1.前言
本文是为了分享ShardingSphere所写的一篇文章,文章不会过分涉及到ShardingSphere的具体使用细节,旨在完成对ShardingSphere相关组件和功能的概览,分库分表的概念的个人理解等理论知识。
2.分库分表
首先我们先聊一聊分库分表,本章阐述分库分表的原因有哪些?使用一些生动的例子来描述何为分库?何为分表。使用图片来描述水平(横向),垂直(纵向)的具体拆分方式,以及各自拆分方式所解决问题和不足。紧接着描述了一些数据分片的常见方式。最后讨论了分库分表后带来的问题。
2.1分库分表的原因
分库分表的原因,总结下来就是:由于业务量的庞大导致数据量的不断膨胀,致使单表或单库无法满足软件正常的使用需求。单库单表在面临庞大业务量和数据量时会有以下的问题,这些问题正是分库分表的主要原因
- 单库单表容量有限
《阿里巴巴Java开发手册》中推荐:

针对Mysql来说,单表不可超过500万行,单库不得超过5000万行。一旦数据量超过阈值,其操作性能会明显下降。
原因是:像Mysql这样的关系型数据库大多采用 B+ 树类型的索引,在数据量超过阈值的情况下,索引深度的增加也将使得磁盘访问的 IO 次数增加,进而导致查询性能的下降。
- 单库的IO瓶颈
- 磁盘IO:数据量大,请求次数多,IO的次数自然多
- 网络IO:数据量大,请求次数多,单机的网络带宽是否扛得住
- 单点问题
- 如果只是单库,那么一个数据库挂了,那么全部的业务都将挂了。
- 可以通过Mysql一些高可用架构部署方式解决此类问题,而分库也是减轻这类问题影响的有效手段
如:一份数据被分别分到数据库A和数据库B上,各50%,数据库A挂了,只会有50%的数据有问题,那50%还是正常的。减轻了问题的严重性。
