB 教程'},{$set:{'title':'MongoDB'}}, false, true)db.col.updateMany({'title':'MongoDB'},{$set:{'title':'MongoDB 教程'}})db.col.updateMany({'title':'MongoDB 教程'},{$set:{'info': {date: Date(), adress: 'ZH'}}})db.col.updateMany({'title':'MongoDB 教程'},{$set:{'tags.0': 'mongo'}})db.col.updateMany({'title':'MongoDB 教程'},{$set:{'info.adress': 'AS'}})db.col.updateMany({'title':'MongoDB 教程'},{$unset:{'arr': ''}})db.col.updateMany({'title':'MongoDB 教程'},{$rename:{'title':'article'}})db.col.updateMany({'article':'MongoDB 教程'},{$rename:{'info.adress': 'adress', 'article': 'info.article'}})// 数组更新操作符// $addToSet会将数组插入被更新的数组字段中,成为内嵌数组,如果想将多个元素直接添加到数组字段中,则需要使用$each操作符db.col.updateMany({'title':'MongoDB 教程'},{$addToSet: {'arr': [3, 4]}})db.col.updateMany({'title':'MongoDB 教程'},{$addToSet: {'arr': {'name': 'gongyz', age: 23}}})db.col.updateMany({'title':'MongoDB 教程'}, {$addToSet: {arr: {$each: [1, 2]}}})db.col.updateMany({'title':'MongoDB 教程'}, {$pop: {arr: 1}}) // 删除最后一个元素db.col.updateMany({'title':'MongoDB 教程'}, {$pop: {arr: -1}}) // 删除第一个元素db.col.updateMany( {'title':'MongoDB 教程'}, { $pull: { tags: {$regex: /mo/} } } )db.col.updateMany( {'title':'MongoDB 教程'}, { $pull: { tags: {$regex: /mo/} } } )// 如果要删除的元素是一个数组,数组元素的值和排列顺序都必须和被删除的元素完全一致db.col.updateMany( {'title':'MongoDB 教程'}, { $pullAll: { arr: [[3, 4]] } } )// 如果要删除的元素是一个文档,$pullAll要求文档的值和排列顺序都必须和被删除的元素完全一致,$pull不需要完全一致db.col.updateMany( {'title':'MongoDB 教程'}, { $pullAll: { arr: [{'name': 'gongyz', 'age': 23}] } } )db.col.updateMany( {'title':'MongoDB 教程'}, { $pull: { arr: {'name': 'gongyz'} } } )// $push和$addToSet命令相似,但是$push命令的功能更加强大,$push和$addToSet一样,如果$push命令中指定的字段不存在,这个字段会被添加到集合中db.col.updateMany({'title':'MongoDB 教程'},{$push: {'arr': [5, 6]}})db.col.updateMany({'title':'MongoDB 教程'}, {$push: {arr: {$each: [7, 8]}}})// 使用$position将元素插入数组中指定的位置db.col.updateMany({'title':'MongoDB 教程'}, {$push: {arr: {$each: [0], $position: 0}}})// 位置倒过来计算,插入到最后一个元素前面db.col.updateMany({'title':'MongoDB 教程'}, {$push: {arr: {$each: [9], $position: -1}}})// 使用$sort对数组进行排序 1(从小到大) -1(从大到小),使用$sort时必须要使用$push和$eachdb.col.updateMany({'title':'MongoDB 教程'}, {$push: {arr: {$each: [10], $sort: -1}}})// 如果插入的是内嵌文档,可以根据内嵌文档的字段排序db.col.updateMany({'title':'MongoDB 教程'}, {$push: {arr: {$each: [{value: 100}, {value: 200}], $sort: {value: -1}}}})// 如果不想插入元素,只想对文档中的数组字段进行排序db.col.updateMany({'title':'MongoDB 教程'}, {$push: {arr: {$each: [], $sort: -1}}})// 使用$slice截取部分数组db.col.updateMany({'title':'MongoDB 教程'}, {$push: {arr: {$each: [1], $slice: -2}}})// 如果不想插入元素,只想截取部分数组db.col.updateMany({'title':'MongoDB 教程'}, {$push: {arr: {$each: [], $slice: 2}}})// $position、$sort、$slice可以一起使用,但这三个操作符的执行顺序是:$position、$sort、$slice,写在命令中操作符的顺序并不重要,并不会影响命令的执行顺序db.col.updateMany({'title':'MongoDB 教程'}, {$push: {arr: {$each: [6, 8], $position: 0, $sort: -1, $slice: 2}}})// 更新数组中所有元素db.col.updateMany({'title':'MongoDB 教程'}, {$set: {'arr.