问题:当我的数据十分多(海量),此时分页若还是使用limit N,M的方式,会特别的慢且浪费资源
实际体验
- 写在前面:工作提供成长环境呀,我这边有500万的数据,是当时做雨润某个报表业务时拉取下来的。
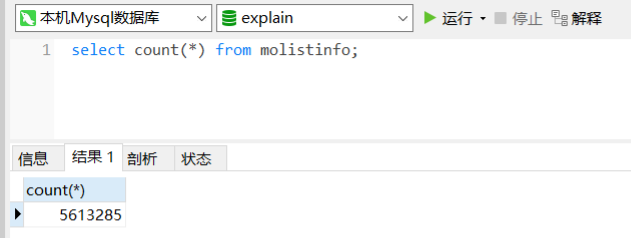
- 书写一个正常分页的语句
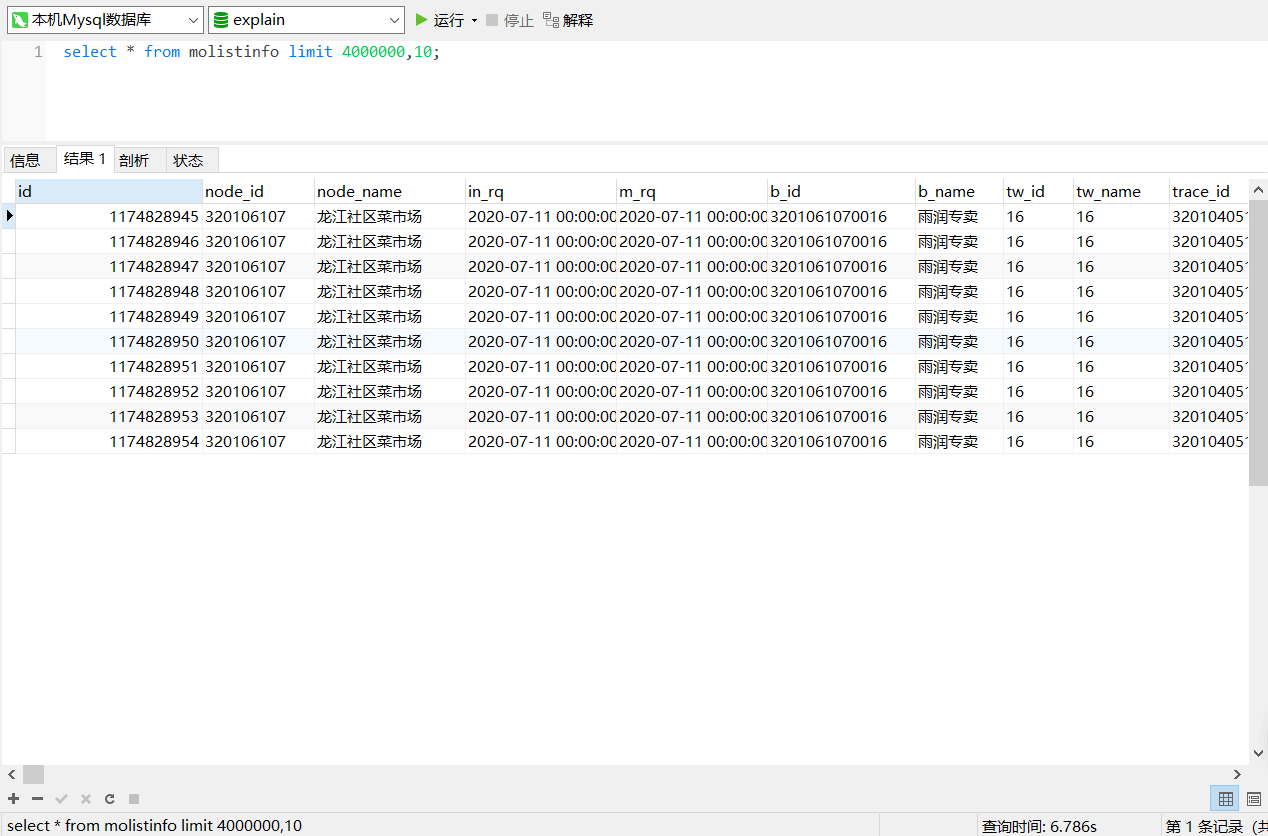
- 这条SQL是跑了6.786s
优化方式1(阿里巴巴手册)
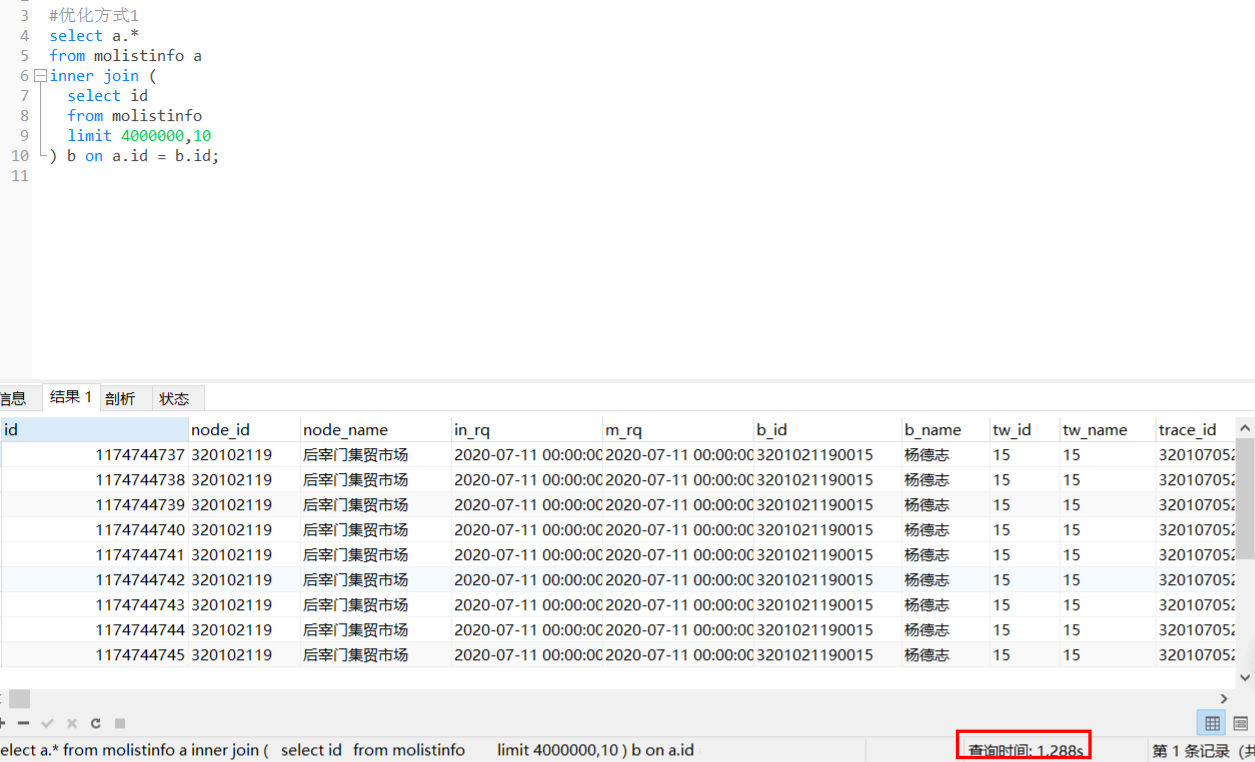
- 先只对id(主键)进行分页,得到临时表
tmp(id) - 我再将原数据表