2.2分库or分表
分库分表在大多数情况下是被同时提及且同时使用的,但是其实这两个东西是可以2选1的。可以只进行分库或仅仅进行分表操作。
举个例子:
1.电商项目中有商品,商品有价格、名称、单位、商品图片、商品富文本描述等信息。正常来讲就是一张表来囊括这么多字段。但是考虑到商品富文本只有在进入详情页,才会用到,且字段占用的空间也很大,影响单条记录的读取速率。
此时可以把富文本信息单独放在一个表中。当前电商项目也是这么做的。这就是所谓的分表(垂直分表)。垂直分表在好多项目中就已经使用。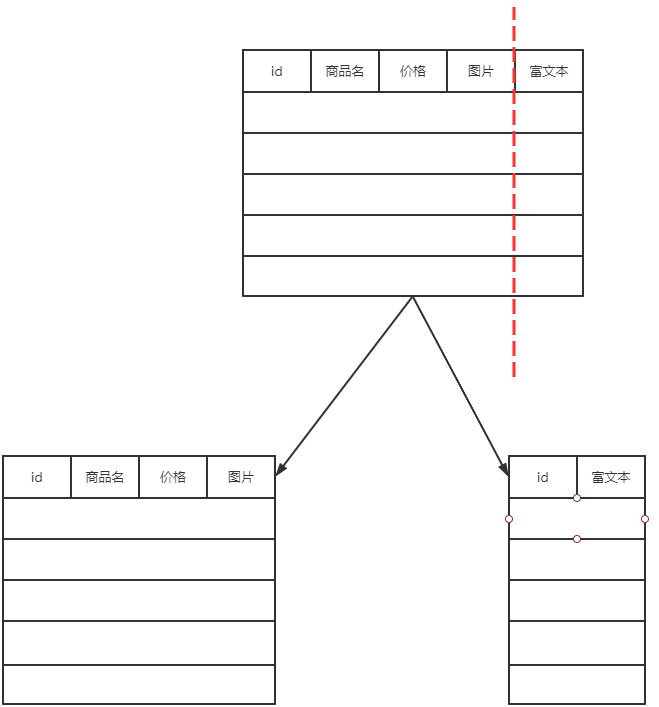
解决的问题**:加快热点数据的操作效率
2.现在的电商平台随着内购活动的上线,几年后订单量陡增。单张订单表已经无法容纳。但是,**这个硬件设施也不给力**,没有服务器再给你部署一个生产数据库了。
这种情况下可以考虑单独的分表操作,一个表我容纳不下,我在这个数据库下再建一张同样的表(order_info2),不就可以了吗。现在两张表不就能放下1千万的数据了吗?这就是仅仅的分表(水平分表)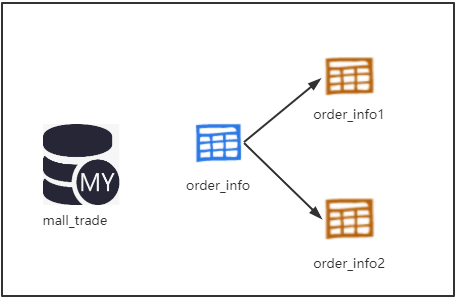
解决的问题:分表后解决了单表数据容量的问题。**
3.突然有一天,后端又喜得一台性能极高的服务器,于是部署了一个新生产Mysql服务器,这时电商项目活动模块的负责人超超,希望活动相关表和订单相关的表分开(受够了订单模块的欺辱,老子要独立)。
这种情况下就可以分库(垂直分库),于是活动相关的表就从mall_trade库分离出来了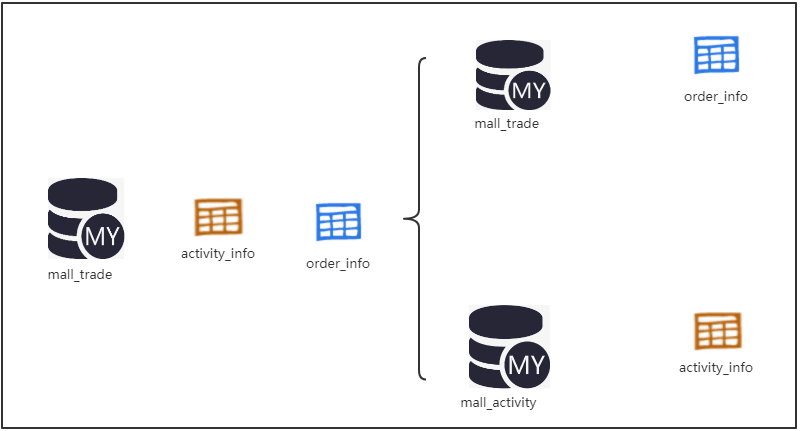
