1.前言
在计算机中表示字母、汉字、标点符号的方式就是用 二进制(0和1)表示,不同的二进制表示不同的字符,最早的字符集就是ASCII码,ASCII码中有128个字符,使用8bit(1字节)就为每个字符生成了一个唯一的编号。然而,我要想表示一个汉字怎么办?于是出现了GBK编码,由于GBK字符集的字符数量十分之大,显然8bit(1字节)的空间肯定不够用,所有使用2个字节16bit进行编码。所以GBK中一个字符占2个字节。那么,其他国家也有自己的语言那么就出现了Unicode字符集编码,其具体的编码表示方式又分为 UTF-8,UTF-16。<br />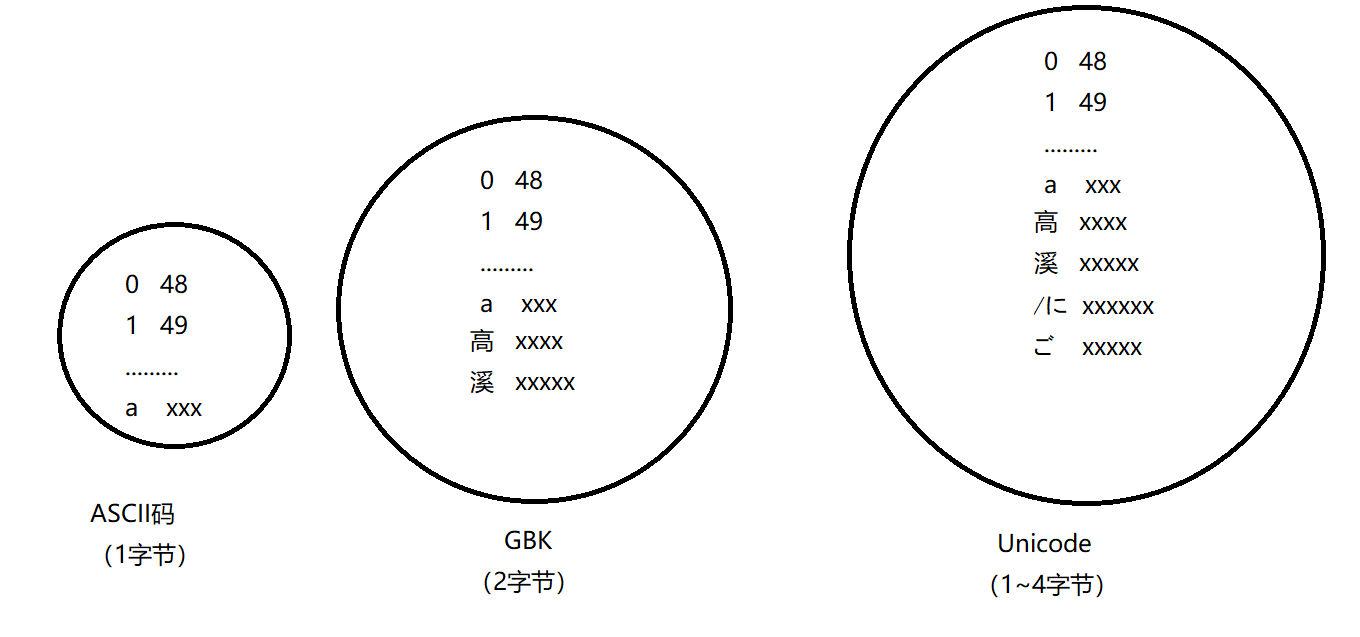
2.UTF-8和UTF-6
UTF-8:以8个bit位为一个单元,最多使用4个单元(字节),就是说:一个字符使用UTF-8编码,其最终的字节长度可能是 1个字节(1个单元)、2个字节(2个单元)、3个字节(单元)或4个字节(单元)
public static void main(String[] args) {String s ="1";System.out.println(s.getBytes().length); // 1String s1="高";System.out.println(s1.getBytes().length); // 3String s2 ="ɑ";System.out.println(s2.getBytes().length); // 2String s3 ="\uDBC0\uDC09"; //System.out.println(s3.getBytes().length); //4}
最后一个s3为啥在显示的是2个码呢?原因是字符串当遇到一个char无法表示的字符时 (比如:)会将这个字符用UTF-16表示。
UTF-16: 以16个bit位为一个单元,最多使用2个单元,也是4个字节。
3.总结
最后我想说的是:
①Java的char类型占2个字节,使用UTF-16编码。
②Java的char类型无法、无法、无法表示所有的汉字、字符
③Java的String类型在获取转换成字节数组时,默认使用平台编码方式,当前我们的平台默认编码是UTF-8.
public static void main(String[] args) {String c="虫";//等同于 System.out.println(c.getBytes(Charset.defaultCharset()).length);System.out.println(c.getBytes().length);byte[] bytes = c.getBytes();//等同于 String string = new String(bytes, StandardCharsets.UTF_8);String string = new String(bytes);System.out.println(string);}
也可以通过StandardCharsets指定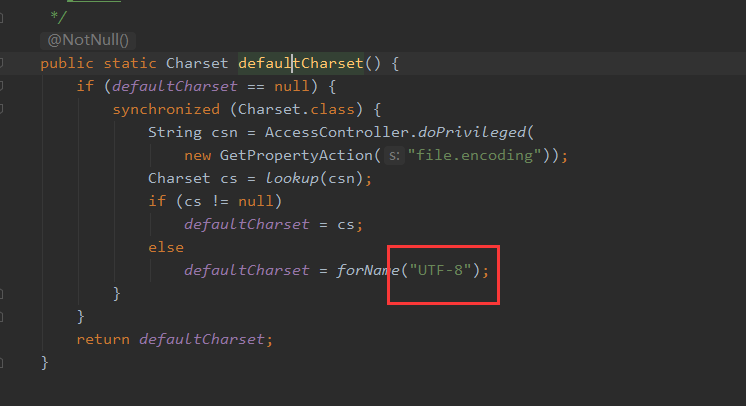

若有收获,就点个赞吧
0 人点赞