$[]': 'updated'}})// $ 是数组中第一个符合筛选条件的数组元素的占位符(query中需要指明要更新的数组元素)db.col.updateMany({'title':'MongoDB 教程','arr': 'updated'}, {$set: {'arr.$': 1}})// save()命令更新文档db.col.save({_id: ObjectId("5ce5ef8caa5dacd1c36450e1"),title: 'MongoDB 新教程',description: 'MongoDB 是一个 Nosql 数据库',by: '菜鸟教程',url: 'http://www.runoob.com',tags: ['mongodb', 'database', 'NoSQL'],likes: 1000})
删除文档
语法
remove() 方法的基本语法格式如下所示:
db.collection.remove(<query>,<justOne>)
如果你的 MongoDB 是 2.6 版本以后的,语法格式如下:
db.collection.remove(<query>,{justOne: <boolean>,writeConcern: <document>})
参数说明:
- query :(可选)删除的文档的条件。
- justOne : (可选)如果设为 true 或 1,则只删除一个文档,如果不设置该参数,或使用默认值 false,则删除所有匹配条件的文档。
- writeConcern : (可选),安全写级别,等级越高,其数据的安全性就越高。
// 删除文档// 默认情况下,remove命令会删除所有符合筛选条件的文档db.col.remove({'title':'MongoDB 教程'})// 删除符合筛选条件的第一篇文档db.col.remove({'title':'MongoDB 教程'}, 1)db.col.remove({'title':'MongoDB 教程'}, {justOne: true})db.col.remove({'title':'MongoDB 教程'}, true)// 删除所有文档(不会删除集合)db.col.remove({})// 如果集合中文档的数量很多,使用remove命令删除所有文档的效率不高,在这种情况下,更加有效率的方法,// 是使用drop命令删除集合,然后再创建空集合并创建索引
MongoDB基本操作进阶之聚合
MongoDB中聚合(aggregate)主要用于处理数据(诸如统计平均值,求和等),并返回计算后的数据结果,MongoDB中聚合的方法使用aggregate(),该方法返回的是文档游标
aggregate() 方法
语法
db.<collection>.aggregate(<pipeline>, <options>)
定义了操作中使用的聚合表达式和管道操作符
声明了一些聚合操作的参数
聚合表达式
字段路径表达式
$<filed> 使用$来指示文档字段
$<filed>.<sub-filed> 使用$和.来指示内嵌文档字段
系统变量表达式
<variable> 使用来指示系统变量
$$CURRENT 指示管道中当前操作的文档
$$CURRENT.<filed> 和 $<filed>是等效的
常量表达式
$literal: <value> 指示常量字
$literal: '$name' 指示常量字符串’name’,这里被当作常量处理,而不是字段路径表达式
聚合管道操作符
- $project:对输入文档进行再次投影
- $match:对输入文档进行筛选
- $limit:筛选出管道内前N篇文档
- $skip:跳过管道内前N篇文档
- $unwind:展开输入文档中的数组字段
- $sort:对输入文档进行排序
- $lookup:对输入文档进行查询操作
- $group:对输入文档进行分组
- $out:将管道中的文档输出
// 聚合操作db.user.insertMany([{name: { firstName: 'alice', lastName: 'wong' },balance: 50},{name: { firstName: 'bob', lastName: 'yang' },balance: 50}])db.user.update({'name.firstName': 'alice'},{$set: { currency: ['CNY', 'USD'] }})db.user.update({'name.firstName': 'bob'},{$set: { currency: 'GBP' }})db.user.insertMany([{name: { firstName: 'charlie', lastName: 'gordon' },balance: 100},{name: { firstName: 'david', lastName: 'wu' },balance: 200,currency: []},{name: { firstName: 'eddie', lastName: 'kim' },balance: 20,currency: null}])db.forex.insertMany([{ccy: 'USD',rate: 6.91,date: new Date('2018-12-21')},{ccy: 'GBP',rate: 68.72,date: new Date('2018-8-21')},{ccy: 'CNY',rate: 1.0,date: new Date('2018-12-21')}])db.transactions.insertMany([{symbol: '600519',qty: 100,price: 567.4,currency: 'CNY'},{symbol: '600518',qty: 2,price: 5677.4,currency: 'USD'},{symbol: '31312',qty: 1010,price: 5167.4,currency: 'USD'}])db.user.remove({})// $project 对输入文档进行再次投影db.user.aggregate([{$project: {_id: 0,balance: 