解决的问题:业务清晰,一定程度上避免单库的资源瓶颈产生
4.N多年后,订单的数据太过膨胀,在案例2中即使分表,一个数据库也容纳不了这么多张订单表数据了。
这种情况下就需要传说中分库分表操作(水平分表且水平分库)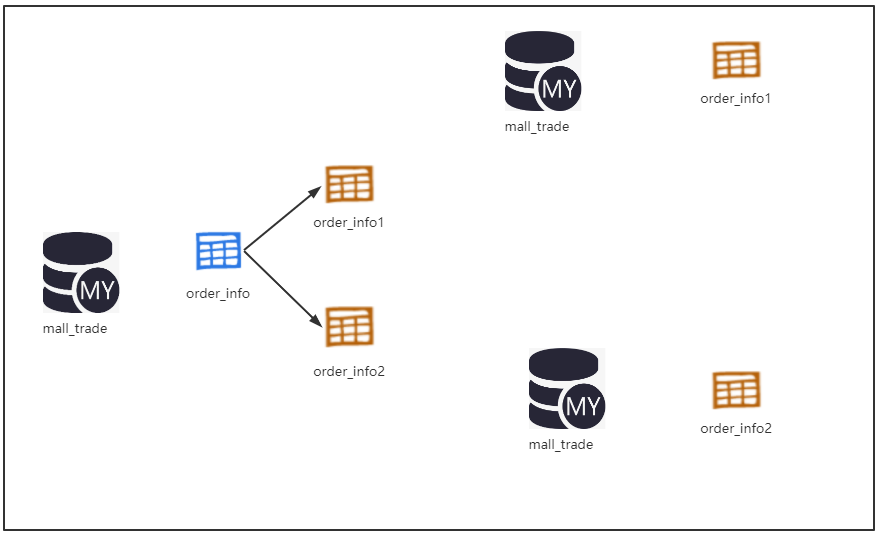
解决的问题:数据量大的问题,同时解决单库的性能瓶颈
2.3 垂直拆分和水平拆分
数据库可以进行水平或垂直拆分,数据表也可以进行水平或垂直拆分。
- 表的垂直拆分(见2.1-案例1)
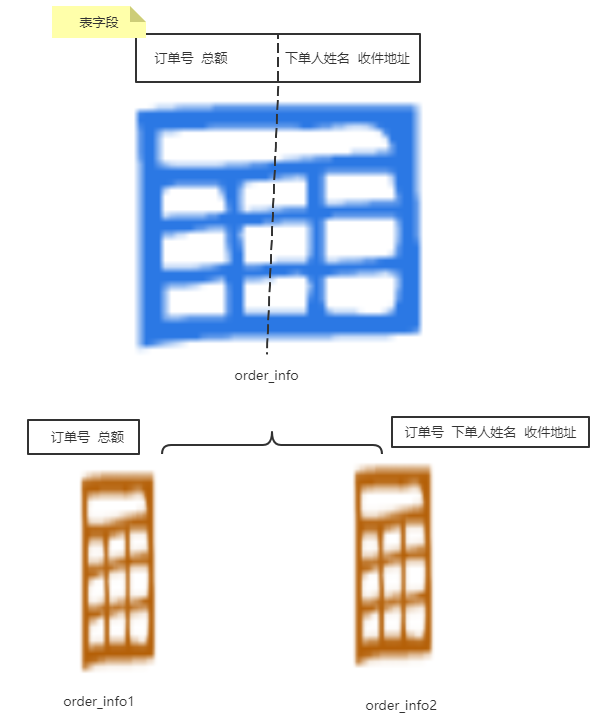
解决的问题:常用字段和不常用字段分离,大字段的隔离,提高对常用字段(热门数据)的操作效率,一定程度缓解单表的存储压力
存在的问题:数据量大时单库仍无能为力。
进行分库时需要设置绑定关系,否则 join会很麻烦
- 表的水平拆分(见2.1-案例2)
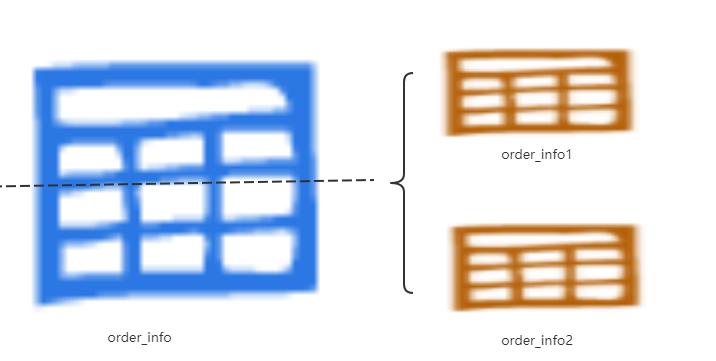
解决的问题:分散了单表压力
存在的问题:仍受单库量的限制,增加分页,排序的难度
- 数据库垂直拆分(见2.1-案例3)
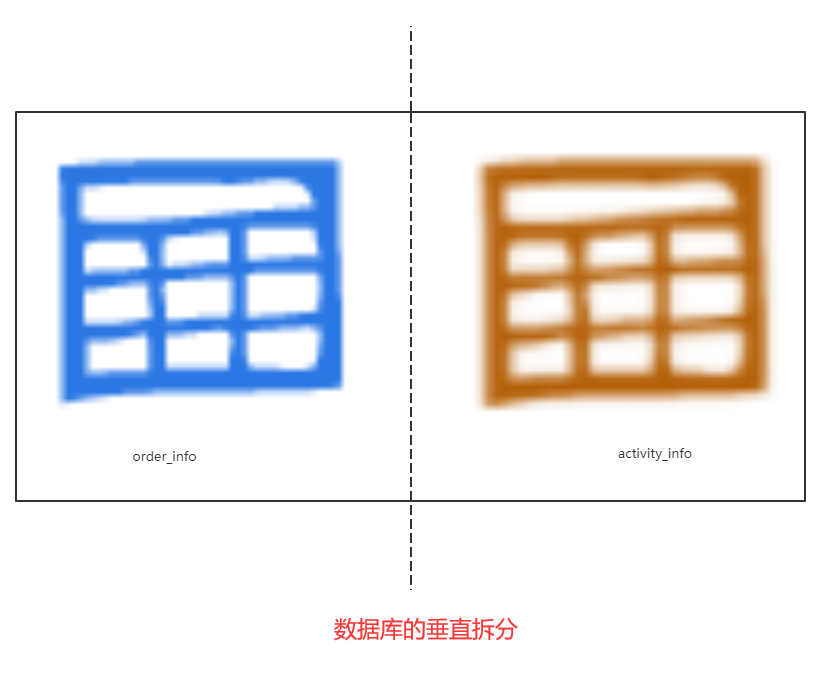
解决的问题:业务清晰,一定程度上避免单库的资源瓶颈产生
存在的问题:单库资源瓶颈依然会产生。跨库join
- 数据库的水平拆分(见2.1-案例4)

可以看到数据库的水平切分一定会带来表的水平切分
解决的问题:从理论上突破了单机数据量处理的瓶颈
存在的问题:除了和分表一样的问题外,维护成本高,分布式事务
2.4数据分片规则