join上tmp(id)表 ```sql select a.* from molistinfo a inner join ( select id from molistinfo limit 4000000,10 ) b on a.id = b.id;
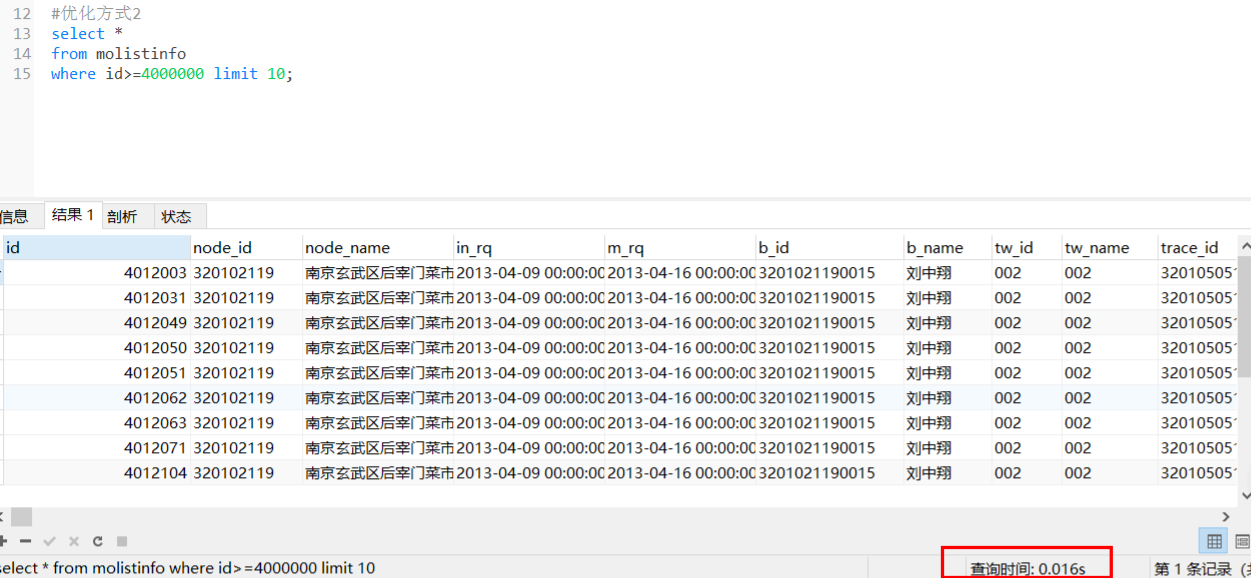
<a name="z4VIu"></a>## 优化方式2- 当id是自增时- 且允许每页数据可能不足10条(id是中间可能有跳跃)```sqlselect *from molistinfowhere id>=4000000 limit 10;
总结
- 优化方式1:通用
- 优化方式2:局限性大,但是最快

若有收获,就点个赞吧
0 人点赞