1,clientName: '$name.firstName'}}])// 字段路径表达式指向的是原文档中不存在的字段db.user.aggregate([{$project: {_id: 0,balance: 1,newArr: ['$name.firstName', '$name.middleName', '$name.lastName']}}])// $project是一个很常用的聚合操作符,可以用来灵活控制输出文档的格式,也可以用来剔除不相关的字段,以优化聚合管道操作的性能// $match 对输入文档进行筛选db.user.aggregate([{$match: {'name.firstName': 'alice'}}])db.user.aggregate([{$match: {$or: [{ balance: { $gt: 40, $lt: 80 } }, { 'name.firstName': 'yang' }]}}])// 将筛选和投影操作符结合在一起db.user.aggregate([{$match: {$or: [{ balance: { $gt: 40, $lt: 80 } }, { 'name.firstName': 'yang' }]}},{$project: {_id: 0}}])// $match也是一个很常用的聚合操作符,应该尽量在聚合管道的开始阶段应用$match,这样可以减少后续阶段中需要处理的文档数量,优化聚合操作的性能// $limit $skipdb.user.aggregate([{$limit: 1}])db.user.aggregate([{$skip: 1}])// $unwind 展开输入文档中的数组字段,会将指定字段数组元素拿出来创建新文档,新文档的主键_id都相同db.user.aggregate([{$unwind: {path: '$currency'}}])// 展开时将数组元素在原数组中的下标位置写入一个指定的字段中db.user.aggregate([{$unwind: {path: '$currency',includeArrayIndex: 'ccyIndex'}}])// 展开数组时保留空数组或不存在数组的文档db.user.aggregate([{$unwind: {path: '$currency',preserveNullAndEmptyArrays: true}}])// sort 对输入文档进行排序db.user.aggregate([{$sort: { balance: 1, 'name.lastName': -1 }}])// $lookup:对输入文档进行查询操作,需要另一个查询集合参与,查询结果会多出一个新字段// $lookup: {// from: <collection to join>,// localField: <field from the input document>,// foreignField: <field from the documents of the 'from' collection>,// as: <output array field>// }// from: 同一数据库中的另一个查询集合// localFiled: 输入文档的字段// foreignFiled:查询集合中字段// as:给新插入的字段取一个名字// 单一字段查询db.user.aggregate([{$lookup: {from: 'forex',localField: 'currency',foreignField: 'ccy',as: 'forexData'}}])// 如果localField是一个数组字段,可以先对数组字段进行展开db.user.aggregate([{$unwind: {path: '$currency',preserveNullAndEmptyArrays: true}},{$lookup: {from: 'forex',localField: 'currency',foreignField: 'ccy',as: 'forexData'}}])// 使用复杂条件进行查询// 对查询集合中的文档使用管道操作符处理时,如果需要参考输入文档中的字段,则必须使用let参数对字段进行声明// $lookup: {// from: <collection to join>,// let: {<var_1>: <expression>, ..., <var_n>: <expression>},// pipeline: [<pipeline to execute on the collection to join>],// as: <output array field>// }// 不相关查询,查询条件和输入文档直接没有直接的联系,$lookup从3.6版本开始支持不相关查询db.user.aggregate([{$lookup: {from: 'forex',pipeline: [{$match: {date: new Date('2018-12-21')}}],as: 'forexData'}}])// 相关查询(使用let声明定义了需要使用的输入文档中的字段时,pipeline中需要使用$expr操作符)db.user.aggregate([{$lookup: {from: 'forex',let: { bal: '$balance' },pipeline: [{$match: {$expr: {$and: [{ $eq: ['$date', new Date('2018-12-20')] }, { $gt: ['$$bal', 100] }]}}}],as: 'forexData'}}])// $group:对输入文档进行分组// $group: {// _id: <expression>,// <field1>: {<accumulator1> : <expression1>},// ...