上面我们已经了解了何为分表,何为分库,垂直拆分和水平拆分的结果。那么现在,我们对商品表进行分库分表,最终结果是让一张商品表,分为2张,每个库各有一张商品表。这个问题的关键点是如何让数据均匀的落在每个库上,避免热点数据集中存储在某一个库下的商品表中。下面介绍几个常用的数据分片算法
2.4.1哈希取模法
哈希取模法十分简单,其分片思想就是:hash(key) mod K 。 甚至可以更简单一点直接使用数值类型的唯一ID直接取模即可
优点: 简单,数据均衡,负载均衡
缺点:扩容比较难, 6%3 != 6%4 ,原数据需要迁移
2.4.2一致性Hash
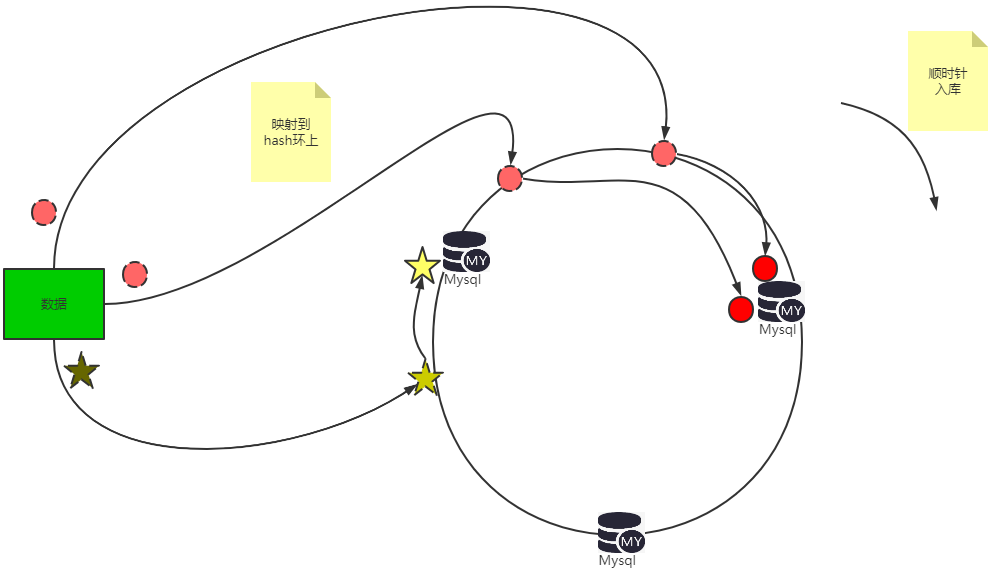
数据库和数据通过计算哈希值映射到一个hash环上(0~2^32-1) ,数据顺时针移入距离其最近的那个数据库即可
优点:扩容简单
缺点:容易出现数据倾斜问题
优缺点原因解释:
①扩容简单:
如下图,在只有数据A、B、C时,红色的球全是数据A的数据,黄色的五角星为数据库B的数据,蓝色的菱形为数据C的数据。当我引入数据库D,是不是只要把数据A的数据全部删除,然后重新映射一遍即可,其涉及的数据库只有数据库A一个,其他的B、C库的数据不用做任何变化。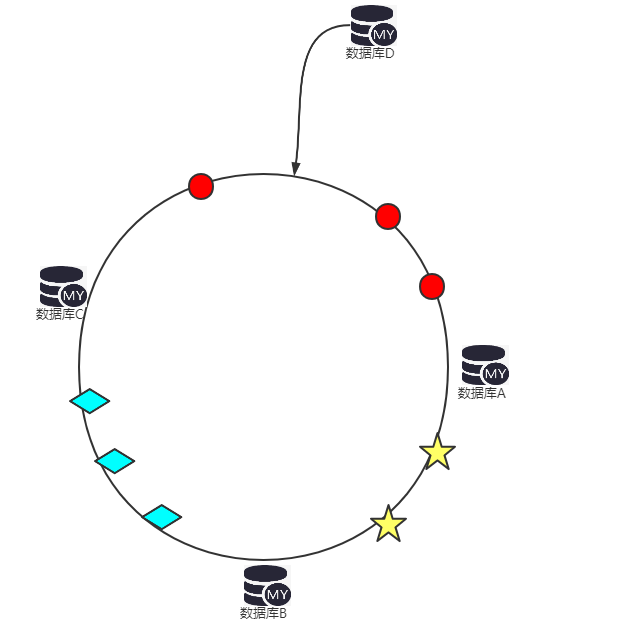
②数据容易倾斜:如下图所示,数据A都成串糖葫芦了,数据库B仅有那一颗孤单的小星星。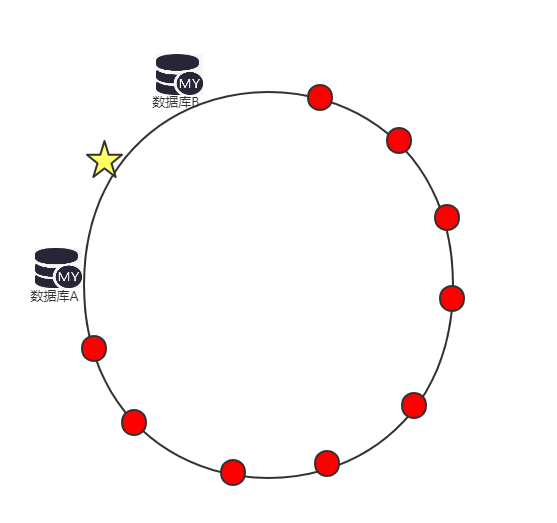
产生数据倾斜的方法时通过添加虚拟节点来控制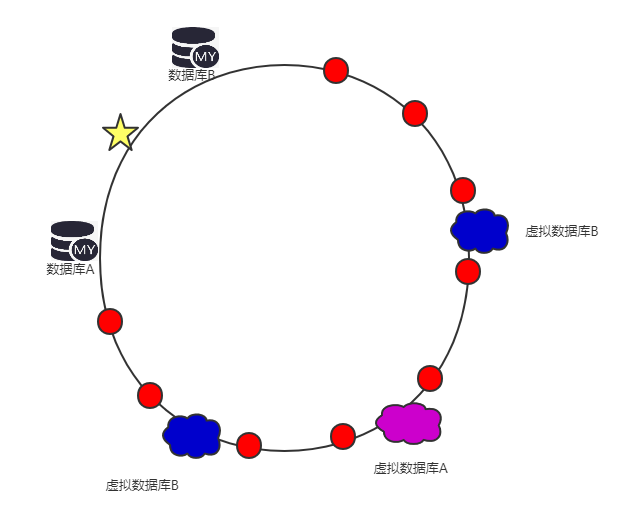
2.4.3范围路由
按照某个字段或某几个字段作为范围的划分条件,比如,按照价格范围来分,0~1000元的商品在A库,1000~2000元的在B库…
优点:简单
缺点:热点问题(0~1000元的东西浏览次数会高一些)压力集中在A库上
2.5分库分表带来的问题
2.5.1主键问题
单库单表的情况下,使用Mysql的自增主键没啥问题。但是在分表或是在分库分表的场景下,自增主键就不太行了吧。
解决方案:
①UUID:简单,但是UUID太长以及无序。UUID有5个版本,我们使用Java自带的UUID是第四版本的
②雪花算法: 1bit + 41bit 时间戳 + 10bit 机器位 + 12bit 顺序号
③借助Redis或zk
④开源项目:美团Leaf
注:shardingsphere 也内置了 UUID 雪花 和借鉴Leaf的分布式主键解决方案
2.5.2分页排序问题
单库单表的情况下,执行完order by后面带着limit就可以了,这里假设分表,你在每张表中都会执行 order by的sql,之后你需要将这些order by 结果再 进行order by之后再limit一下(这是我认为的,嘿嘿)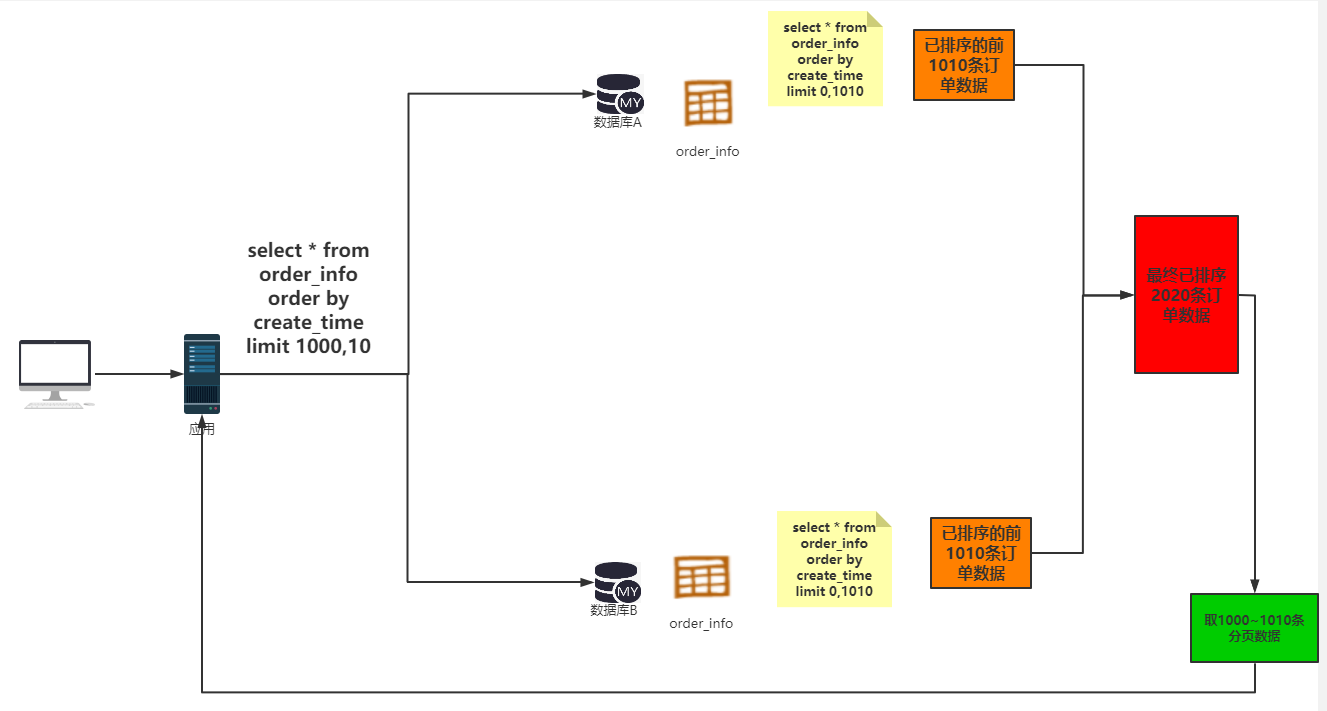
解释说明:用户查询第1000条~1010条数据,在单表情况下我一条sql就行了,但是在分表后,具体执行的话要变成如下步骤:
①在数据库A中查询 0~1010条数据,在数据库B中也查询0~1010条数据 (这两组都是排好序的)
②将两组数据再排序,组成一个更大的数据集合 (红色方块)
③然后取1000~1010这个范围的数据。