// }// _id: 定义分组规则db.transactions.aggregate([{$group: {_id: '$currency'}}])// 不使用聚合操作符的情况下,$group可以返回输入文档中某一字段的所有(不重复的)值// 使用聚合操作符计算分值聚合值db.transactions.aggregate([{$group: {_id: '$currency',totalQty: { $sum: '$qty' },totalNotional: { $sum: { $multiply: ['$price', '$qty'] } },avgPrice: { $avg: '$price' },count: { $sum: 1 },maxNotional: { $max: { $multiply: ['$price', '$qty'] } },minNotional: { $min: { $multiply: ['$price', '$qty'] } }}}])// 使用聚合操作符计算所有文档聚合值db.transactions.aggregate([{$group: {_id: null,totalQty: { $sum: '$qty' },totalNotional: { $sum: { $multiply: ['$price', '$qty'] } },avgPrice: { $avg: '$price' },count: { $sum: 1 },maxNotional: { $max: { $multiply: ['$price', '$qty'] } },minNotional: { $min: { $multiply: ['$price', '$qty'] } }}}])// 使用聚合操作符创建数组字段db.transactions.aggregate([{$group: {_id: '$currency',symbols: { $push: '$symbol' }}}])// $out 将管道中的文档输出写入一个新集合db.transactions.aggregate([{$group: {_id: '$currency',symbols: { $push: '$symbol' }}},{$out: 'output'}])// $out 将管道中的文档输出写入一个已存在的集合,新集合会覆盖旧的集合db.transactions.aggregate([{$group: {_id: '$currency',totalNotional: { $sum: { $multiply: ['$price', '$qty'] } }}},{$out: 'output'}])// 如果聚合管道操作遇到错误,$out不会创建新集合或者是覆盖已存在的集合内容
MongoDB局限
每个聚合管道阶段使用的内存不能超过100MB,如果数据量较大,为了防止聚合管道阶段超出内存上线并且抛出错误,可以启用allowDiskUse选项,在allowDiskUse启用之后,聚合阶段可以在内存量不足时,将操作数据写入临时文件中,临时文件会被写入dbPath下的_tmp文件夹,dbPath的默认值为/data/db。
MongoDB对聚合操作的优化
// 聚合阶段顺序优化// $project + $match// $match阶段会在$project阶段之前运行db.transactions.aggregate([{$project: {_id: 0,symbol: 1,currency: 1,notional: { $multiply: ['$price', '$qty'] }}},{$match: {currency: 'USD',notional: { $gt: 1000 }}}])// 相当于db.transactions.aggregate([{$match: {currency: 'USD'}},{$project: {_id: 0,symbol: 1,currency: 1,notional: { $multiply: ['$price', '$qty'] }}},{$match: {notional: { $gt: 1000 }}}])// $project + $sort// $match阶段会在$sort阶段之前运行db.transactions.aggregate([{$sort: {price: 1}},{$match: {currency: 'USD'}}])// 相当于db.transactions.aggregate([{$match: {currency: 'USD'}},{$sort: {price: 1}}])// $project + $skip// $skip阶段会在$project阶段之前运行db.transactions.aggregate([{$project: {_id: 0,symbol: 1,currency: 1,notional: { $multiply: ['$price', '$qty'] }}},{$skip: 2}])// 相当于db.transactions.aggregate([{$skip: 2},{$project: {_id: 0,symbol: 1,currency: 1,notional: { $multiply: ['$price', '$qty'] }}}])// 聚合阶段合并优化// $sort + $limit// 如果两者之间没有夹杂着会改变文档数量的聚合阶段,$sort和$limit阶段可以合并db.transactions.aggregate([{$sort: { price: 1 }},{$project: {_id: 0,symbol: 1,currency: 1,notional: { $multiply: ['$price', '$qty'] }}},{$limit: 2}])// $limit + $limit// $skip + $skip// $match + $match// 连续的$limit,$skip,$match阶段排列在一起时,可以合并为一个阶段// {$limit: 10},// {$limit: 5}// 合并// {$limit: 15}// {$skip: 10},// {$skip: 5}// 合并// {$skip: 15}// {$match: {currency: 'USD'}},// {$match: {qty: 1}}// 合并{$match: {$and: [{ currency: 'USD' }, { qty: 1 }]}}// $lookup + $unwind// 连续排列在一起的$lookup和$unwind阶段,如果$unwind应用在$lookup阶段创建的as字段上,则两者可以合并db.transactions.aggregate([{$lookup: {from: 'forex',localField: 'currency',foreignField: 'ccy',as: 'forexData'}},{$unwind: '$forexData'}])