分表后的分页排序是比单表的分页排序要麻烦的多。当然这些操作不需要你去考虑,使用ShardingSphere后它会帮你完成这些事情,ShardingSphere对这项操作进行了优化,对2个已排序的数据集排序使用归并排序,且不将数据直接放入内存,而是只放指向数据的指针。
2.5.3关联查询问题
分库后,关联查询的问题变得不是那么简单,
比如说现在订单表和订单明细表,一张订单带着一个订单明细List。一般这种情况下还是好解决的,比如我人为的控制 订单和订单明细在分库的时候都进入同一个库。在shardingSphere中订单和订单明细表可以设置绑定表的关系,在Mycat中可以设置ER表的配置。
还有一种就是所有数据库都需要的某张表,这样的表可以设置为一个全局表,每个库都放同样的数据。
最后一种就是垂直分库,比如超超的活动单库一个库,订单这边单独一个库,一个订单想联查出参与的活动信息,这种跨库的联合查询Mycat和ShardingSphere都不支持,这种情况下,就得服务调用服务,代码层面塞值了。
2.5.4分布式事务问题
分库后会带来分布式事务问题,其解决方案有:
①JTA:依赖于XA协议(分布式事务的处理方案),JTA是依照XA协议定义的一套解决分布式事务问题的接口(规范)。JTA架构中的参与者有:AP(应用程序),TM(事务管理者),RM(资源管理者)。JTA是一套接口,定义了TM实现的接口和RM需要实现的接口,RM的实现接口由数据库厂商实现,TM接口由一些事务管理者实现厂商(说白了,就是一群厉害的人帮你实现这个TM)。然后程序通过被实现的UserTransaction接口(我认为一般TM实现厂商会帮我们实现),与TM交互,TM和RM交互,完成分布式事务控制 。
②Seata各种模式
③消息事务
2.6异构索引
异构索引使用场景是:假设订单数据表有 order_id和 user_id 两个字段 ,现在我按照order_id取模的方式进行分表。当用户按照order_id查询时,按照同样的取模方式可以快速准确定位到去哪张表查询。
但是现在用户只想看用户编号为2的订单数据,那么就无法准确定位那张表的数据了。我必须全部扫描所有的表。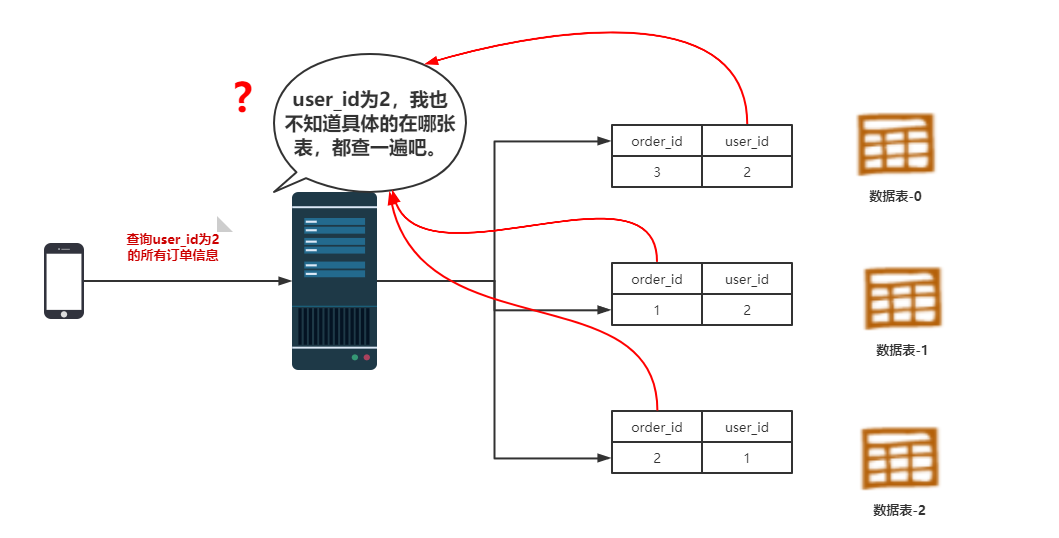
为了解决这一问题,就引出了异构索引的概念,如果在存储订单信息时,多存一张user_id和order_id关系表就可以解决了。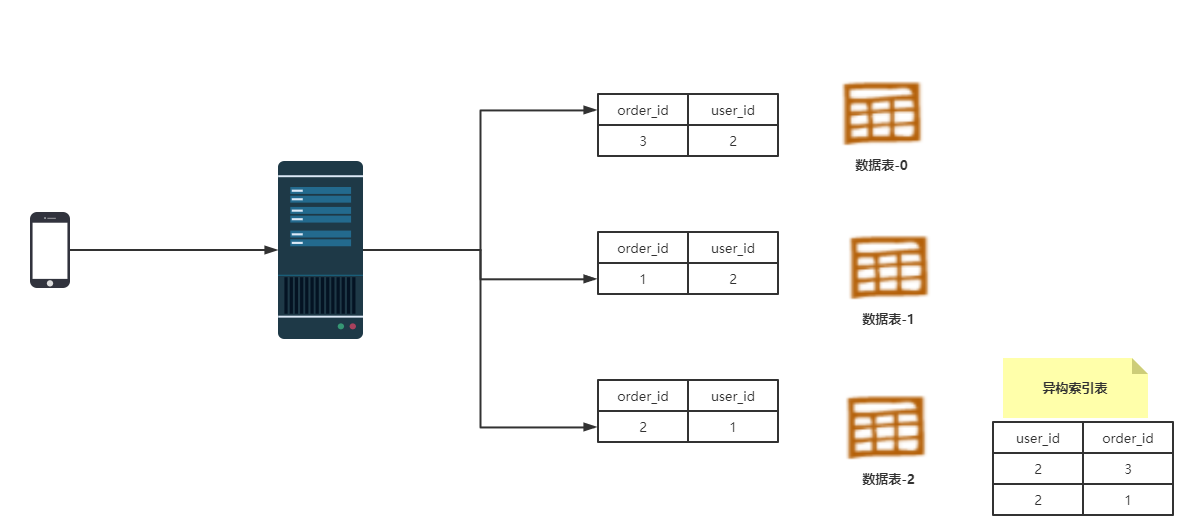
通过异构索引表的查询步骤如下:
①通过user_id =2 判断出异构索引表在 第2个节点上。
②查询到user_id=2的所有订单号List信息。
③根据订单号,依次查询数据表,只要查询第0个节点和第1个节点即可。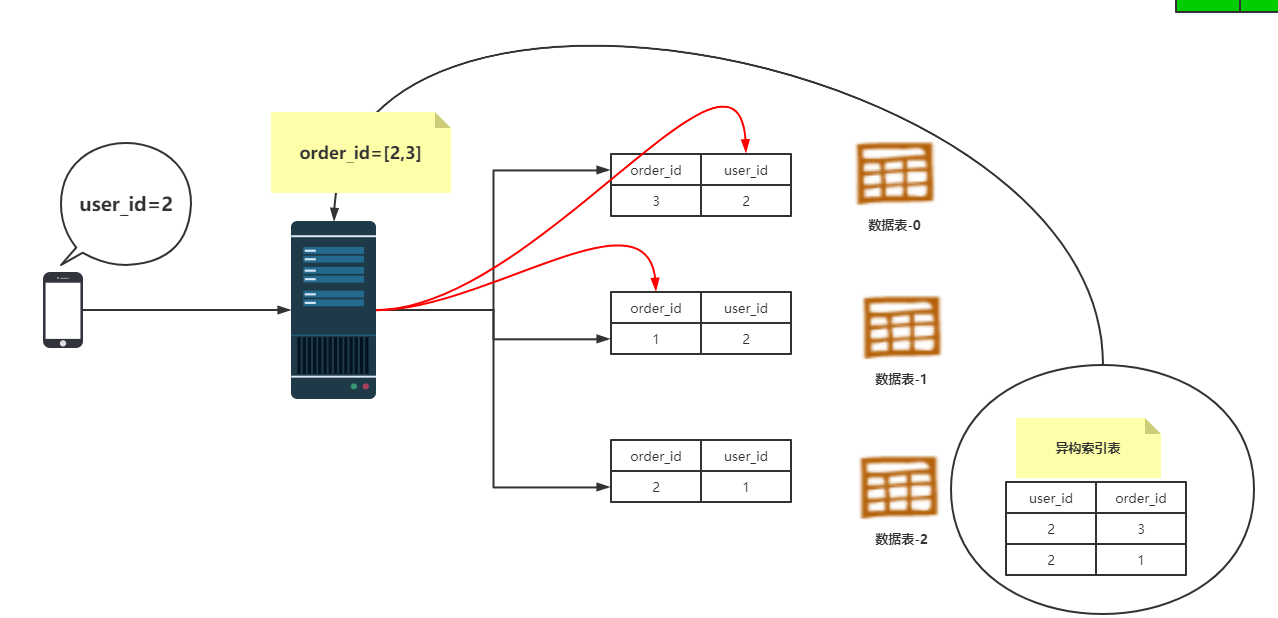
3.ShardingSphere-JDBC简介
ShardingSphere是一个生态圈,ShardingSphere-JDBC是其中的一个组件。官方定义其是一个轻量级Java框架。
3.1解决思路
ShardingSphere-JDBC解决分库分表问题的思路是,在各个应用服务上做文章。假设现在没有这些分库分表的中间件,但是又要实现分库分表,那我们只能在写代码时人为的控制,其代码大概是下面的样子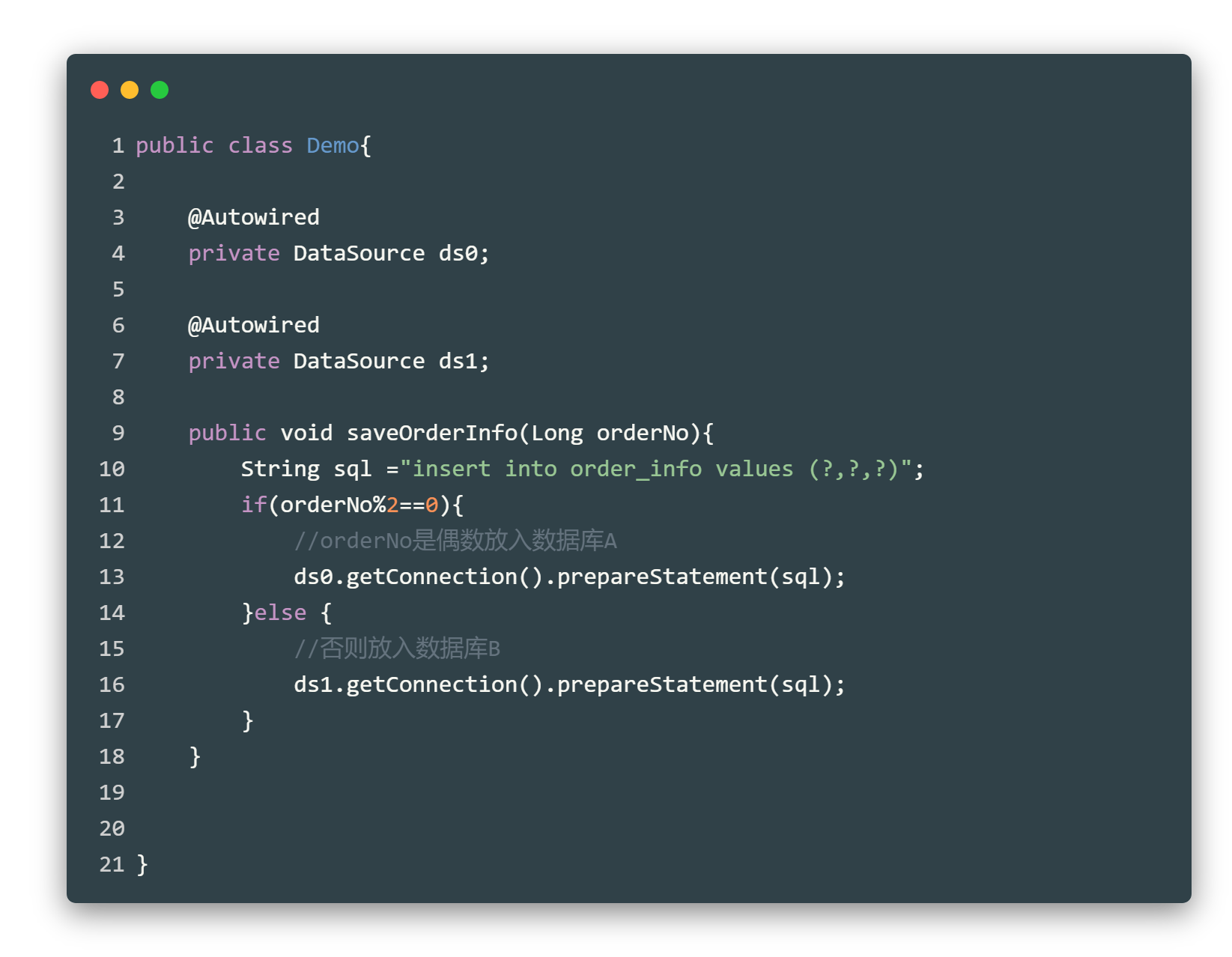
上面的代码就可以将订单数据按照订单号奇偶来进行分库分表了。但是这样的代码肯定是不行的。我写一个业务接口,不仅考虑自身业务逻辑还要去实现分库分表逻辑。这难度也太大了。