论MongoDB中索引的重要性
基本概念
- 对文档指定字段进行排序的数据结构
- 加快文档查询和排序的速度
- 复合键索引只能支持前缀子查询
例:A、B、C三个字段的复合索引,对索引中A、AB、ABC字段的查询称之为前缀子查询
基本操作
创建索引
createIndex()方法基本语法格式如下所示:
>db.collection.createIndex(keys, options)
语法中 Key 值为你要创建的索引字段,1 为指定按升序创建索引,如果你想按降序来创建索引指定为 -1 即可。
// 创建一个单键索引db.userWithIndex.createIndex({name: 1})// 创建一个复合索引db.userWithIndex.createIndex({name: 1, balance: -1})// 创建一个多键索引(用于数组的索引,数组字段中的每一个元素,都会在多键索引中创建一个键)db.userWithIndex.createIndex({currency: 1})// 查看集合中已经存在的索引db.userWithIndex.getIndexes()
查看索引
db.userWithIndex.getIndexes()
查询分析
- 检视索引的效果
- explain()
// 使用没有创建索引的字段进行搜索// COLLSCAN (Collection Scan 扫描整个集合,低效的查询)db.userWithIndex.find({balance: 100}).explain()// 使用已经创建索引的字段进行搜索// IXSCAN —> FETCH// 通过索引完成初步筛选,再根据索引中指示的文档储存地址,把对应的文档提取出来db.userWithIndex.find({name: 'alice'}).explain()// 仅返回创建了索引的字段(查询效率更高)// PROJECTION —> IXSCANdb.userWithIndex.find({name: 'alice'}, {_id: 0, name: 1}).explain()// 使用已经创建索引的字段进行排序// IXSCAN —> FETCHdb.userWithIndex.find().sort({name: 1, balance: -1}).explain()// 使用未创建索引的字段进行排序// COLLSCAN —> SORT_KEY_GENERATOR —> SORTdb.userWithIndex.find().sort({name: 1, balance: 1}).explain()// 删除索引db.userWithIndex.dropIndex()// 如果需要更改某些字段上已经创建的索引,必须首先删除原有索引,再重新创建新索引,否则,新索引不会包含原有文档// 使用索引名称删除索引db.userWithIndex.dropIndex('name_1')// 使用索引定义删除索引db.userWithIndex.dropIndex({name: 1, balance: -1})
删除索引
db.userWithIndex.dropIndex()// 如果需要更改某些字段上已经创建的索引,必须首先删除原有索引,再重新创建新索引,否则,新索引不会包含原有文档// 使用索引名称删除索引db.userWithIndex.dropIndex('name_1')// 使用索引定义删除索引db.userWithIndex.dropIndex({name: 1, balance: -1})
索引选项
// options 定义了创建索引时可以使用的一些参数,也可以设定索引的特性// 创建具有唯一性的索引db.userWithIndex.createIndex({balance: 1}, {unique: true})// 如果已有文档中的某个字段出现了重复值,就不可以在这个字段上创建唯一性索引db.userWithIndex.createIndex({name: 1}, {unique: true})// 如果新增的文档不包含唯一性索引,只有第一个缺少改字段的文档可以被写入数据库,索引中该文档的键值被默认为nulldb.userWithIndex.insert({name: 'cherlie', lastAccess: new Date()})db.userWithIndex.insert({name: 'david', lastAccess: new Date()})// 复合键索引也可以具有唯一性,在这种情况下,不同的文档之间,其所包含的复合键字段值的组合,不可以重复// 创建具有稀疏性的索引db.userWithIndex.createIndex({balance: 1}, {sparse: true})// 只将包含索引字段的文档加入到索引中(即便索引字段值为 null)db.userWithIndex.insert({name: 'cherlie', lastAccess: new Date()})// 如果同一个索引既具有唯一性,又具有稀疏性,就可以保存多篇缺失索引键值得文档了db.userWithIndex.createIndex({balance: 1}, {unique: true, sparse: true})db.userWithIndex.insert({name: 'cherlie', lastAccess: new Date()})// 复合键索引也可以具有稀疏性,在这种情况下,只有在缺失复合键所包含的所有字段的情况下,文档才不会被加入到索引中
索引的生存时间
// 针对日期字段,或者包含日期字段的数组字段,可以使用设定了生存时间的索引,来自动删除字段值超过生存时间的文档// 在 lastAccess 字段上创建一个生存时间是20s的索引db.userWithIndex.createIndex({lastAccess: 1}, {expireAfterSeconds: 20})db.userWithIndex.insert({name: 'eddie', lastAccess: new Date()})// 复合键索引不具备生存时间特效// 当索引建是包含日期元素的数组字段时,数组中最小的日期将被用来计算文档是否过期// 数据库使用一个后台线程来监测和删除过期的文档,删除操作可能会有一定的延迟
MongoDB之数据模型
待更新…

若有收获,就点个赞吧
0 人点赞