于是ShardingSphere-JDBC所做的工作就是将上述的行为封装起来,你不需要手动去写分库分表逻辑。你只需要告诉ShardingSphere-JDBC,你想怎么分库怎么分表,具体实现ShardingSpherer-JDBC去帮你做。同时,你也不必要去操作两个数据源,ShardingSphere-JDBC将所有的数据源封装成一个ShardingSphereDataSource,你只需要使用这一个数据源,去执行相关数据库sql,具体是数据源A执行Sql还是数据源B执行Sql,ShardingSphere-JDBC会依据你设置的分库分表规则去决定。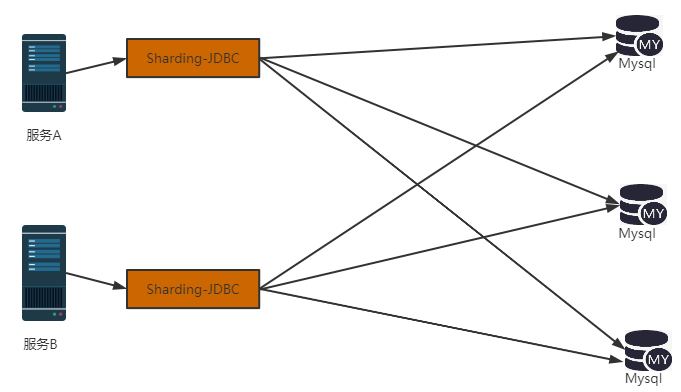
3.2主要学习内容
ShardingSphere-JDBC的主要使用方式是:在各个业务服务中引入jar包,并配置分库分表规则即可。于是其学习重点应该是:
- 数据分片的配置规则学习:行表达式
- 分布式事务的配置:XA、Seata-AT
- 读写分离的配置
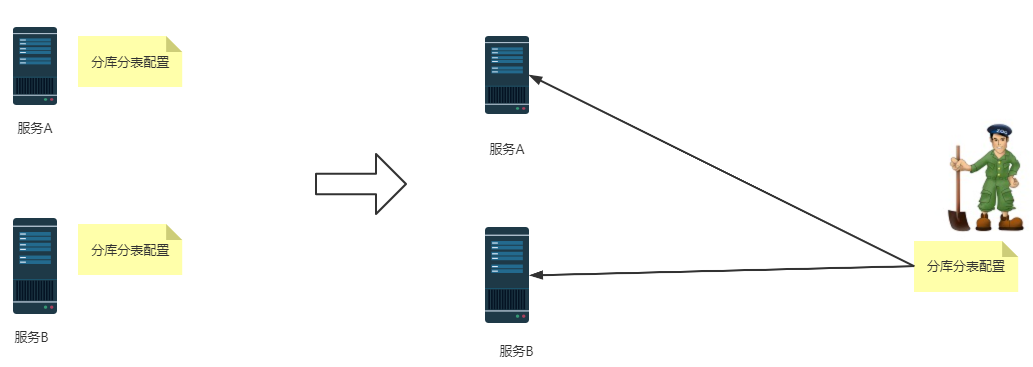
- 分布式治理:统一管理配置规则,见下图
4.ShardingSphere-Proxy简介
ShardingSphere-Proxy是ShardingSphere的另一个解决分库分表问题的组件,它就类似于MyCat
4.1解决思路
ShardingSphere-Proxy从名字上看就代理的意思,它解决分库分表问题的方法是做数据库的代理。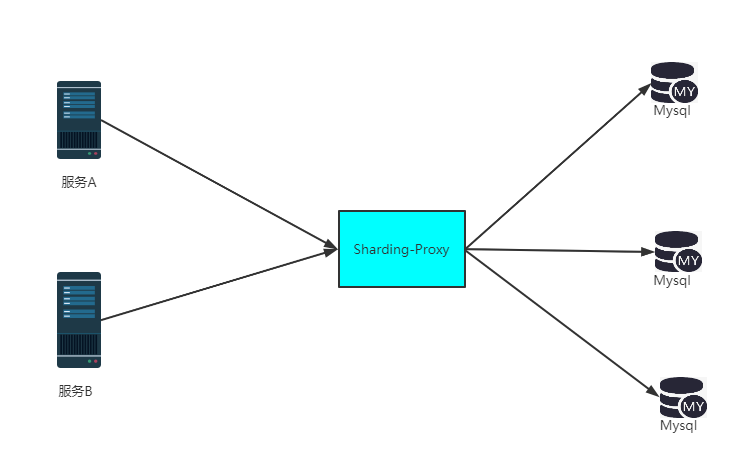
4.2主要学习内容
同3.2一样

若有收获,就点个赞吧
0 人点赞
